







利用Python的imblearn库解决类别不均衡问题
样本类别不均衡问题
类别不平衡问题概述
类别不平衡问题是指采集的原始数据集中的不同类别数据样本数量相差过大,分布不均衡,如二分类下雨或不下雨问题中,与下雨相关的数据样本有50个,而与不下雨相关的数据样本有100个,在二分类过程中由于与下雨相关的数据样本过少,会导致学习到的与下雨相关的知识经验过少,进而错误地将下雨分类为不下雨。
解决类别不平衡问题常用的两种方法
解决类别不平衡问题的常用方法有两种:一是继续尽可能地收集到更多的数据样本使得类别均衡(个人认为在数据处理过程中不太现实),二是采用抽样方法,抽样方法又包括过采样和欠采样。
过采样
过采样是指通过增加类别数量少的数据样本数量使得数据样本均衡的方法,实现过采样的常用算法有SMOTE(Synthetic Minority Oversampling Technique)和ADASYN(Adaptive Synthetic) 。SMOTE算法的核心思想是合成类别数量少的数据样本,SMOTE算法会随机选取少数类样本来合成新样本,却不考虑周边样本的情况,进而容易导致新合成的样本有用特征信息过少及与多数类样本重叠的情况。ADASYN算法是根据数据分布的情况自适应地为不同少数类样本生成不同数量的新样本,不会像SMOTE算法一样为每个少数类样本合成相同数量的数据样本。过采样与欠采样相比,过采样使用的场景更多也更有效。
欠采样
欠采样是指通过减少类别数量多的数据样本数量使得数据样本均衡的方法,实现欠采样的常用算法有随机欠采样、原型生成和NearMiss,随机欠采样算法随机地选择目标类的数据子集来平衡数据,这种方法快速简便,原型生成算法要求原始数据集最好能够聚类成簇,减少数据集的样本数量,利余的数据样本足由原始数据集生成而并不直接来源于原始数输出据集。NearMiss算法利用了KNN算法思想,计算量会偏大。
Python中的imblearn库支持过采样和欠采样中及的算法,打开Anaconda Prompt应用程序或者windows命令菜单,在Anaconda Promp:应用程序或者windows的命令行窗口输入如下命令:
pip install imblearn
上述安装如果过慢,可采用第三方镜像:
清华:https://pypi.tuna.tsinghua.edu.cn/simple
阿里云:http://mirrors.aliyun.com/pypi/simple
中国科技大学 :https://pypi.mirrors.ustc.edu.cn/simple
华中理工大学:http://pypi.hustunique.com
山东理工大学:http://pypi.sdutlinux.org
例如:安装imblearn包:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple imblearn
判断样本类别分布
数据仍采用sns.heatmap变量相关热力图章节所用数据集
#标签类别分布
count=data['信用分类'].value_counts()
percent=count/count.sum()
print(percent,'\n',count)
#数据可视化
#count.plot(kind='line',color=['r'])
count.plot(kind='bar',fontsize=16,color=['g','r'])
plt.title('信用分类')#分类变量,1:好;0:差
plt.xticks(rotation=0)
for x,y in enumerate(count):
plt.text(x,y+2,y,ha='center',fontsize=12)
plt.savefig("1.png")
1 0.69375
0 0.30625
Name: 信用分类, dtype: float64
1 555
0 245
Name: 信用分类, dtype: int64
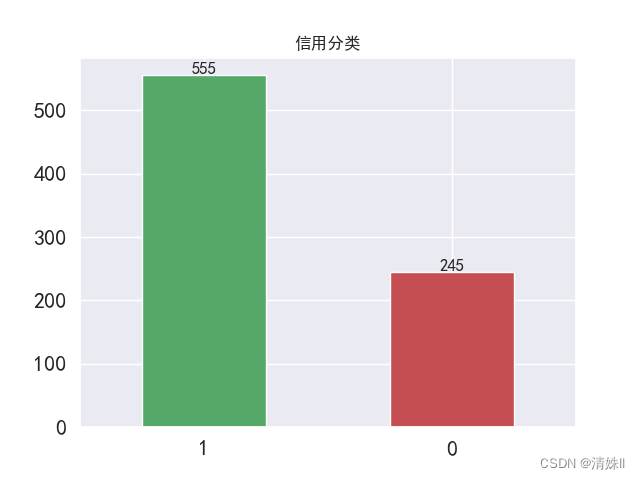
可见样本存在类别不均衡问题。
过采样算法——imblearn.over_sampling
模板:
########过采样############
from imblearn.over_sampling import SMOTE,ADASYN
from collections import Counter#快速统计样本类别
#X为数据样本特征,y为数据样本标签
result=sorted(Counter(y).items())
#result列表,列表每个元素为二元组,二元组含义为(类别,类别数量)
print("原始数据样本:")
for i in result:
print(f"类别{i[0]}有{i[1]}个数据样本")
#SMOTE
xSMOTE,ySMOTE=SMOTE().fit_resample(X,y)
result1=sorted(Counter(ySMOTE).items())
print("SMOTE算法处理后:")
for i in result1:
print(f"类别{i[0]}有{i[1]}个数据样本")
#ADASYN
xADASYN,yADASYN=ADASYN().fit_resample(X,y)
result2=sorted(Counter(YADASYN).items())
print("ADASYN算法处理后:")
for i in result2:
print(f"类别{i[0]}有{i[1]}个数据样本")
应用:
from imblearn.over_sampling import SMOTE,ADASYN
from collections import Counter#快速统计样本类别
#加载数据
data=pd.read_csv(r'D:/Jupyter/data/training.csv',encoding="gb18030")#解决不是utf_8存储数据报错问题
data.drop(['编号'],axis=1,inplace=True)
x=data.drop(['信用分类'],axis=1)
y=data['信用分类']
xSMOTE,ySMOTE=SMOTE().fit_resample(x,y)
result1=sorted(Counter(ySMOTE).items())
print("SMOTE算法处理后:")
for i in result1:
print(f"类别{i[0]}有{i[1]}个数据样本")
xADASYN,yADASYN=ADASYN().fit_resample(x,y)
result2=sorted(Counter(yADASYN).items())
print("ADASYN算法处理后:")
for i in result2:
print(f"类别{i[0]}有{i[1]}个数据样本")
SMOTE算法处理后:
类别0有555个数据样本
类别1有555个数据样本
ADASYN算法处理后:
类别0有590个数据样本
类别1有555个数据样本
可见,ADASYN算法不会像SMOTE算法一样为每个少数类样本合成相同数量的数据样本。
欠采样算法——imblearn.under_sampling
########欠采样#############
from imblearn.under_sampling import RandomUnderSampler,ClusterCentroids,NearMiss
from collections import Counter#快速统计样本类别
#X为数据样本特征,y为数据样本标签
result=sorted(Counter(y).items())
#result列表,列表每个元素为二元组,二元组含义为(类别,类别数量)
print("原始数据样本:")
for i in result:
print(f"类别{i[0]}有{i[1]}个数据样本")
#RandomUnderSampler
xRandom,yRandom=RandomUnderSampler().fit_resample(X,y)
result1=sorted(Counter(yRandom).items())
print("随机欠采样算法处理后:")
for i in result1:
print(f"类别{i[0]}有{i[1]}个数据样本")
#ClusterCentroids
xCentroids,yCentroids=ClusterCentroids().fit_resample(X,y)
result2=sorted(Counter(YCentroids).items())
print("原型生成算法处理后:")
for i in result2:
print(f"类别{i[0]}有{i[1]}个数据样本")
#NearMiss
xCentroids,yCentroids=NearMiss().fit_resample(X,y)
result3=sorted(Counter(YCentroids).items())
print("NearMiss算法处理后:")
for i in result3:
print(f"类别{i[0]}有{i[1]}个数据样本")
PyCharm 批量更换变量名快捷键:Ctrl+R,很实用推荐!!!
应用
from imblearn.under_sampling import RandomUnderSampler,ClusterCentroids,NearMiss
from collections import Counter#快速统计样本类别
#加载数据
data=pd.read_csv(r'D:/Jupyter/data/training.csv',encoding="gb18030")#解决不是utf_8存储数据报错问题
data.drop(['编号'],axis=1,inplace=True)
X=data.drop(['信用分类'],axis=1)
y=data['信用分类']
#X为数据样本特征,y为数据样本标签
result=sorted(Counter(y).items())
#result列表,列表每个元素为二元组,二元组含义为(类别,类别数量)
print("原始数据样本:")
for i in result:
print(f"类别{i[0]}有{i[1]}个数据样本")
print()
#RandomUnderSampler
xRandom,yRandom=RandomUnderSampler().fit_resample(X,y)
result1=sorted(Counter(yRandom).items())
print("随机欠采样算法处理后:")
for i in result1:
print(f"类别{i[0]}有{i[1]}个数据样本")
print()
#ClusterCentroids
# xCentroids,yCentroids=ClusterCentroids().fit_resample(X,y)
# result2=sorted(Counter(yCentroids).items())
# print("原型生成算法处理后:")
# for i in result2:
# print(f"类别{i[0]}有{i[1]}个数据样本")
#print()
#NearMiss
xCentroids,yCentroids=NearMiss().fit_resample(X,y)
result3=sorted(Counter(yCentroids).items())
print("NearMiss算法处理后:")
for i in result3:
print(f"类别{i[0]}有{i[1]}个数据样本")
print()
原始数据样本:
类别0有245个数据样本
类别1有555个数据样本
随机欠采样算法处理后:
类别0有245个数据样本
类别1有245个数据样本
NearMiss算法处理后:
类别0有245个数据样本
类别1有245个数据样本
注:运行原型生成算法代码会报错:AttributeError: ‘NoneType’ object has no attribute ‘split’.
目前未解决,如果有解决方法的可以私信或者评论区告诉我,好多算法代码运行都会遇到这个错误,我真的会谢。
想要了解更多Python采样方法,在这里推荐一篇博客:python抽样方法详解及实现















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









