







一、概念
1.MR是Hadoop中的分布式计算框架,但是不适合实时计算场景,所以需要改进。
2.Spark具有如下几个主要特点:
(1)运行速度快:使用DAG执行引擎以支持循环数据流与内存计算。
(2)容易使用:支持使用Scala、Java、Python和R语言进行编程,可以通过Spark Shell进行交互式编程。
(3)通用性:Spark提供了完整而强大的技术栈,包括SQL查询、流式计算、机器学习和图算法组件。
(4)运行模式多样:可运行于独立的集群模式中,可运行于Hadoop中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源。
3.Scala
(1)是Spark的主要编程语言。
(2)Scala具备强大的并发性,支持函数式编程,可以更好地支持分布式系统
(3)Scala语法简洁,能提供优雅的API
(4)Scala兼容Java,运行速度快,且能融合到Hadoop生态圈中
(5)Spark提供了内存计算,可将中间结果放到内存中,对于迭代运算效率更高
(6)Spark基于DAG的任务调度执行机制,要优于Hadoop MapReduce的迭代执行机制
二、习题
大题
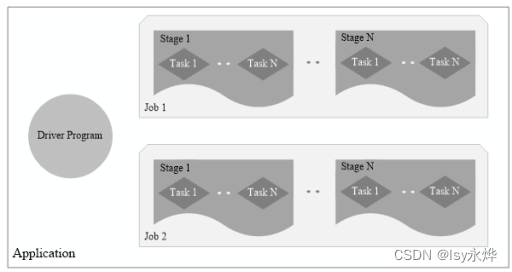
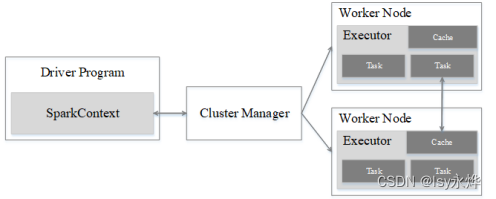
1.写出下列Spark中的概念: (1)RDD (2)DAG (3)Executor (4)Application (5)Task (6)Job (7)Stage (8)宽依赖 (9)窄依赖 。
答:
(1)RDD:弹性分布式数据集,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型。
(2)DAG:有向无环图,反映RDD之间的依赖关系。
(3)Executor:是运行在工作节点(WorkerNode)的一个进程,负责运行Task。
(4)Application:用户编写的Spark应用程序。
(5)Task:运行在Executor上的工作单元 。
(6)Job:一个Job包含多个RDD及作用于相应RDD上的各种操作。
(7)Stage:是Job的基本调度单位,一个Job会分为多组Task,每组Task被称为Stage,或者也被称为TaskSet,代表了一组关联的、相互之间没有Shuffle依赖关系的任务组成的任务集。
判断题
1.Spark的计算模式也属于MapReduce。( )
正确答案: 正确
2.Spark提供了内存计算,可将中间结果放到内存中,对于迭代运算效率更高。( )
正确答案: 正确
3.Spark的生态系统主要包含了Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX等组件。( )
正确答案: 正确
4.Spark只能部署在资源管理器YARN之上,并提供一站式的大数据解决方案。( )
正确答案: 错误
可运行于独立的集群模式中,可运行于Hadoop中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源。
5.Spark基于DAG的任务调度执行机制,要优于Hadoop MapReduce的迭代执行机制。( )
正确答案: 正确















 1496
1496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









