






目录
一、项目背景和目的
在医疗和食品行业,口罩佩戴是维护卫生规范的重要要求。口罩佩戴目标检测系统系统可以用于确保员工和工作人员在工作时正确佩戴口罩,减少交叉污染的风险。
2019新型冠状病毒(2019-nCoV)突袭中国武汉,感染人数感染危害之震惊全球!在党和国家的强有力和正确的领导下,全国人民众志成城,团结一致战胜疫情狙击战。平台上线了口罩识别检测系统,实现实时检测未佩戴口人员并及时预警, 为构建人们安全架起一道安全防线网,为阻击和防卫疫情尽一份力。
二、算法
所以口罩识别是一项重要的任务。YOLOv8是前沿的目标检测技术,它基于先前 YOLO 版本在目标检测任务上的成功,进一步提升性能和灵活性。
我们将使用YOLOv8训练口罩数据集,完成一个多目标检测实战项目。可实时检测图像标志,并提供可视化演示界面 。
YOLOv8的网络结构图:
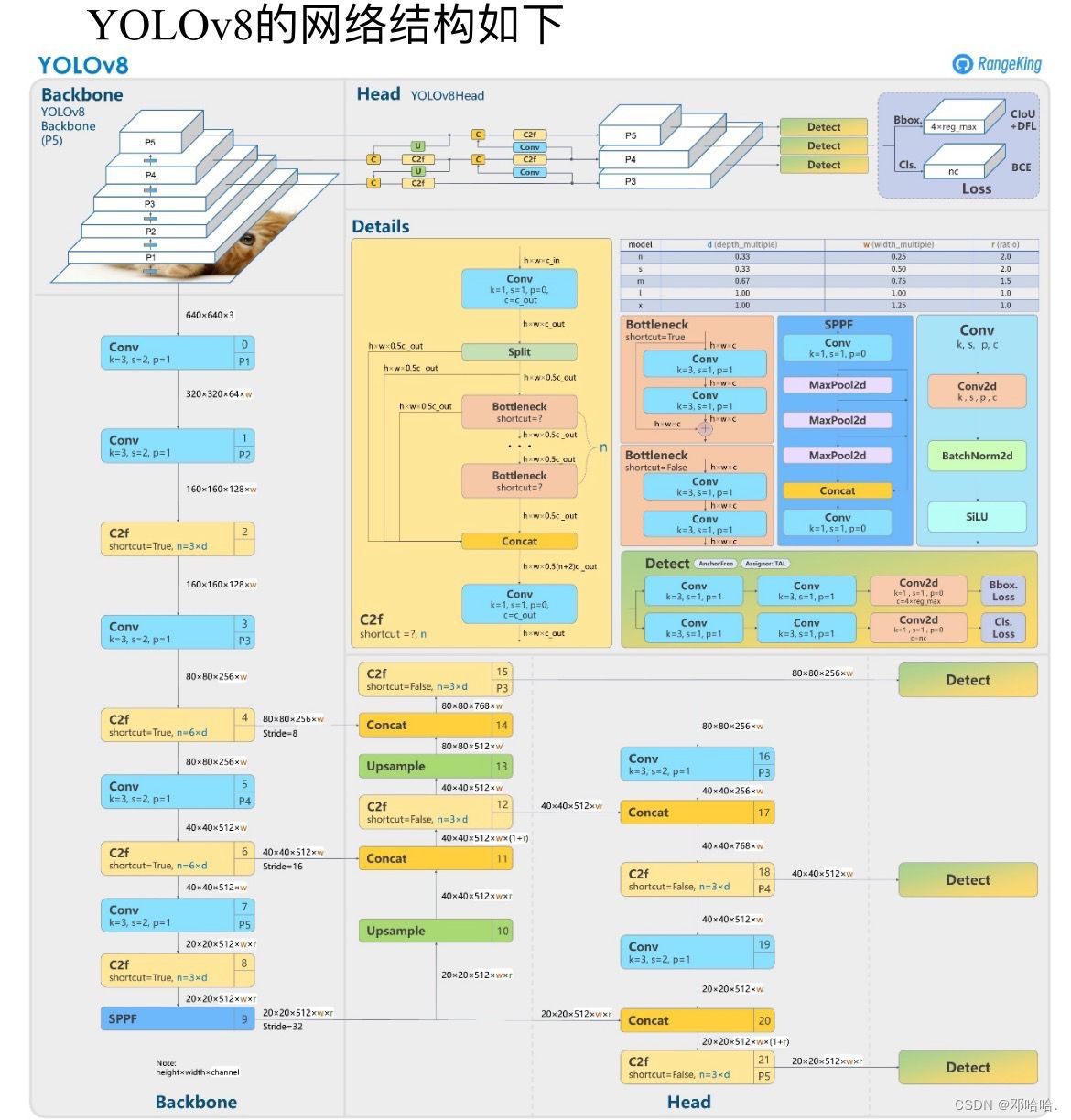
三、项目实现过程:
1、YOLOv8环境配置:
首先去自己的anaconda的安装的envs(虚拟环境),在导航栏输入cmd,进入命令窗口。
确保python>=3.7;CUDA>=10.1,PYtorch>=1.7
(1)、创建一个虚拟环境
conda create -n torch1.12.1 python=3.8.8
(2)、激活刚建的虚拟环境
activate torch1.12.1
(3)、到官方网站下载yolo模型 ,下载好后解压,里面有个文件requirements.txt
activate torch1.12.1 安装一个整体包:
pip install -r .\requirements.txt
直接按照路径会有问题,找到自己 requirements.txt 文件路径,我这里是pip install -r D:\ultralytics-main\ultralytics-main\requirements.txt
(4)、然后安装ultralytics ,这是必须的。可以用镜像地址。
pip install ultralytics -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
(5)、安装下载好包,接下来就是验证:
yolo predict model=yolov8n.pt source='ultralytics/assets/bus.jpg' show=True save=True
四、关于数据集
- 在互联网上搜索并下载了人物和口罩佩戴的图片,然后进行了筛选,确保每张图片包含至少一个口罩目标,这一步骤有助于确保我们的数据集具有高质量的标注。最后总共得到了6900张图片
-
划分数据集
- 标签类别包含两类no-mask、mask(分别为没有佩戴口罩与佩戴口罩的人群)
-
train: D:\nrr\Dataset\images\train val: D:\nrr\Dataset\images\val test: D:\nrr\Dataset\images\test nc: 2 names: ['no-mask','mask'] -
加载模型
- 创建main.py文件并调用,性能最佳的模型被保存为 "best.pt",路径在weights文件夹中。
-
from ultralytics import YOLO if __name__ == '__main__': # 直接使用预训练权重或yaml文件创建模型 model = YOLO('yolov8n.pt') model.train(**{'cfg': 'ultralytics/cfg/default.yaml', 'data': r"D:\nrr\Dataset\data_2class.yaml"}) 模型推理 model = YOLO('runs/detect/yolov8n_exp/weights/best.pt') model.predict(source='dataset/images/test', **{'save': True}) -
训练结果如图
-
如图可以看到模型训练时,可以准确的识别佩戴口罩与不佩戴口罩
-

五、训练效果
如图显示,得到的map@0.5性能指标为0.991。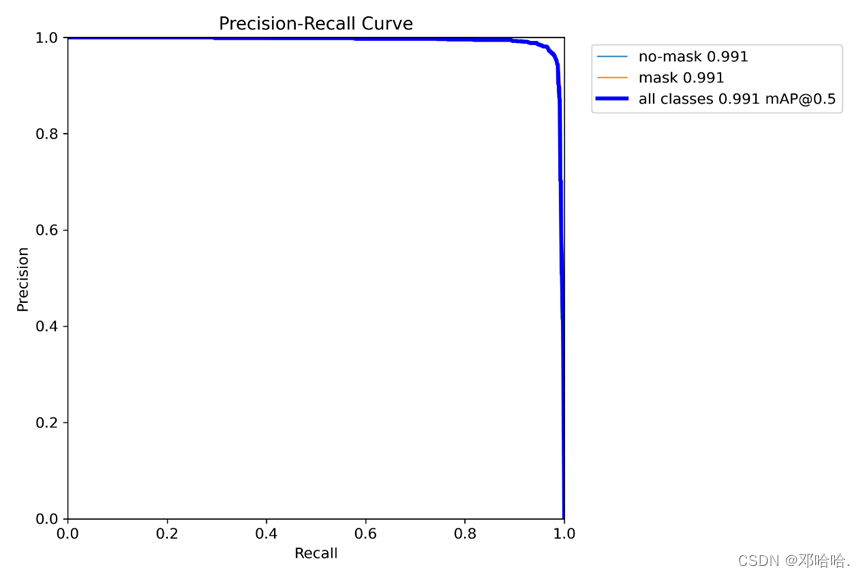
box_loss(边界框损失):边界框损失是目标检测任务中的一个损失函数,它度量了模型在预测目标边界框位置方面的误差。较低的边界框损失通常表示模型更好地定位目标。
cls_loss(类别损失):类别损失是目标检测任务中的另一个损失函数,它度量了模型在预测目标类别方面的误差。较低的类别损失通常表示模型更好地识别目标的类别。
dfl_loss(特征图级别的损失):YOLOv8 中的 dfl_loss 可能是指特征图级别的损失,用于优化特征图的相关性,以提高目标检测性能。
Precision (P):精确度是指模型预测的正类别目标中有多少是真正的正类别目标。它表示模型在识别目标时的准确性。计算公式为:Precision = TP / (TP + FP),其中 TP 表示真正的正类别目标,FP 表示模型错误地预测为正类别的目标。
Recall (R):召回率是指在所有真正的正类别目标中,模型成功检测到多少。它表示模型在识别正类别目标时的覆盖范围。计算公式为:Recall = TP / (TP + FN),其中 TP 表示真正的正类别目标,FN 表示模型未能检测到的正类别目标。
mAP50 (平均精确度@0.5 IoU):mAP50 是指模型在测试数据集上的平均精确度,当 IoU 阈值为 0.5 时的表现。它通过计算不同类别的精确度并取平均来评估模型在目标检测任务中的性能。通常,mAP50 越高表示模型在识别目标时的准确性越高。
mAP50-95 (平均精确度@0.5-0.95 IoU):mAP50-95 是指模型在测试数据集上的平均精确度,考虑了 IoU 阈值从 0.5 到 0.95 的范围。它更全面地评估模型的性能,因为不同任务可能要求不同 IoU 阈值的精确度。
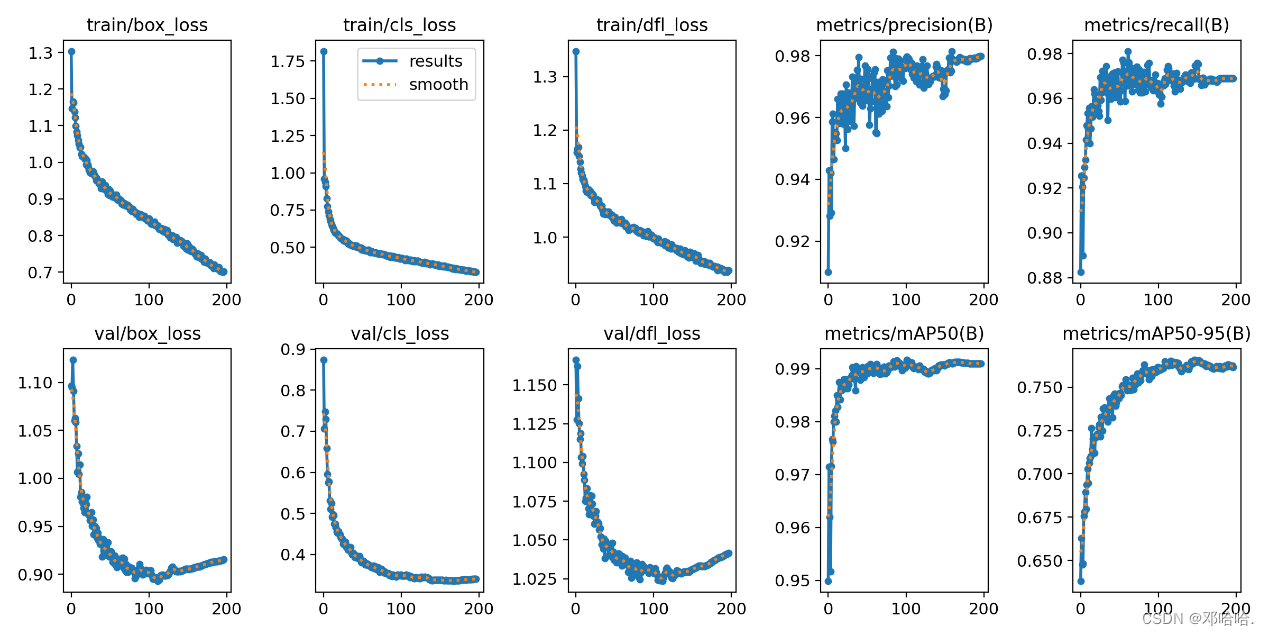
图5.2 results图
但是比较训练集的损失和验证集的损失曲线,发现训练集的损失曲线一直下降,而验证集的损失曲线后面呈上升状态,说明模型训练过程中发生了过拟合。
可以考虑使用以下方法缓解或者解决过拟合:
(1)增加数据量:过拟合可能是由于数据量不足导致的,因此可以增加训练数据量,以减少过拟合的风险。
(2)减少特征维度:通过特征选择、降维等方法,减少模型的特征维度,可以减少模型对于噪声的敏感度,从而降低过拟合的风险。4.增加噪声:增加一些噪声可以使得模型更加鲁棒,从而减少过拟合的风险。
(3)早停法:在训练过程中,通过监控模型在验证集上的性能,当模型在验证集上的性能开始下降时,停止训练,可以有效避免过拟合。6. Dropout:在神经网络中,通过随机丢弃一些神经元,可以有效地减少模型的复杂度,从而降低过拟合的风险。
(4)数据增强:通过对数据进行一些变换,比如旋转、平移、缩放等,可以增加训练数据的多样性,从而减少过拟合的风险。
六、训练结果分析
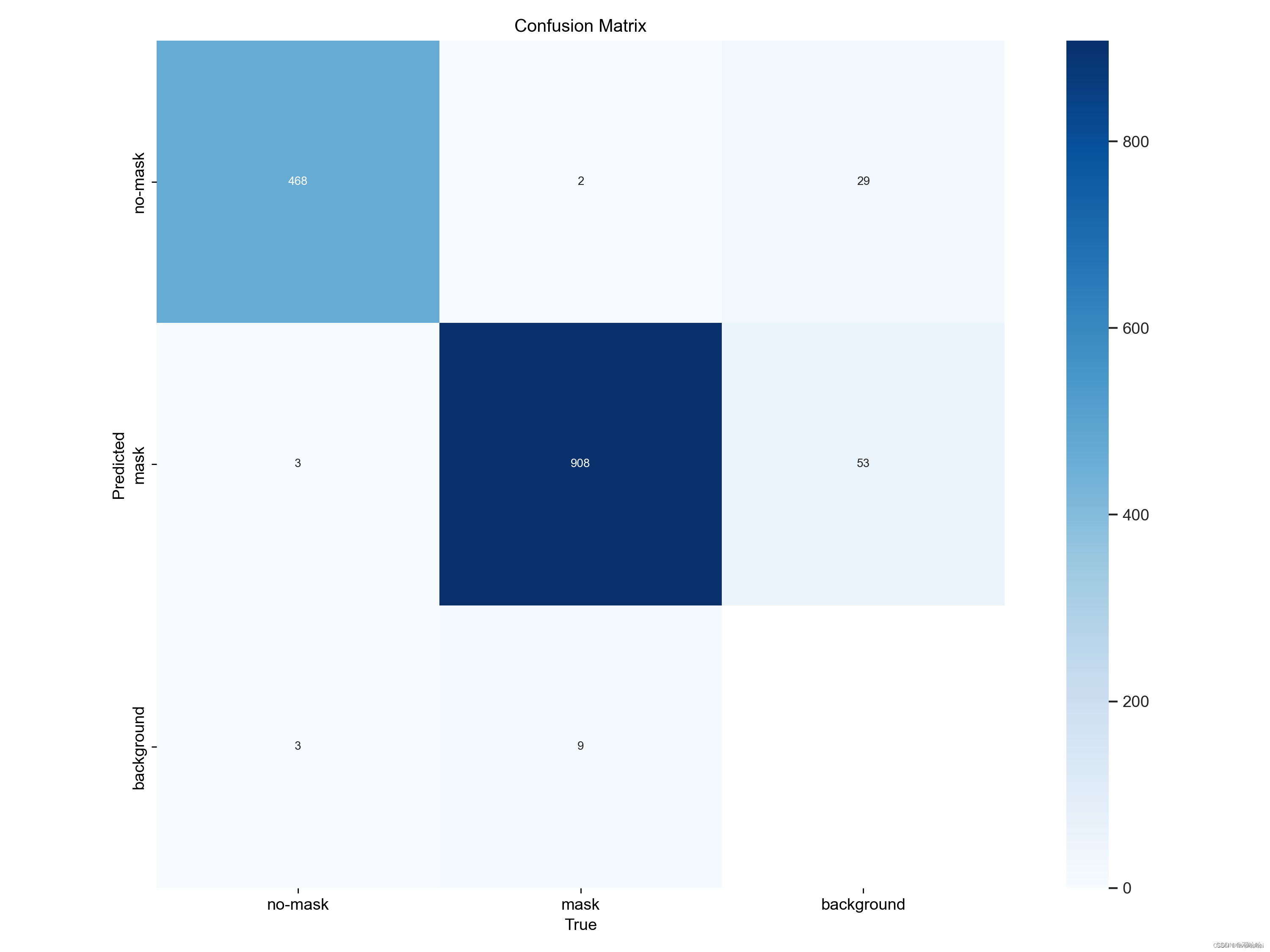
confusion_matrix.png :列代表预测的类别,行代表实际的类别。其对角线上的值表示预测正确的数量比例,非对角线元素则是预测错误的部分。混淆矩阵的对角线值越高越好,这表明在此训练中有着较高的正确率。
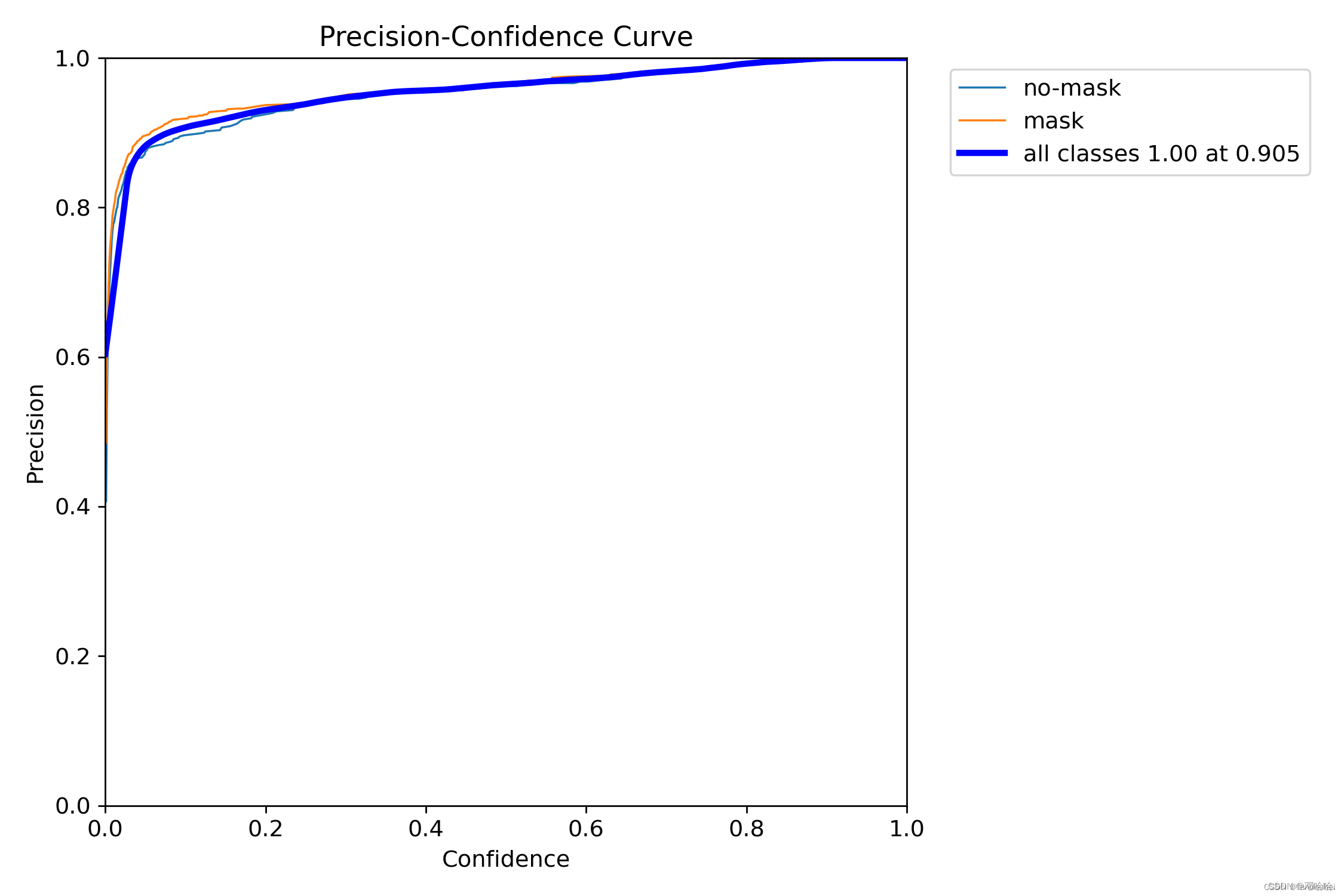
P_curve.png(单一类准确率)
准确率precision和置信度confidence的关系图
意思就是,当我设置置信度为某一数值的时候,各个类别识别的准确率。两个类别所识别的精确度。在不同类别上都有较高的精确度。我们的模型在验证集上的均值平均准确率为0.905。
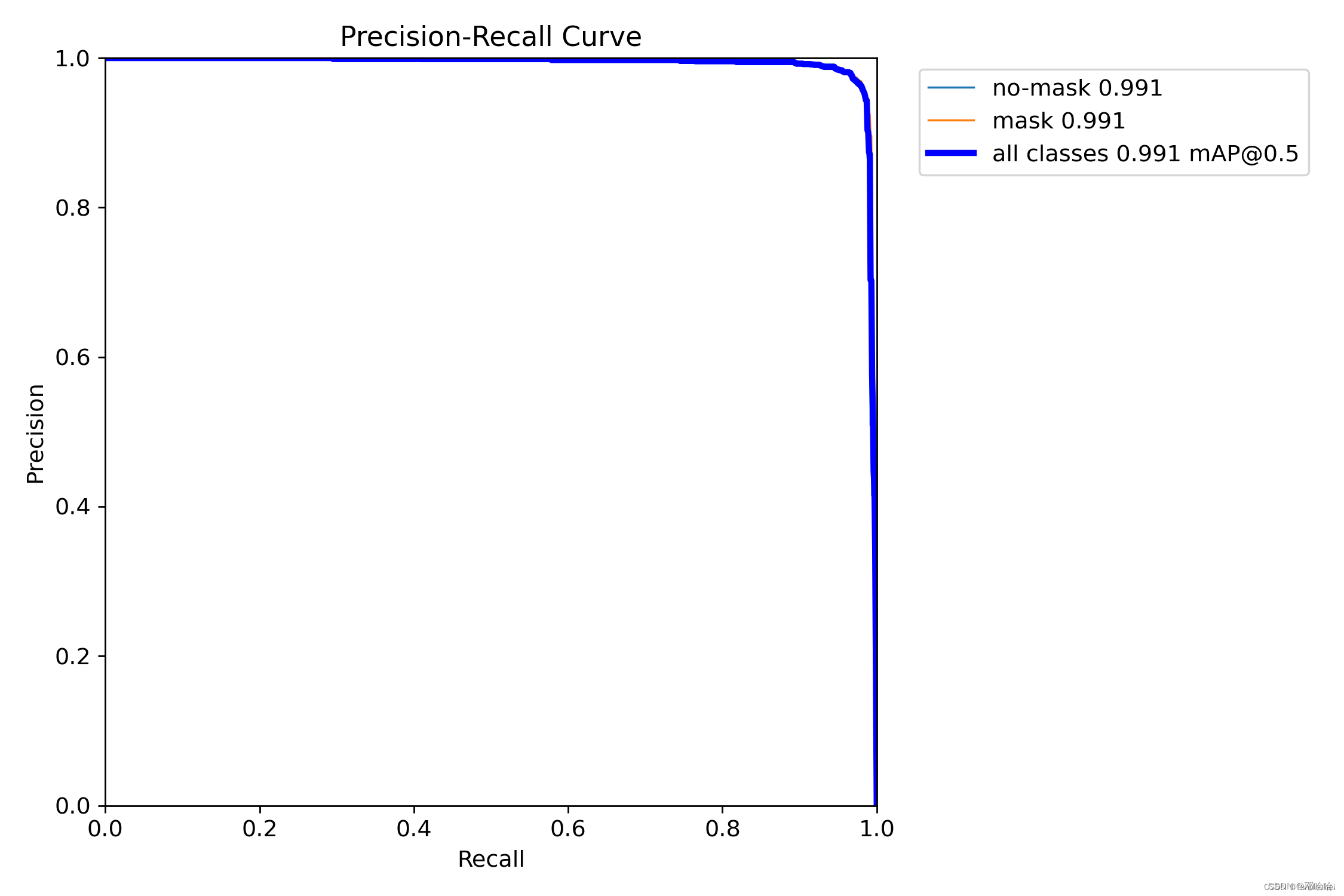
PR_curve.png(精确率和召回率的关系图)
mAP 是 Mean Average Precision 的缩写,即 均值平均精度。可以看出精确率与召回率成正比关系。如图显示,得到的map@0.5性能指标为0.991。
七、代码运行过程:
八、总结
在项目中,我学到了许多有关目标检测和深度学习的重要知识和经验。通过这次项目,我深入了解了目标检测领域的主要算法,特别是YOLOv8。学习了如何使用现代深度学习技术来构建高性能的目标检测系统;学习了如何收集、标注和预处理图像数据,以创建适用于训练的数据集;了解了模型训练的基本原理,包括损失函数、优化器和迭代过程;还学会了如何选择和调整超参数以优化模型性能;此外,学习了如何使用不同的性能指标(如Precision、Recall、mAP等)来评估模型的性能。















 455
455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}