







 本文深入探讨Transformer的面试重点,包括Transformer的Embedding、预微调模块、FFN、Encoder和Decoder结构,以及Transformer在处理长文本和解决seq2seq问题的优势。还介绍了BERT的预训练任务和处理长文本的方法。
本文深入探讨Transformer的面试重点,包括Transformer的Embedding、预微调模块、FFN、Encoder和Decoder结构,以及Transformer在处理长文本和解决seq2seq问题的优势。还介绍了BERT的预训练任务和处理长文本的方法。
面试理论点-TRANSFORMER
三层Embedding
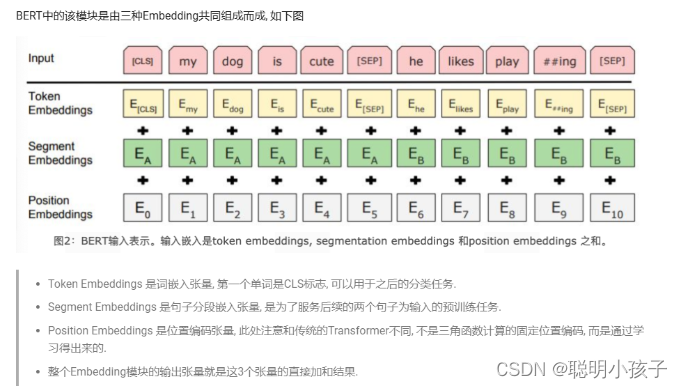
2.2 双向Transformer模块¶
BERT中只使用了经典Transformer架构中的Encoder部分, 完全舍弃了Decoder部分. 而两大预训练任务也集中体现在训练Transformer模块中.
2.3 预微调模块¶
- 经过中间层Transformer的处理后, BERT的最后一层根据任务的不同需求而做不同的调整即可.
- 比如对于sequence-level的分类任务, BERT直接取第一个[CLS] token 的final hidden state, 再加一层全连接层后进行softmax来预测最终的标签.
3.1 任务一: Masked LM¶
带mask的语言模型训练
- 关于传统的语言模型训练, 都是采用left-to-right, 或者left-to-right + right-to-left结合的方式, 但这种单向方式或者拼接的方式提取特征的能力有限. 为此BERT提出一个深度双向表达模型(deep bidirectional representation). 即采用MASK任务来训练模型.
- 1: 在原始训练文本中, 随机的抽取15%的token作为参与MASK任务的对象.
- 2: 在这些被选中的token中, 数据生成器并不是把它们全部变成[MASK], 而是有下列3种情况.
- 2.1: 在80%的概率下, 用[MASK]标记替换该token, 比如my dog is hairy -> my dog is [MASK]
- 2.2: 在10%的概率下, 用一个随机的单词替换token, 比如my dog is hairy -> my dog is apple
- 2.3: 在10%的概率下, 保持该token不变, 比如my dog is hairy -> my dog is hairy
- 3: 模型在训练的过程中, 并不知道它将要预测哪些单词? 哪些单词是原始的样子? 哪些单词被遮掩成了[MASK]? 哪些单词被替换成了其他单词? 正是在这样一种高度不确定的情况下, 反倒逼着模型快速学习该token的分布式上下文的语义, 尽最大努力学习原始语言说话的样子. 同时因为原始文本中只有15%的token参与了MASK操作, 并不会破坏原语言的表达能力和语言规则.
3.2 任务二: Next Sentence Prediction¶
下一句话预测任务
- 在NLP中有一类重要的问题比如QA(Quention-Answer), NLI(Natural Language Inference), 需要模型能够很好的理解两个句子之间的关系, 从而需要在模型的训练中引入对应的任务. 在BERT中引入的就是Next Sentence Prediction任务. 采用的方式是输入句子对(A, B), 模型来预测句子B是不是句子A的真实的下一句话.
- 1: 所有参与任务训练的语句都被选中作为句子A.
- 1.1: 其中50%的B是原始文本中真实跟随A的下一句话. (标记为IsNext, 代表正样本)
- 1.2: 其中50%的B是原始文本中随机抽取的一句话. (标记为NotNext, 代表负样本)
- 2: 在任务二中, BERT模型可以在测试集上取得97%-98%的准确率.
transformerFFN
- 前馈全连接层模块
- 前馈全连接层模块, 由两个线性变换组成, 中间有一个Relu激活函数, 对应的数学公式形式如下:FFN(x)=max(0,xW1+b1)W2+b2𝐹𝐹𝑁(𝑥)=max(0,𝑥𝑊1+𝑏1)𝑊2+𝑏2
- 注意: 原版论文中的前馈全连接层, 输入和输出的维度均为d_model = 512, 层内的连接维度d_ff = 2048, 均采用4倍的大小关系.
- 前馈全连接层的作用: 单纯的多头注意力机制并不足以提取到理想的特征, 因此增加全连接层来提升网络的能力.
1.1 Encoder模块的结构和作用:¶
- 经典的Transformer结构中的Encoder模块包含6个Encoder Block.
- 每个Encoder Block包含一个多头自注意力层, 和一个前馈全连接层.
1.2 关于Encoder Block¶
- 在Transformer架构中, 6个一模一样的Encoder Block层层堆叠在一起, 共同组成完整的Encoder, 因此剖析一个Block就可以对整个Encoder的内部结构有清晰的认识.
1.4 Decoder模块¶
-
Decoder模块的结构和作用:
- 经典的Transformer结构中的Decoder模块包含6个Decoder Block.
- 每个Decoder Block包含三个子层.
- 一个多头self-attention层
- 一个Encoder-Decoder attention层
- 一个前馈全连接层
-
Decoder Block中的多头self-attention层
- Decoder中的多头self-attention层与Encoder模块一致, 但需要注意的是Decoder模块的多头self-attention需要做look-ahead-mask, 因为在预测的时候"不能看见未来的信息", 所以要将当前的token和之后的token全部mask.
1.5 Add & Norm模块¶
-
Add & Norm模块接在每一个Encoder Block和Decoder Block中的每一个子层的后面. 具体来说Add表示残差连接, Norm表示LayerNorm.
- 对于每一个Encoder Block, 里面的两个子层后面都有Add & Norm.
- 对于每一个Decoder Block, 里面的三个子层后面都有Add & Norm.
- 具体的数学表达形式为: LayerNorm(x + Sublayer(x)), 其中Sublayer(x)为子层的输出.
-
Add残差连接的作用: 和其他神经网络模型中的残差连接作用一致, 都是为了将信息传递的更深, 增强模型的拟合能力. 试验表明残差连接的确增强了模型的表现.
-
Norm的作用: 随着网络层数的额增加, 通过多层的计算后参数可能会出现过大, 过小, 方差变大等现象, 这会导致学习过程出现异常, 模型的收敛非常慢. 因此对每一层计算后的数值进行规范化可以提升模型的表现.

1 Decoder端的输入解析¶
1.1 Decoder端的架构¶
Transformer原始论文中的Decoder模块是由N=6个相同的Decoder Block堆叠而成, 其中每一个Block是由3个子模块构成, 分别是多头self-attention模块, Encoder-Decoder attention模块, 前馈全连接层模块.
- 6个Block的输入不完全相同:
- 最下面的一层Block接收的输入是经历了MASK之后的Decoder端的输入 + Encoder端的输出.
- 其他5层Block接收的输入模式一致, 都是前一层Block的输出 + Encoder端的输出.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









