







Python3 正则表达式
在 Python3 中正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。
re 模块使 Python 语言拥有全部的正则表达式功能。
compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。
re 模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串做为它们的第一个参数。
本章节主要介绍 Python 中常用的正则表达式处理函数。
re.match 函数
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match() 就返回 none。
函数语法:
re.match(pattern, string, flags=0)
函数参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
匹配成功 re.match 方法返回一个匹配的对象,否则返回 None。
我们可以使用 group(num) 或 groups() 匹配对象函数来获取匹配表达式。
| 匹配对象方法 | 描述 |
|---|---|
| group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
| groups() | 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 |
实例 1:
#!/usr/bin/python
import re
print(re.match('www', 'www.w3cschool.cn').span()) # 在起始位置匹配
print(re.match('cn', 'www.w3cschool.cn')) # 不在起始位置匹配
尝试一下
以上实例运行输出结果为:
(0, 3) None
实例 2:
#!/usr/bin/python3
import re
line = "Cats are smarter than dogs"
matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I)
if matchObj:
print ("matchObj.group() : ", matchObj.group())
print ("matchObj.group(1) : ", matchObj.group(1))
print ("matchObj.group(2) : ", matchObj.group(2))
else:
print ("No match!!")
尝试一下
以上实例执行结果如下:
matchObj.group() : Cats are smarter than dogs matchObj.group(1) : Cats matchObj.group(2) : smarter
re.search 方法
re.search 扫描整个字符串并返回第一个成功的匹配。
函数语法:
re.search(pattern, string, flags=0)
函数参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
匹配成功 re.search 方法返回一个匹配的对象,否则返回 None。
我们可以使用 group(num) 或 groups() 匹配对象函数来获取匹配表达式。
| 匹配对象方法 | 描述 |
|---|---|
| group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
| groups() | 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 |
实例 1:
#!/usr/bin/python3
import re
print(re.search('www', 'www.w3cschool.cn').span()) # 在起始位置匹配
print(re.search('cn', 'www.w3cschool.cn').span()) # 不在起始位置匹配
尝试一下
以上实例运行输出结果为:
(0, 3) (14, 16)
实例 2:
#!/usr/bin/python3
import re
line = "Cats are smarter than dogs";
searchObj = re.search( r'(.*) are (.*?) .*', line, re.M|re.I)
if searchObj:
print ("searchObj.group() : ", searchObj.group())
print ("searchObj.group(1) : ", searchObj.group(1))
print ("searchObj.group(2) : ", searchObj.group(2))
else:
print ("Nothing found!!")
尝试一下
以上实例执行结果如下:
searchObj.group() : Cats are smarter than dogs searchObj.group(1) : Cats searchObj.group(2) : smarter
re.match 与 re.search 的区别
re.match 只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回 None;而 re.search 匹配整个字符串,直到找到一个匹配。
实例:
#!/usr/bin/python3
import re
line = "Cats are smarter than dogs";
matchObj = re.match( r'dogs', line, re.M|re.I)
if matchObj:
print ("match --> matchObj.group() : ", matchObj.group())
else:
print ("No match!!")
matchObj = re.search( r'dogs', line, re.M|re.I)
if matchObj:
print ("search --> matchObj.group() : ", matchObj.group())
else:
print ("No match!!")
尝试一下
以上实例运行结果如下:
No match!! search --> matchObj.group() : dogs
检索和替换
Python 的 re 模块提供了 re.sub 用于替换字符串中的匹配项。
语法:
re.sub(pattern, repl, string, max=0)
返回的字符串是在字符串中用 re 最左边不重复的匹配来替换。如果模式没有发现,字符将被没有改变地返回。
可选参数 count 是模式匹配后替换的最大次数;count 必须是非负整数。缺省值是 0 表示替换所有的匹配。
实例:
#!/usr/bin/python3
import re
phone = "2004-959-559 # 这是一个电话号码"
# 删除注释
num = re.sub(r'#.*$', "", phone)
print ("电话号码 : ", num)
# 移除非数字的内容
num = re.sub(r'\D', "", phone)
print ("电话号码 : ", num)
尝试一下
以上实例执行结果如下:
电话号码 : 2004-959-559 电话号码 : 2004959559
正则表达式修饰符 - 可选标志
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 or(|) 它们来指定。如 re.L | re.M 被设置成 L 和 M 标志:
| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
正则表达式模式
模式字符串使用特殊的语法来表示一个正则表达式:
字母和数字表示他们自身。一个正则表达式模式中的字母和数字匹配同样的字符串。
多数字母和数字前加一个反斜杠时会拥有不同的含义。
标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。
反斜杠本身需要使用反斜杠转义。
由于正则表达式通常都包含反斜杠,所以你最好使用原始字符串来表示它们。模式元素(如 r'/t',等价于'//t')匹配相应的特殊字符。
下表列出了正则表达式模式语法中的特殊元素。如果你使用模式的同时提供了可选的标志参数,某些模式元素的含义会改变。
| 模式 | 描述 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾。 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| [...] | 用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k' |
| [^...] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| re* | 匹配0个或多个的表达式。 |
| re+ | 匹配1个或多个的表达式。 |
| re? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| re{ n} | 匹配n个前面表达式。例如,"o{2}"不能匹配"Bob"中的"o",但是能匹配"food"中的两个o。 |
| re{ n,} | 精确匹配n个前面表达式。例如,"o{2,}"不能匹配"Bob"中的"o",但能匹配"foooood"中的所有o。"o{1,}"等价于"o+"。"o{0,}"则等价于"o*"。 |
| re{ n, m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| a| b | 匹配a或b |
| (re) | G匹配括号内的表达式,也表示一个组 |
| (?imx) | 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。 |
| (?-imx) | 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。 |
| (?: re) | 类似 (...), 但是不表示一个组 |
| (?imx: re) | 在括号中使用i, m, 或 x 可选标志 |
| (?-imx: re) | 在括号中不使用i, m, 或 x 可选标志 |
| (?#...) | 注释. |
| (?= re) | 前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
| (?! re) | 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功 |
| (?> re) | 匹配的独立模式,省去回溯。 |
| \w | 匹配非特殊字符,即a-z、A-Z、0-9、_、汉字 |
| \W | 匹配特殊字符,即非字母、非数字、非汉字、非_ |
| \s | 匹配任意空白字符,等价于 [\t\n\r\f]. |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9]. |
| \D | 匹配任意非数字 |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。c |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \n, \t, 等. | 匹配一个换行符。匹配一个制表符。等 |
| \1...\9 | 匹配第n个分组的子表达式。 |
| \10 | 匹配第n个分组的子表达式,如果它经匹配。否则指的是八进制字符码的表达式。 |
正则表达式实例
字符匹配
| 实例 | 描述 |
|---|---|
| python | 匹配 "python". |
字符类
| 实例 | 描述 |
|---|---|
| [Pp]ython | 匹配 "Python" 或 "python" |
| rub[ye] | 匹配 "ruby" 或 "rube" |
| [aeiou] | 匹配中括号内的任意一个字母 |
| [0-9] | 匹配任何数字。类似于 [0123456789] |
| [a-z] | 匹配任何小写字母 |
| [A-Z] | 匹配任何大写字母 |
| [a-zA-Z0-9] | 匹配任何字母及数字 |
| [^aeiou] | 除了aeiou字母以外的所有字符 |
| [^0-9] | 匹配除了数字外的字符 |
特殊字符类
| 实例 | 描述 |
|---|---|
| . | 匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用象 '[.\n]' 的模式。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \w | 匹配包括下划线的任何单词字符。等价于'[A-Za-z0-9_]'。 |
| \W | 匹配任何非单词字符。等价于 '[^A-Za-z0-9_]'。 |
Python3 CGI 编程
什么是 CGI
CGI 目前由 NCSA 维护,NCSA 定义 CGI 如下:
CGI(Common Gateway Interface),通用网关接口,它是一段程序,运行在服务器上如:HTTP服务器,提供同客户端 HTML 页面的接口。
网页浏览
为了更好的了解 CGI 是如何工作的,我们可以从在网页上点击一个链接或 URL 的流程:
- 1、使用你的浏览器访问 URL 并连接到 HTTP web 服务器。
- 2、Web 服务器接收到请求信息后会解析 URL,并查找访问的文件在服务器上是否存在,如果存在返回文件的内容,否则返回错误信息。
- 3、浏览器从服务器上接收信息,并显示接收的文件或者错误信息。
CGI 程序可以是 Python 脚本,PERL 脚本,SHELL 脚本,C 或者 C++ 程序等。
CGI 架构图
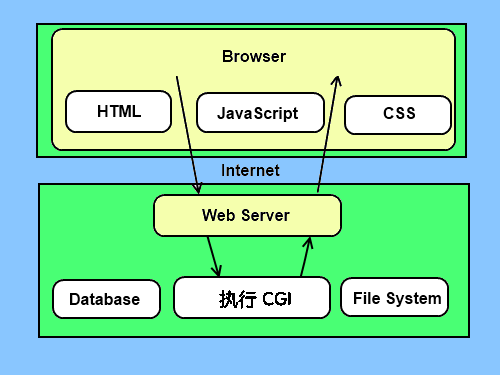
Web 服务器支持及配置
在你进行 CGI 编程前,确保您的 Web 服务器支持 CGI 及已经配置了 CGI 的处理程序。
Apache 支持 CGI 配置(这里使用PHPstudy集成的Apache):
打开Apache的配置文件httpd-conf,在文件中找到如下内容:
首先找到ScriptAlias(图片内容为已经修改过的值,默认值应该有所不同而且是被注释掉的)
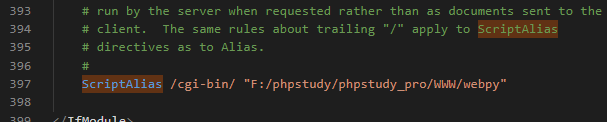
修改为项目地址 ScriptAlias /cgi-bin/ "F:/phpstudy/phpstudy_pro/WWW/webpy" (之前的项目都放在F:/phpstudy/phpstudy_pro/WWW/下,这个文件夹是PHPstudy的apache默认项目文件夹,将路径改为这样可以方便localhost访问)。
然后找到Directory,将其修改为
<Directory "F:/phpstudy/phpstudy_pro/WWW/webpy">
AllowOverride None
Options +ExecCGI
Order allow,deny
Allow from all
</Directory>
注意:这里的路径和上面设置的路径是一样的。
接着找到AddHandler

添加.py。使apache识别.py文件为cgi程序(图中已添加)。
接下来我们就可以在webpy文件夹下写pythonCGI程序了。
第一个CGI程序
我们使用 Python 创建第一个 CGI 程序,文件名为 hello.py,文件位于 /var/www/cgi-bin目录中,内容如下:
#!/usr/bin/python3
# 请注意第一行代码,在linux中需要在py文件中正确指定python解释器的路径才能运行 # 在Windows中使用Python CGI文件也需要正确指定python解释器的路径才能运行
#coding=utf-8
print("Content-type:text/html") # 指定返回的类型,没有这行代码会报错
print() # 空行,告诉服务器结束头部
# 以下是要返回的HTML正文 print ('<html>')
print ('<head>')
print ('<title>Hello Word - 我的第一个 CGI 程序!</title>')
print ('</head>')
print ('<body>')
print ('<h2>Hello Word! 我的第一CGI程序</h2>')
print ('</body>')
print ('</html>')
文件保存后修改 hello.py,修改文件权限为 755(linux和macos需要在webpy文件夹下使用下面的命令来修改文件读写权限,在Windows环境下需要修改文件的读写权限):
chmod 755 hello.py 以上程序在浏览器访问显示结果如下:

这个的 hello.py 脚本是一个简单的 Python 脚本,脚本第一行的输出内容"Content-type:text/html"发送到浏览器并告知浏览器显示的内容类型为"text/html"。
用 print 输出一个空行用于告诉服务器结束头部信息。
注:如果此处出现乱码,可以在打印html的时候打印,在下文部分代码中有所体现(注意,这里不使用UTF-8的原因是小编在这里使用utf-8出现乱码,这是因为小编的系统是Windows系统,系统默认字符集是GBK,所以会出现乱码)。
另外:请注意第一行代码,在linux中需要在py文件中正确指定python解释器的路径才能运行 。在Windows中使用Python CGI文件也需要正确指定python解释器的路径才能运行
HTTP头部
hello.py 文件内容中的" Content-type:text/html"即为 HTTP 头部的一部分,它会发送给浏览器告诉浏览器文件的内容类型。
HTTP 头部的格式如下:
HTTP 字段名: 字段内容
例如:
Content-type: text/html以下表格介绍了 CGI 程序中 HTTP 头部经常使用的信息:
| 头 | 描述 |
|---|---|
| Content-type: | 请求的与实体对应的 MIME 信息。例如: Content-type:text/html |
| Expires: Date | 响应过期的日期和时间 |
| Location: URL | 用来重定向接收方到非请求URL的位置来完成请求或标识新的资源 |
| Last-modified: Date | 请求资源的最后修改时间 |
| Content-length: N | 请求的内容长度 |
| Set-Cookie: String | 设置 Http Cookie |
CGI 环境变量
所有的 CGI 程序都接收以下的环境变量,这些变量在 CGI 程序中发挥了重要的作用:
| 变量名 | 描述 |
|---|---|
| CONTENT_TYPE | 这个环境变量的值指示所传递来的信息的 MIME 类型。目前,环境变量 CONTENT_TYPE 一般都是:application/x-www-form-urlencoded,他表示数据来自于 HTML 表单。 |
| CONTENT_LENGTH | 如果服务器与 CGI 程序信息的传递方式是 POST,这个环境变量即使从标准输入 STDIN 中可以读到的有效数据的字节数。这个环境变量在读取所输入的数据时必须使用。 |
| HTTP_COOKIE | 客户机内的 COOKIE 内容。 |
| HTTP_USER_AGENT | 提供包含了版本数或其他专有数据的客户浏览器信息。 |
| PATH_INFO | 这个环境变量的值表示紧接在 CGI 程序名之后的其他路径信息。它常常作为 CGI 程序的参数出现。 |
| QUERY_STRING | 如果服务器与 CGI 程序信息的传递方式是 GET,这个环境变量的值即使所传递的信息。这个信息经跟在 CGI 程序名的后面,两者中间用一个问号'?'分隔。 |
| REMOTE_ADDR | 这个环境变量的值是发送请求的客户机的IP地址,例如上面的192.168.1.67。这个值总是存在的。而且它是 Web 客户机需要提供给Web服务器的唯一标识,可以在 CGI 程序中用它来区分不同的 Web 客户机。 |
| REMOTE_HOST | 这个环境变量的值包含发送 CGI 请求的客户机的主机名。如果不支持你想查询,则无需定义此环境变量。 |
| REQUEST_METHOD | 提供脚本被调用的方法。对于使用 HTTP/1.0 协议的脚本,仅 GET 和 POST 有意义。 |
| SCRIPT_FILENAME | CGI 脚本的完整路径 |
| SCRIPT_NAME | CGI 脚本的的名称 |
| SERVER_NAME | 这是你的 WEB 服务器的主机名、别名或IP地址。 |
| SERVER_SOFTWARE | 这个环境变量的值包含了调用 CGI 程序的 HTTP 服务器的名称和版本号。例如,上面的值为 Apache/2.2.14(Unix) |
以下是一个简单的 CGI 脚本输出 CGI 的环境变量:
#!/usr/bin/python3
#coding=utf-8
import os
print ("Content-type: text/html")
print ()
print ("<b>环境变量</b><br>")
print ("<ul>")
for key in os.environ.keys():
print ("<li><span style='color:green'>%30s </span> : %s </li>" % (key,os.environ[key]))
print ("</ul>")
将以上点保存为 test.py ,并修改文件权限为 755,执行结果如下:
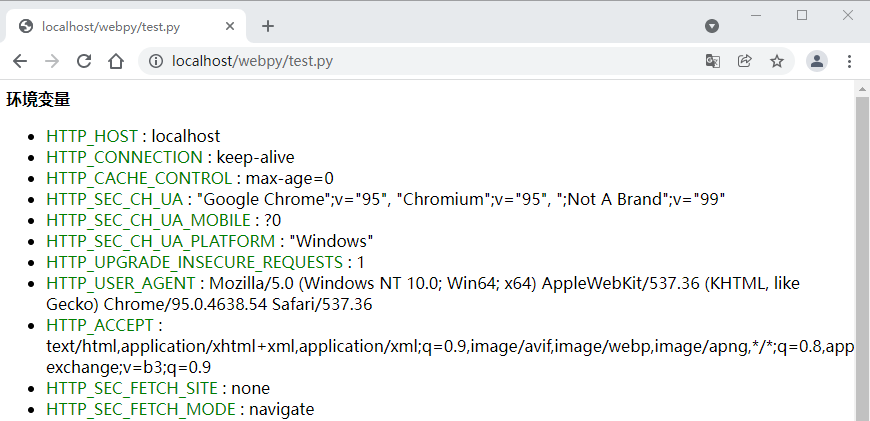
GET 和 POST 方法
浏览器客户端通过两种方法向服务器传递信息,这两种方法就是 GET 方法和 POST 方法。
使用 GET 方法传输数据
GET 方法发送编码后的用户信息到服务端,数据信息包含在请求页面的 URL 上,以"?"号分割, 如下所示:
http://localhost/webpy/test.py?key1=value1&key2=value2
有关 GET 请求的其他一些注释:
- GET 请求可被缓存
- GET 请求保留在浏览器历史记录中
- GET 请求可被收藏为书签
- GET 请求不应在处理敏感数据时使用
- GET 请求有长度限制
- GET 请求只应当用于取回数据
简单的 url 实例:GET 方法
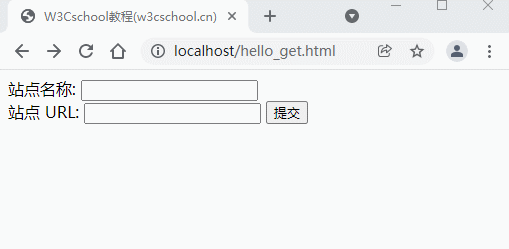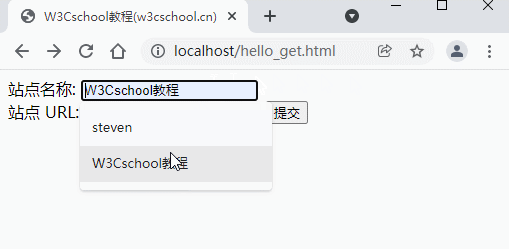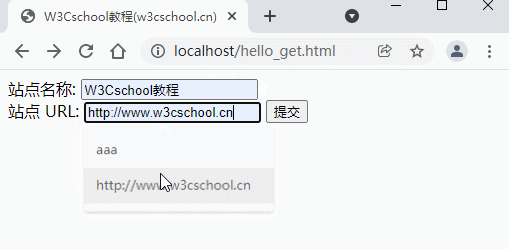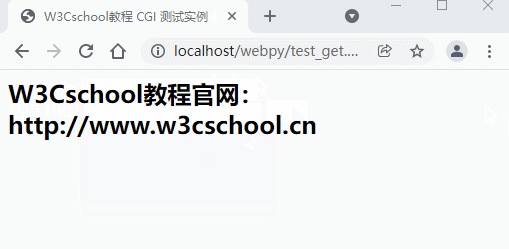
以下是一个简单的 URL,使用 GET 方法向 test_get.py 程序发送两个参数:
http://localhost/webpy/test_get.py?name=W3Cschool教程&url=http://www.w3cschool.cn
以下为 test_get.py 文件的代码:
#!/usr/bin/python3
#coding=utf-8
# CGI处理模块
import cgi, cgitb
# 创建 FieldStorage 的实例化
form = cgi.FieldStorage()
# 获取数据
site_name = form.getvalue('name')
site_url = form.getvalue('url')
print ("Content-type:text/html")
print ()
print ("<html>")
print ("<head>")
print ("<title>W3Cschool教程 CGI 测试实例</title>")
print ("</head>")
print ("<body>")
print ("<h2>%s官网:%s</h2>" % (site_name, site_url))
print ("</body>")
print ("</html>")
文件保存后修改 hello_get.py,修改文件权限为 755:
chmod 755 hello_get.py 浏览器请求输出结果:
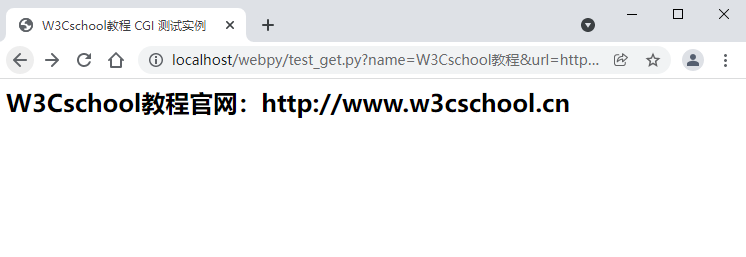
简单的表单实例:GET 方法
以下是一个通过 HTML 的表单使用 GET 方法向服务器发送两个数据,提交的服务器脚本同样是 test_get.py 文件,hello_get.html 代码如下:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>W3Cschool教程(w3cschool.cn)</title>
</head>
<body>
<form action="/webpy/test_get.py" method="get">
站点名称: <input type="text" name="name"> <br />
站点 URL: <input type="text" name="url" />
<input type="submit" value="提交" />
</form>
</body>
</html>
默认情况下 webpy 目录只能存放脚本文件,我们将 hello_get.html 存储在 WWW 目录下,修改文件权限为 755:
chmod 755 hello_get.html
Gif 演示如下所示:
使用 POST 方法传递数据
使用 POST 方法向服务器传递数据是更安全可靠的,像一些敏感信息如用户密码等需要使用 POST 传输数据。
以下同样是 test_get.py ,它也可以处理浏览器提交的 POST 表单数据:
#!/usr/bin/python3
#coding=utf-8
# CGI处理模块
import cgi, cgitb
# 创建 FieldStorage 的实例化
form = cgi.FieldStorage()
# 获取数据
site_name = form.getvalue('name')
site_url = form.getvalue('url')
print ("Content-type:text/html")
print ()
print ("<html>")
print ("<head>")
print ("<meta charset=\"utf-8\">")
print ("<title>W3Cschool教程 CGI 测试实例</title>")
print ("</head>")
print ("<body>")
print ("<h2>%s官网:%s</h2>" % (site_name, site_url))
print ("</body>")
print ("</html>")
以下为表单通过 POST 方法(method="post")向服务器脚本 test_get.py 提交数据:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>W3Cschool教程(w3cschool.cn)</title>
</head>
<body>
<form action="/webpy/hello_get.py" method="post">
站点名称: <input type="text" name="name"> <br />
站点 URL: <input type="text" name="url" />
<input type="submit" value="提交" />
</form>
</body>
</html>
</form>
Gif 演示如下所示:

通过 CGI 程序传递 checkbox 数据
checkbox 用于提交一个或者多个选项数据,HTML 代码如下:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>W3Cschool教程(w3cschool.cn)</title>
</head>
<body>
<form action="/webpy/checkbox.py" method="POST" target="_blank">
<input type="checkbox" name="youj" value="on" /> W3Cschool教程
<input type="checkbox" name="google" value="on" /> Google
<input type="submit" value="选择站点" />
</form>
</body>
</html>
以下为 checkbox.py 文件的代码:
#!/usr/bin/python3
#coding=utf-8
# 引入 CGI 处理模块
import cgi, cgitb
# 创建 FieldStorage的实例
form = cgi.FieldStorage()
# 接收字段数据
if form.getvalue('google'):
google_flag = "是"
else:
google_flag = "否"
if form.getvalue('youj'):
youj_flag = "是"
else:
youj_flag = "否"
print ("Content-type:text/html")
print ()
print ("<html>")
print ("<head>")
print ("<title>W3Cschool教程 CGI 测试实例</title>")
print ("</head>")
print ("<body>")
print ("<h2> W3Cschool教程是否选择了 : %s</h2>" % youj_flag)
print ("<h2> Google 是否选择了 : %s</h2>" % google_flag)
print ("</body>")
print ("</html>")
修改 checkbox.py 权限:
chmod 755 checkbox.py
浏览器访问 Gif 演示图:

通过 CGI 程序传递 Radio 数据
Radio 只向服务器传递一个数据,HTML 代码如下:
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>W3Cschool教程(w3cschool.cn)</title> </head> <body> <form action="/webpy/radiobutton.py" method="post" target="_blank"> <input type="radio" name="site" value="W3Cschool教程" /> W3Cschool教程<input type="radio" name="site" value="google" /> Google <input type="submit" value="提交" /> </form> </body> </html>
radiobutton.py 脚本代码如下:
#!/usr/bin/python3
#coding=utf-8
# 引入 CGI 处理模块
import cgi, cgitb
# 创建 FieldStorage的实例
form = cgi.FieldStorage()
# 接收字段数据
if form.getvalue('site'):
site = form.getvalue('site')
else:
site = "提交数据为空"
print ("Content-type:text/html")
print ()
print ("<html>")
print ("<head>")
print ("<title>W3Cschool教程 CGI 测试实例</title>")
print ("</head>")
print ("<body>")
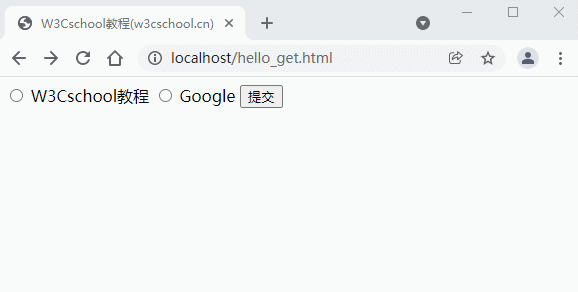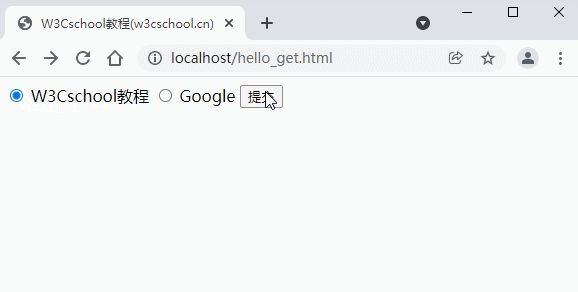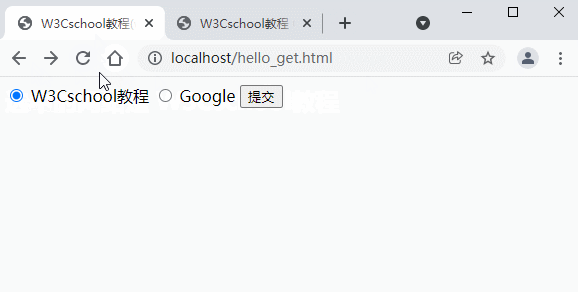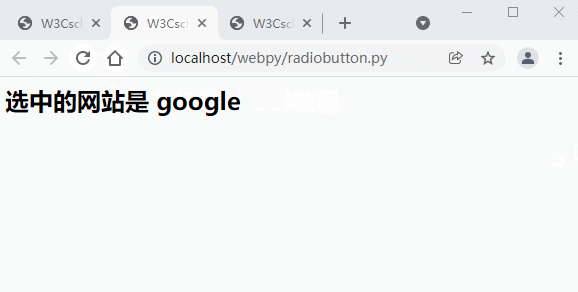
print ("<h2> 选中的网站是 %s</h2>" % site)
print ("</body>")
print ("</html>")
修改 radiobutton.py 权限:
chmod 755 radiobutton.py
浏览器访问 Gif 演示图:
通过 CGI 程序传递 Textarea 数据
Textarea 向服务器传递多行数据,HTML 代码如下:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>W3Cschool教程(w3cschool.cn)</title>
</head>
<body>
<form action="/webpy/textarea.py" method="post" target="_blank">
<textarea name="textcontent" cols="40" rows="4">
在这里输入内容...
</textarea>
<input type="submit" value="提交" />
</form>
</body>
</html>
textarea.py 脚本代码如下:
#!/usr/bin/python3
#coding=utf-8
# 引入 CGI 处理模块
import cgi, cgitb
# 创建 FieldStorage的实例
form = cgi.FieldStorage()
# 接收字段数据
if form.getvalue('textcontent'):
text_content = form.getvalue('textcontent')
else:
text_content = "没有内容"
print ("Content-type:text/html")
print ()
print ("<html>")
print ("<head>")
print ("<title>W3Cschool教程 CGI 测试实例</title>")
print ("</head>")
print ("<body>")
print ("<h2> 输入的内容是:%s</h2>" % text_content)
print ("</body>")
print ("</html>")
修改 textarea.py 权限:
chmod 755 textarea.py
浏览器访问 Gif 演示图:

通过 CGI 程序传递下拉数据。
HTML 下拉框代码如下:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>W3Cschool教程(w3cschool.cn)</title>
</head>
<body>
<form action="/webpy/dropdown.py" method="post" target="_blank">
<select name="dropdown">
<option value="W3Cschool教程" selected>W3Cschool教程</option>
<option value="google">Google</option>
</select>
<input type="submit" value="提交"/>
</form>
</body>
</html>
dropdown.py 脚本代码如下所示:
#!/usr/bin/python3
#coding=utf-8
# 引入 CGI 处理模块
import cgi, cgitb
# 创建 FieldStorage的实例
form = cgi.FieldStorage()
# 接收字段数据
if form.getvalue('dropdown'):
dropdown_value = form.getvalue('dropdown')
else:
dropdown_value = "没有内容"
print ("Content-type:text/html")
print ()
print ("<html>")
print ("<head>")
print ("<meta charset=\"utf-8\">")
print ("<title>W3Cschool教程 CGI 测试实例</title>")
print ("</head>")
print ("<body>")
print ("<h2> 选中的选项是:%s</h2>" % dropdown_value)
print ("</body>")
print ("</html>")
修改 dropdown.py 权限:
chmod 755 dropdown.py
浏览器访问 Gif 演示图:

CGI 中使用 Cookie
在 http 协议一个很大的缺点就是不对用户身份的进行判断,这样给编程人员带来很大的不便,而 cookie 功能的出现弥补了这个不足。
cookie 就是在客户访问脚本的同时,通过客户的浏览器,在客户硬盘上写入纪录数据 ,当下次客户访问脚本时取回数据信息,从而达到身份判别的功能,cookie 常用在身份校验中。
cookie 的语法
http cookie 的发送是通过 http 头部来实现的,他早于文件的传递,头部set-cookie 的语法如下:
Set-cookie:name=name;expires=date;path=path;domain=domain;secure
- name=name: 需要设置cookie的值(name不能使用";"和","号),有多个name值时用 ";" 分隔,例如:name1=name1;name2=name2;name3=name3。
- expires=date: cookie的有效期限,格式: expires="Wdy,DD-Mon-YYYY HH:MM:SS"
- path=path: 设置 cookie 支持的路径,如果path是一个路径,则 cookie 对这个目录下的所有文件及子目录生效,例如: path="/webpy/",如果path是一个文件,则cookie指对这个文件生效,例如:path="/webpy/cookie.py"。
- domain=domain: 对 cookie 生效的域名,例如:domain="www.w3cschool.cn"
- secure: 如果给出此标志,表示cookie只能通过SSL协议的https服务器来传递。
- cookie的接收是通过设置环境变量 HTTP_COOKIE 来实现的,CGI 程序可以通过检索该变量获取 cookie 信息。
Cookie 设置
Cookie 的设置非常简单,cookie 会在 http 头部单独发送。以下实例在 cookie 中设置了name 和 expires:
#!/usr/bin/python3
#coding=utf-8
print ('Content-Type: text/html')
print ('Set-Cookie: name="W3Cschool";expires=Thu 02 Dec 2021 18:30:00 GMT')//注意,这个cookie在这个时间前有效,之后使用cookie会过期
print ()
print ("""
<html>
<head>
<meta charset="gbk">
<title>W3Cschool教程(w3cschool.cn)</title>
</head>
<body>
<h1>Cookie set OK!</h1>
</body>
</html>
""")
将以上代码保存到 cookie_set.py,并修改 cookie_set.py 权限:
chmod 755 cookie_set.py
以上实例使用了 Set-Cookie 头信息来设置 Cookie 信息,可选项中设置了 Cookie 的其他属性,如过期时间 Expires,域名 Domain,路径 Path。这些信息设置在 "Content-type:text/html"之前。
注意:cookie不能存放中文,本文采用英文例子,如果要使用中文可以使用后端编码(可以采用utf-8等编码,python和JavaScript都有提供响应的编解码的功能),传到前端后再将其解码即可。
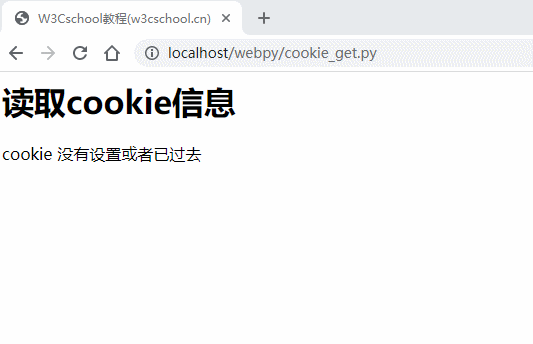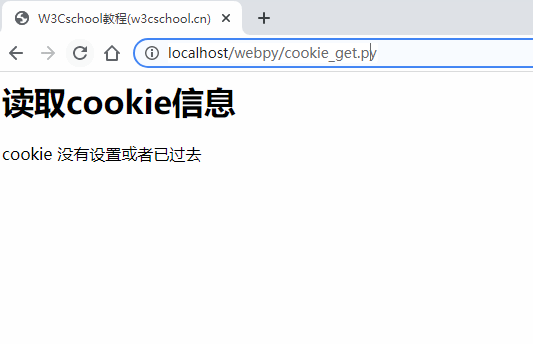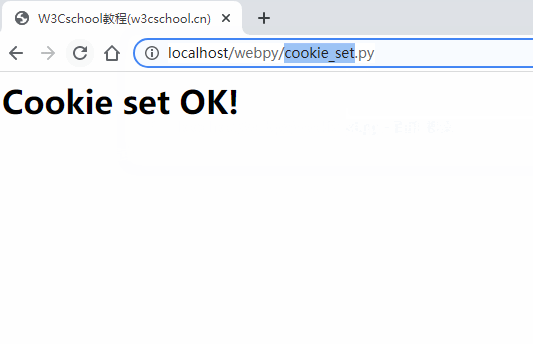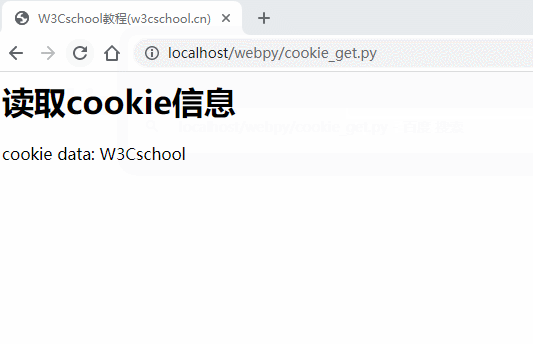
检索Cookie信息
Cookie 信息检索页非常简单,Cookie 信息存储在 CGI 的环境变量 HTTP_COOKIE 中,存储格式如下:
key1=value1;key2=value2;key3=value3....
以下是一个简单的 CGI 检索 cookie 信息的程序:
#!/usr/bin/python3
#coding=utf-8
# 导入模块
import os
import http.cookies
print ("Content-type: text/html")
print ()
print ("""
<html>
<head>
<meta charset="gbk">
<title>W3Cschool教程(w3cschool.cn)</title>
</head>
<body>
<h1>读取cookie信息</h1>
""")
if 'HTTP_COOKIE' in os.environ:
cookie_string=os.environ.get('HTTP_COOKIE')
c=http.cookies.SimpleCookie()
c.load(cookie_string)
try:
data=c['name'].value
print ("cookie data: "+data+"<br>")
except KeyError:
print ("cookie 没有设置或者已过去<br>")
print ("""
</body>
</html>
""")
将以上代码保存到 cookie_get.py,并修改 cookie_get.py 权限:
chmod 755 cookie_get.py
以上 cookie 设置的Gif 如下所示:
文件上传实例
HTML 设置上传文件的表单需要设置 enctype 属性为 multipart/form-data,代码如下所示:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>W3Cschool教程(w3cschool.cn)</title>
</head>
<body>
<form enctype="multipart/form-data"
action="/webpy/save_file.py" method="post">
<p>选中文件: <input type="file" name="filename" /></p>
<p><input type="submit" value="上传" /></p>
</form>
</body>
</html>save_file.py 脚本文件代码如下:
#!/usr/bin/python3
#coding=utf-8
import cgi, os
import cgitb
cgitb.enable()
form = cgi.FieldStorage()
# 获取文件名
fileitem = form['filename']
# 检测文件是否上传
if fileitem.filename:
# 设置文件路径
fn = os.path.basename(fileitem.filename)
open(os.getcwd()+'/tmp/' + fn, 'wb').write(fileitem.file.read())
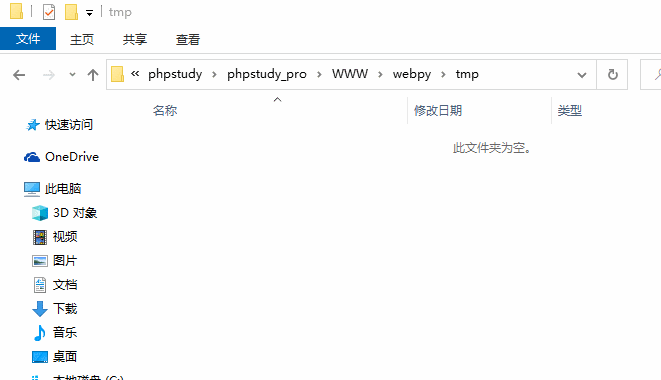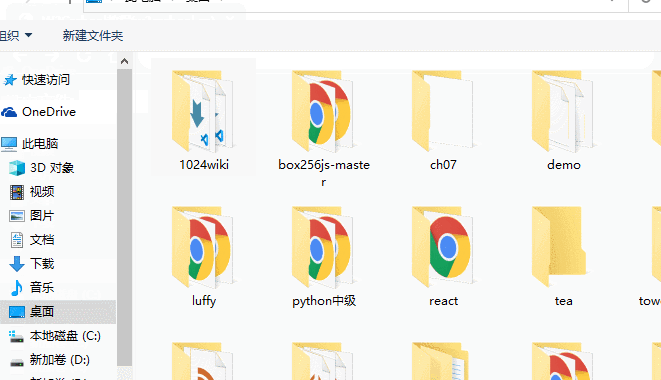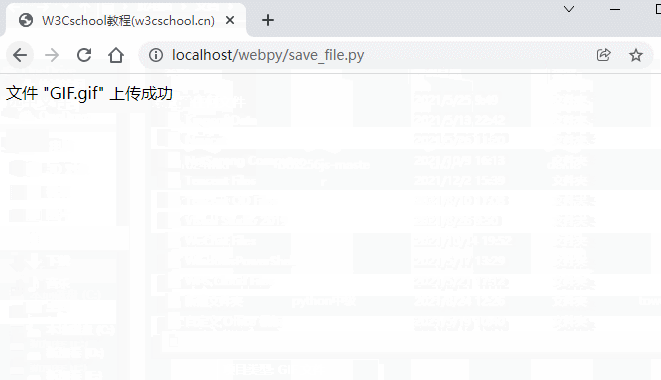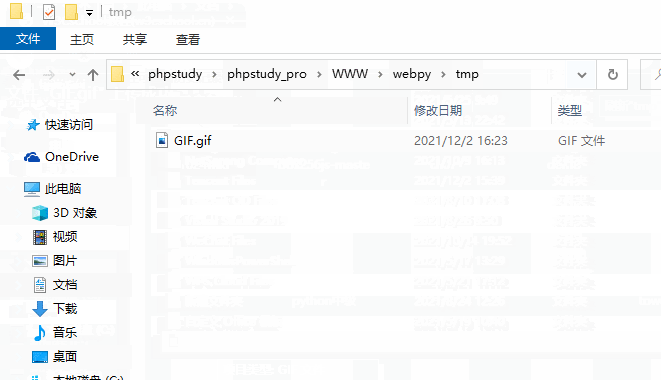
message = '文件 "' + fn + '" 上传成功'
else:
message = '文件没有上传'
print ("Content-type: text/html")
print ()
print ("""
<html>
<head>
<meta charset="gbk">
<title>W3Cschool教程(w3cschool.cn)</title>
</head>
<body>
<p>%s</p>
</body>
</html>
""" % (message,))
将以上代码保存到 save_file.py,并修改 save_file.py 权限:
chmod 755 save_file.py
以上文件上传代码 Gif 如下所示:
如果你使用的系统是 Unix/Linux,你必须替换文件分隔符,在 window 下只需要使用open() 语句即可:
fn = os.path.basename(fileitem.filename.replace("\\", "/" ))
另外,请注意在webpy下创建一个tmp文件夹,不然上传的时候会报错
文件下载对话框
我们先在当前目录下创建 foo.txt 文件,用于程序的下载。
文件下载通过设置 HTTP 头信息来实现,功能代码如下:
#!/usr/bin/python3
# HTTP 头部
print ("Content-Disposition: attachment; filename=\"foo.txt\"")
print ()
# 打开文件
fo = open("foo.txt", "rb")
str = fo.read();
print (str)
# 关闭文件
fo.close()
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









