






一 第一天 快速入门
import mindspore
from mindspore import nn
from mindspore.dataset import vision, transforms
from mindspore.dataset import MnistDataset
处理数据集
# MindSpore提供基于Pipeline的[数据引擎](https://www.mindspore.cn/docs/zh-CN/r2.3/design/data_engine.html),通过[数据集(Dataset)](https://www.mindspore.cn/tutorials/zh-CN/r2.3/beginner/dataset.html)和[数据变换(Transforms)](https://www.mindspore.cn/tutorials/zh-CN/r2.3/beginner/transforms.html)实现高效的数据预处理。在本教程中,我们使用Mnist数据集,自动下载完成后,使用`mindspore.dataset`提供的数据变换进行预处理。
# > 本章节中的示例代码依赖`download`,可使用命令`pip install download`安装。如本文档以Notebook运行时,完成安装后需要重启kernel才能执行后续代码。
# Download data from open datasets
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)
数据集目录结构如下:
# MNIST_Data
# └── train
# ├── train-images-idx3-ubyte (60000个训练图片)
# ├── train-labels-idx1-ubyte (60000个训练标签)
# └── test
# ├── t10k-images-idx3-ubyte (10000个测试图片)
# ├── t10k-labels-idx1-ubyte (10000个测试标签)
# 数据下载完成后,获得数据集对象。
In[3]:
train_dataset = MnistDataset('MNIST_Data/train')
test_dataset = MnistDataset('MNIST_Data/test')
# 打印数据集中包含的数据列名,用于dataset的预处理。
In[4]:
print(train_dataset.get_col_names())
# MindSpore的dataset使用数据处理流水线(Data Processing Pipeline),需指定map、batch、shuffle等操作。这里我们使用map对图像数据及标签进行变换处理,将输入的图像缩放为1/255,根据均值0.1307和标准差值0.3081进行归一化处理,然后将处理好的数据集打包为大小为64的batch。
In[5]:
def datapipe(dataset, batch_size):
image_transforms = [
vision.Rescale(1.0 / 255.0, 0),
vision.Normalize(mean=(0.1307,), std=(0.3081,)),
vision.HWC2CHW()
]
label_transform = transforms.TypeCast(mindspore.int32)
dataset = dataset.map(image_transforms, 'image')
dataset = dataset.map(label_transform, 'label')
dataset = dataset.batch(batch_size)
return dataset
In[6]:
# Map vision transforms and batch dataset
train_dataset = datapipe(train_dataset, 64)
test_dataset = datapipe(test_dataset, 64)
# 可使用[create_tuple_iterator](https://www.mindspore.cn/docs/zh-CN/r2.3/api_python/dataset/dataset_method/iterator/mindspore.dataset.Dataset.create_tuple_iterator.html) 或[create_dict_iterator](https://www.mindspore.cn/docs/zh-CN/r2.3/api_python/dataset/dataset_method/iterator/mindspore.dataset.Dataset.create_dict_iterator.html)对数据集进行迭代访问,查看数据和标签的shape和datatype。
In[7]:
for image, label in test_dataset.create_tuple_iterator():
print(f"Shape of image [N, C, H, W]: {image.shape} {image.dtype}")
print(f"Shape of label: {label.shape} {label.dtype}")
break
In[8]:
for data in test_dataset.create_dict_iterator():
print(f"Shape of image [N, C, H, W]: {data['image'].shape} {data['image'].dtype}")
print(f"Shape of label: {data['label'].shape} {data['label'].dtype}")
break
网络构建
# `mindspore.nn`类是构建所有网络的基类,也是网络的基本单元。当用户需要自定义网络时,可以继承`nn.Cell`类,并重写`__init__`方法和`construct`方法。`__init__`包含所有网络层的定义,`construct`中包含数据([Tensor](https://www.mindspore.cn/tutorials/zh-CN/r2.3/beginner/tensor.html))的变换过程。
In[9]:
# Define model
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.dense_relu_sequential = nn.SequentialCell(
nn.Dense(28*28, 512),
nn.ReLU(),
nn.Dense(512, 512),
nn.ReLU(),
nn.Dense(512, 10)
)
def construct(self, x):
x = self.flatten(x)
logits = self.dense_relu_sequential(x)
return logits
model = Network()
print(model)
模型训练
在模型训练中,一个完整的训练过程(step)需要实现以下三步:
1. **正向计算**:模型预测结果(logits),并与正确标签(label)求预测损失(loss)。
2. **反向传播**:利用自动微分机制,自动求模型参数(parameters)对于loss的梯度(gradients)。
3. **参数优化**:将梯度更新到参数上。
MindSpore使用函数式自动微分机制,因此针对上述步骤需要实现:
1. 定义正向计算函数。
2. 使用[value_and_grad](https://www.mindspore.cn/docs/zh-CN/r2.3/api_python/mindspore/mindspore.value_and_grad.html)通过函数变换获得梯度计算函数。
3. 定义训练函数,使用[set_train](https://www.mindspore.cn/docs/zh-CN/r2.3/api_python/nn/mindspore.nn.Cell.html#mindspore.nn.Cell.set_train)设置为训练模式,执行正向计算、反向传播和参数优化。
In[11]:
Instantiate loss function and optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = nn.SGD(model.trainable_params(), 1e-2)
1. Define forward function
def forward_fn(data, label):
logits = model(data)
loss = loss_fn(logits, label)
return loss, logits
2. Get gradient function
grad_fn = mindspore.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=True)
3. Define function of one-step training
def train_step(data, label):
(loss, _), grads = grad_fn(data, label)
optimizer(grads)
return loss
def train(model, dataset):
size = dataset.get_dataset_size()
model.set_train()
for batch, (data, label) in enumerate(dataset.create_tuple_iterator()):
loss = train_step(data, label)if batch % 100 == 0:
loss, current = loss.asnumpy(), batch
print(f"loss: {loss:>7f} [{current:>3d}/{size:>3d}]")
除训练外,我们定义测试函数,用来评估模型的性能。
# In[12]:
def test(model, dataset, loss_fn):
num_batches = dataset.get_dataset_size()
model.set_train(False)
total, test_loss, correct = 0, 0, 0
for data, label in dataset.create_tuple_iterator():
pred = model(data)
total += len(data)
test_loss += loss_fn(pred, label).asnumpy()
correct += (pred.argmax(1) == label).asnumpy().sum()
test_loss /= num_batches
correct /= total
print(f"Test: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
# 训练过程需多次迭代数据集,一次完整的迭代称为一轮(epoch)。在每一轮,遍历训练集进行训练,结束后使用测试集进行预测。打印每一轮的loss值和预测准确率(Accuracy),可以看到loss在不断下降,Accuracy在不断提高。
# In[13]:
epochs = 3
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(model, train_dataset)
test(model, test_dataset, loss_fn)
print("Done!")
保存模型
# 模型训练完成后,需要将其参数进行保存。
# In[14]:
# Save checkpoint
mindspore.save_checkpoint(model, "model.ckpt")
print("Saved Model to model.ckpt")
加载模型
加载保存的权重分为两步:
# 1. 重新实例化模型对象,构造模型。
# 2. 加载模型参数,并将其加载至模型上。
# In[15]:
# Instantiate a random initialized model
model = Network()
# Load checkpoint and load parameter to model
param_dict = mindspore.load_checkpoint("model.ckpt")
param_not_load, _ = mindspore.load_param_into_net(model, param_dict)
print(param_not_load)
# > `param_not_load`是未被加载的参数列表,为空时代表所有参数均加载成功。
# 加载后的模型可以直接用于预测推理。
# In[16]:
model.set_train(False)
for data, label in test_dataset:
pred = model(data)
predicted = pred.argmax(1)
print(f'Predicted: "{predicted[:10]}", Actual: "{label[:10]}"')
break
二 第二天张量
创建张量
- 构造张量时,支持传入
Tensor、float、int、bool、tuple、list和numpy.ndarray
from mindspore import Tensor
tensor_data = Tensor(data) # 其中tensor是list 或ndarray- init进行初始化
from mindspore import Tensor
from mindspore.common.initializer import One, Normal
data = Tensor(shape=(2,3), dtype=mindspore.float32, init=Normal())- 继承另一个张量的属性,形成新的张量
from mindspore import ops
x_ones = ops.ones_like(x_data)
x_zeros = ops.zeros_like(x_data)张量的属性
不太了解的属性是步长。 每一维步长(strides): Tensor每一维所需要的字节数,是一个tuple。
## 张量的运算
-
加减乘除等基本算数都可以使用广为熟识的运算符
+,-,*,/,//,% -
拼接
ops.concat((data1, data2), axis=0) # 同pandas拼接
ops.stack([data1, data2]) #会升维Tensor 与 Numpy 转换
n = t.asnumpy() # tensor -> numpy
t = Tensor.from_numpy(n) # numpy -> tensor
# 下面这个操作不单n加1,t也会
np.add(n,1,out=n) 稀疏张量
常用稀疏张量的表达形式是 <indices:Tensor, values:Tensor, shape:Tensor>。其中,indices表示非零下标元素, values表示非零元素的值,shape表示的是被压缩的稀疏张量的形状。
CSRTensor
CSR(Compressed Sparse Row)稀疏张量格式有着高效的存储与计算的优势。其中,非零元素的值存储在values中,非零元素的位置存储在indptr(行)和indices(列)中。各参数含义如下:
-
indptr: 一维整数张量, 表示稀疏数据每一行的非零元素在values中的起始位置和终止位置, 索引数据类型支持int16、int32、int64。 -
indices: 一维整数张量,表示稀疏张量非零元素在列中的位置, 与values长度相等,索引数据类型支持int16、int32、int64。 -
values: 一维张量,表示CSRTensor相对应的非零元素的值,与indices长度相等。 -
shape: 表示被压缩的稀疏张量的形状,数据类型为Tuple,目前仅支持二维CSRTensor。
COOTensor
COO(Coordinate Format)稀疏张量格式用来表示某一张量在给定索引上非零元素的集合,若非零元素的个数为N,被压缩的张量的维数为ndims。各参数含义如下:
-
indices: 二维整数张量,每行代表非零元素下标。形状:[N, ndims], 索引数据类型支持int16、int32、int64。 -
values: 一维张量,表示相对应的非零元素的值。形状:[N]。 -
shape: 表示被压缩的稀疏张量的形状,目前仅支持二维COOTensor。
三 第三天 数据集 Dataset
1.1 数据集介绍
数据是深度学习的基础,高质量的数据输入将在整个深度神经网络中起到积极作用。MindSpore提供基于Pipeline的数据引擎,通过数据集(Dataset)和数据变换(Transforms)实现高效的数据预处理。其中Dataset是Pipeline的起始,用于加载原始数据。mindspore.dataset提供了内置的文本、图像、音频等数据集加载接口,并提供了自定义数据集加载接口。
1.2 数据集加载
train_dataset = MnistDataset("MNIST_Data/train", shuffle=False)
复制1.3 数据集迭代
用create_tuple_iterator或create_dict_iterator接口创建数据迭代器,迭代访问数据。
1.4 数据集常用操作
- 数据集随机shuffle可以消除数据排列造成的分布不均问题。
- map操作是数据预处理的关键操作,可以针对数据集指定列(column)添加数据变换(Transforms),将数据变换应用于该列数据的每个元素,并返回包含变换后元素的新数据集。
- batch 将数据集打包为固定大小的batch是在有限硬件资源下使用梯度下降进行模型优化的折中方法,可以保证梯度下降的随机性和优化计算量。
1.5 自定义数据集¶
- 可随机访问数据集:实现了__getitem__和__len__方法的数据集,表示可以通过索引/键直接访问对应位置的数据样本。
- 可迭代数据集:实现了__iter__和__next__方法的数据集,表示可以通过迭代的方式逐步获取数据样本。这种类型的数据集特别适用于随机访问成本太高或者不可行的情况。
- 生成器:也属于可迭代的数据集类型,其直接依赖Python的生成器类型generator返回数据,直至生成器抛出StopIteration异常。
2. 课后小结
2.1 基本了解了数据集的概念及一些常见操作。
2.2 有些囫囵吞枣,有待在实践中去加深认识。
四 第四天 数据变换 Transfroms
数据变换 Transforms
通常情况下,直接加载的原始数据并不能直接送入神经网络进行训练,此时我们需要对其进行数据预处理。MindSpore提供不同种类的数据变换(Transforms),配合数据处理Pipeline来实现数据预处理。所有的Transforms均可通过map方法传入,实现对指定数据列的处理。
mindspore.dataset提供了面向图像、文本、音频等不同数据类型的Transforms,同时也支持使用Lambda函数。下面分别对其进行介绍。
实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
pip uninstall mindspore -y
pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
引入代码库
import numpy as np
from PIL import Image
from download import download
from mindspore.dataset import transforms, vision, text
from mindspore.dataset import GeneratorDataset, MnistDataset
Common Transforms
mindspore.dataset.transforms模块支持一系列通用Transforms。这里我们以Compose为例,介绍其使用方式。
Compose
Compose接收一个数据增强操作序列,然后将其组合成单个数据增强操作。我们仍基于Mnist数据集呈现Transforms的应用效果。
代码示例
# Download data from open datasetsurl = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)train_dataset = MnistDataset('MNIST_Data/train')image, label = next(train_dataset.create_tuple_iterator())
print(image.shape)
运行结果(28, 28, 1)
composed = transforms.Compose([vision.Rescale(1.0 / 255.0, 0),vision.Normalize(mean=(0.1307,), std=(0.3081,)),vision.HWC2CHW()]
)train_dataset = train_dataset.map(composed, 'image')
image, label = next(train_dataset.create_tuple_iterator())
print(image.shape)
运行结果(1, 28, 28)
API文档地址
通用Transforms详见mindspore.dataset.transforms
Vision Transforms
mindspore.dataset.vision模块提供一系列针对图像数据的Transforms。在Mnist数据处理过程中,使用了Rescale、Normalize和HWC2CHW变换。下面对其进行详述。
Rescale
Rescale变换用于调整图像像素值的大小,包括两个参数:
- rescale:缩放因子。
- shift:平移因子。
图像的每个像素将根据这两个参数进行调整,输出的像素值为 o u t p u t i = i n p u t i ∗ r e s c a l e + s h i f t output_{i} = input_{i} * rescale + shift outputi=inputi∗rescale+shift。
这里我们先使用numpy随机生成一个像素值在[0, 255]的图像,将其像素值进行缩放。
代码示例
random_np = np.random.randint(0, 255, (48, 48), np.uint8)
random_image = Image.fromarray(random_np)
print(random_np)
运行结果:
[[103 74 20 ... 133 190 202][ 65 128 170 ... 77 11 94][ 10 31 216 ... 68 141 22]...[190 106 254 ... 27 137 23][115 103 170 ... 65 136 93][ 0 212 28 ... 92 39 75]]
为了更直观地呈现Transform前后的数据对比,我们使用Transforms的Eager模式进行演示。首先实例化Transform对象,然后调用对象进行数据处理。
rescale = vision.Rescale(1.0 / 255.0, 0)
rescaled_image = rescale(random_image)
print(rescaled_image)
运行结果
[[0.4039216 0.2901961 0.07843138 ... 0.52156866 0.74509805 0.79215693][0.25490198 0.5019608 0.6666667 ... 0.3019608 0.04313726 0.36862746][0.03921569 0.12156864 0.8470589 ... 0.26666668 0.5529412 0.08627451]...[0.74509805 0.4156863 0.9960785 ... 0.10588236 0.5372549 0.09019608][0.45098042 0.4039216 0.6666667 ... 0.25490198 0.53333336 0.3647059 ][0. 0.8313726 0.10980393 ... 0.36078432 0.15294118 0.29411766]]
可以看到,使用Rescale后的每个像素值都进行了缩放。
Normalize
Normalize变换用于对输入图像的归一化,包括三个参数:
- mean:图像每个通道的均值。
- std:图像每个通道的标准差。
- is_hwc:bool值,输入图像的格式。True为(height, width, channel),False为(channel, height, width)。
图像的每个通道将根据mean和std进行调整,计算公式为 o u t p u t c = i n p u t c − m e a n c s t d c output_{c} = \frac{input_{c} - mean_{c}}{std_{c}} outputc=stdcinputc−meanc,其中 c c c代表通道索引。
normalize = vision.Normalize(mean=(0.1307,), std=(0.3081,))
normalized_image = normalize(rescaled_image)
print(normalized_image)
运行结果
[[ 0.8867953 0.51767635 -0.16964827 ... 1.2686423 1.99415162.1468906 ][ 0.40312228 1.2050011 1.7395868 ... 0.55586106 -0.28420240.77224106][-0.29693064 -0.02963769 2.3250859 ... 0.44130698 1.3704681-0.14419182]...[ 1.9941516 0.92498 2.8087587 ... -0.08055063 1.3195552-0.13146357][ 1.0395341 0.8867953 1.7395868 ... 0.40312228 1.3068270.7595128 ][-0.42421296 2.2741728 -0.06782239 ... 0.74678457 0.072188180.5304046 ]]
HWC2CHW
HWC2CHW变换用于转换图像格式。在不同的硬件设备中可能会对(height, width, channel)或(channel, height, width)两种不同格式有针对性优化。MindSpore设置HWC为默认图像格式,在有CHW格式需求时,可使用该变换进行处理。
这里我们先将前文中normalized_image处理为HWC格式,然后进行转换。可以看到转换前后的shape发生了变化。
代码示例
hwc_image = np.expand_dims(normalized_image, -1)
hwc2chw = vision.HWC2CHW()
chw_image = hwc2chw(hwc_image)
print(hwc_image.shape, chw_image.shape)
运行结果:(48, 48, 1) (1, 48, 48)
API文档:mindspore.dataset.vision
Text Transforms
mindspore.dataset.text模块提供一系列针对文本数据的Transforms。与图像数据不同,文本数据需要有分词(Tokenize)、构建词表、Token转Index等操作。这里简单介绍其使用方法。
首先我们定义三段文本,作为待处理的数据,并使用GeneratorDataset进行加载。
代码示例:
texts = ['Welcome to Beijing']
test_dataset = GeneratorDataset(texts, 'text')
PythonTokenizer
分词(Tokenize)操作是文本数据的基础处理方法,MindSpore提供多种不同的Tokenizer。这里我们选择基础的PythonTokenizer举例,此Tokenizer允许用户自由实现分词策略。随后我们利用map操作将此分词器应用到输入的文本中,对其进行分词。
代码示例:
def my_tokenizer(content):return content.split()test_dataset = test_dataset.map(text.PythonTokenizer(my_tokenizer))
print(next(test_dataset.create_tuple_iterator()))
运行结果:[Tensor(shape=[3], dtype=String, value= ['Welcome', 'to', 'Beijing'])]
Lookup
Lookup为词表映射变换,用来将Token转换为Index。在使用Lookup前,需要构造词表,一般可以加载已有的词表,或使用Vocab生成词表。这里我们选择使用Vocab.from_dataset方法从数据集中生成词表。
代码示例:
vocab = text.Vocab.from_dataset(test_dataset)
获得词表后我们可以使用vocab方法查看词表。
print(vocab.vocab())
运行结果:{'to': 2, 'Welcome': 1, 'Beijing': 0}
生成词表后,可以配合map方法进行词表映射变换,将Token转为Index。
test_dataset = test_dataset.map(text.Lookup(vocab))
print(next(test_dataset.create_tuple_iterator()))
运行结果:[Tensor(shape=[3], dtype=Int32, value= [1, 2, 0])]
API文档
mindspore.dataset.text
Lambda Transforms
Lambda函数是一种不需要名字、由一个单独表达式组成的匿名函数,表达式会在调用时被求值。Lambda Transforms可以加载任意定义的Lambda函数,提供足够的灵活度。在这里,我们首先使用一个简单的Lambda函数,对输入数据乘2:
代码示例
test_dataset = GeneratorDataset([1, 2, 3], 'data', shuffle=False)
test_dataset = test_dataset.map(lambda x: x * 2)
print(list(test_dataset.create_tuple_iterator()))
可以看到map传入Lambda函数后,迭代获得数据进行了乘2操作。
我们也可以定义较复杂的函数,配合Lambda函数实现复杂数据处理:
def func(x):return x * x + 2test_dataset = test_dataset.map(lambda x: func(x))print(list(test_dataset.create_tuple_iterator()))
运行结果:[[Tensor(shape=[], dtype=Int64, value= 6)], [Tensor(shape=[], dtype=Int64, value= 18)], [Tensor(shape=[], dtype=Int64, value= 38)]]
五 第五天 网络构建jpynb
-
基本介绍:介绍了MindSpore框架的基本概念,如张量(Tensor)、数据集(Dataset)、数据变换(Transforms)、网络构建、函数式自动微分、模型训练、保存与加载,以及使用静态图加速等内容。
-
网络构建:详细讲述了神经网络模型是如何由神经网络层和Tensor操作构成的。在MindSpore中,所有的网络都基于
Cell类构建,这是构建网络的基本单元。通过Cell的嵌套结构,可以使用面向对象的编程思维来构建和管理神经网络结构。 -
定义模型类:介绍了如何通过继承
nn.Cell类来定义自己的神经网络模型。在类的__init__方法中实例化子Cell和状态管理,在construct方法中实现Tensor操作。construct方法用于构建神经网络的计算图。 -
构建示例模型:以Mnist数据集分类任务为例,展示了如何构建一个简单的神经网络模型。模型包括
Flatten层用于数据平铺,以及SequentialCell包含多个Dense和ReLU层。 -
模型层的使用:详细分解了构建的神经网络模型中的每一层,包括:
nn.Flatten:将2D张量转换为1D数组。nn.Dense:全连接层,进行线性变换。nn.ReLU:激活函数,引入非线性。nn.SequentialCell:有序的Cell容器,按顺序处理输入Tensor。nn.Softmax:将logits转换为预测概率。
-
模型参数:介绍了如何通过
model.parameters_and_names()获取模型的参数名和参数详情,这对于理解模型结构和参数优化非常重要。 -
代码示例:教程中提供了丰富的代码示例,包括如何实例化模型、如何构造输入数据、如何调用模型进行预测,以及如何获取模型的输出和预测类别。
-
模型的输出:展示了如何通过模型获得原始预测值,并使用
nn.Softmax层将这些值转换为预测概率,然后通过argmax函数找到最大概率对应的类别。
六 第六天函数式自动微分
一、简介:
神经网络的训练主要使用反向传播算法,模型预测值(logits)与正确标签(label)送入损失函数(loss function)获得loss,然后进行反向传播计算,求得梯度(gradients),最终更新至模型参数(parameters)。自动微分能够计算可导函数在某点处的导数值,是反向传播算法的一般化。自动微分主要解决的问题是将一个复杂的数学运算分解为一系列简单的基本运算,该功能对用户屏蔽了大量的求导细节和过程,大大降低了框架的使用门槛。
MindSpore使用函数式自动微分的设计理念,提供更接近于数学语义的自动微分接口grad和value_and_grad,简便模型反向传播的使用。
二、环境准备:
老规矩,没有下载MindSpore框架的友友们,回看昇思25天学习打卡营第1天|快速入门-CSDN博客
import numpy as np
import time
import mindspore
from mindspore import nn
from mindspore import ops
from mindspore import Tensor, Parameter三、函数和计算图:
计算图是用图形语言表示数学函数的一种方式,也是深度学习框架表达神经网络模型的统一方法。我们将根据下面的计算图构造计算函数和神经网络。
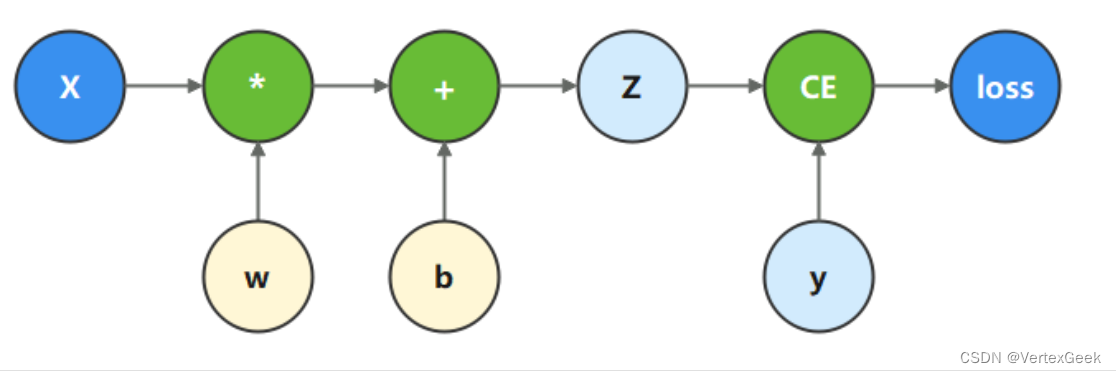
在这个模型中,𝑥𝑥为输入,𝑦𝑦为正确值,𝑤𝑤和𝑏𝑏是我们需要优化的参数,也就是我们常说的权重和偏置。我们根据计算图描述的计算过程,构造计算函数。 其中binary_cross_entropy_with_logits 是一个损失函数,计算预测值和目标值之间的二值交叉熵损失。
x = ops.ones(5, mindspore.float32) # 创造输入X
y = ops.zeros(3, mindspore.float32) # 创造Y
w = Parameter(Tensor(np.random.randn(5, 3), mindspore.float32), name='w') # 权重
b = Parameter(Tensor(np.random.randn(3,), mindspore.float32), name='b') # 偏置
def function(x, y, w, b):
z = ops.matmul(x, w) + b #简单的线性变换,也就是Y = WX + b
# 计算交叉熵损失
loss = ops.binary_cross_entropy_with_logits(z, y, ops.ones_like(z), ops.ones_like(z))
return loss
loss = function(x, y, w, b)
print(loss)
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time.time())), "VertexGeek")
四、微分函数和梯度计算:
为了优化模型参数,需要求参数对loss的导数:∂loss∂𝑤∂loss∂𝑤和∂loss∂𝑏∂loss∂𝑏,此时我们调用mindspore.grad函数,来获得function的微分函数。
这里使用了grad函数的两个入参,分别为:
fn:待求导的函数。grad_position:指定求导输入位置的索引(这里的索引是指待求导函数中输入的形参,在我们这个例子中是w和b,对应的index分别是2和3)。
grad_fn = mindspore.grad(function, (2, 3))
grads = grad_fn(x, y, w, b)
print(grads)
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time.time())), "VertexGeek")
五、Stop Gradient:
通常情况下,求导时会求loss对参数的导数,因此函数的输出只有loss一项。当我们希望函数输出多项时,微分函数会求所有输出项对参数的导数。此时如果想实现对某个输出项的梯度截断,或消除某个Tensor对梯度的影响,需要用到Stop Gradient操作。MindSpore提供了ops.stop_gradient方法实现对梯度的截断:
def function_with_logits(x, y, w, b):
z = ops.matmul(x, w) + b
loss = ops.binary_cross_entropy_with_logits(z, y, ops.ones_like(z), ops.ones_like(z))
# 这里返回损失和预测两个值
return loss, z
grad_fn = mindspore.grad(function_with_logits, (2, 3))
grads = grad_fn(x, y, w, b)
print(grads)
# 使用stop_gradient方法后:
def function_stop_gradient(x, y, w, b):
z = ops.matmul(x, w) + b
loss = ops.binary_cross_entropy_with_logits(z, y, ops.ones_like(z), ops.ones_like(z))
return loss, ops.stop_gradient(z)
grad_fn = mindspore.grad(function_stop_gradient, (2, 3))
grads = grad_fn(x, y, w, b)
print(grads)
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time.time())), "VertexGeek")未截断的输出:
 截断后的输出:
截断后的输出:

六、Auxiliary data:
Auxiliary data意为辅助数据,是函数除第一个输出项外的其他输出。通常我们会将函数的loss设置为函数的第一个输出,其他的输出即为辅助数据。在MindSpore中,grad和value_and_grad提供has_aux参数,当其设置为True时,可以自动实现前文手动添加stop_gradient的功能,满足返回辅助数据的同时不影响梯度计算的效果。
grad_fn = mindspore.grad(function_with_logits, (2, 3), has_aux=True)
grads, (z,) = grad_fn(x, y, w, b)
print(grads, z)
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time.time())), "VertexGeek")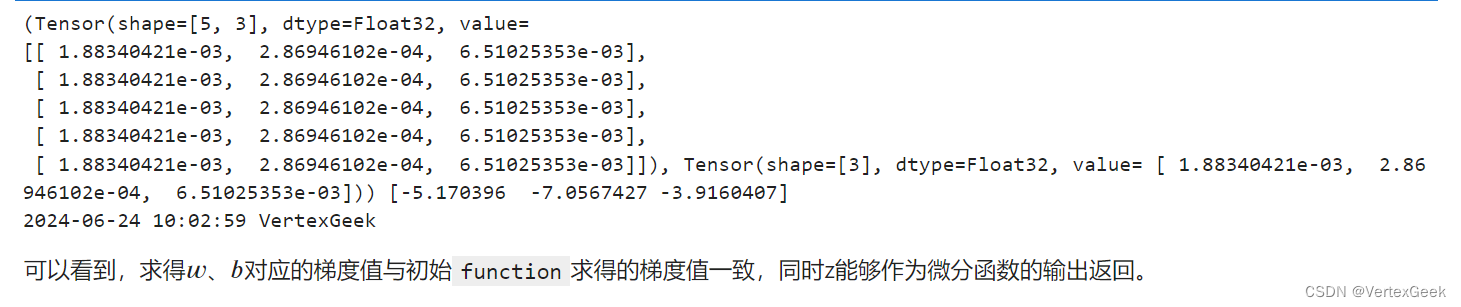
七、神经网络梯度计算:
下面我们要把前面介绍的自动微分方法运用到神经网络中,以实现反向传播,对神经网络还不熟悉的友友,可以阅读昇思25天学习打卡营第5天|网络构建-CSDN博客。
# 定义一个简单的神经网络
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.w = w
self.b = b
def construct(self, x):
z = ops.matmul(x, self.w) + self.b
return z
# 实例化模型和损失参数:
model = Network()
loss_fn = nn.BCEWithLogitsLoss()
# 前向计算:
def forward_fn(x, y):
z = model(x)
loss = loss_fn(z, y)
return loss
# 计算梯度
grad_fn = mindspore.value_and_grad(forward_fn, None, weights=model.trainable_params())
loss, grads = grad_fn(x, y)
print(grads)
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time.time())), "VertexGeek")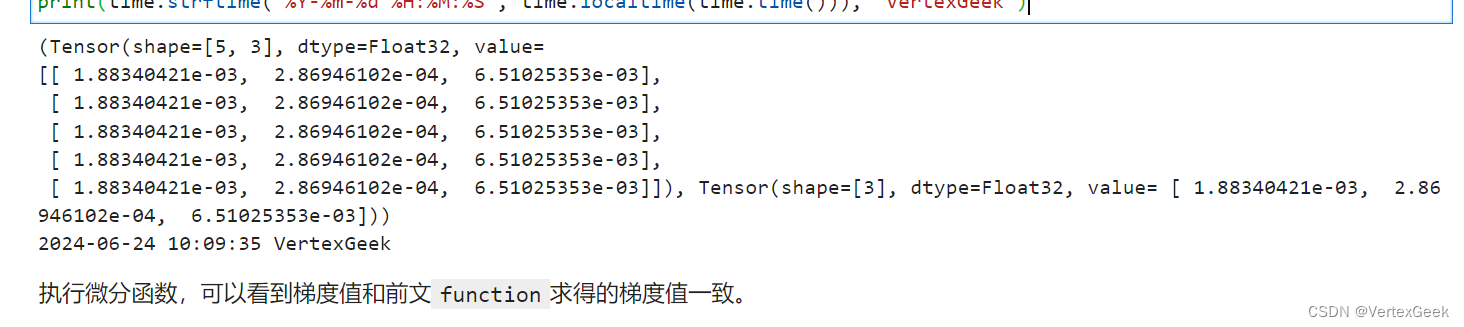
七 第七天模型训练
内容介绍:
模型训练一般分为四个步骤:
-
构建数据集。
-
定义神经网络模型。
-
定义超参、损失函数及优化器。
-
输入数据集进行训练与评估。
具体内容:
- 导包
import mindspore
from mindspore import nn
from mindspore.dataset import vision, transforms
from mindspore.dataset import MnistDataset
from download import download- 构建数据集
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)
def datapipe(path, batch_size):
image_transforms = [
vision.Rescale(1.0 / 255.0, 0),
vision.Normalize(mean=(0.1307,), std=(0.3081,)),
vision.HWC2CHW()
]
label_transform = transforms.TypeCast(mindspore.int32)
dataset = MnistDataset(path)
dataset = dataset.map(image_transforms, 'image')
dataset = dataset.map(label_transform, 'label')
dataset = dataset.batch(batch_size)
return dataset
train_dataset = datapipe('MNIST_Data/train', batch_size=64)
test_dataset = datapipe('MNIST_Data/test', batch_size=64)- 定义神经网络模型
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.dense_relu_sequential = nn.SequentialCell(
nn.Dense(28*28, 512),
nn.ReLU(),
nn.Dense(512, 512),
nn.ReLU(),
nn.Dense(512, 10)
)
def construct(self, x):
x = self.flatten(x)
logits = self.dense_relu_sequential(x)
return logits
model = Network()- 定义超参、损失函数和优化器
超参(Hyperparameters)是可以调整的参数,可以控制模型训练优化的过程,不同的超参数值可能会影响模型训练和收敛速度。目前深度学习模型多采用批量随机梯度下降算法进行优化。
训练轮次(epoch):训练时遍历数据集的次数。
批次大小(batch size):数据集进行分批读取训练,设定每个批次数据的大小。batch size过小,花费时间多,同时梯度震荡严重,不利于收敛;batch size过大,不同batch的梯度方向没有任何变化,容易陷入局部极小值,因此需要选择合适的batch size,可以有效提高模型精度、全局收敛。
学习率(learning rate):如果学习率偏小,会导致收敛的速度变慢,如果学习率偏大,则可能会导致训练不收敛等不可预测的结果。梯度下降法被广泛应用在最小化模型误差的参数优化算法上。梯度下降法通过多次迭代,并在每一步中最小化损失函数来预估模型的参数。学习率就是在迭代过程中,会控制模型的学习进度。
epochs = 3
batch_size = 64
learning_rate = 1e-2损失函数(loss function)用于评估模型的预测值(logits)和目标值(targets)之间的误差。训练模型时,随机初始化的神经网络模型开始时会预测出错误的结果。损失函数会评估预测结果与目标值的相异程度,模型训练的目标即为降低损失函数求得的误差。
常见的损失函数包括用于回归任务的`nn.MSELoss`(均方误差)和用于分类的`nn.NLLLoss`(负对数似然)等。 `nn.CrossEntropyLoss` 结合了`nn.LogSoftmax`和`nn.NLLLoss`,可以对logits 进行归一化并计算预测误差。
loss_fn = nn.CrossEntropyLoss()模型优化(Optimization)是在每个训练步骤中调整模型参数以减少模型误差的过程。MindSpore提供多种优化算法的实现,称之为优化器(Optimizer)。优化器内部定义了模型的参数优化过程(即梯度如何更新至模型参数),所有优化逻辑都封装在优化器对象中。在这里,我们使用SGD(Stochastic Gradient Descent)优化器。
我们通过`model.trainable_params()`方法获得模型的可训练参数,并传入学习率超参来初始化优化器。
optimizer = nn.SGD(model.trainable_params(), learning_rate=learning_rate)在训练过程中,通过微分函数可计算获得参数对应的梯度,将其传入优化器中即可实现参数优化,具体形态如下:
grads = grad_fn(inputs)
optimizer(grads)
- 训练与评估
设置了超参、损失函数和优化器后,我们就可以循环输入数据来训练模型。一次数据集的完整迭代循环称为一轮(epoch)。每轮执行训练时包括两个步骤:
-
训练:迭代训练数据集,并尝试收敛到最佳参数。
-
验证/测试:迭代测试数据集,以检查模型性能是否提升。
def forward_fn(data, label):
logits = model(data)
loss = loss_fn(logits, label)
return loss, logits
# Get gradient function
grad_fn = mindspore.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=True)
# Define function of one-step training
def train_step(data, label):
(loss, _), grads = grad_fn(data, label)
optimizer(grads)
return loss
def train_loop(model, dataset):
size = dataset.get_dataset_size()
model.set_train()
for batch, (data, label) in enumerate(dataset.create_tuple_iterator()):
loss = train_step(data, label)
if batch % 100 == 0:
loss, current = loss.asnumpy(), batch
print(f"loss: {loss:>7f} [{current:>3d}/{size:>3d}]")def test_loop(model, dataset, loss_fn):
num_batches = dataset.get_dataset_size()
model.set_train(False)
total, test_loss, correct = 0, 0, 0
for data, label in dataset.create_tuple_iterator():
pred = model(data)
total += len(data)
test_loss += loss_fn(pred, label).asnumpy()
correct += (pred.argmax(1) == label).asnumpy().sum()
test_loss /= num_batches
correct /= total
print(f"Test: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")loss_fn = nn.CrossEntropyLoss()
optimizer = nn.SGD(model.trainable_params(), learning_rate=learning_rate)
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train_loop(model, train_dataset)
test_loop(model, test_dataset, loss_fn)
print("Done!")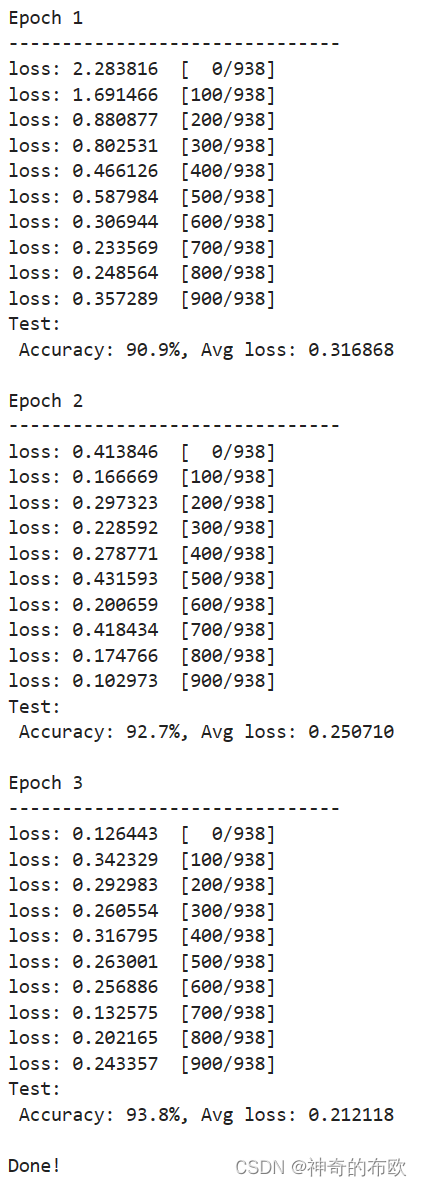
MindSpore的易用性也给我带来了很大的便利。通过简洁明了的API和丰富的文档支持,我能够快速地掌握MindSpore的使用方法,并轻松地构建自己的深度学习模型。同时,MindSpore还提供了丰富的预训练模型和示例代码,让我能够更快地入门并深入理解深度学习的应用。
在模型训练的过程中,我深刻体会到了深度学习模型的复杂性和挑战性。通过不断地调整网络结构、优化参数设置以及尝试不同的训练策略,我逐渐掌握了如何构建和训练一个性能优异的深度学习模型。这个过程让我更加明白了深度学习模型训练需要耐心、细致和持续的努力。

八 第八天 保存与加载
capture captured_output
# 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
!pip uninstall mindspore -y
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
import numpy as np
import mindspore
from mindspore import nn
from mindspore import Tensor
def network():
model = nn.SequentialCell(
nn.Flatten(),
nn.Dense(28*28, 512),
nn.ReLU(),
nn.Dense(512, 512),
nn.ReLU(),
nn.Dense(512, 10))
return model
保存和加载模型权重
保存模型使用save_checkpoint接口,传入网络和指定的保存路径:
model = network()
mindspore.save_checkpoint(model, "model.ckpt")
要加载模型权重,需要先创建相同模型的实例,然后使用load_checkpoint和load_param_into_net方法加载参数。
model = network()
param_dict = mindspore.load_checkpoint("model.ckpt")
param_not_load, _ = mindspore.load_param_into_net(model, param_dict)
print(param_not_load)
param_not_load是未被加载的参数列表,为空时代表所有参数均加载成功。
保存和加载MindIR
除Checkpoint外,MindSpore提供了云侧(训练)和端侧(推理)统一的中间表示(Intermediate Representation,IR)。可使用export接口直接将模型保存为MindIR。
model = network()
inputs = Tensor(np.ones([1, 1, 28, 28]).astype(np.float32))
mindspore.export(model, inputs, file_name="model", file_format="MINDIR")
MindIR同时保存了Checkpoint和模型结构,因此需要定义输入Tensor来获取输入shape。
已有的MindIR模型可以方便地通过load接口加载,传入nn.GraphCell即可进行推理
nn.GraphCell仅支持图模式
mindspore.set_context(mode=mindspore.GRAPH_MODE)
graph = mindspore.load("model.mindir")
model = nn.GraphCell(graph)
outputs = model(inputs)
print(outputs.shape)
九 第九天 使用静态图加速
背景介绍
AI编译框架分为两种运行模式,分别是动态图模式以及静态图模式。MindSpore默认情况下是以动态图模式运行,但也支持手工切换为静态图模式。两种运行模式的详细介绍如下:
动态图模式
动态图的特点是计算图的构建和计算同时发生(Define by run),其符合Python的解释执行方式,在计算图中定义一个Tensor时,其值就已经被计算且确定,因此在调试模型时较为方便,能够实时得到中间结果的值,但由于所有节点都需要被保存,导致难以对整个计算图进行优化。
在MindSpore中,动态图模式又被称为PyNative模式。由于动态图的解释执行特性,在脚本开发和网络流程调试过程中,推荐使用动态图模式进行调试。 如需要手动控制框架采用PyNative模式,可以通过以下代码进行网络构建:
%%capture captured_output
# 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
!pip uninstall mindspore -y
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
import numpy as np
import mindspore as ms
from mindspore import nn, Tensor
ms.set_context(mode=ms.PYNATIVE_MODE) # 使用set_context进行动态图模式的配置class Network(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.dense_relu_sequential = nn.SequentialCell(
nn.Dense(28*28, 512),
nn.ReLU(),
nn.Dense(512, 512),
nn.ReLU(),
nn.Dense(512, 10)
)def construct(self, x):
x = self.flatten(x)
logits = self.dense_relu_sequential(x)
return logitsmodel = Network()
input = Tensor(np.ones([64, 1, 28, 28]).astype(np.float32))
output = model(input)
print(output)
静态图模式
相较于动态图而言,静态图的特点是将计算图的构建和实际计算分开(Define and run)。有关静态图模式的运行原理,可以参考静态图语法支持。
在MindSpore中,静态图模式又被称为Graph模式,在Graph模式下,基于图优化、计算图整图下沉等技术,编译器可以针对图进行全局的优化,获得较好的性能,因此比较适合网络固定且需要高性能的场景。
如需要手动控制框架采用静态图模式,可以通过以下代码进行网络构建:
import numpy as np
import mindspore as ms
from mindspore import nn, Tensor
ms.set_context(mode=ms.GRAPH_MODE) # 使用set_context进行运行静态图模式的配置class Network(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.dense_relu_sequential = nn.SequentialCell(
nn.Dense(28*28, 512),
nn.ReLU(),
nn.Dense(512, 512),
nn.ReLU(),
nn.Dense(512, 10)
)def construct(self, x):
x = self.flatten(x)
logits = self.dense_relu_sequential(x)
return logitsmodel = Network()
input = Tensor(np.ones([64, 1, 28, 28]).astype(np.float32))
output = model(input)
print(output)
静态图模式的使用场景
MindSpore编译器重点面向Tensor数据的计算以及其微分处理。因此使用MindSpore API以及基于Tensor对象的操作更适合使用静态图编译优化。其他操作虽然可以部分入图编译,但实际优化作用有限。另外,静态图模式先编译后执行的模式导致其存在编译耗时。因此,如果函数无需反复执行,那么使用静态图加速也可能没有价值。
有关使用静态图来进行网络编译的示例,请参考网络构建。
静态图模式开启方式
通常情况下,由于动态图的灵活性,我们会选择使用PyNative模式来进行自由的神经网络构建,以实现模型的创新和优化。但是当需要进行性能加速时,我们需要对神经网络部分或整体进行加速。MindSpore提供了两种切换为图模式的方式,分别是基于装饰器的开启方式以及基于全局context的开启方式。
基于装饰器的开启方式
MindSpore提供了jit装饰器,可以通过修饰Python函数或者Python类的成员函数使其被编译成计算图,通过图优化等技术提高运行速度。此时我们可以简单的对想要进行性能优化的模块进行图编译加速,而模型其他部分,仍旧使用解释执行方式,不丢失动态图的灵活性。无论全局context是设置成静态图模式还是动态图模式,被jit修饰的部分始终会以静态图模式进行运行。
在需要对Tensor的某些运算进行编译加速时,可以在其定义的函数上使用jit修饰器,在调用该函数时,该模块自动被编译为静态图。需要注意的是,jit装饰器只能用来修饰函数,无法对类进行修饰。jit的使用示例如下:
import numpy as np
import mindspore as ms
from mindspore import nn, Tensorclass Network(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.dense_relu_sequential = nn.SequentialCell(
nn.Dense(28*28, 512),
nn.ReLU(),
nn.Dense(512, 512),
nn.ReLU(),
nn.Dense(512, 10)
)def construct(self, x):
x = self.flatten(x)
logits = self.dense_relu_sequential(x)
return logitsinput = Tensor(np.ones([64, 1, 28, 28]).astype(np.float32))
@ms.jit # 使用ms.jit装饰器,使被装饰的函数以静态图模式运行
def run(x):
model = Network()
return model(x)output = run(input)
print(output)
除使用修饰器外,也可使用函数变换方式调用jit方法,示例如下:
import numpy as np
import mindspore as ms
from mindspore import nn, Tensorclass Network(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.dense_relu_sequential = nn.SequentialCell(
nn.Dense(28*28, 512),
nn.ReLU(),
nn.Dense(512, 512),
nn.ReLU(),
nn.Dense(512, 10)
)def construct(self, x):
x = self.flatten(x)
logits = self.dense_relu_sequential(x)
return logitsinput = Tensor(np.ones([64, 1, 28, 28]).astype(np.float32))
def run(x):
model = Network()
return model(x)run_with_jit = ms.jit(run) # 通过调用jit将函数转换为以静态图方式执行
output = run(input)
print(output)
当我们需要对神经网络的某部分进行加速时,可以直接在construct方法上使用jit修饰器,在调用实例化对象时,该模块自动被编译为静态图。示例如下:
import numpy as np
import mindspore as ms
from mindspore import nn, Tensorclass Network(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.dense_relu_sequential = nn.SequentialCell(
nn.Dense(28*28, 512),
nn.ReLU(),
nn.Dense(512, 512),
nn.ReLU(),
nn.Dense(512, 10)
)@ms.jit # 使用ms.jit装饰器,使被装饰的函数以静态图模式运行
def construct(self, x):
x = self.flatten(x)
logits = self.dense_relu_sequential(x)
return logitsinput = Tensor(np.ones([64, 1, 28, 28]).astype(np.float32))
model = Network()
output = model(input)
print(output)
基于context的开启方式
context模式是一种全局的设置模式。代码示例如下:
import numpy as np
import mindspore as ms
from mindspore import nn, Tensor
ms.set_context(mode=ms.GRAPH_MODE) # 使用set_context进行运行静态图模式的配置class Network(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.dense_relu_sequential = nn.SequentialCell(
nn.Dense(28*28, 512),
nn.ReLU(),
nn.Dense(512, 512),
nn.ReLU(),
nn.Dense(512, 10)
)def construct(self, x):
x = self.flatten(x)
logits = self.dense_relu_sequential(x)
return logitsmodel = Network()
input = Tensor(np.ones([64, 1, 28, 28]).astype(np.float32))
output = model(input)
print(output)
静态图的语法约束
在Graph模式下,Python代码并不是由Python解释器去执行,而是将代码编译成静态计算图,然后执行静态计算图。因此,编译器无法支持全量的Python语法。MindSpore的静态图编译器维护了Python常用语法子集,以支持神经网络的构建及训练。详情可参考静态图语法支持。
JitConfig配置选项
在图模式下,可以通过使用JitConfig配置选项来一定程度的自定义编译流程,目前JitConfig支持的配置参数如下:
- jit_level: 用于控制优化等级。
- exec_mode: 用于控制模型执行方式。
- jit_syntax_level: 设置静态图语法支持级别,详细介绍请见静态图语法支持。
静态图高级编程技巧
使用静态图高级编程技巧可以有效地提高编译效率以及执行效率,并可以使程序运行的更加稳定。详情可参考静态图高级编程技巧。
十 第十天FCN图像语义分割
全卷积网络(Fully Convolutional Networks,FCN)是UC Berkeley的Jonathan Long等人于2015年在Fully Convolutional Networks for Semantic Segmentation[1]一文中提出的用于图像语义分割的一种框架。
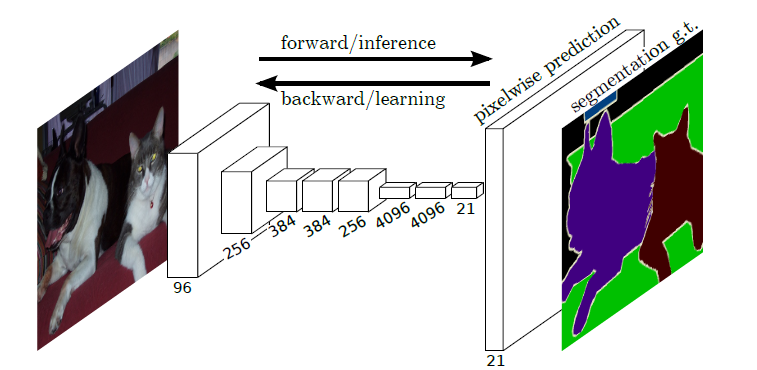
FCN是首个端到端(end to end)进行像素级(pixel level)预测的全卷积网络。
语义分割
在具体介绍FCN之前,首先介绍何为语义分割:
图像语义分割(semantic segmentation)是图像处理和机器视觉技术中关于图像理解的重要一环,AI领域中一个重要分支,常被应用于人脸识别、物体检测、医学影像、卫星图像分析、自动驾驶感知等领域。

语义分割的目的是对图像中每个像素点进行分类。与普通的分类任务只输出某个类别不同,语义分割任务输出与输入大小相同的图像,输出图像的每个像素对应了输入图像每个像素的类别。语义在图像领域指的是图像的内容,对图片意思的理解,下图是一些语义分割的实例:
模型简介
FCN主要用于图像分割领域,是一种端到端的分割方法,是深度学习应用在图像语义分割的开山之作。通过进行像素级的预测直接得出与原图大小相等的label map。因FCN丢弃全连接层替换为全卷积层,网络所有层均为卷积层,故称为全卷积网络。
全卷积神经网络主要使用以下三种技术:
-
卷积化(Convolutional)
使用VGG-16作为FCN的backbone。VGG-16的输入为224*224的RGB图像,输出为1000个预测值。VGG-16只能接受固定大小的输入,丢弃了空间坐标,产生非空间输出。VGG-16中共有三个全连接层,全连接层也可视为带有覆盖整个区域的卷积。将全连接层转换为卷积层能使网络输出由一维非空间输出变为二维矩阵,利用输出能生成输入图片映射的heatmap。

-
上采样(Upsample)
在卷积过程的卷积操作和池化操作会使得特征图的尺寸变小,为得到原图的大小的稠密图像预测,需要对得到的特征图进行上采样操作。使用双线性插值的参数来初始化上采样逆卷积的参数,后通过反向传播来学习非线性上采样。在网络中执行上采样,以通过像素损失的反向传播进行端到端的学习。
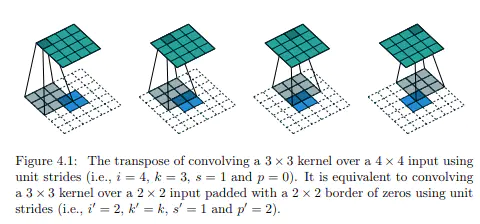
-
跳跃结构(Skip Layer)
利用上采样技巧对最后一层的特征图进行上采样得到原图大小的分割是步长为32像素的预测,称之为FCN-32s。由于最后一层的特征图太小,损失过多细节,采用skips结构将更具有全局信息的最后一层预测和更浅层的预测结合,使预测结果获取更多的局部细节。将底层(stride 32)的预测(FCN-32s)进行2倍的上采样得到原尺寸的图像,并与从pool4层(stride 16)进行的预测融合起来(相加),这一部分的网络被称为FCN-16s。随后将这一部分的预测再进行一次2倍的上采样并与从pool3层得到的预测融合起来,这一部分的网络被称为FCN-8s。 Skips结构将深层的全局信息与浅层的局部信息相结合。
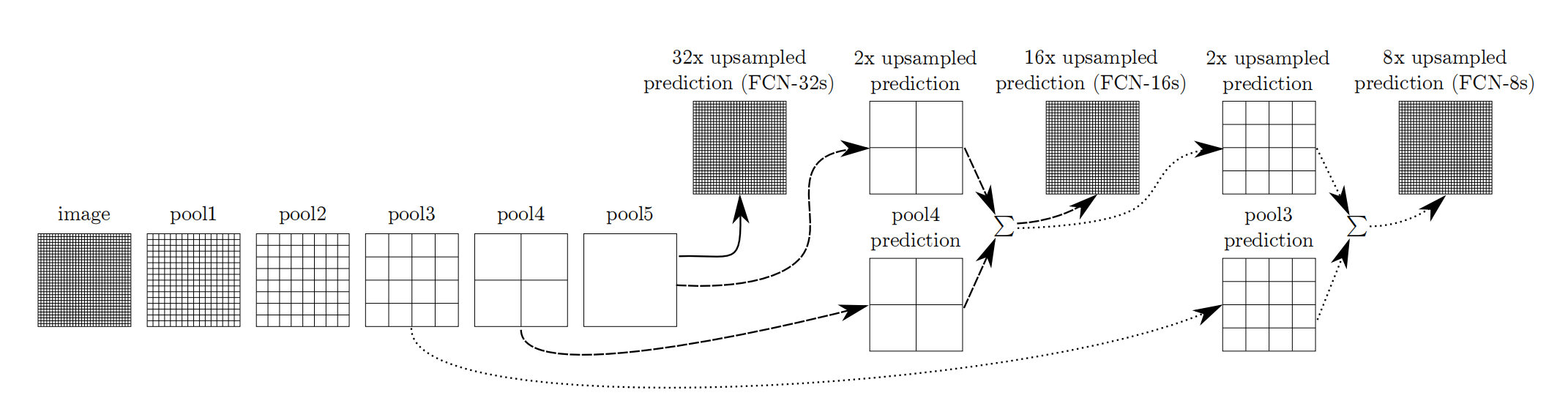
网络特点
- 不含全连接层(fc)的全卷积(fully conv)网络,可适应任意尺寸输入。
- 增大数据尺寸的反卷积(deconv)层,能够输出精细的结果。
- 结合不同深度层结果的跳级(skip)结构,同时确保鲁棒性和精确性。
数据处理
开始实验前,需确保本地已经安装Python环境及MindSpore。
[1]:
%%capture captured_output
# 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
!pip uninstall mindspore -y
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
[2]:
# 查看当前 mindspore 版本
!pip show mindspore
Name: mindspore Version: 2.2.14 Summary: MindSpore is a new open source deep learning training/inference framework that could be used for mobile, edge and cloud scenarios. Home-page: https://www.mindspore.cn Author: The MindSpore Authors Author-email: contact@mindspore.cn License: Apache 2.0 Location: /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages Requires: asttokens, astunparse, numpy, packaging, pillow, protobuf, psutil, scipy Required-by:
[3]:
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/dataset_fcn8s.tar"
download(url, "./dataset", kind="tar", replace=True)
Creating data folder... Downloading data from https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/dataset_fcn8s.tar (537.2 MB) file_sizes: 100%|█████████████████████████████| 563M/563M [00:03<00:00, 156MB/s] Extracting tar file... Successfully downloaded / unzipped to ./dataset
[3]:
'./dataset'
数据预处理
由于PASCAL VOC 2012数据集中图像的分辨率大多不一致,无法放在一个tensor中,故输入前需做标准化处理。
数据加载
将PASCAL VOC 2012数据集与SDB数据集进行混合。
[4]:
import numpy as np
import cv2
import mindspore.dataset as ds
class SegDataset:
def __init__(self,
image_mean,
image_std,
data_file='',
batch_size=32,
crop_size=512,
max_scale=2.0,
min_scale=0.5,
ignore_label=255,
num_classes=21,
num_readers=2,
num_parallel_calls=4):
self.data_file = data_file
self.batch_size = batch_size
self.crop_size = crop_size
self.image_mean = np.array(image_mean, dtype=np.float32)
self.image_std = np.array(image_std, dtype=np.float32)
self.max_scale = max_scale
self.min_scale = min_scale
self.ignore_label = ignore_label
self.num_classes = num_classes
self.num_readers = num_readers
self.num_parallel_calls = num_parallel_calls
max_scale > min_scale
def preprocess_dataset(self, image, label):
image_out = cv2.imdecode(np.frombuffer(image, dtype=np.uint8), cv2.IMREAD_COLOR)
label_out = cv2.imdecode(np.frombuffer(label, dtype=np.uint8), cv2.IMREAD_GRAYSCALE)
sc = np.random.uniform(self.min_scale, self.max_scale)
new_h, new_w = int(sc * image_out.shape[0]), int(sc * image_out.shape[1])
image_out = cv2.resize(image_out, (new_w, new_h), interpolation=cv2.INTER_CUBIC)
label_out = cv2.resize(label_out, (new_w, new_h), interpolation=cv2.INTER_NEAREST)
image_out = (image_out - self.image_mean) / self.image_std
out_h, out_w = max(new_h, self.crop_size), max(new_w, self.crop_size)
pad_h, pad_w = out_h - new_h, out_w - new_w
if pad_h > 0 or pad_w > 0:
image_out = cv2.copyMakeBorder(image_out, 0, pad_h, 0, pad_w, cv2.BORDER_CONSTANT, value=0)
label_out = cv2.copyMakeBorder(label_out, 0, pad_h, 0, pad_w, cv2.BORDER_CONSTANT, value=self.ignore_label)
offset_h = np.random.randint(0, out_h - self.crop_size + 1)
offset_w = np.random.randint(0, out_w - self.crop_size + 1)
image_out = image_out[offset_h: offset_h + self.crop_size, offset_w: offset_w + self.crop_size, :]
label_out = label_out[offset_h: offset_h + self.crop_size, offset_w: offset_w+self.crop_size]
if np.random.uniform(0.0, 1.0) > 0.5:
image_out = image_out[:, ::-1, :]
label_out = label_out[:, ::-1]
image_out = image_out.transpose((2, 0, 1))
image_out = image_out.copy()
label_out = label_out.copy()
label_out = label_out.astype("int32")
return image_out, label_out
def get_dataset(self):
ds.config.set_numa_enable(True)
dataset = ds.MindDataset(self.data_file, columns_list=["data", "label"],
shuffle=True, num_parallel_workers=self.num_readers)
transforms_list = self.preprocess_dataset
dataset = dataset.map(operations=transforms_list, input_columns=["data", "label"],
output_columns=["data", "label"],
num_parallel_workers=self.num_parallel_calls)
dataset = dataset.shuffle(buffer_size=self.batch_size * 10)
dataset = dataset.batch(self.batch_size, drop_remainder=True)
return dataset
# 定义创建数据集的参数
IMAGE_MEAN = [103.53, 116.28, 123.675]
IMAGE_STD = [57.375, 57.120, 58.395]
DATA_FILE = "dataset/dataset_fcn8s/mindname.mindrecord"
# 定义模型训练参数
train_batch_size = 4
crop_size = 512
min_scale = 0.5
max_scale = 2.0
ignore_label = 255
num_classes = 21
# 实例化Dataset
dataset = SegDataset(image_mean=IMAGE_MEAN,
image_std=IMAGE_STD,
data_file=DATA_FILE,
batch_size=train_batch_size,
crop_size=crop_size,
max_scale=max_scale,
min_scale=min_scale,
ignore_label=ignore_label,
num_classes=num_classes,
num_readers=2,
num_parallel_calls=4)
dataset = dataset.get_dataset()
训练集可视化
运行以下代码观察载入的数据集图片(数据处理过程中已做归一化处理)。
[5]:
import numpy as np
import matplotlib.pyplot as plt
plt.figure(figsize=(16, 8))
# 对训练集中的数据进行展示
for i in range(1, 9):
plt.subplot(2, 4, i)
show_data = next(dataset.create_dict_iterator())
show_images = show_data["data"].asnumpy()
show_images = np.clip(show_images, 0, 1)
# 将图片转换HWC格式后进行展示
plt.imshow(show_images[0].transpose(1, 2, 0))
plt.axis("off")
plt.subplots_adjust(wspace=0.05, hspace=0)
plt.show()

网络构建
网络流程
FCN网络的流程如下图所示:
- 输入图像image,经过pool1池化后,尺寸变为原始尺寸的1/2。
- 经过pool2池化,尺寸变为原始尺寸的1/4。
- 接着经过pool3、pool4、pool5池化,大小分别变为原始尺寸的1/8、1/16、1/32。
- 经过conv6-7卷积,输出的尺寸依然是原图的1/32。
- FCN-32s是最后使用反卷积,使得输出图像大小与输入图像相同。
- FCN-16s是将conv7的输出进行反卷积,使其尺寸扩大两倍至原图的1/16,并将其与pool4输出的特征图进行融合,后通过反卷积扩大到原始尺寸。
- FCN-8s是将conv7的输出进行反卷积扩大4倍,将pool4输出的特征图反卷积扩大2倍,并将pool3输出特征图拿出,三者融合后通反卷积扩大到原始尺寸。
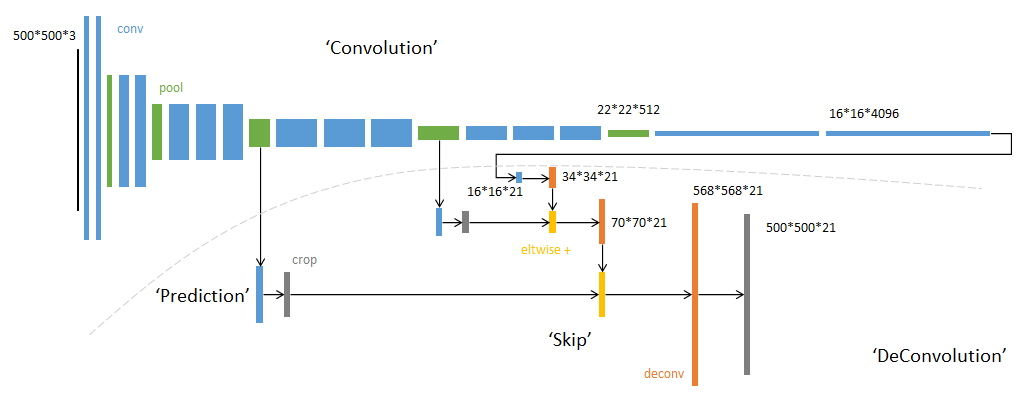
使用以下代码构建FCN-8s网络。
[6]:
import mindspore.nn as nn
class FCN8s(nn.Cell):
def __init__(self, n_class):
super().__init__()
self.n_class = n_class
self.conv1 = nn.SequentialCell(
nn.Conv2d(in_channels=3, out_channels=64,
kernel_size=3, weight_init='xavier_uniform'),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(in_channels=64, out_channels=64,
kernel_size=3, weight_init='xavier_uniform'),
nn.BatchNorm2d(64),
nn.ReLU()
)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.SequentialCell(
nn.Conv2d(in_channels=64, out_channels=128,
kernel_size=3, weight_init='xavier_uniform'),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(in_channels=128, out_channels=128,
kernel_size=3, weight_init='xavier_uniform'),
nn.BatchNorm2d(128),
nn.ReLU()
)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv3 = nn.SequentialCell(
nn.Conv2d(in_channels=128, out_channels=256,
kernel_size=3, weight_init='xavier_uniform'),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256,
kernel_size=3, weight_init='xavier_uniform'),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256,
kernel_size=3, weight_init='xavier_uniform'),
nn.BatchNorm2d(256),
nn.ReLU()
)
self.pool3 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv4 = nn.SequentialCell(
nn.Conv2d(in_channels=256, out_channels=512,
kernel_size=3, weight_init='xavier_uniform'),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512,
kernel_size=3, weight_init='xavier_uniform'),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512,
kernel_size=3, weight_init='xavier_uniform'),
nn.BatchNorm2d(512),
nn.ReLU()
)
self.pool4 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv5 = nn.SequentialCell(
nn.Conv2d(in_channels=512, out_channels=512,
kernel_size=3, weight_init='xavier_uniform'),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512,
kernel_size=3, weight_init='xavier_uniform'),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512,
kernel_size=3, weight_init='xavier_uniform'),
nn.BatchNorm2d(512),
nn.ReLU()
)
self.pool5 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv6 = nn.SequentialCell(
nn.Conv2d(in_channels=512, out_channels=4096,
kernel_size=7, weight_init='xavier_uniform'),
nn.BatchNorm2d(4096),
nn.ReLU(),
)
self.conv7 = nn.SequentialCell(
nn.Conv2d(in_channels=4096, out_channels=4096,
kernel_size=1, weight_init='xavier_uniform'),
nn.BatchNorm2d(4096),
nn.ReLU(),
)
self.score_fr = nn.Conv2d(in_channels=4096, out_channels=self.n_class,
kernel_size=1, weight_init='xavier_uniform')
self.upscore2 = nn.Conv2dTranspose(in_channels=self.n_class, out_channels=self.n_class,
kernel_size=4, stride=2, weight_init='xavier_uniform')
self.score_pool4 = nn.Conv2d(in_channels=512, out_channels=self.n_class,
kernel_size=1, weight_init='xavier_uniform')
self.upscore_pool4 = nn.Conv2dTranspose(in_channels=self.n_class, out_channels=self.n_class,
kernel_size=4, stride=2, weight_init='xavier_uniform')
self.score_pool3 = nn.Conv2d(in_channels=256, out_channels=self.n_class,
kernel_size=1, weight_init='xavier_uniform')
self.upscore8 = nn.Conv2dTranspose(in_channels=self.n_class, out_channels=self.n_class,
kernel_size=16, stride=8, weight_init='xavier_uniform')
def construct(self, x):
x1 = self.conv1(x)
p1 = self.pool1(x1)
x2 = self.conv2(p1)
p2 = self.pool2(x2)
x3 = self.conv3(p2)
p3 = self.pool3(x3)
x4 = self.conv4(p3)
p4 = self.pool4(x4)
x5 = self.conv5(p4)
p5 = self.pool5(x5)
x6 = self.conv6(p5)
x7 = self.conv7(x6)
sf = self.score_fr(x7)
u2 = self.upscore2(sf)
s4 = self.score_pool4(p4)
f4 = s4 + u2
u4 = self.upscore_pool4(f4)
s3 = self.score_pool3(p3)
f3 = s3 + u4
out = self.upscore8(f3)
return out
训练准备
导入VGG-16部分预训练权重
FCN使用VGG-16作为骨干网络,用于实现图像编码。使用下面代码导入VGG-16预训练模型的部分预训练权重。
[7]:
from download import download
from mindspore import load_checkpoint, load_param_into_net
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/fcn8s_vgg16_pretrain.ckpt"
download(url, "fcn8s_vgg16_pretrain.ckpt", replace=True)
def load_vgg16():
ckpt_vgg16 = "fcn8s_vgg16_pretrain.ckpt"
param_vgg = load_checkpoint(ckpt_vgg16)
load_param_into_net(net, param_vgg)
损失函数
语义分割是对图像中每个像素点进行分类,仍是分类问题,故损失函数选择交叉熵损失函数来计算FCN网络输出与mask之间的交叉熵损失。这里我们使用的是mindspore.nn.CrossEntropyLoss()作为损失函数。
自定义评价指标 Metrics
这一部分主要对训练出来的模型效果进行评估,为了便于解释,假设如下:共有 𝑘+1𝑘+1 个类(从 𝐿0𝐿0 到 𝐿𝑘𝐿𝑘, 其中包含一个空类或背景), 𝑝𝑖𝑗𝑝𝑖𝑗 表示本属于𝑖𝑖类但被预测为𝑗𝑗类的像素数量。即, 𝑝𝑖𝑖𝑝𝑖𝑖 表示真正的数量, 而 𝑝𝑖𝑗𝑝𝑗𝑖𝑝𝑖𝑗𝑝𝑗𝑖 则分别被解释为假正和假负, 尽管两者都是假正与假负之和。
- Pixel Accuracy(PA, 像素精度):这是最简单的度量,为标记正确的像素占总像素的比例。
𝑃𝐴=∑𝑘𝑖=0𝑝𝑖𝑖∑𝑘𝑖=0∑𝑘𝑗=0𝑝𝑖𝑗𝑃𝐴=∑𝑖=0𝑘𝑝𝑖𝑖∑𝑖=0𝑘∑𝑗=0𝑘𝑝𝑖𝑗
- Mean Pixel Accuracy(MPA, 均像素精度):是PA的一种简单提升,计算每个类内被正确分类像素数的比例,之后求所有类的平均。
𝑀𝑃𝐴=1𝑘+1∑𝑖=0𝑘𝑝𝑖𝑖∑𝑘𝑗=0𝑝𝑖𝑗𝑀𝑃𝐴=1𝑘+1∑𝑖=0𝑘𝑝𝑖𝑖∑𝑗=0𝑘𝑝𝑖𝑗
- Mean Intersection over Union(MloU, 均交并比):为语义分割的标准度量。其计算两个集合的交集和并集之,在语义分割的问题中,这两个集合为真实值(ground truth) 和预测值(predicted segmentation)。这个比例可以变形为正真数 (intersection) 比上真正、假负、假正(并集)之和。在每个类上计算loU,之后平均。
𝑀𝐼𝑜𝑈=1𝑘+1∑𝑖=0𝑘𝑝𝑖𝑖∑𝑘𝑗=0𝑝𝑖𝑗+∑𝑘𝑗=0𝑝𝑗𝑖−𝑝𝑖𝑖𝑀𝐼𝑜𝑈=1𝑘+1∑𝑖=0𝑘𝑝𝑖𝑖∑𝑗=0𝑘𝑝𝑖𝑗+∑𝑗=0𝑘𝑝𝑗𝑖−𝑝𝑖𝑖
- Frequency Weighted Intersection over Union(FWIoU, 频权交井比):为MloU的一种提升,这种方法根据每个类出现的频率为其设置权重。
𝐹𝑊𝐼𝑜𝑈=1∑𝑘𝑖=0∑𝑘𝑗=0𝑝𝑖𝑗∑𝑖=0𝑘𝑝𝑖𝑖∑𝑘𝑗=0𝑝𝑖𝑗+∑𝑘𝑗=0𝑝𝑗𝑖−𝑝𝑖𝑖𝐹𝑊𝐼𝑜𝑈=1∑𝑖=0𝑘∑𝑗=0𝑘𝑝𝑖𝑗∑𝑖=0𝑘𝑝𝑖𝑖∑𝑗=0𝑘𝑝𝑖𝑗+∑𝑗=0𝑘𝑝𝑗𝑖−𝑝𝑖𝑖
[8]:
import numpy as np
import mindspore as ms
import mindspore.nn as nn
import mindspore.train as train
class PixelAccuracy(train.Metric):
def __init__(self, num_class=21):
super(PixelAccuracy, self).__init__()
self.num_class = num_class
def _generate_matrix(self, gt_image, pre_image):
mask = (gt_image >= 0) & (gt_image < self.num_class)
label = self.num_class * gt_image[mask].astype('int') + pre_image[mask]
count = np.bincount(label, minlength=self.num_class**2)
confusion_matrix = count.reshape(self.num_class, self.num_class)
return confusion_matrix
def clear(self):
self.confusion_matrix = np.zeros((self.num_class,) * 2)
def update(self, *inputs):
y_pred = inputs[0].asnumpy().argmax(axis=1)
y = inputs[1].asnumpy().reshape(4, 512, 512)
self.confusion_matrix += self._generate_matrix(y, y_pred)
def eval(self):
pixel_accuracy = np.diag(self.confusion_matrix).sum() / self.confusion_matrix.sum()
return pixel_accuracy
class PixelAccuracyClass(train.Metric):
def __init__(self, num_class=21):
super(PixelAccuracyClass, self).__init__()
self.num_class = num_class
def _generate_matrix(self, gt_image, pre_image):
mask = (gt_image >= 0) & (gt_image < self.num_class)
label = self.num_class * gt_image[mask].astype('int') + pre_image[mask]
count = np.bincount(label, minlength=self.num_class**2)
confusion_matrix = count.reshape(self.num_class, self.num_class)
return confusion_matrix
def update(self, *inputs):
y_pred = inputs[0].asnumpy().argmax(axis=1)
y = inputs[1].asnumpy().reshape(4, 512, 512)
self.confusion_matrix += self._generate_matrix(y, y_pred)
def clear(self):
self.confusion_matrix = np.zeros((self.num_class,) * 2)
def eval(self):
mean_pixel_accuracy = np.diag(self.confusion_matrix) / self.confusion_matrix.sum(axis=1)
mean_pixel_accuracy = np.nanmean(mean_pixel_accuracy)
return mean_pixel_accuracy
class MeanIntersectionOverUnion(train.Metric):
def __init__(self, num_class=21):
super(MeanIntersectionOverUnion, self).__init__()
self.num_class = num_class
def _generate_matrix(self, gt_image, pre_image):
mask = (gt_image >= 0) & (gt_image < self.num_class)
label = self.num_class * gt_image[mask].astype('int') + pre_image[mask]
count = np.bincount(label, minlength=self.num_class**2)
confusion_matrix = count.reshape(self.num_class, self.num_class)
return confusion_matrix
def update(self, *inputs):
y_pred = inputs[0].asnumpy().argmax(axis=1)
y = inputs[1].asnumpy().reshape(4, 512, 512)
self.confusion_matrix += self._generate_matrix(y, y_pred)
def clear(self):
self.confusion_matrix = np.zeros((self.num_class,) * 2)
def eval(self):
mean_iou = np.diag(self.confusion_matrix) / (
np.sum(self.confusion_matrix, axis=1) + np.sum(self.confusion_matrix, axis=0) -
np.diag(self.confusion_matrix))
mean_iou = np.nanmean(mean_iou)
return mean_iou
class FrequencyWeightedIntersectionOverUnion(train.Metric):
def __init__(self, num_class=21):
super(FrequencyWeightedIntersectionOverUnion, self).__init__()
self.num_class = num_class
def _generate_matrix(self, gt_image, pre_image):
mask = (gt_image >= 0) & (gt_image < self.num_class)
label = self.num_class * gt_image[mask].astype('int') + pre_image[mask]
count = np.bincount(label, minlength=self.num_class**2)
confusion_matrix = count.reshape(self.num_class, self.num_class)
return confusion_matrix
def update(self, *inputs):
y_pred = inputs[0].asnumpy().argmax(axis=1)
y = inputs[1].asnumpy().reshape(4, 512, 512)
self.confusion_matrix += self._generate_matrix(y, y_pred)
def clear(self):
self.confusion_matrix = np.zeros((self.num_class,) * 2)
def eval(self):
freq = np.sum(self.confusion_matrix, axis=1) / np.sum(self.confusion_matrix)
iu = np.diag(self.confusion_matrix) / (
np.sum(self.confusion_matrix, axis=1) + np.sum(self.confusion_matrix, axis=0) -
np.diag(self.confusion_matrix))
frequency_weighted_iou = (freq[freq > 0] * iu[freq > 0]).sum()
return frequency_weighted_iou
模型训练
导入VGG-16预训练参数后,实例化损失函数、优化器,使用Model接口编译网络,训练FCN-8s网络。
import mindspore
from mindspore import Tensor
import mindspore.nn as nn
from mindspore.train import ModelCheckpoint, CheckpointConfig, LossMonitor, TimeMonitor, Model
device_target = "Ascend"
mindspore.set_context(mode=mindspore.PYNATIVE_MODE, device_target=device_target)
train_batch_size = 4
num_classes = 21
# 初始化模型结构
net = FCN8s(n_class=21)
# 导入vgg16预训练参数
load_vgg16()
# 计算学习率
min_lr = 0.0005
base_lr = 0.05
train_epochs = 1
iters_per_epoch = dataset.get_dataset_size()
total_step = iters_per_epoch * train_epochs
lr_scheduler = mindspore.nn.cosine_decay_lr(min_lr,
base_lr,
total_step,
iters_per_epoch,
decay_epoch=2)
lr = Tensor(lr_scheduler[-1])
# 定义损失函数
loss = nn.CrossEntropyLoss(ignore_index=255)
# 定义优化器
optimizer = nn.Momentum(params=net.trainable_params(), learning_rate=lr, momentum=0.9, weight_decay=0.0001)
# 定义loss_scale
scale_factor = 4
scale_window = 3000
loss_scale_manager = ms.amp.DynamicLossScaleManager(scale_factor, scale_window)
# 初始化模型
if device_target == "Ascend":
model = Model(net, loss_fn=loss, optimizer=optimizer, loss_scale_manager=loss_scale_manager, metrics={"pixel accuracy": PixelAccuracy(), "mean pixel accuracy": PixelAccuracyClass(), "mean IoU": MeanIntersectionOverUnion(), "frequency weighted IoU": FrequencyWeightedIntersectionOverUnion()})
else:
model = Model(net, loss_fn=loss, optimizer=optimizer, metrics={"pixel accuracy": PixelAccuracy(), "mean pixel accuracy": PixelAccuracyClass(), "mean IoU": MeanIntersectionOverUnion(), "frequency weighted IoU": FrequencyWeightedIntersectionOverUnion()})
# 设置ckpt文件保存的参数
time_callback = TimeMonitor(data_size=iters_per_epoch)
loss_callback = LossMonitor()
callbacks = [time_callback, loss_callback]
save_steps = 330
keep_checkpoint_max = 5
config_ckpt = CheckpointConfig(save_checkpoint_steps=10,
keep_checkpoint_max=keep_checkpoint_max)
ckpt_callback = ModelCheckpoint(prefix="FCN8s",
directory="./ckpt",
config=config_ckpt)
callbacks.append(ckpt_callback)
model.train(train_epochs, dataset, callbacks=callbacks)
epoch: 1 step: 1, loss is 3.05394
epoch: 1 step: 2, loss is 3.0132477
epoch: 1 step: 3, loss is 2.9661493
epoch: 1 step: 4, loss is 2.9077418
epoch: 1 step: 5, loss is 2.636743
......
因为FCN网络在训练的过程中需要大量的训练数据和训练轮数,这里只提供了小数据单个epoch的训练来演示loss收敛的过程,下文中使用已训练好的权重文件进行模型评估和推理效果的展示。
模型评估
IMAGE_MEAN = [103.53, 116.28, 123.675]
IMAGE_STD = [57.375, 57.120, 58.395]
DATA_FILE = "dataset/dataset_fcn8s/mindname.mindrecord"
# 下载已训练好的权重文件
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/FCN8s.ckpt"
download(url, "FCN8s.ckpt", replace=True)
net = FCN8s(n_class=num_classes)
ckpt_file = "FCN8s.ckpt"
param_dict = load_checkpoint(ckpt_file)
load_param_into_net(net, param_dict)
if device_target == "Ascend":
model = Model(net, loss_fn=loss, optimizer=optimizer, loss_scale_manager=loss_scale_manager, metrics={"pixel accuracy": PixelAccuracy(), "mean pixel accuracy": PixelAccuracyClass(), "mean IoU": MeanIntersectionOverUnion(), "frequency weighted IoU": FrequencyWeightedIntersectionOverUnion()})
else:
model = Model(net, loss_fn=loss, optimizer=optimizer, metrics={"pixel accuracy": PixelAccuracy(), "mean pixel accuracy": PixelAccuracyClass(), "mean IoU": MeanIntersectionOverUnion(), "frequency weighted IoU": FrequencyWeightedIntersectionOverUnion()})
# 实例化Dataset
dataset = SegDataset(image_mean=IMAGE_MEAN,
image_std=IMAGE_STD,
data_file=DATA_FILE,
batch_size=train_batch_size,
crop_size=crop_size,
max_scale=max_scale,
min_scale=min_scale,
ignore_label=ignore_label,
num_classes=num_classes,
num_readers=2,
num_parallel_calls=4)
dataset_eval = dataset.get_dataset()
model.eval(dataset_eval)
模型推理
使用训练的网络对模型推理结果进行展示。
import cv2
import matplotlib.pyplot as plt
net = FCN8s(n_class=num_classes)
# 设置超参
ckpt_file = "FCN8s.ckpt"
param_dict = load_checkpoint(ckpt_file)
load_param_into_net(net, param_dict)
eval_batch_size = 4
img_lst = []
mask_lst = []
res_lst = []
# 推理效果展示(上方为输入图片,下方为推理效果图片)
plt.figure(figsize=(8, 5))
show_data = next(dataset_eval.create_dict_iterator())
show_images = show_data["data"].asnumpy()
mask_images = show_data["label"].reshape([4, 512, 512])
show_images = np.clip(show_images, 0, 1)
for i in range(eval_batch_size):
img_lst.append(show_images[i])
mask_lst.append(mask_images[i])
res = net(show_data["data"]).asnumpy().argmax(axis=1)
for i in range(eval_batch_size):
plt.subplot(2, 4, i + 1)
plt.imshow(img_lst[i].transpose(1, 2, 0))
plt.axis("off")
plt.subplots_adjust(wspace=0.05, hspace=0.02)
plt.subplot(2, 4, i + 5)
plt.imshow(res[i])
plt.axis("off")
plt.subplots_adjust(wspace=0.05, hspace=0.02)
plt.show()
总结
FCN的核心贡献在于提出使用全卷积层,通过学习让图片实现端到端分割。与传统使用CNN进行图像分割的方法相比,FCN有两大明显的优点:一是可以接受任意大小的输入图像,无需要求所有的训练图像和测试图像具有固定的尺寸。二是更加高效,避免了由于使用像素块而带来的重复存储和计算卷积的问题。
同时FCN网络也存在待改进之处:
一是得到的结果仍不够精细。进行8倍上采样虽然比32倍的效果好了很多,但是上采样的结果仍比较模糊和平滑,尤其是边界处,网络对图像中的细节不敏感。 二是对各个像素进行分类,没有充分考虑像素与像素之间的关系(如不连续性和相似性)。忽略了在通常的基于像素分类的分割方法中使用的空间规整(spatial regularization)步骤,缺乏空间一致性
十一 第十一天 ResNet50迁移学习
数据准备
下载数据集
下载案例所用到的狗与狼分类数据集,数据集中的图像来自于ImageNet,每个分类有大约120张训练图像与30张验证图像。使用download接口下载数据集,并将下载后的数据集自动解压到当前目录下。
[1]:
%%capture captured_output
# 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
!pip uninstall mindspore -y
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
[2]:
# 查看当前 mindspore 版本
!pip show mindspore
Name: mindspore
Version: 2.2.14
Summary: MindSpore is a new open source deep learning training/inference framework that could be used for mobile, edge and cloud scenarios.
Home-page: https://www.mindspore.cn
Author: The MindSpore Authors
Author-email: contact@mindspore.cn
License: Apache 2.0
Location: /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages
Requires: asttokens, astunparse, numpy, packaging, pillow, protobuf, psutil, scipy
Required-by:
[3]:
from download import download
dataset_url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/intermediate/Canidae_data.zip"
download(dataset_url, "./datasets-Canidae", kind="zip", replace=True)
数据集的目录结构如下:
datasets-Canidae/data/
└── Canidae
├── train
│ ├── dogs
│ └── wolves
└── val
├── dogs
└── wolves
加载数据集
狼狗数据集提取自ImageNet分类数据集,使用mindspore.dataset.ImageFolderDataset接口来加载数据集,并进行相关图像增强操作。
首先执行过程定义一些输入:
[4]:
batch_size = 18 # 批量大小
image_size = 224 # 训练图像空间大小
num_epochs = 5 # 训练周期数
lr = 0.001 # 学习率
momentum = 0.9 # 动量
workers = 4 # 并行线程个数
[5]:
import mindspore as ms
import mindspore.dataset as ds
import mindspore.dataset.vision as vision
# 数据集目录路径
data_path_train = "./datasets-Canidae/data/Canidae/train/"
data_path_val = "./datasets-Canidae/data/Canidae/val/"
# 创建训练数据集
def create_dataset_canidae(dataset_path, usage):
"""数据加载"""
data_set = ds.ImageFolderDataset(dataset_path,
num_parallel_workers=workers,
shuffle=True,)
# 数据增强操作
mean = [0.485 * 255, 0.456 * 255, 0.406 * 255]
std = [0.229 * 255, 0.224 * 255, 0.225 * 255]
scale = 32
if usage == "train":
# Define map operations for training dataset
trans = [
vision.RandomCropDecodeResize(size=image_size, scale=(0.08, 1.0), ratio=(0.75, 1.333)),
vision.RandomHorizontalFlip(prob=0.5),
vision.Normalize(mean=mean, std=std),
vision.HWC2CHW()
]
else:
# Define map operations for inference dataset
trans = [
vision.Decode(),
vision.Resize(image_size + scale),
vision.CenterCrop(image_size),
vision.Normalize(mean=mean, std=std),
vision.HWC2CHW()
]
# 数据映射操作
data_set = data_set.map(
operations=trans,
input_columns='image',
num_parallel_workers=workers)
# 批量操作
data_set = data_set.batch(batch_size)
return data_set
dataset_train = create_dataset_canidae(data_path_train, "train")
step_size_train = dataset_train.get_dataset_size()
dataset_val = create_dataset_canidae(data_path_val, "val")
step_size_val = dataset_val.get_dataset_size()
数据集可视化
从mindspore.dataset.ImageFolderDataset接口中加载的训练数据集返回值为字典,用户可通过 create_dict_iterator 接口创建数据迭代器,使用 next 迭代访问数据集。本章中 batch_size 设为18,所以使用 next 一次可获取18个图像及标签数据。
[6]:
data = next(dataset_train.create_dict_iterator())
images = data["image"]
labels = data["label"]
print("Tensor of image", images.shape)
print("Labels:", labels)
Tensor of image (18, 3, 224, 224)
Labels: [1 0 1 0 0 1 1 1 0 1 0 0 1 0 1 1 1 0]
对获取到的图像及标签数据进行可视化,标题为图像对应的label名称。
[7]:
import matplotlib.pyplot as plt
import numpy as np
# class_name对应label,按文件夹字符串从小到大的顺序标记label
class_name = {0: "dogs", 1: "wolves"}
plt.figure(figsize=(5, 5))
for i in range(4):
# 获取图像及其对应的label
data_image = images[i].asnumpy()
data_label = labels[i]
# 处理图像供展示使用
data_image = np.transpose(data_image, (1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
data_image = std * data_image + mean
data_image = np.clip(data_image, 0, 1)
# 显示图像
plt.subplot(2, 2, i+1)
plt.imshow(data_image)
plt.title(class_name[int(labels[i].asnumpy())])
plt.axis("off")
plt.show()

训练模型
本章使用ResNet50模型进行训练。搭建好模型框架后,通过将pretrained参数设置为True来下载ResNet50的预训练模型并将权重参数加载到网络中。
构建Resnet50网络
[8]:
from typing import Type, Union, List, Optional
from mindspore import nn, train
from mindspore.common.initializer import Normal
weight_init = Normal(mean=0, sigma=0.02)
gamma_init = Normal(mean=1, sigma=0.02)
[9]:
class ResidualBlockBase(nn.Cell):
expansion: int = 1 # 最后一个卷积核数量与第一个卷积核数量相等
def __init__(self, in_channel: int, out_channel: int,
stride: int = 1, norm: Optional[nn.Cell] = None,
down_sample: Optional[nn.Cell] = None) -> None:
super(ResidualBlockBase, self).__init__()
if not norm:
self.norm = nn.BatchNorm2d(out_channel)
else:
self.norm = norm
self.conv1 = nn.Conv2d(in_channel, out_channel,
kernel_size=3, stride=stride,
weight_init=weight_init)
self.conv2 = nn.Conv2d(in_channel, out_channel,
kernel_size=3, weight_init=weight_init)
self.relu = nn.ReLU()
self.down_sample = down_sample
def construct(self, x):
"""ResidualBlockBase construct."""
identity = x # shortcuts分支
out = self.conv1(x) # 主分支第一层:3*3卷积层
out = self.norm(out)
out = self.relu(out)
out = self.conv2(out) # 主分支第二层:3*3卷积层
out = self.norm(out)
if self.down_sample is not None:
identity = self.down_sample(x)
out += identity # 输出为主分支与shortcuts之和
out = self.relu(out)
return out
[10]:
class ResidualBlock(nn.Cell):
expansion = 4 # 最后一个卷积核的数量是第一个卷积核数量的4倍
def __init__(self, in_channel: int, out_channel: int,
stride: int = 1, down_sample: Optional[nn.Cell] = None) -> None:
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channel, out_channel,
kernel_size=1, weight_init=weight_init)
self.norm1 = nn.BatchNorm2d(out_channel)
self.conv2 = nn.Conv2d(out_channel, out_channel,
kernel_size=3, stride=stride,
weight_init=weight_init)
self.norm2 = nn.BatchNorm2d(out_channel)
self.conv3 = nn.Conv2d(out_channel, out_channel * self.expansion,
kernel_size=1, weight_init=weight_init)
self.norm3 = nn.BatchNorm2d(out_channel * self.expansion)
self.relu = nn.ReLU()
self.down_sample = down_sample
def construct(self, x):
identity = x # shortscuts分支
out = self.conv1(x) # 主分支第一层:1*1卷积层
out = self.norm1(out)
out = self.relu(out)
out = self.conv2(out) # 主分支第二层:3*3卷积层
out = self.norm2(out)
out = self.relu(out)
out = self.conv3(out) # 主分支第三层:1*1卷积层
out = self.norm3(out)
if self.down_sample is not None:
identity = self.down_sample(x)
out += identity # 输出为主分支与shortcuts之和
out = self.relu(out)
return out
[11]:
def make_layer(last_out_channel, block: Type[Union[ResidualBlockBase, ResidualBlock]],
channel: int, block_nums: int, stride: int = 1):
down_sample = None # shortcuts分支
if stride != 1 or last_out_channel != channel * block.expansion:
down_sample = nn.SequentialCell([
nn.Conv2d(last_out_channel, channel * block.expansion,
kernel_size=1, stride=stride, weight_init=weight_init),
nn.BatchNorm2d(channel * block.expansion, gamma_init=gamma_init)
])
layers = []
layers.append(block(last_out_channel, channel, stride=stride, down_sample=down_sample))
in_channel = channel * block.expansion
# 堆叠残差网络
for _ in range(1, block_nums):
layers.append(block(in_channel, channel))
return nn.SequentialCell(layers)
[12]:
from mindspore import load_checkpoint, load_param_into_net
class ResNet(nn.Cell):
def __init__(self, block: Type[Union[ResidualBlockBase, ResidualBlock]],
layer_nums: List[int], num_classes: int, input_channel: int) -> None:
super(ResNet, self).__init__()
self.relu = nn.ReLU()
# 第一个卷积层,输入channel为3(彩色图像),输出channel为64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, weight_init=weight_init)
self.norm = nn.BatchNorm2d(64)
# 最大池化层,缩小图片的尺寸
self.max_pool = nn.MaxPool2d(kernel_size=3, stride=2, pad_mode='same')
# 各个残差网络结构块定义,
self.layer1 = make_layer(64, block, 64, layer_nums[0])
self.layer2 = make_layer(64 * block.expansion, block, 128, layer_nums[1], stride=2)
self.layer3 = make_layer(128 * block.expansion, block, 256, layer_nums[2], stride=2)
self.layer4 = make_layer(256 * block.expansion, block, 512, layer_nums[3], stride=2)
# 平均池化层
self.avg_pool = nn.AvgPool2d()
# flattern层
self.flatten = nn.Flatten()
# 全连接层
self.fc = nn.Dense(in_channels=input_channel, out_channels=num_classes)
def construct(self, x):
x = self.conv1(x)
x = self.norm(x)
x = self.relu(x)
x = self.max_pool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avg_pool(x)
x = self.flatten(x)
x = self.fc(x)
return x
def _resnet(model_url: str, block: Type[Union[ResidualBlockBase, ResidualBlock]],
layers: List[int], num_classes: int, pretrained: bool, pretrianed_ckpt: str,
input_channel: int):
model = ResNet(block, layers, num_classes, input_channel)
if pretrained:
# 加载预训练模型
download(url=model_url, path=pretrianed_ckpt, replace=True)
param_dict = load_checkpoint(pretrianed_ckpt)
load_param_into_net(model, param_dict)
return model
def resnet50(num_classes: int = 1000, pretrained: bool = False):
"ResNet50模型"
resnet50_url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/models/application/resnet50_224_new.ckpt"
resnet50_ckpt = "./LoadPretrainedModel/resnet50_224_new.ckpt"
return _resnet(resnet50_url, ResidualBlock, [3, 4, 6, 3], num_classes,
pretrained, resnet50_ckpt, 2048)
固定特征进行训练
使用固定特征进行训练的时候,需要冻结除最后一层之外的所有网络层。通过设置 requires_grad == False 冻结参数,以便不在反向传播中计算梯度。
[13]:
import mindspore as ms
import matplotlib.pyplot as plt
import os
import time
net_work = resnet50(pretrained=True)
# 全连接层输入层的大小
in_channels = net_work.fc.in_channels
# 输出通道数大小为狼狗分类数2
head = nn.Dense(in_channels, 2)
# 重置全连接层
net_work.fc = head
# 平均池化层kernel size为7
avg_pool = nn.AvgPool2d(kernel_size=7)
# 重置平均池化层
net_work.avg_pool = avg_pool
# 冻结除最后一层外的所有参数
for param in net_work.get_parameters():
if param.name not in ["fc.weight", "fc.bias"]:
param.requires_grad = False
# 定义优化器和损失函数
opt = nn.Momentum(params=net_work.trainable_params(), learning_rate=lr, momentum=0.5)
loss_fn = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
def forward_fn(inputs, targets):
logits = net_work(inputs)
loss = loss_fn(logits, targets)
return loss
grad_fn = ms.value_and_grad(forward_fn, None, opt.parameters)
def train_step(inputs, targets):
loss, grads = grad_fn(inputs, targets)
opt(grads)
return loss
# 实例化模型
model1 = train.Model(net_work, loss_fn, opt, metrics={"Accuracy": train.Accuracy()})
Downloading data from https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/models/application/resnet50_224_new.ckpt (97.7 MB) file_sizes: 100%|████████████████████████████| 102M/102M [00:01<00:00, 98.7MB/s] Successfully downloaded file to ./LoadPretrainedModel/resnet50_224_new.ckpt
训练和评估
开始训练模型,与没有预训练模型相比,将节约一大半时间,因为此时可以不用计算部分梯度。保存评估精度最高的ckpt文件于当前路径的./BestCheckpoint/resnet50-best-freezing-param.ckpt。
[14]:
import mindspore as ms
import matplotlib.pyplot as plt
import os
import time
dataset_train = create_dataset_canidae(data_path_train, "train")
step_size_train = dataset_train.get_dataset_size()
dataset_val = create_dataset_canidae(data_path_val, "val")
step_size_val = dataset_val.get_dataset_size()
num_epochs = 5
# 创建迭代器
data_loader_train = dataset_train.create_tuple_iterator(num_epochs=num_epochs)
data_loader_val = dataset_val.create_tuple_iterator(num_epochs=num_epochs)
best_ckpt_dir = "./BestCheckpoint"
best_ckpt_path = "./BestCheckpoint/resnet50-best-freezing-param.ckpt"
[15]:
import mindspore as ms
import matplotlib.pyplot as plt
import os
import time
# 开始循环训练
print("Start Training Loop ...")
best_acc = 0
for epoch in range(num_epochs):
losses = []
net_work.set_train()
epoch_start = time.time()
# 为每轮训练读入数据
for i, (images, labels) in enumerate(data_loader_train):
labels = labels.astype(ms.int32)
loss = train_step(images, labels)
losses.append(loss)
# 每个epoch结束后,验证准确率
acc = model1.eval(dataset_val)['Accuracy']
epoch_end = time.time()
epoch_seconds = (epoch_end - epoch_start) * 1000
step_seconds = epoch_seconds/step_size_train
print("-" * 20)
print("Epoch: [%3d/%3d], Average Train Loss: [%5.3f], Accuracy: [%5.3f]" % (
epoch+1, num_epochs, sum(losses)/len(losses), acc
))
print("epoch time: %5.3f ms, per step time: %5.3f ms" % (
epoch_seconds, step_seconds
))
if acc > best_acc:
best_acc = acc
if not os.path.exists(best_ckpt_dir):
os.mkdir(best_ckpt_dir)
ms.save_checkpoint(net_work, best_ckpt_path)
print("=" * 80)
print(f"End of validation the best Accuracy is: {best_acc: 5.3f}, "
f"save the best ckpt file in {best_ckpt_path}", flush=True)
Start Training Loop ... -------------------- Epoch: [ 1/ 5], Average Train Loss: [0.668], Accuracy: [0.767] epoch time: 113742.394 ms, per step time: 8124.457 ms -------------------- Epoch: [ 2/ 5], Average Train Loss: [0.567], Accuracy: [0.917] epoch time: 762.233 ms, per step time: 54.445 ms -------------------- Epoch: [ 3/ 5], Average Train Loss: [0.501], Accuracy: [0.983] epoch time: 747.744 ms, per step time: 53.410 ms -------------------- Epoch: [ 4/ 5], Average Train Loss: [0.433], Accuracy: [0.983] epoch time: 705.954 ms, per step time: 50.425 ms -------------------- Epoch: [ 5/ 5], Average Train Loss: [0.390], Accuracy: [1.000] epoch time: 752.829 ms, per step time: 53.774 ms ================================================================================ End of validation the best Accuracy is: 1.000, save the best ckpt file in ./BestCheckpoint/resnet50-best-freezing-param.ckpt
可视化模型预测
使用固定特征得到的best.ckpt文件对对验证集的狼和狗图像数据进行预测。若预测字体为蓝色即为预测正确,若预测字体为红色则预测错误。
[16]:
import matplotlib.pyplot as plt
import mindspore as ms
def visualize_model(best_ckpt_path, val_ds):
net = resnet50()
# 全连接层输入层的大小
in_channels = net.fc.in_channels
# 输出通道数大小为狼狗分类数2
head = nn.Dense(in_channels, 2)
# 重置全连接层
net.fc = head
# 平均池化层kernel size为7
avg_pool = nn.AvgPool2d(kernel_size=7)
# 重置平均池化层
net.avg_pool = avg_pool
# 加载模型参数
param_dict = ms.load_checkpoint(best_ckpt_path)
ms.load_param_into_net(net, param_dict)
model = train.Model(net)
# 加载验证集的数据进行验证
data = next(val_ds.create_dict_iterator())
images = data["image"].asnumpy()
labels = data["label"].asnumpy()
class_name = {0: "dogs", 1: "wolves"}
# 预测图像类别
output = model.predict(ms.Tensor(data['image']))
pred = np.argmax(output.asnumpy(), axis=1)
# 显示图像及图像的预测值
plt.figure(figsize=(5, 5))
for i in range(4):
plt.subplot(2, 2, i + 1)
# 若预测正确,显示为蓝色;若预测错误,显示为红色
color = 'blue' if pred[i] == labels[i] else 'red'
plt.title('predict:{}'.format(class_name[pred[i]]), color=color)
picture_show = np.transpose(images[i], (1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
picture_show = std * picture_show + mean
picture_show = np.clip(picture_show, 0, 1)
plt.imshow(picture_show)
plt.axis('off')
plt.show()
[17]:
visualize_model(best_ckpt_path, dataset_val)

十二 第十二天 ResNet50图像分析
图像分类是最基础的计算机视觉应用,属于有监督学习类别,如给定一张图像(猫、狗、飞机、汽车等等),判断图像所属的类别。本章将介绍使用ResNet50网络对CIFAR-10数据集进行分类。
ResNet网络介绍
ResNet50网络是2015年由微软实验室的何恺明提出,获得ILSVRC2015图像分类竞赛第一名。在ResNet网络提出之前,传统的卷积神经网络都是将一系列的卷积层和池化层堆叠得到的,但当网络堆叠到一定深度时,就会出现退化问题。下图是在CIFAR-10数据集上使用56层网络与20层网络训练误差和测试误差图,由图中数据可以看出,56层网络比20层网络训练误差和测试误差更大,随着网络的加深,其误差并没有如预想的一样减小。
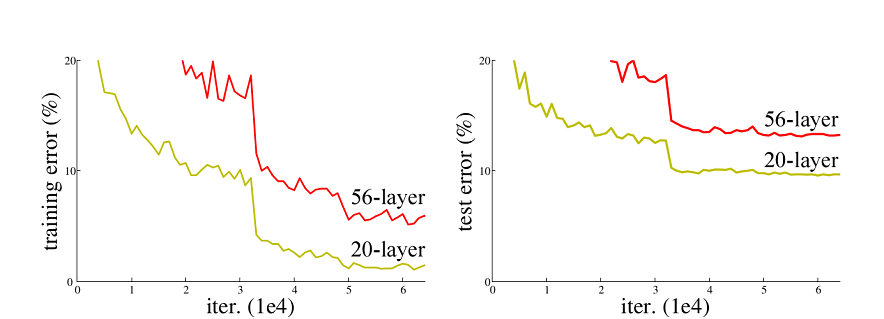
ResNet网络提出了残差网络结构(Residual Network)来减轻退化问题,使用ResNet网络可以实现搭建较深的网络结构(突破1000层)。论文中使用ResNet网络在CIFAR-10数据集上的训练误差与测试误差图如下图所示,图中虚线表示训练误差,实线表示测试误差。由图中数据可以看出,ResNet网络层数越深,其训练误差和测试误差越小。
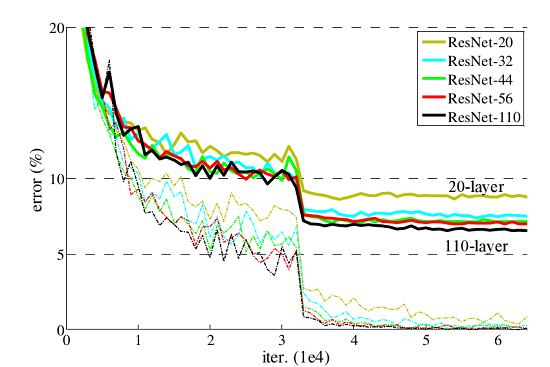
了解ResNet网络更多详细内容,参见ResNet论文。
数据集准备与加载
CIFAR-10数据集共有60000张32*32的彩色图像,分为10个类别,每类有6000张图,数据集一共有50000张训练图片和10000张评估图片。首先,如下示例使用download接口下载并解压,目前仅支持解析二进制版本的CIFAR-10文件(CIFAR-10 binary version)。
[ ]:
%%capture captured_output
# 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
!pip uninstall mindspore -y
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
[ ]:
# 查看当前 mindspore 版本
!pip show mindspore
[ ]:
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/cifar-10-binary.tar.gz"
download(url, "./datasets-cifar10-bin", kind="tar.gz", replace=True)
下载后的数据集目录结构如下:
datasets-cifar10-bin/cifar-10-batches-bin
├── batches.meta.text
├── data_batch_1.bin
├── data_batch_2.bin
├── data_batch_3.bin
├── data_batch_4.bin
├── data_batch_5.bin
├── readme.html
└── test_batch.bin
然后,使用mindspore.dataset.Cifar10Dataset接口来加载数据集,并进行相关图像增强操作。
[ ]:
import mindspore as ms
import mindspore.dataset as ds
import mindspore.dataset.vision as vision
import mindspore.dataset.transforms as transforms
from mindspore import dtype as mstype
data_dir = "./datasets-cifar10-bin/cifar-10-batches-bin" # 数据集根目录
batch_size = 256 # 批量大小
image_size = 32 # 训练图像空间大小
workers = 4 # 并行线程个数
num_classes = 10 # 分类数量
def create_dataset_cifar10(dataset_dir, usage, resize, batch_size, workers):
data_set = ds.Cifar10Dataset(dataset_dir=dataset_dir,
usage=usage,
num_parallel_workers=workers,
shuffle=True)
trans = []
if usage == "train":
trans += [
vision.RandomCrop((32, 32), (4, 4, 4, 4)),
vision.RandomHorizontalFlip(prob=0.5)
]
trans += [
vision.Resize(resize),
vision.Rescale(1.0 / 255.0, 0.0),
vision.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010]),
vision.HWC2CHW()
]
target_trans = transforms.TypeCast(mstype.int32)
# 数据映射操作
data_set = data_set.map(operations=trans,
input_columns='image',
num_parallel_workers=workers)
data_set = data_set.map(operations=target_trans,
input_columns='label',
num_parallel_workers=workers)
# 批量操作
data_set = data_set.batch(batch_size)
return data_set
# 获取处理后的训练与测试数据集
dataset_train = create_dataset_cifar10(dataset_dir=data_dir,
usage="train",
resize=image_size,
batch_size=batch_size,
workers=workers)
step_size_train = dataset_train.get_dataset_size()
dataset_val = create_dataset_cifar10(dataset_dir=data_dir,
usage="test",
resize=image_size,
batch_size=batch_size,
workers=workers)
step_size_val = dataset_val.get_dataset_size()
对CIFAR-10训练数据集进行可视化。
[ ]:
import matplotlib.pyplot as plt
import numpy as np
data_iter = next(dataset_train.create_dict_iterator())
images = data_iter["image"].asnumpy()
labels = data_iter["label"].asnumpy()
print(f"Image shape: {images.shape}, Label shape: {labels.shape}")
# 训练数据集中,前六张图片所对应的标签
print(f"Labels: {labels[:6]}")
classes = []
with open(data_dir + "/batches.meta.txt", "r") as f:
for line in f:
line = line.rstrip()
if line:
classes.append(line)
# 训练数据集的前六张图片
plt.figure()
for i in range(6):
plt.subplot(2, 3, i + 1)
image_trans = np.transpose(images[i], (1, 2, 0))
mean = np.array([0.4914, 0.4822, 0.4465])
std = np.array([0.2023, 0.1994, 0.2010])
image_trans = std * image_trans + mean
image_trans = np.clip(image_trans, 0, 1)
plt.title(f"{classes[labels[i]]}")
plt.imshow(image_trans)
plt.axis("off")
plt.show()
构建网络
残差网络结构(Residual Network)是ResNet网络的主要亮点,ResNet使用残差网络结构后可有效地减轻退化问题,实现更深的网络结构设计,提高网络的训练精度。本节首先讲述如何构建残差网络结构,然后通过堆叠残差网络来构建ResNet50网络。
构建残差网络结构
残差网络结构图如下图所示,残差网络由两个分支构成:一个主分支,一个shortcuts(图中弧线表示)。主分支通过堆叠一系列的卷积操作得到,shotcuts从输入直接到输出,主分支输出的特征矩阵𝐹(𝑥)𝐹(𝑥)加上shortcuts输出的特征矩阵𝑥𝑥得到𝐹(𝑥)+𝑥𝐹(𝑥)+𝑥,通过Relu激活函数后即为残差网络最后的输出。
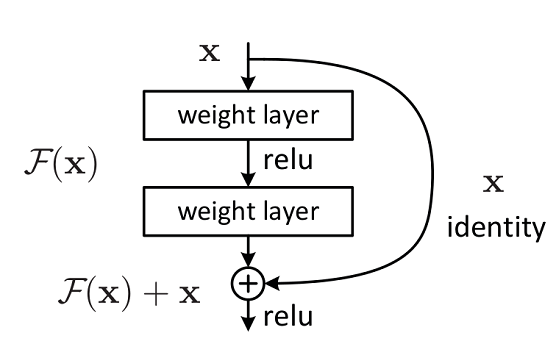
残差网络结构主要由两种,一种是Building Block,适用于较浅的ResNet网络,如ResNet18和ResNet34;另一种是Bottleneck,适用于层数较深的ResNet网络,如ResNet50、ResNet101和ResNet152。
Building Block
Building Block结构图如下图所示,主分支有两层卷积网络结构:
- 主分支第一层网络以输入channel为64为例,首先通过一个3×33×3的卷积层,然后通过Batch Normalization层,最后通过Relu激活函数层,输出channel为64;
- 主分支第二层网络的输入channel为64,首先通过一个3×33×3的卷积层,然后通过Batch Normalization层,输出channel为64。
最后将主分支输出的特征矩阵与shortcuts输出的特征矩阵相加,通过Relu激活函数即为Building Block最后的输出。
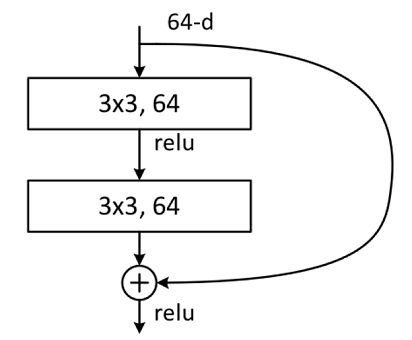
主分支与shortcuts输出的特征矩阵相加时,需要保证主分支与shortcuts输出的特征矩阵shape相同。如果主分支与shortcuts输出的特征矩阵shape不相同,如输出channel是输入channel的一倍时,shortcuts上需要使用数量与输出channel相等,大小为1×11×1的卷积核进行卷积操作;若输出的图像较输入图像缩小一倍,则要设置shortcuts中卷积操作中的stride为2,主分支第一层卷积操作的stride也需设置为2。
如下代码定义ResidualBlockBase类实现Building Block结构。
[ ]:
from typing import Type, Union, List, Optional
import mindspore.nn as nn
from mindspore.common.initializer import Normal
# 初始化卷积层与BatchNorm的参数
weight_init = Normal(mean=0, sigma=0.02)
gamma_init = Normal(mean=1, sigma=0.02)
class ResidualBlockBase(nn.Cell):
expansion: int = 1 # 最后一个卷积核数量与第一个卷积核数量相等
def __init__(self, in_channel: int, out_channel: int,
stride: int = 1, norm: Optional[nn.Cell] = None,
down_sample: Optional[nn.Cell] = None) -> None:
super(ResidualBlockBase, self).__init__()
if not norm:
self.norm = nn.BatchNorm2d(out_channel)
else:
self.norm = norm
self.conv1 = nn.Conv2d(in_channel, out_channel,
kernel_size=3, stride=stride,
weight_init=weight_init)
self.conv2 = nn.Conv2d(in_channel, out_channel,
kernel_size=3, weight_init=weight_init)
self.relu = nn.ReLU()
self.down_sample = down_sample
def construct(self, x):
"""ResidualBlockBase construct."""
identity = x # shortcuts分支
out = self.conv1(x) # 主分支第一层:3*3卷积层
out = self.norm(out)
out = self.relu(out)
out = self.conv2(out) # 主分支第二层:3*3卷积层
out = self.norm(out)
if self.down_sample is not None:
identity = self.down_sample(x)
out += identity # 输出为主分支与shortcuts之和
out = self.relu(out)
return out
Bottleneck
Bottleneck结构图如下图所示,在输入相同的情况下Bottleneck结构相对Building Block结构的参数数量更少,更适合层数较深的网络,ResNet50使用的残差结构就是Bottleneck。该结构的主分支有三层卷积结构,分别为1×11×1的卷积层、3×33×3卷积层和1×11×1的卷积层,其中1×11×1的卷积层分别起降维和升维的作用。
- 主分支第一层网络以输入channel为256为例,首先通过数量为64,大小为1×11×1的卷积核进行降维,然后通过Batch Normalization层,最后通过Relu激活函数层,其输出channel为64;
- 主分支第二层网络通过数量为64,大小为3×33×3的卷积核提取特征,然后通过Batch Normalization层,最后通过Relu激活函数层,其输出channel为64;
- 主分支第三层通过数量为256,大小1×11×1的卷积核进行升维,然后通过Batch Normalization层,其输出channel为256。
最后将主分支输出的特征矩阵与shortcuts输出的特征矩阵相加,通过Relu激活函数即为Bottleneck最后的输出。
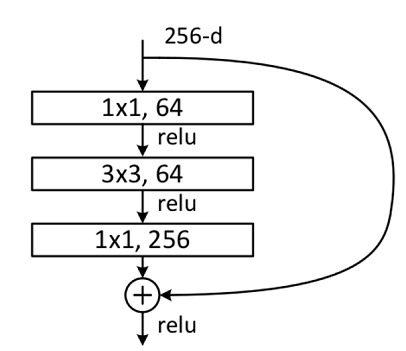
主分支与shortcuts输出的特征矩阵相加时,需要保证主分支与shortcuts输出的特征矩阵shape相同。如果主分支与shortcuts输出的特征矩阵shape不相同,如输出channel是输入channel的一倍时,shortcuts上需要使用数量与输出channel相等,大小为1×11×1的卷积核进行卷积操作;若输出的图像较输入图像缩小一倍,则要设置shortcuts中卷积操作中的stride为2,主分支第二层卷积操作的stride也需设置为2。
如下代码定义ResidualBlock类实现Bottleneck结构。
[ ]:
class ResidualBlock(nn.Cell):
expansion = 4 # 最后一个卷积核的数量是第一个卷积核数量的4倍
def __init__(self, in_channel: int, out_channel: int,
stride: int = 1, down_sample: Optional[nn.Cell] = None) -> None:
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channel, out_channel,
kernel_size=1, weight_init=weight_init)
self.norm1 = nn.BatchNorm2d(out_channel)
self.conv2 = nn.Conv2d(out_channel, out_channel,
kernel_size=3, stride=stride,
weight_init=weight_init)
self.norm2 = nn.BatchNorm2d(out_channel)
self.conv3 = nn.Conv2d(out_channel, out_channel * self.expansion,
kernel_size=1, weight_init=weight_init)
self.norm3 = nn.BatchNorm2d(out_channel * self.expansion)
self.relu = nn.ReLU()
self.down_sample = down_sample
def construct(self, x):
identity = x # shortscuts分支
out = self.conv1(x) # 主分支第一层:1*1卷积层
out = self.norm1(out)
out = self.relu(out)
out = self.conv2(out) # 主分支第二层:3*3卷积层
out = self.norm2(out)
out = self.relu(out)
out = self.conv3(out) # 主分支第三层:1*1卷积层
out = self.norm3(out)
if self.down_sample is not None:
identity = self.down_sample(x)
out += identity # 输出为主分支与shortcuts之和
out = self.relu(out)
return out
构建ResNet50网络
ResNet网络层结构如下图所示,以输入彩色图像224×224224×224为例,首先通过数量64,卷积核大小为7×77×7,stride为2的卷积层conv1,该层输出图片大小为112×112112×112,输出channel为64;然后通过一个3×33×3的最大下采样池化层,该层输出图片大小为56×5656×56,输出channel为64;再堆叠4个残差网络块(conv2_x、conv3_x、conv4_x和conv5_x),此时输出图片大小为7×77×7,输出channel为2048;最后通过一个平均池化层、全连接层和softmax,得到分类概率。
对于每个残差网络块,以ResNet50网络中的conv2_x为例,其由3个Bottleneck结构堆叠而成,每个Bottleneck输入的channel为64,输出channel为256。
如下示例定义make_layer实现残差块的构建,其参数如下所示:
last_out_channel:上一个残差网络输出的通道数。block:残差网络的类别,分别为ResidualBlockBase和ResidualBlock。channel:残差网络输入的通道数。block_nums:残差网络块堆叠的个数。stride:卷积移动的步幅。
[ ]:
def make_layer(last_out_channel, block: Type[Union[ResidualBlockBase, ResidualBlock]],
channel: int, block_nums: int, stride: int = 1):
down_sample = None # shortcuts分支
if stride != 1 or last_out_channel != channel * block.expansion:
down_sample = nn.SequentialCell([
nn.Conv2d(last_out_channel, channel * block.expansion,
kernel_size=1, stride=stride, weight_init=weight_init),
nn.BatchNorm2d(channel * block.expansion, gamma_init=gamma_init)
])
layers = []
layers.append(block(last_out_channel, channel, stride=stride, down_sample=down_sample))
in_channel = channel * block.expansion
# 堆叠残差网络
for _ in range(1, block_nums):
layers.append(block(in_channel, channel))
return nn.SequentialCell(layers)
ResNet50网络共有5个卷积结构,一个平均池化层,一个全连接层,以CIFAR-10数据集为例:
- conv1:输入图片大小为32×3232×32,输入channel为3。首先经过一个卷积核数量为64,卷积核大小为7×77×7,stride为2的卷积层;然后通过一个Batch Normalization层;最后通过Reul激活函数。该层输出feature map大小为16×1616×16,输出channel为64。
- conv2_x:输入feature map大小为16×1616×16,输入channel为64。首先经过一个卷积核大小为3×33×3,stride为2的最大下采样池化操作;然后堆叠3个[1×1,64;3×3,64;1×1,256][1×1,64;3×3,64;1×1,256]结构的Bottleneck。该层输出feature map大小为8×88×8,输出channel为256。
- conv3_x:输入feature map大小为8×88×8,输入channel为256。该层堆叠4个[1×1,128;3×3,128;1×1,512]结构的Bottleneck。该层输出feature map大小为4×44×4,输出channel为512。
- conv4_x:输入feature map大小为4×44×4,输入channel为512。该层堆叠6个[1×1,256;3×3,256;1×1,1024]结构的Bottleneck。该层输出feature map大小为2×22×2,输出channel为1024。
- conv5_x:输入feature map大小为2×22×2,输入channel为1024。该层堆叠3个[1×1,512;3×3,512;1×1,2048]结构的Bottleneck。该层输出feature map大小为1×11×1,输出channel为2048。
- average pool & fc:输入channel为2048,输出channel为分类的类别数。
如下示例代码实现ResNet50模型的构建,通过用调函数resnet50即可构建ResNet50模型,函数resnet50参数如下:
num_classes:分类的类别数,默认类别数为1000。pretrained:下载对应的训练模型,并加载预训练模型中的参数到网络中。
[ ]:
from mindspore import load_checkpoint, load_param_into_net
class ResNet(nn.Cell):
def __init__(self, block: Type[Union[ResidualBlockBase, ResidualBlock]],
layer_nums: List[int], num_classes: int, input_channel: int) -> None:
super(ResNet, self).__init__()
self.relu = nn.ReLU()
# 第一个卷积层,输入channel为3(彩色图像),输出channel为64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, weight_init=weight_init)
self.norm = nn.BatchNorm2d(64)
# 最大池化层,缩小图片的尺寸
self.max_pool = nn.MaxPool2d(kernel_size=3, stride=2, pad_mode='same')
# 各个残差网络结构块定义
self.layer1 = make_layer(64, block, 64, layer_nums[0])
self.layer2 = make_layer(64 * block.expansion, block, 128, layer_nums[1], stride=2)
self.layer3 = make_layer(128 * block.expansion, block, 256, layer_nums[2], stride=2)
self.layer4 = make_layer(256 * block.expansion, block, 512, layer_nums[3], stride=2)
# 平均池化层
self.avg_pool = nn.AvgPool2d()
# flattern层
self.flatten = nn.Flatten()
# 全连接层
self.fc = nn.Dense(in_channels=input_channel, out_channels=num_classes)
def construct(self, x):
x = self.conv1(x)
x = self.norm(x)
x = self.relu(x)
x = self.max_pool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avg_pool(x)
x = self.flatten(x)
x = self.fc(x)
return x
[ ]:
def _resnet(model_url: str, block: Type[Union[ResidualBlockBase, ResidualBlock]],
layers: List[int], num_classes: int, pretrained: bool, pretrained_ckpt: str,
input_channel: int):
model = ResNet(block, layers, num_classes, input_channel)
if pretrained:
# 加载预训练模型
download(url=model_url, path=pretrained_ckpt, replace=True)
param_dict = load_checkpoint(pretrained_ckpt)
load_param_into_net(model, param_dict)
return model
def resnet50(num_classes: int = 1000, pretrained: bool = False):
"""ResNet50模型"""
resnet50_url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/models/application/resnet50_224_new.ckpt"
resnet50_ckpt = "./LoadPretrainedModel/resnet50_224_new.ckpt"
return _resnet(resnet50_url, ResidualBlock, [3, 4, 6, 3], num_classes,
pretrained, resnet50_ckpt, 2048)
模型训练与评估
本节使用ResNet50预训练模型进行微调。调用resnet50构造ResNet50模型,并设置pretrained参数为True,将会自动下载ResNet50预训练模型,并加载预训练模型中的参数到网络中。然后定义优化器和损失函数,逐个epoch打印训练的损失值和评估精度,并保存评估精度最高的ckpt文件(resnet50-best.ckpt)到当前路径的./BestCheckPoint下。
由于预训练模型全连接层(fc)的输出大小(对应参数num_classes)为1000, 为了成功加载预训练权重,我们将模型的全连接输出大小设置为默认的1000。CIFAR10数据集共有10个分类,在使用该数据集进行训练时,需要将加载好预训练权重的模型全连接层输出大小重置为10。
此处我们展示了5个epochs的训练过程,如果想要达到理想的训练效果,建议训练80个epochs。
[ ]:
# 定义ResNet50网络
network = resnet50(pretrained=True)
# 全连接层输入层的大小
in_channel = network.fc.in_channels
fc = nn.Dense(in_channels=in_channel, out_channels=10)
# 重置全连接层
network.fc = fc
[ ]:
# 设置学习率
num_epochs = 5
lr = nn.cosine_decay_lr(min_lr=0.00001, max_lr=0.001, total_step=step_size_train * num_epochs,
step_per_epoch=step_size_train, decay_epoch=num_epochs)
# 定义优化器和损失函数
opt = nn.Momentum(params=network.trainable_params(), learning_rate=lr, momentum=0.9)
loss_fn = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
def forward_fn(inputs, targets):
logits = network(inputs)
loss = loss_fn(logits, targets)
return loss
grad_fn = ms.value_and_grad(forward_fn, None, opt.parameters)
def train_step(inputs, targets):
loss, grads = grad_fn(inputs, targets)
opt(grads)
return loss
[ ]:
import os
# 创建迭代器
data_loader_train = dataset_train.create_tuple_iterator(num_epochs=num_epochs)
data_loader_val = dataset_val.create_tuple_iterator(num_epochs=num_epochs)
# 最佳模型存储路径
best_acc = 0
best_ckpt_dir = "./BestCheckpoint"
best_ckpt_path = "./BestCheckpoint/resnet50-best.ckpt"
if not os.path.exists(best_ckpt_dir):
os.mkdir(best_ckpt_dir)
[ ]:
import mindspore.ops as ops
def train(data_loader, epoch):
"""模型训练"""
losses = []
network.set_train(True)
for i, (images, labels) in enumerate(data_loader):
loss = train_step(images, labels)
if i % 100 == 0 or i == step_size_train - 1:
print('Epoch: [%3d/%3d], Steps: [%3d/%3d], Train Loss: [%5.3f]' %
(epoch + 1, num_epochs, i + 1, step_size_train, loss))
losses.append(loss)
return sum(losses) / len(losses)
def evaluate(data_loader):
"""模型验证"""
network.set_train(False)
correct_num = 0.0 # 预测正确个数
total_num = 0.0 # 预测总数
for images, labels in data_loader:
logits = network(images)
pred = logits.argmax(axis=1) # 预测结果
correct = ops.equal(pred, labels).reshape((-1, ))
correct_num += correct.sum().asnumpy()
total_num += correct.shape[0]
acc = correct_num / total_num # 准确率
return acc
[ ]:
# 开始循环训练
print("Start Training Loop ...")
for epoch in range(num_epochs):
curr_loss = train(data_loader_train, epoch)
curr_acc = evaluate(data_loader_val)
print("-" * 50)
print("Epoch: [%3d/%3d], Average Train Loss: [%5.3f], Accuracy: [%5.3f]" % (
epoch+1, num_epochs, curr_loss, curr_acc
))
print("-" * 50)
# 保存当前预测准确率最高的模型
if curr_acc > best_acc:
best_acc = curr_acc
ms.save_checkpoint(network, best_ckpt_path)
print("=" * 80)
print(f"End of validation the best Accuracy is: {best_acc: 5.3f}, "
f"save the best ckpt file in {best_ckpt_path}", flush=True)
可视化模型预测
定义visualize_model函数,使用上述验证精度最高的模型对CIFAR-10测试数据集进行预测,并将预测结果可视化。若预测字体颜色为蓝色表示为预测正确,预测字体颜色为红色则表示预测错误。
由上面的结果可知,5个epochs下模型在验证数据集的预测准确率在70%左右,即一般情况下,6张图片中会有2张预测失败。如果想要达到理想的训练效果,建议训练80个epochs。
[ ]:
import matplotlib.pyplot as plt
def visualize_model(best_ckpt_path, dataset_val):
num_class = 10 # 对狼和狗图像进行二分类
net = resnet50(num_class)
# 加载模型参数
param_dict = ms.load_checkpoint(best_ckpt_path)
ms.load_param_into_net(net, param_dict)
# 加载验证集的数据进行验证
data = next(dataset_val.create_dict_iterator())
images = data["image"]
labels = data["label"]
# 预测图像类别
output = net(data['image'])
pred = np.argmax(output.asnumpy(), axis=1)
# 图像分类
classes = []
with open(data_dir + "/batches.meta.txt", "r") as f:
for line in f:
line = line.rstrip()
if line:
classes.append(line)
# 显示图像及图像的预测值
plt.figure()
for i in range(6):
plt.subplot(2, 3, i + 1)
# 若预测正确,显示为蓝色;若预测错误,显示为红色
color = 'blue' if pred[i] == labels.asnumpy()[i] else 'red'
plt.title('predict:{}'.format(classes[pred[i]]), color=color)
picture_show = np.transpose(images.asnumpy()[i], (1, 2, 0))
mean = np.array([0.4914, 0.4822, 0.4465])
std = np.array([0.2023, 0.1994, 0.2010])
picture_show = std * picture_show + mean
picture_show = np.clip(picture_show, 0, 1)
plt.imshow(picture_show)
plt.axis('off')
plt.show()
# 使用测试数据集进行验证
visualize_model(best_ckpt_path=best_ckpt_path, dataset_val=dataset_val)
[ ]:
import time
print(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())),'skx')
十三 第十三天 Shufflenet图形分析
ShuffleNet网络介绍
ShuffleNetV1是旷视科技提出的一种计算高效的CNN模型,和MobileNet, SqueezeNet等一样主要应用在移动端,所以模型的设计目标就是利用有限的计算资源来达到最好的模型精度。ShuffleNetV1的设计核心是引入了两种操作:Pointwise Group Convolution和Channel Shuffle,这在保持精度的同时大大降低了模型的计算量。因此,ShuffleNetV1和MobileNet类似,都是通过设计更高效的网络结构来实现模型的压缩和加速。
了解ShuffleNet更多详细内容,详见论文ShuffleNet。
如下图所示,ShuffleNet在保持不低的准确率的前提下,将参数量几乎降低到了最小,因此其运算速度较快,单位参数量对模型准确率的贡献非常高。
图片来源:Bianco S, Cadene R, Celona L, et al. Benchmark analysis of representative deep neural network architectures[J]. IEEE access, 2018, 6: 64270-64277.
模型架构
ShuffleNet最显著的特点在于对不同通道进行重排来解决Group Convolution带来的弊端。通过对ResNet的Bottleneck单元进行改进,在较小的计算量的情况下达到了较高的准确率。
Pointwise Group Convolution
Group Convolution(分组卷积)原理如下图所示,相比于普通的卷积操作,分组卷积的情况下,每一组的卷积核大小为in_channels/g*k*k,一共有g组,所有组共有(in_channels/g*k*k)*out_channels个参数,是正常卷积参数的1/g。分组卷积中,每个卷积核只处理输入特征图的一部分通道,其优点在于参数量会有所降低,但输出通道数仍等于卷积核的数量。
图片来源:Huang G, Liu S, Van der Maaten L, et al. Condensenet: An efficient densenet using learned group convolutions[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 2752-2761.
Depthwise Convolution(深度可分离卷积)将组数g分为和输入通道相等的in_channels,然后对每一个in_channels做卷积操作,每个卷积核只处理一个通道,记卷积核大小为1*k*k,则卷积核参数量为:in_channels*k*k,得到的feature maps通道数与输入通道数相等;
Pointwise Group Convolution(逐点分组卷积)在分组卷积的基础上,令每一组的卷积核大小为 1×11×1,卷积核参数量为(in_channels/g*1*1)*out_channels。
[*]:
%%capture captured_output
# 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
!pip uninstall mindspore -y
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
[*]:
# 查看当前 mindspore 版本
!pip show mindspore
[*]:
from mindspore import nn
import mindspore.ops as ops
from mindspore import Tensor
class GroupConv(nn.Cell):
def __init__(self, in_channels, out_channels, kernel_size,
stride, pad_mode="pad", pad=0, groups=1, has_bias=False):
super(GroupConv, self).__init__()
self.groups = groups
self.convs = nn.CellList()
for _ in range(groups):
self.convs.append(nn.Conv2d(in_channels // groups, out_channels // groups,
kernel_size=kernel_size, stride=stride, has_bias=has_bias,
padding=pad, pad_mode=pad_mode, group=1, weight_init='xavier_uniform'))
def construct(self, x):
features = ops.split(x, split_size_or_sections=int(len(x[0]) // self.groups), axis=1)
outputs = ()
for i in range(self.groups):
outputs = outputs + (self.convs[i](features[i].astype("float32")),)
out = ops.cat(outputs, axis=1)
return out
Channel Shuffle
Group Convolution的弊端在于不同组别的通道无法进行信息交流,堆积GConv层后一个问题是不同组之间的特征图是不通信的,这就好像分成了g个互不相干的道路,每一个人各走各的,这可能会降低网络的特征提取能力。这也是Xception,MobileNet等网络采用密集的1x1卷积(Dense Pointwise Convolution)的原因。
为了解决不同组别通道“近亲繁殖”的问题,ShuffleNet优化了大量密集的1x1卷积(在使用的情况下计算量占用率达到了惊人的93.4%),引入Channel Shuffle机制(通道重排)。这项操作直观上表现为将不同分组通道均匀分散重组,使网络在下一层能处理不同组别通道的信息。
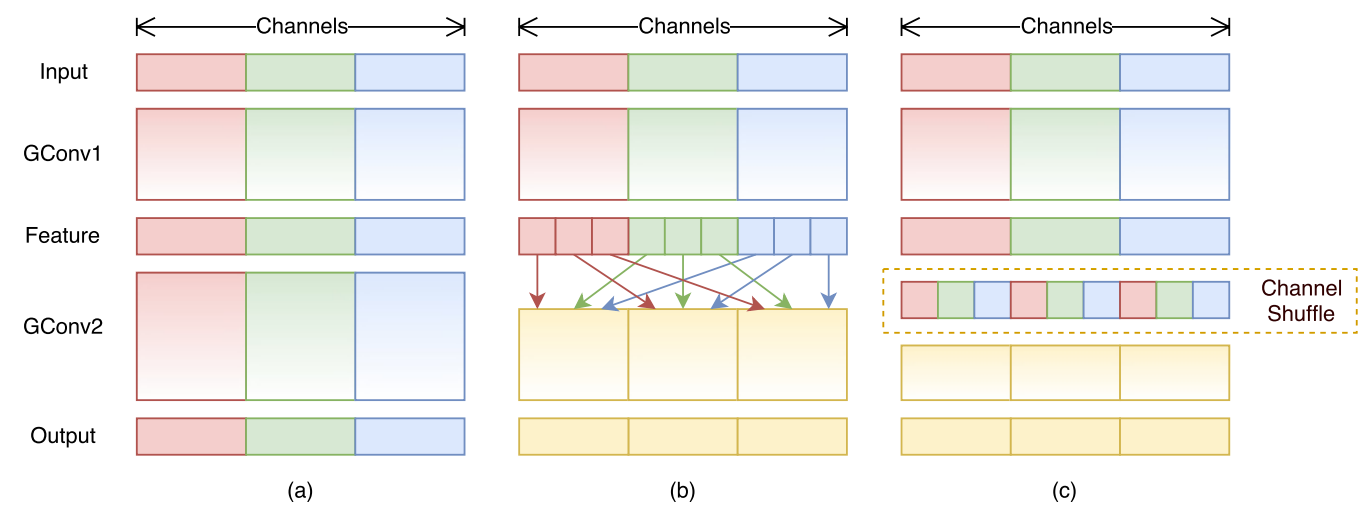
如下图所示,对于g组,每组有n个通道的特征图,首先reshape成g行n列的矩阵,再将矩阵转置成n行g列,最后进行flatten操作,得到新的排列。这些操作都是可微分可导的且计算简单,在解决了信息交互的同时符合了ShuffleNet轻量级网络设计的轻量特征。
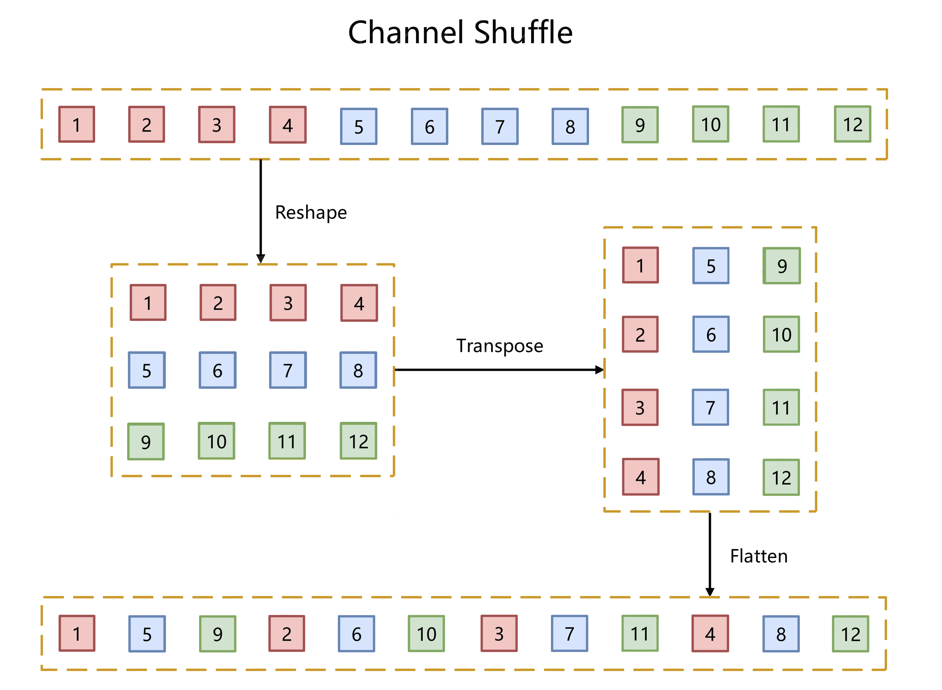
为了阅读方便,将Channel Shuffle的代码实现放在下方ShuffleNet模块的代码中。
ShuffleNet模块
如下图所示,ShuffleNet对ResNet中的Bottleneck结构进行由(a)到(b), (c)的更改:
-
将开始和最后的1×11×1卷积模块(降维、升维)改成Point Wise Group Convolution;
-
为了进行不同通道的信息交流,再降维之后进行Channel Shuffle;
-
降采样模块中,3×33×3 Depth Wise Convolution的步长设置为2,长宽降为原来的一般,因此shortcut中采用步长为2的3×33×3平均池化,并把相加改成拼接。
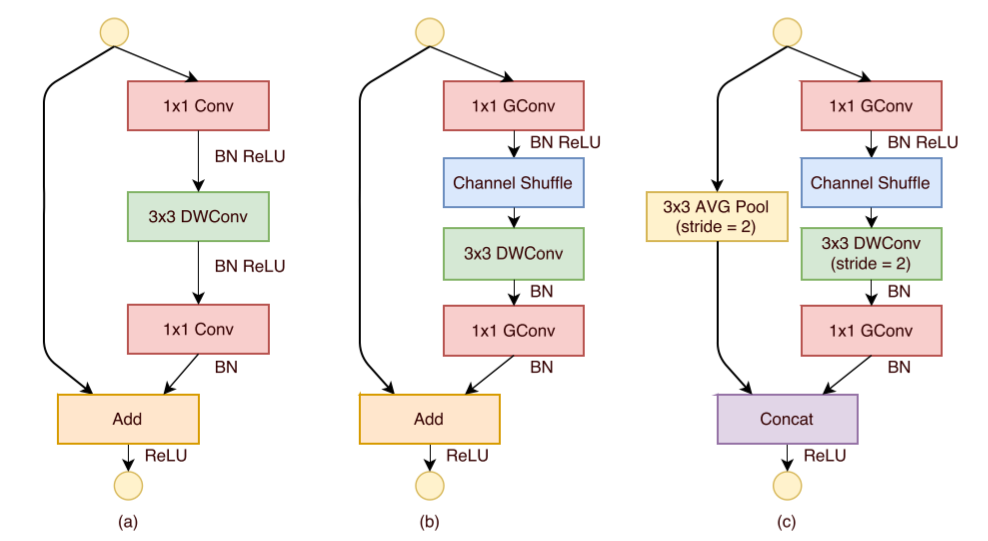
[*]:
class ShuffleV1Block(nn.Cell):
def __init__(self, inp, oup, group, first_group, mid_channels, ksize, stride):
super(ShuffleV1Block, self).__init__()
self.stride = stride
pad = ksize // 2
self.group = group
if stride == 2:
outputs = oup - inp
else:
outputs = oup
self.relu = nn.ReLU()
branch_main_1 = [
GroupConv(in_channels=inp, out_channels=mid_channels,
kernel_size=1, stride=1, pad_mode="pad", pad=0,
groups=1 if first_group else group),
nn.BatchNorm2d(mid_channels),
nn.ReLU(),
]
branch_main_2 = [
nn.Conv2d(mid_channels, mid_channels, kernel_size=ksize, stride=stride,
pad_mode='pad', padding=pad, group=mid_channels,
weight_init='xavier_uniform', has_bias=False),
nn.BatchNorm2d(mid_channels),
GroupConv(in_channels=mid_channels, out_channels=outputs,
kernel_size=1, stride=1, pad_mode="pad", pad=0,
groups=group),
nn.BatchNorm2d(outputs),
]
self.branch_main_1 = nn.SequentialCell(branch_main_1)
self.branch_main_2 = nn.SequentialCell(branch_main_2)
if stride == 2:
self.branch_proj = nn.AvgPool2d(kernel_size=3, stride=2, pad_mode='same')
def construct(self, old_x):
left = old_x
right = old_x
out = old_x
right = self.branch_main_1(right)
if self.group > 1:
right = self.channel_shuffle(right)
right = self.branch_main_2(right)
if self.stride == 1:
out = self.relu(left + right)
elif self.stride == 2:
left = self.branch_proj(left)
out = ops.cat((left, right), 1)
out = self.relu(out)
return out
def channel_shuffle(self, x):
batchsize, num_channels, height, width = ops.shape(x)
group_channels = num_channels // self.group
x = ops.reshape(x, (batchsize, group_channels, self.group, height, width))
x = ops.transpose(x, (0, 2, 1, 3, 4))
x = ops.reshape(x, (batchsize, num_channels, height, width))
return x
构建ShuffleNet网络
ShuffleNet网络结构如下图所示,以输入图像224×224224×224,组数3(g = 3)为例,首先通过数量24,卷积核大小为3×33×3,stride为2的卷积层,输出特征图大小为112×112112×112,channel为24;然后通过stride为2的最大池化层,输出特征图大小为56×5656×56,channel数不变;再堆叠3个ShuffleNet模块(Stage2, Stage3, Stage4),三个模块分别重复4次、8次、4次,其中每个模块开始先经过一次下采样模块(上图(c)),使特征图长宽减半,channel翻倍(Stage2的下采样模块除外,将channel数从24变为240);随后经过全局平均池化,输出大小为1×1×9601×1×960,再经过全连接层和softmax,得到分类概率。
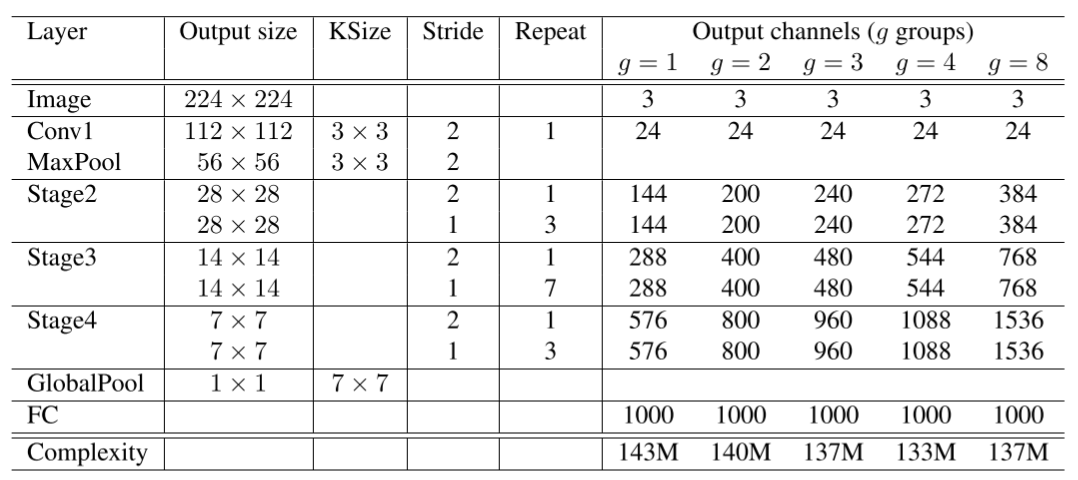
[*]:
class ShuffleNetV1(nn.Cell):
def __init__(self, n_class=1000, model_size='2.0x', group=3):
super(ShuffleNetV1, self).__init__()
print('model size is ', model_size)
self.stage_repeats = [4, 8, 4]
self.model_size = model_size
if group == 3:
if model_size == '0.5x':
self.stage_out_channels = [-1, 12, 120, 240, 480]
elif model_size == '1.0x':
self.stage_out_channels = [-1, 24, 240, 480, 960]
elif model_size == '1.5x':
self.stage_out_channels = [-1, 24, 360, 720, 1440]
elif model_size == '2.0x':
self.stage_out_channels = [-1, 48, 480, 960, 1920]
else:
raise NotImplementedError
elif group == 8:
if model_size == '0.5x':
self.stage_out_channels = [-1, 16, 192, 384, 768]
elif model_size == '1.0x':
self.stage_out_channels = [-1, 24, 384, 768, 1536]
elif model_size == '1.5x':
self.stage_out_channels = [-1, 24, 576, 1152, 2304]
elif model_size == '2.0x':
self.stage_out_channels = [-1, 48, 768, 1536, 3072]
else:
raise NotImplementedError
input_channel = self.stage_out_channels[1]
self.first_conv = nn.SequentialCell(
nn.Conv2d(3, input_channel, 3, 2, 'pad', 1, weight_init='xavier_uniform', has_bias=False),
nn.BatchNorm2d(input_channel),
nn.ReLU(),
)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, pad_mode='same')
features = []
for idxstage in range(len(self.stage_repeats)):
numrepeat = self.stage_repeats[idxstage]
output_channel = self.stage_out_channels[idxstage + 2]
for i in range(numrepeat):
stride = 2 if i == 0 else 1
first_group = idxstage == 0 and i == 0
features.append(ShuffleV1Block(input_channel, output_channel,
group=group, first_group=first_group,
mid_channels=output_channel // 4, ksize=3, stride=stride))
input_channel = output_channel
self.features = nn.SequentialCell(features)
self.globalpool = nn.AvgPool2d(7)
self.classifier = nn.Dense(self.stage_out_channels[-1], n_class)
def construct(self, x):
x = self.first_conv(x)
x = self.maxpool(x)
x = self.features(x)
x = self.globalpool(x)
x = ops.reshape(x, (-1, self.stage_out_channels[-1]))
x = self.classifier(x)
return x
模型训练和评估
采用CIFAR-10数据集对ShuffleNet进行预训练。
训练集准备与加载
采用CIFAR-10数据集对ShuffleNet进行预训练。CIFAR-10共有60000张32*32的彩色图像,均匀地分为10个类别,其中50000张图片作为训练集,10000图片作为测试集。如下示例使用mindspore.dataset.Cifar10Dataset接口下载并加载CIFAR-10的训练集。目前仅支持二进制版本(CIFAR-10 binary version)。
[*]:
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/cifar-10-binary.tar.gz"
download(url, "./dataset", kind="tar.gz", replace=True)
[*]:
import mindspore as ms
from mindspore.dataset import Cifar10Dataset
from mindspore.dataset import vision, transforms
def get_dataset(train_dataset_path, batch_size, usage):
image_trans = []
if usage == "train":
image_trans = [
vision.RandomCrop((32, 32), (4, 4, 4, 4)),
vision.RandomHorizontalFlip(prob=0.5),
vision.Resize((224, 224)),
vision.Rescale(1.0 / 255.0, 0.0),
vision.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010]),
vision.HWC2CHW()
]
elif usage == "test":
image_trans = [
vision.Resize((224, 224)),
vision.Rescale(1.0 / 255.0, 0.0),
vision.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010]),
vision.HWC2CHW()
]
label_trans = transforms.TypeCast(ms.int32)
dataset = Cifar10Dataset(train_dataset_path, usage=usage, shuffle=True)
dataset = dataset.map(image_trans, 'image')
dataset = dataset.map(label_trans, 'label')
dataset = dataset.batch(batch_size, drop_remainder=True)
return dataset
dataset = get_dataset("./dataset/cifar-10-batches-bin", 128, "train")
batches_per_epoch = dataset.get_dataset_size()
模型训练
本节用随机初始化的参数做预训练。首先调用ShuffleNetV1定义网络,参数量选择"2.0x",并定义损失函数为交叉熵损失,学习率经过4轮的warmup后采用余弦退火,优化器采用Momentum。最后用train.model中的Model接口将模型、损失函数、优化器封装在model中,并用model.train()对网络进行训练。将ModelCheckpoint、CheckpointConfig、TimeMonitor和LossMonitor传入回调函数中,将会打印训练的轮数、损失和时间,并将ckpt文件保存在当前目录下。
[*]:
import time
import mindspore
import numpy as np
from mindspore import Tensor, nn
from mindspore.train import ModelCheckpoint, CheckpointConfig, TimeMonitor, LossMonitor, Model, Top1CategoricalAccuracy, Top5CategoricalAccuracy
def train():
mindspore.set_context(mode=mindspore.PYNATIVE_MODE, device_target="Ascend")
net = ShuffleNetV1(model_size="2.0x", n_class=10)
loss = nn.CrossEntropyLoss(weight=None, reduction='mean', label_smoothing=0.1)
min_lr = 0.0005
base_lr = 0.05
lr_scheduler = mindspore.nn.cosine_decay_lr(min_lr,
base_lr,
batches_per_epoch*250,
batches_per_epoch,
decay_epoch=250)
lr = Tensor(lr_scheduler[-1])
optimizer = nn.Momentum(params=net.trainable_params(), learning_rate=lr, momentum=0.9, weight_decay=0.00004, loss_scale=1024)
loss_scale_manager = ms.amp.FixedLossScaleManager(1024, drop_overflow_update=False)
model = Model(net, loss_fn=loss, optimizer=optimizer, amp_level="O3", loss_scale_manager=loss_scale_manager)
callback = [TimeMonitor(), LossMonitor()]
save_ckpt_path = "./"
config_ckpt = CheckpointConfig(save_checkpoint_steps=batches_per_epoch, keep_checkpoint_max=5)
ckpt_callback = ModelCheckpoint("shufflenetv1", directory=save_ckpt_path, config=config_ckpt)
callback += [ckpt_callback]
print("============== Starting Training ==============")
start_time = time.time()
# 由于时间原因,epoch = 5,可根据需求进行调整
model.train(5, dataset, callbacks=callback)
use_time = time.time() - start_time
hour = str(int(use_time // 60 // 60))
minute = str(int(use_time // 60 % 60))
second = str(int(use_time % 60))
print("total time:" + hour + "h " + minute + "m " + second + "s")
print("============== Train Success ==============")
if __name__ == '__main__':
train()
训练好的模型保存在当前目录的shufflenetv1-5_390.ckpt中,用作评估。
模型评估
在CIFAR-10的测试集上对模型进行评估。
设置好评估模型的路径后加载数据集,并设置Top 1, Top 5的评估标准,最后用model.eval()接口对模型进行评估。
[*]:
from mindspore import load_checkpoint, load_param_into_net
def test():
mindspore.set_context(mode=mindspore.GRAPH_MODE, device_target="Ascend")
dataset = get_dataset("./dataset/cifar-10-batches-bin", 128, "test")
net = ShuffleNetV1(model_size="2.0x", n_class=10)
param_dict = load_checkpoint("shufflenetv1-5_390.ckpt")
load_param_into_net(net, param_dict)
net.set_train(False)
loss = nn.CrossEntropyLoss(weight=None, reduction='mean', label_smoothing=0.1)
eval_metrics = {'Loss': nn.Loss(), 'Top_1_Acc': Top1CategoricalAccuracy(),
'Top_5_Acc': Top5CategoricalAccuracy()}
model = Model(net, loss_fn=loss, metrics=eval_metrics)
start_time = time.time()
res = model.eval(dataset, dataset_sink_mode=False)
use_time = time.time() - start_time
hour = str(int(use_time // 60 // 60))
minute = str(int(use_time // 60 % 60))
second = str(int(use_time % 60))
log = "result:" + str(res) + ", ckpt:'" + "./shufflenetv1-5_390.ckpt" \
+ "', time: " + hour + "h " + minute + "m " + second + "s"
print(log)
filename = './eval_log.txt'
with open(filename, 'a') as file_object:
file_object.write(log + '\n')
if __name__ == '__main__':
test()
模型预测
在CIFAR-10的测试集上对模型进行预测,并将预测结果可视化。
[*]:
import mindspore
import matplotlib.pyplot as plt
import mindspore.dataset as ds
net = ShuffleNetV1(model_size="2.0x", n_class=10)
show_lst = []
param_dict = load_checkpoint("shufflenetv1-5_390.ckpt")
load_param_into_net(net, param_dict)
model = Model(net)
dataset_predict = ds.Cifar10Dataset(dataset_dir="./dataset/cifar-10-batches-bin", shuffle=False, usage="train")
dataset_show = ds.Cifar10Dataset(dataset_dir="./dataset/cifar-10-batches-bin", shuffle=False, usage="train")
dataset_show = dataset_show.batch(16)
show_images_lst = next(dataset_show.create_dict_iterator())["image"].asnumpy()
image_trans = [
vision.RandomCrop((32, 32), (4, 4, 4, 4)),
vision.RandomHorizontalFlip(prob=0.5),
vision.Resize((224, 224)),
vision.Rescale(1.0 / 255.0, 0.0),
vision.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010]),
vision.HWC2CHW()
]
dataset_predict = dataset_predict.map(image_trans, 'image')
dataset_predict = dataset_predict.batch(16)
class_dict = {0:"airplane", 1:"automobile", 2:"bird", 3:"cat", 4:"deer", 5:"dog", 6:"frog", 7:"horse", 8:"ship", 9:"truck"}
# 推理效果展示(上方为预测的结果,下方为推理效果图片)
plt.figure(figsize=(16, 5))
predict_data = next(dataset_predict.create_dict_iterator())
output = model.predict(ms.Tensor(predict_data['image']))
pred = np.argmax(output.asnumpy(), axis=1)
index = 0
for image in show_images_lst:
plt.subplot(2, 8, index+1)
plt.title('{}'.format(class_dict[pred[index]]))
index += 1
plt.imshow(image)
plt.axis("off")
plt.show()















 68
68

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









