






代码链接附上
我之前部署过两个TTS,ASR是我第一次接触,所以想写文记录一下,和之前的TTS不同的是FunASR没有webui,只有api的调用,所以本地部署的时候有一点手足无措。因此进行记录。话不多说,现在开始。
1. 克隆仓促至本地:
在本地储存位置打开git bash:
git clone https://github.com/modelscope/FunASR.git2. 创建新环境:
conda create -n funasr python=3.9
conda activate funasr
conda install pytorch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 pytorch-cuda=11.8 -c pytorch -c nvidia
建议在安装torch的时候使用pip命令,conda命令一般都安不上。
pip install torch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 --index-url https://download.pytorch.org/whl/cu1183. 安装funasr
pip install -U funasr4. 使用预训练模型,这一步有两个方式,一是在每次运行脚本的时候让其下载模型,二是直接下载预训练模型在本地调用。我在本地运行的时候是使用的前者。因此需要安装modelscope与huggingface_hub。
pip install -U modelscope huggingface huggingface_hub
5. 快速开始
(1)命令行开始
funasr ++model=paraformer-zh ++punc_model="ct-punc" ++input="example/asr_example_en.wav"其中,input是输入的音频路径,默认是根据提供的模型目录,自动从ModelScope平台下载所需的模型和示例数据。但是仓库中的原命令是跑不通的,因此我将input转化为本地路径,就可以了。
(2)脚本
新建Python文件运行下列代码,同样,我将音频文件下载到本地调用。
from funasr import AutoModel
from funasr.utils.postprocess_utils import rich_transcription_postprocess
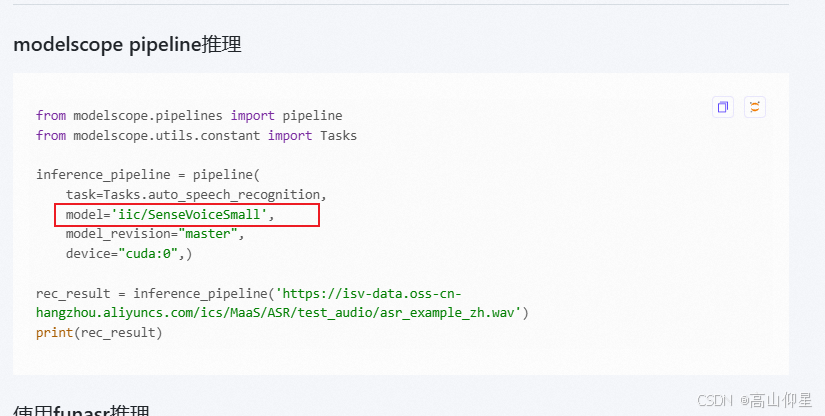
model_dir = "iic/SenseVoiceSmall"
model = AutoModel(
model=model_dir,
vad_model="fsmn-vad",
vad_kwargs={"max_single_segment_time": 30000},
device="cuda:0",
)
# en
res = model.generate(
input=f"example/asr_example_en.wav",
cache={},
language="auto", # "zn", "en", "yue", "ja", "ko", "nospeech"
use_itn=True,
batch_size_s=60,
merge_vad=True, #
merge_length_s=15,
)
text = rich_transcription_postprocess(res[0]["text"])
print(text)input设置为自己的本地路径,就可成功运行。
6 流式输出
上面是非流式输出的实现,下面是流式输出的实现。
(a)脚本
from funasr import AutoModel
chunk_size = [0, 10, 5] #[0, 10, 5] 600ms, [0, 8, 4] 480ms
encoder_chunk_look_back = 4 #number of chunks to lookback for encoder self-attention
decoder_chunk_look_back = 1 #number of encoder chunks to lookback for decoder cross-attention
model = AutoModel(model='iic/SenseVoiceSmall')
import soundfile
import os
wav_file = "example/asr_example.wav"
speech, sample_rate = soundfile.read(wav_file)
chunk_stride = chunk_size[1] * 960 # 600ms
cache = {}
total_chunk_num = int(len((speech)-1)/chunk_stride+1)
for i in range(total_chunk_num):
speech_chunk = speech[i*chunk_stride:(i+1)*chunk_stride]
is_final = i == total_chunk_num - 1
res = model.generate(input=speech_chunk, cache=cache, is_final=is_final, chunk_size=chunk_size, encoder_chunk_look_back=encoder_chunk_look_back, decoder_chunk_look_back=decoder_chunk_look_back)
print(res)其中,model = AutoModel(model='iic/SenseVoiceSmall') 和 wav_file = "example/asr_example.wav"分别为模型和输入的路径,如果需要换输入音频就直接改为自己音频的路径,若需要换个模型看效果,则需要在funasr的github中进入模型仓库-modelscope中查看路径。因为每次运行都是从modelscope上下载模型。

剩下的一些api和docker流程以及模型用法我会慢慢全部更新完成。
7 服务端客户端的运行
这里我测试的是runtime\python\websocket中的funasr_wss_server.py和funasr_wss_client.py的运行。我在windows中运行服务端代码的时候没有运行成功,错误信息:RuntimeError: no running event loop
表明 asyncio.get_running_loop() 失败了,通常是因为当前环境下 asyncio 没有正确启动。Windows 下 asyncio 事件循环机制可能导致此问题。因此需要修改后面的代码,完整代码如下:
import asyncio
import json
import websockets
import time
import logging
import tracemalloc
import numpy as np
import argparse
import ssl
parser = argparse.ArgumentParser()
parser.add_argument(
"--host", type=str, default="0.0.0.0", required=False, help="host ip, localhost, 0.0.0.0"
)
parser.add_argument("--port", type=int, default=10095, required=False, help="grpc server port")
parser.add_argument(
"--asr_model",
type=str,
default="iic/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch",
help="model from modelscope",
)
parser.add_argument("--asr_model_revision", type=str, default="v2.0.4", help="")
parser.add_argument(
"--asr_model_online",
type=str,
default="iic/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-online",
help="model from modelscope",
)
parser.add_argument("--asr_model_online_revision", type=str, default="v2.0.4", help="")
parser.add_argument(
"--vad_model",
type=str,
default="iic/speech_fsmn_vad_zh-cn-16k-common-pytorch",
help="model from modelscope",
)
parser.add_argument("--vad_model_revision", type=str, default="v2.0.4", help="")
parser.add_argument(
"--punc_model",
type=str,
default="iic/punc_ct-transformer_zh-cn-common-vad_realtime-vocab272727",
help="model from modelscope",
)
parser.add_argument("--punc_model_revision", type=str, default="v2.0.4", help="")
parser.add_argument("--ngpu", type=int, default=1, help="0 for cpu, 1 for gpu")
parser.add_argument("--device", type=str, default="cuda", help="cuda, cpu")
parser.add_argument("--ncpu", type=int, default=4, help="cpu cores")
parser.add_argument(
"--certfile",
type=str,
default="../../ssl_key/server.crt",
required=False,
help="certfile for ssl",
)
parser.add_argument(
"--keyfile",
type=str,
default="../../ssl_key/server.key",
required=False,
help="keyfile for ssl",
)
args = parser.parse_args()
websocket_users = set()
print("model loading")
from funasr import AutoModel
# asr
model_asr = AutoModel(
model=args.asr_model,
model_revision=args.asr_model_revision,
ngpu=args.ngpu,
ncpu=args.ncpu,
device=args.device,
disable_pbar=True,
disable_log=True,
)
# asr
model_asr_streaming = AutoModel(
model=args.asr_model_online,
model_revision=args.asr_model_online_revision,
ngpu=args.ngpu,
ncpu=args.ncpu,
device=args.device,
disable_pbar=True,
disable_log=True,
)
# vad
model_vad = AutoModel(
model=args.vad_model,
model_revision=args.vad_model_revision,
ngpu=args.ngpu,
ncpu=args.ncpu,
device=args.device,
disable_pbar=True,
disable_log=True,
# chunk_size=60,
)
if args.punc_model != "":
model_punc = AutoModel(
model=args.punc_model,
model_revision=args.punc_model_revision,
ngpu=args.ngpu,
ncpu=args.ncpu,
device=args.device,
disable_pbar=True,
disable_log=True,
)
else:
model_punc = None
print("model loaded! only support one client at the same time now!!!!")
async def ws_reset(websocket):
print("ws reset now, total num is ", len(websocket_users))
websocket.status_dict_asr_online["cache"] = {}
websocket.status_dict_asr_online["is_final"] = True
websocket.status_dict_vad["cache"] = {}
websocket.status_dict_vad["is_final"] = True
websocket.status_dict_punc["cache"] = {}
await websocket.close()
async def clear_websocket():
for websocket in websocket_users:
await ws_reset(websocket)
websocket_users.clear()
async def ws_serve(websocket, path="dafault_path"):
frames = []
frames_asr = []
frames_asr_online = []
global websocket_users
# await clear_websocket()
websocket_users.add(websocket)
websocket.status_dict_asr = {}
websocket.status_dict_asr_online = {"cache": {}, "is_final": False}
websocket.status_dict_vad = {"cache": {}, "is_final": False}
websocket.status_dict_punc = {"cache": {}}
websocket.chunk_interval = 10
websocket.vad_pre_idx = 0
speech_start = False
speech_end_i = -1
websocket.wav_name = "microphone"
websocket.mode = "2pass"
print("new user connected", flush=True)
try:
async for message in websocket:
if isinstance(message, str):
messagejson = json.loads(message)
if "is_speaking" in messagejson:
websocket.is_speaking = messagejson["is_speaking"]
websocket.status_dict_asr_online["is_final"] = not websocket.is_speaking
if "chunk_interval" in messagejson:
websocket.chunk_interval = messagejson["chunk_interval"]
if "wav_name" in messagejson:
websocket.wav_name = messagejson.get("wav_name")
if "chunk_size" in messagejson:
chunk_size = messagejson["chunk_size"]
if isinstance(chunk_size, str):
chunk_size = chunk_size.split(",")
websocket.status_dict_asr_online["chunk_size"] = [int(x) for x in chunk_size]
if "encoder_chunk_look_back" in messagejson:
websocket.status_dict_asr_online["encoder_chunk_look_back"] = messagejson[
"encoder_chunk_look_back"
]
if "decoder_chunk_look_back" in messagejson:
websocket.status_dict_asr_online["decoder_chunk_look_back"] = messagejson[
"decoder_chunk_look_back"
]
if "hotword" in messagejson:
websocket.status_dict_asr["hotword"] = messagejson["hotwords"]
if "mode" in messagejson:
websocket.mode = messagejson["mode"]
websocket.status_dict_vad["chunk_size"] = int(
websocket.status_dict_asr_online["chunk_size"][1] * 60 / websocket.chunk_interval
)
if len(frames_asr_online) > 0 or len(frames_asr) >= 0 or not isinstance(message, str):
if not isinstance(message, str):
frames.append(message)
duration_ms = len(message) // 32
websocket.vad_pre_idx += duration_ms
# asr online
frames_asr_online.append(message)
websocket.status_dict_asr_online["is_final"] = speech_end_i != -1
if (
len(frames_asr_online) % websocket.chunk_interval == 0
or websocket.status_dict_asr_online["is_final"]
):
if websocket.mode == "2pass" or websocket.mode == "online":
audio_in = b"".join(frames_asr_online)
try:
await async_asr_online(websocket, audio_in)
except:
print(f"error in asr streaming, {websocket.status_dict_asr_online}")
frames_asr_online = []
if speech_start:
frames_asr.append(message)
# vad online
try:
speech_start_i, speech_end_i = await async_vad(websocket, message)
except:
print("error in vad")
if speech_start_i != -1:
speech_start = True
beg_bias = (websocket.vad_pre_idx - speech_start_i) // duration_ms
frames_pre = frames[-beg_bias:]
frames_asr = []
frames_asr.extend(frames_pre)
# asr punc offline
if speech_end_i != -1 or not websocket.is_speaking:
# print("vad end point")
if websocket.mode == "2pass" or websocket.mode == "offline":
audio_in = b"".join(frames_asr)
try:
await async_asr(websocket, audio_in)
except:
print("error in asr offline")
frames_asr = []
speech_start = False
frames_asr_online = []
websocket.status_dict_asr_online["cache"] = {}
if not websocket.is_speaking:
websocket.vad_pre_idx = 0
frames = []
websocket.status_dict_vad["cache"] = {}
else:
frames = frames[-20:]
except websockets.ConnectionClosed:
print("ConnectionClosed...", websocket_users, flush=True)
await ws_reset(websocket)
websocket_users.remove(websocket)
except websockets.InvalidState:
print("InvalidState...")
except Exception as e:
print("Exception:", e)
async def async_vad(websocket, audio_in):
segments_result = model_vad.generate(input=audio_in, **websocket.status_dict_vad)[0]["value"]
# print(segments_result)
speech_start = -1
speech_end = -1
if len(segments_result) == 0 or len(segments_result) > 1:
return speech_start, speech_end
if segments_result[0][0] != -1:
speech_start = segments_result[0][0]
if segments_result[0][1] != -1:
speech_end = segments_result[0][1]
return speech_start, speech_end
async def async_asr(websocket, audio_in):
if len(audio_in) > 0:
# print(len(audio_in))
rec_result = model_asr.generate(input=audio_in, **websocket.status_dict_asr)[0]
# print("offline_asr, ", rec_result)
if model_punc is not None and len(rec_result["text"]) > 0:
# print("offline, before punc", rec_result, "cache", websocket.status_dict_punc)
rec_result = model_punc.generate(
input=rec_result["text"], **websocket.status_dict_punc
)[0]
# print("offline, after punc", rec_result)
if len(rec_result["text"]) > 0:
# print("offline", rec_result)
mode = "2pass-offline" if "2pass" in websocket.mode else websocket.mode
message = json.dumps(
{
"mode": mode,
"text": rec_result["text"],
"wav_name": websocket.wav_name,
"is_final": websocket.is_speaking,
}
)
await websocket.send(message)
else:
mode = "2pass-offline" if "2pass" in websocket.mode else websocket.mode
message = json.dumps(
{
"mode": mode,
"text": "",
"wav_name": websocket.wav_name,
"is_final": websocket.is_speaking,
}
)
await websocket.send(message)
async def async_asr_online(websocket, audio_in):
if len(audio_in) > 0:
# print(websocket.status_dict_asr_online.get("is_final", False))
rec_result = model_asr_streaming.generate(
input=audio_in, **websocket.status_dict_asr_online
)[0]
# print("online, ", rec_result)
if websocket.mode == "2pass" and websocket.status_dict_asr_online.get("is_final", False):
return
# websocket.status_dict_asr_online["cache"] = dict()
if len(rec_result["text"]):
mode = "2pass-online" if "2pass" in websocket.mode else websocket.mode
message = json.dumps(
{
"mode": mode,
"text": rec_result["text"],
"wav_name": websocket.wav_name,
"is_final": websocket.is_speaking,
}
)
await websocket.send(message)
async def main():
if len(args.certfile) > 0:
# 加载SSL证书
ssl_context = ssl.SSLContext(ssl.PROTOCOL_TLS_SERVER)
ssl_cert = args.certfile
ssl_key = args.keyfile
ssl_context.load_cert_chain(ssl_cert, keyfile=ssl_key)
server = await websockets.serve(
ws_serve,
args.host,
args.port,
subprotocols=["binary"],
ping_interval=None,
ssl=ssl_context
)
else:
# 无SSL
server = await websockets.serve(
ws_serve,
args.host,
args.port,
subprotocols=["binary"],
ping_interval=None,
max_queue=10
)
print(f"Server started on {args.host}:{args.port}")
await server.wait_closed()
if __name__ == "__main__":
asyncio.run(main()) # 统一入口在修改最后的运行代码之后,服务端运行成功,在运行客户端的时候又报了错:ConnectionClosedError: received 1011 (internal error); then sent 1011 (internal error) end
此时服务端报错:TypeError: ws_serve() missing 1 required positional argument: 'path' ERROR:websockets.server:connection handler failed Traceback (most recent call last): File "D:\anaconda3\envs\funasr\lib\site-packages\websockets\asyncio\server.py", line 374, in conn_handler await self.handler(connection) TypeError: ws_serve() missing 1 required positional argument: 'path'
说明 websockets.serve() 期望 ws_serve 这个函数接受两个参数(websocket, path),但ws_serve 可能只定义了一个参数(websocket)。所以在服务端代码中修改了
async def ws_serve(websocket, path="default_path"):
就可运行成功,成功之后就可连接电脑麦克风进行实时语音转文字。

















 3047
3047

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









