









目录
总纲
写在前面的话
首先这篇博客绝对原创。读者遇到编程中的任何问题可以留言,看到了就会回复
需要的前瞻知识
这篇博客是假设读者都是已经安装好了Hadoop,Spark,以及对idea插件等,如果在安装这些大数据软件遇到了困难可以根据版本号在CSDN里搜对应的大数据软件安装
用到的软件版本
Hadoop2.7.7;Java1.8.0;sbt1.4.0;Spark2.4.0;Hive2.1.1;ZooKeeper3.5.10;Python3.7.9
数据集
也可点击下面的链接
链接:https://pan.baidu.com/s/13T8IHjAjvbsvQtQ01Ro__Q?pwd=494j
提取码:494j
执行过程
对于有Hadoop基础的来说很简单
在命令行输入(我已经配好了Hadoop的环境变量,没有配好的需要进HADOOP_HOME/bin执行,大概是这个路径)
[root@master ~]# start-all.sh 得到运行结果
[root@master ~]# start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [master]
master: starting namenode, logging to /root/hadoop-2.7.7/logs/hadoop-root-namenode-master.out
s2: starting datanode, logging to /root/hadoop-2.7.7/logs/hadoop-root-datanode-slave2.out
s1: starting datanode, logging to /root/hadoop-2.7.7/logs/hadoop-root-datanode-slave.out
localhost: starting datanode, logging to /root/hadoop-2.7.7/logs/hadoop-root-datanode-master.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /root/hadoop-2.7.7/logs/hadoop-root-secondarynamenode-master.out
starting yarn daemons
starting resourcemanager, logging to /root/hadoop-2.7.7/logs/yarn-root-resourcemanager-master.out
s2: starting nodemanager, logging to /root/hadoop-2.7.7/logs/yarn-root-nodemanager-slave2.out
s1: starting nodemanager, logging to /root/hadoop-2.7.7/logs/yarn-root-nodemanager-slave.out
localhost: starting nodemanager, logging to /root/hadoop-2.7.7/logs/yarn-root-nodemanager-master.out
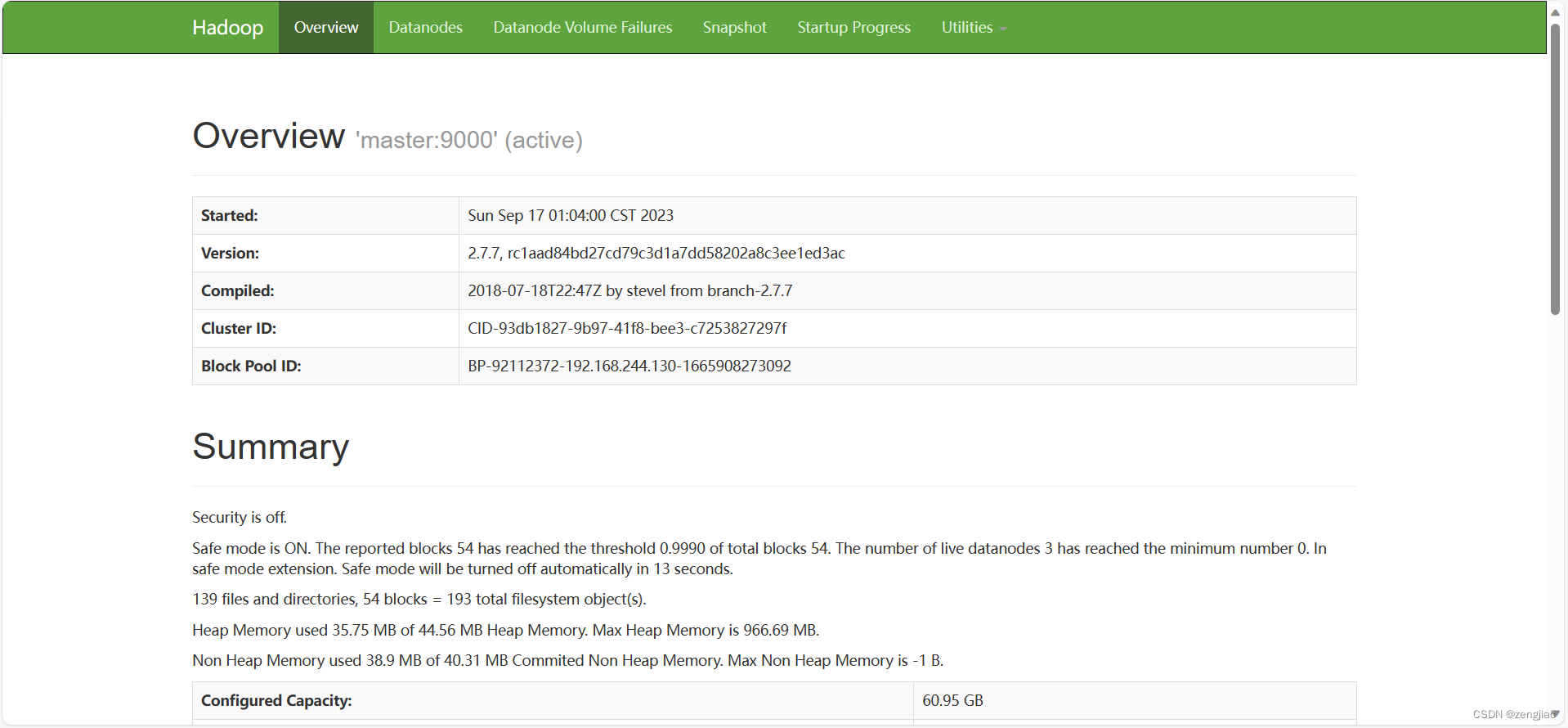
同时访问界面
其实就是Master:50070
使用命令行
1. 确认HDFS目标路径已存在,如果没有可以先创建:
bash
hdfs dfs -mkdir /zjcbigdata2. 上传本地文件到HDFS路径下:
bash
hdfs dfs -put /root/res.csv /zjcbigdata这个命令会把本地/root/res.csv文件上传到HDFS的/zjcbigdata路径下。3. 验证文件是否上传成功:
bash
hdfs dfs -ls /zjcbigdata如果成果进入界面可以找到

















 1680
1680

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









