






一、Retinex 理论
1977年美国物理学家Land首次提出了Retinex 理论,其基于以下三个假设:
1.真实世界是无颜色的,我们所感知的颜色是光与物质的相互作用的结果;
2.每一颜色区域由给定波长的红、绿、蓝三原色构成的;
3.三原色决定了每个单位区域的颜色。
Retinex理论认为一张图像的颜色的由光照和物质本身共同决定(就如同白色物体在绿光下呈现绿色),即可将图像用函数S(x,y)表示,光照因素由L(x,y)表示,物质本身因素由R(x,y)来表示,即可视为:
两边取对数并简单变化可得:
如下图所示:
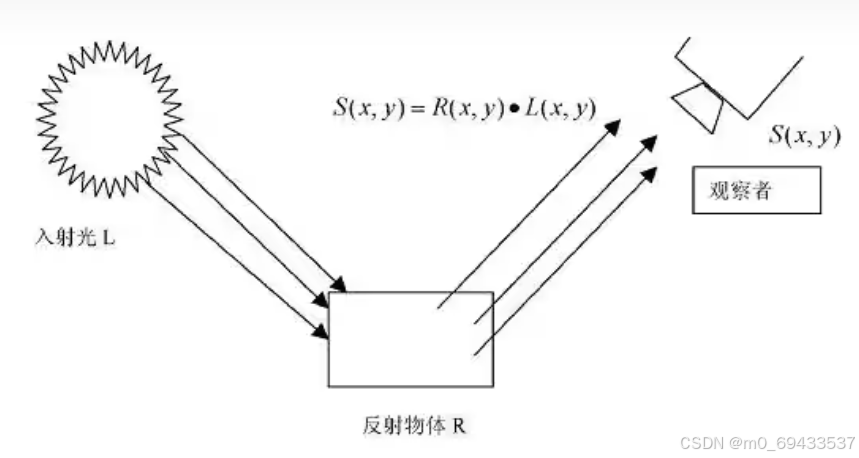
基于Retinex的图像增强算法均致力于去除光照因素,即L(x,y),如此便可获得物质本身的属性R(x,y),消除光照的影响,这也是为什么他可以用于低照度图像增强。
显然,这个假设合理且可被接受,但是我们怎么从一张图像中获得光照强度影响呢?这个问题至今依旧只能通过不同的模型近似求得。下面将介绍这几种模型。
二、SSR算法
SSR算法简单粗暴,即对图像进行高斯滤波,即是光照因素。乍一听,感觉这毫无道理。但是这是有解释的,即其认为光照因素的变化总是缓慢地,低通滤波可以过滤去高频信息(边界,纹理),而光照信息则会被保留,假设高斯滤波函数为F(x,y),即得到(*意为卷积):
这里有一个简单的对比表明高斯滤波为何可以滤出光照因素,滤波核越大图像越模糊,对于图像亮度极低时应当采用较大的核,这里核大小为201(可能过大),但可以看到,滤波后图像剩下的基本是光照部分:
 滤波之前原图
滤波之前原图
 滤波之后图像
滤波之后图像
其算法如下:
import numpy as np
import cv2
def replaceZeroes(data):
# 将图像中的0值,去除,因为对像素值取log的时候不能存在0值
# 这里可以将min_nonzero变为1,取图像中本来就有的像素值或许可以略微增加稳定性(我猜的)
min_nonzero = min(data[np.nonzero(data)])
data[data == 0] = min_nonzero
return data
def SSR(src_img, size):
L_blur = cv2.GaussianBlur(src_img, (size, size), 0)
img = replaceZeroes(src_img)
L_blur = replaceZeroes(L_blur)
# 这里除以255只是归一化,因为log函数只处理浮点数,没有什么特别意义,除以1.0也没影响
dst_Img = cv2.log(img/255.0)
dst_Lblur = cv2.log(L_blur/255.0)
log_R = cv2.subtract(dst_Img, dst_Lblur)
# 这是我参考的一个博主的写法,不知道为何要乘,注释掉,有待讨论
# dst_IxL = cv2.multiply(dst_Img, dst_Lblur)
# log_R = cv2.subtract(dst_Img, dst_IxL)
# 这是将log_R变化到0-255,而非直接取exp
dst_R1 = cv2.normalize(log_R, None, 0, 255, cv2.NORM_MINMAX)
log_uint8 = cv2.convertScaleAbs(dst_R1)
return log_uint8
if __name__ == '__main__':
img = r'C:\Users\omen\anaconda3\opencv\archive\Bicycle\2015_00010.jpg'
size = 201
src_img = cv2.imread(img)
b_gray, g_gray, r_gray = cv2.split(src_img)
b_gray1 = SSR(b_gray, size)
g_gray1 = SSR(g_gray, size)
r_gray1 = SSR(r_gray, size)
result = cv2.merge([b_gray1, g_gray1, r_gray1])
cv2.imshow('img', src_img)
cv2.imshow('result', result)
cv2.waitKey(0)这里有两个问题:首先,
# 这是将log_R变化到0-255,而非直接取exp
dst_R1 = cv2.normalize(log_R, None, 0, 255, cv2.NORM_MINMAX)这里为什么不直接对log_R取exp,得到R(x,y)。我认为是这样的:R(x,y)的值通常是0.0~1.0之间,0表示物体完全不反光,即绝对黑体;1表示物体绝对反光。我们也可以不用normalize函数,而是将取exp,得到R(x,y),后乘以255便可得完美图像。但是之前求光照因素并不是一个没有误差的办法,导致求出的R值不一定在0~1之间(有时甚至在十几,几十),直接乘以255会让图像失真严重,故大家一般都是用normalize函数。
然后是第二个问题,即
# 这是我参考的一个博主的写法,不知道为何要乘,注释掉,有待讨论
# dst_IxL = cv2.multiply(dst_Img, dst_Lblur)
# log_R = cv2.subtract(dst_Img, dst_IxL)这里我参考许多博主,他们都将高斯模糊后的图像和原图像相乘之后减,公式如下,这与原公式不符,但是如此得到的图像似乎效果也还不错。而且在高斯核较小的时候,如3,5时,乘之后再减的图像增强效果显著好于直接减的增强效果。
很多人疑惑这个乘法取消掉之后图像变得只有边界,难以区分哪个是对哪个是错,这让学习中多了许多困难,但这是由于高斯核设置的太小,对于较暗的图像将高斯核设置大一些没有这个乘法也可得到不错的增强图像。
但是这点我还不太理解为何要乘,似乎这个乘法可以对高斯核进行一些自适应调整。也希望有大佬可以不吝赐教,感激不尽。
三、MSR算法
理解了前面的内容,MSR算法就十分简单易懂了。之前提到,对图像进行高斯滤波的时候不同的高斯核会导致不同的结果,那高斯核咋选合适呢?MSR就着力于此,它使用K(一般取3)个高斯核进行滤波,获得K个图像,最后将他们以1/K的权重相加得到滤波图像。 也就是综合不同高斯核滤波的优点来增强图像喽。公式如下,其中w代表权重:
算法如下:
# MSR
import numpy as np
import cv2
def replaceZeroes(data):
min_nonzero = min(data[np.nonzero(data)])
data[data == 0] = min_nonzero
return data
def MSR(img, scales):
weight = 1 / 3.0
scales_size = len(scales)
h, w = img.shape[:2]
log_R = np.zeros((h, w), dtype=np.float32)
for i in range(scales_size):
img = replaceZeroes(img)
L_blur = cv2.GaussianBlur(img, (scales[i], scales[i]), 0)
L_blur = replaceZeroes(L_blur)
dst_Img = cv2.log(img / 255.0)
dst_Lblur = cv2.log(L_blur / 255.0)
# dst_Ixl = cv2.multiply(dst_Img, dst_Lblur)
log_R += weight * cv2.subtract(dst_Img, dst_Lblur)
dst_R = cv2.normalize(log_R, None, 0, 255, cv2.NORM_MINMAX)
log_uint8 = cv2.convertScaleAbs(dst_R)
return log_uint8
if __name__ == '__main__':
img = r'C:\Users\omen\anaconda3\opencv\archive\Bicycle\2015_00010.jpg'
scales = [101, 201, 301] # 可调整的位置
src_img = cv2.imread(img)
b_gray, g_gray, r_gray = cv2.split(src_img)
b_gray = MSR(b_gray, scales)
g_gray = MSR(g_gray, scales)
r_gray = MSR(r_gray, scales)
result = cv2.merge([b_gray, g_gray, r_gray])
cv2.imshow('Original Image', src_img)
cv2.imshow('Enhanced(MSR) Image', result)
cv2.waitKey(0)
cv2.destroyAllWindows()四、MSRCR算法
MSRCR算法也是基于MSR算法的改进,我们可以注意到之前的算法都是对R,G,B三色通道分别操作,最后再合成,而没有对颜色有特殊处理,MSRCR正是根据图像中本身不同的颜色占比,对不同颜色特殊处理,旨在恢复色彩。其公式如下所示:
其中β是增益常数;α是受控制的非线性强度。Si指的是每通道的像素值,指的是之前MSR算法求出的反射。这个公式大概意思就是说把这个像素中某个颜色占三个通道的比例乘以它本身的反射率,以此模拟真实颜色。其中的α,β都是经验参数。
算法如下:
import cv2
import numpy as np
def replaceZeroes(data):
min_nonzero = min(data[np.nonzero(data)])
data[data == 0] = min_nonzero
return data
def MSR(img, scales):
weight = 1 / 3.0
scales_size = len(scales)
h, w = img.shape[:2]
log_R = np.zeros((h, w), dtype=np.float32)
for i in range(scales_size):
img = replaceZeroes(img)
L_blur = cv2.GaussianBlur(img, (0, 0), scales[i])
L_blur = replaceZeroes(L_blur)
dst_Img = cv2.log(img / 255.0)
dst_Lblur = cv2.log(L_blur / 255.0)
retinex = cv2.subtract(dst_Img, dst_Lblur)
# dst_Ixl = cv2.multiply(dst_Img, dst_Lblur)
log_R += weight * retinex
# dst_R = cv2.normalize(log_R, None, 0, 255, cv2.NORM_MINMAX)
# log_uint8 = cv2.convertScaleAbs(dst_R)
return log_R
def MSRCR(img, alpha, beta):
img_sum = img[:, :, 0] + img[:, :, 1] + img[:, :, 2]
img_sum = replaceZeroes(img_sum) / 1.0
res = []
for j in range(3):
chance = img[:, :, j]
chance_msr = MSR(chance, scales=[15, 81, 151])
chance_msrcr = beta * (cv2.log(alpha * chance) - cv2.log(img_sum)) * chance_msr
res.append(chance_msrcr)
return res
img = cv2.imread(r"C:\Users\omen\anaconda3\opencv\archive\Bicycle\2015_00001.png")
cv2.imshow('img', img)
alpha = 125.0
beta = 46.0
res = MSRCR(img, alpha, beta)
res = cv2.merge([res[0], res[1], res[2]])
res1 = cv2.convertScaleAbs(cv2.normalize(res, None, 0, 255, cv2.NORM_MINMAX))
cv2.imshow('res', res1)
cv2.waitKey(0)整体只是在MSR算法上稍作修改,没有值得强调的地方。
五、结果展示
原图
SSR算法增强

MSR算法增强

MSRCR算法
六、总结
笔者也是刚开始学习图像处理方面,才疏学浅,所写代码,所阐述的理解难以避免有错漏之处,若有人发现问题还望不吝指导。同时推荐以下几篇文章都讲的很好:
【低照度图像增强系列(2)】Retinex(SSR/MSR/MSRCR)算法详解与代码实现_ssr低光增强算法原理-CSDN博客
Retinex图像增强算法(SSR, MSR, MSRCR)详解及其OpenCV源码_msrcr算法原理-CSDN博客

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









