







OUC2022秋季软工09组第二次作业
声明
本博客为OUC2022秋季软件工程第二次作业
一、视频学习心得及问题总结
1.1、学习心得
人工智能和机器学习的概述,回顾了这几年全球各个国家在人工智能领域提出的政策并分析当下人工智能的人才培养,如今人工智能这个词已经家喻户晓,虽然每年都有很多人工智能相关专业的人才毕业,但是在人工智能领域仍然有很大的人才缺口继续填补。人工智能起源于1956年的在美国召开的达特茅斯会议,从此人工智能到现在经历了三起两落的状态,也从第一阶段的计算智能过渡到了感知智能,从一个只会计算的机器到了能够听说读写等等的智能机器。与人工智能相关的有机器学期以及当下最火热的深度学习,总体领域范围是如下 人工智能 > 机器学习 > 深度学习,机器学习的主要问题是怎么学,通过对问题的建模,确定假设空间和目标函数,根据目标函数求解最优模型,求解模型参数。其中又分为监督、无监督学习、半监督和强化学习,机器学习虽然也应用了神经网络但是层数不够多,深度学习应用了深度神经网络,随着各种硬件的支持算力的提高等等,发展的越来越快,应用领域已经遍及到我们周围。但是深度学习也有其不能地方,如算法输出不稳定容易被攻击,模型复杂难以纠错,模型层级符合程度高,参数不透明等等。对于神经网络,有生物神经元到M-P神经元,多信号输入累加,超过阈值神经元就会被激活,如S性函数、ReLU、双极S性函数、Leaky ReLU等等激活函数,神经网络中参数的学习误差反向传播,根据误差信号回传来重新调整神经元权重,而误差信号就是梯度,深层神经网络会出现梯度消失的问题,会导致误差无法传播,多层网络陷入局部极值,无法继续优化,对于这种情况引入多层神经网络,进行逐层预训练和微调。自编码器是一种假设输出和输入相同尽可能复现输入信号的神经网络,一般是多层神经网络。受限玻尔兹曼机是两层神经网络,包含可见层和隐藏层,是基于概率分布定义,高层是底层特征条件的概率1,输出只有两种状态。
1.2、问题总结
1、深度学习是运用了神经网络的机器学习,即赋予计算机类似我们人脑“神经元”的部分,那么它是否会向我们人脑一样实现预测效果?(就像我们下围棋总会预测对手下一步甚至下几步的想法)它又是如何实现联想储存记忆和高速寻找最优解的问题?
2、我们现如今所研究的卷积神经网络CNN和循环神经网络RNN是如何应用到深度学习中的?其研究前景和市场价值如何?
3、对于某一具体问题怎么样通过代码实现对问题的建模和解决呢?怎样才能快速上手在一些小的项目上实现呢?
4、对于其中的激活函数怎么运用以及损失函数怎么构造和运用?
5、当下深度学习的瓶颈在哪里呢?是算力、算法、数据集还是其他什么因素?以及这两天看到LeCun说概率论无法实现真正的AI, 我们要退回原点重新开始。这句话是指我们基于概率建立起来的AI这座大厦是理论基础就有问题吗?最近几年到十几年会不会迎来人工智能的第三次低谷?
6、在第一个视频中,我们得知深度学习比传统机器学习在很多方面具有很大的优势,那么传统机器学习对比深度学习有没有存在优势的地方?
7、我们知道深度学习有三个助推剂:大数据、算法、计算力。这三个助推剂是如何推动深度学习的发展的?此外,这三个元素哪个对深度学习的推动作用最大?是否在这三个元素中有一个元素因为发展速度跟不上其它两个元素的发展速度而限制了深度学习的发展速度?
8、第二个视频中,我们知道,深度学习的算法依赖于大数据,但数据不是中立的:从真实社会中抽取,必然带有社会固有的不平等、排斥性和歧视。深度学习中还有没有视频没有提到的机器偏见相关的问题?深度学习中这些类似机器偏见的伦理性问题是否是无法规避的?
二、代码练习
2.1、pytorch基础练习
2.1.1 定义数据
用torch.Tensor 定义数据:
-
一个数
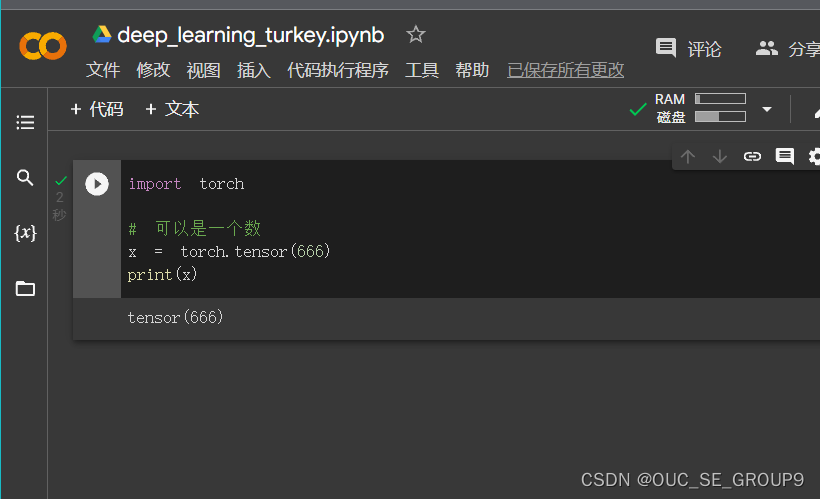
-
一维数组
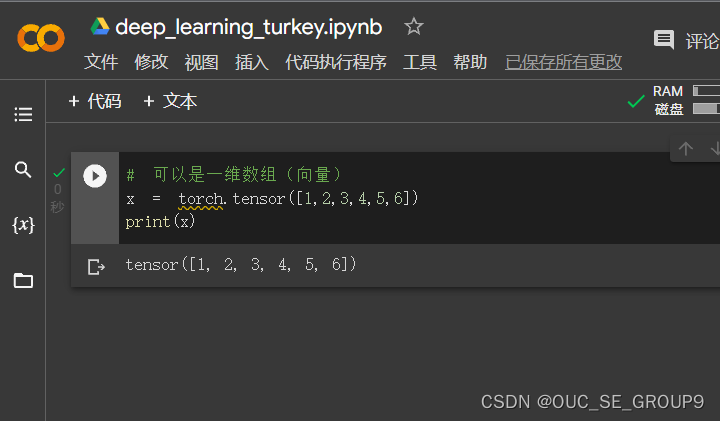
-
二维数组
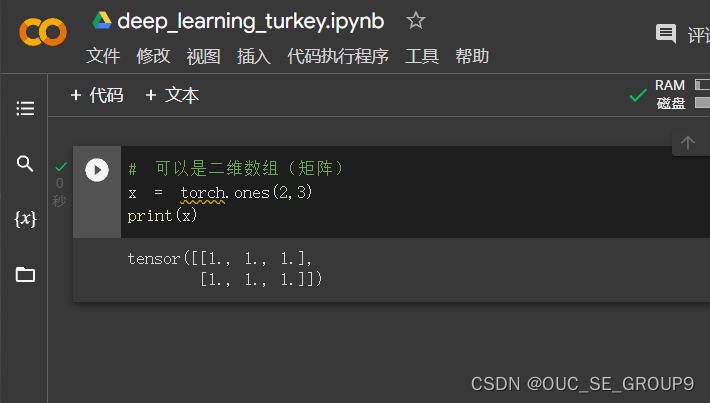
-
张量
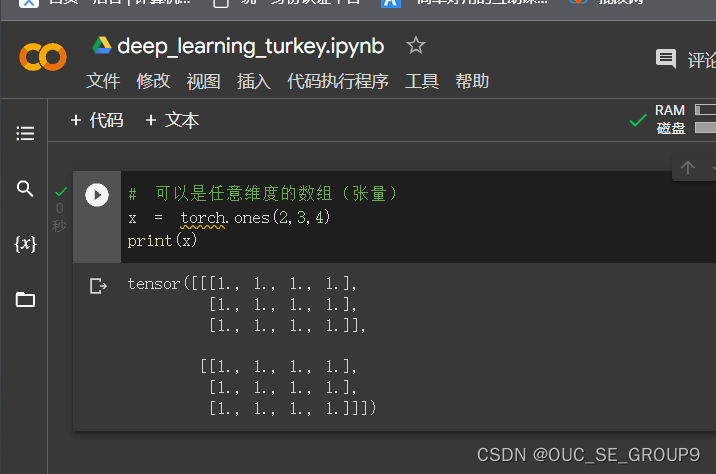
创建Tensor的其他方法:
-
创建一个空张量
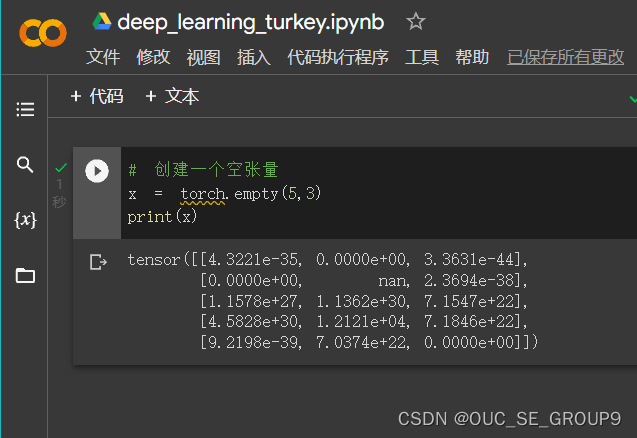
-
创建一个随机初始化的张量
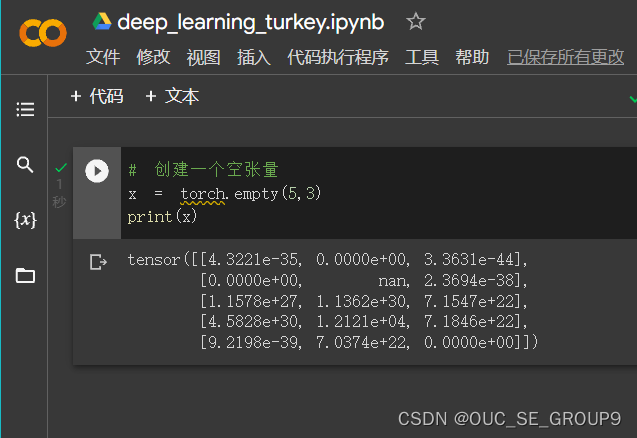
-
创建一个全0的张量,里面的数据类型为 long
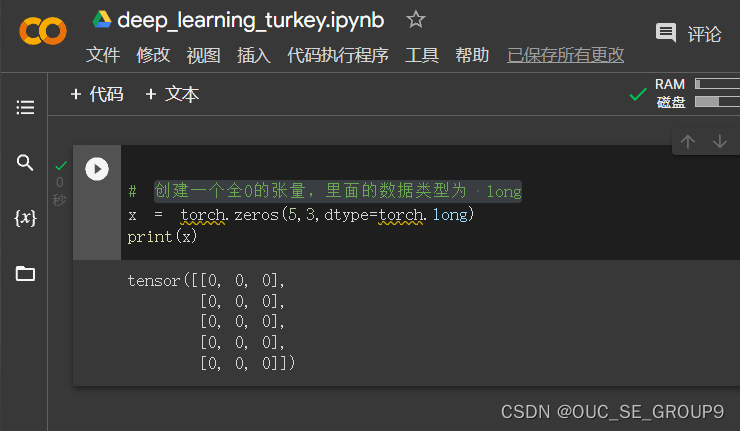
-
基于现有的tensor,创建一个新tensor,从而可以利用原有的tensor的dtype,device,size之类的属性信息
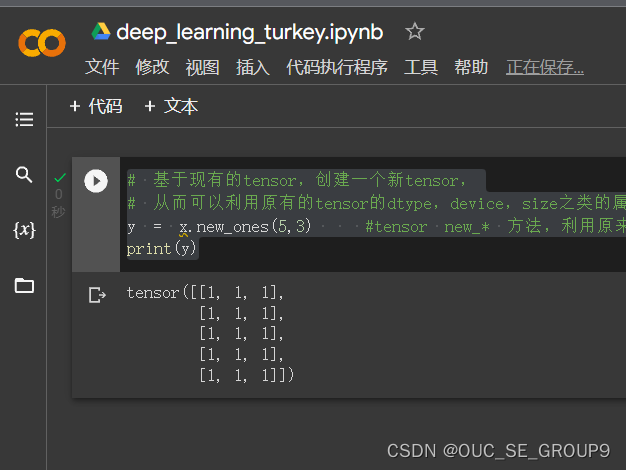
-
利用原来的tensor的大小,但是重新定义了dtype
2.1.2定义操作
-
创建一个 2x4 的tensor
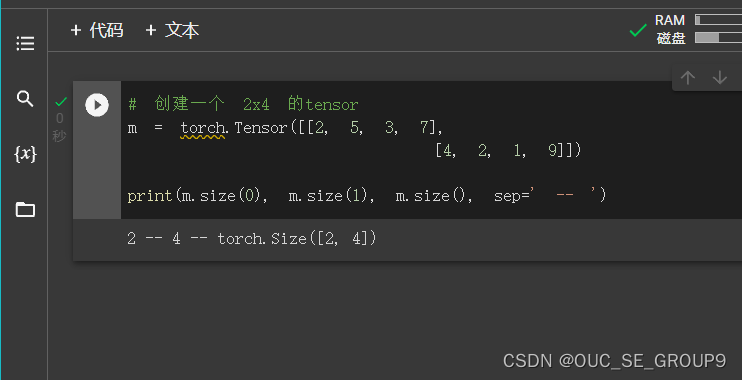
-
返回 m 中元素的数量
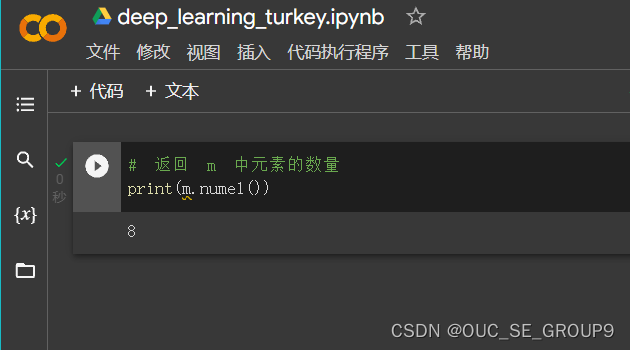
-
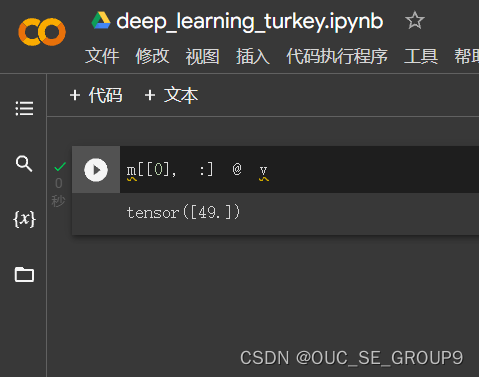
返回第0行,第2列的数
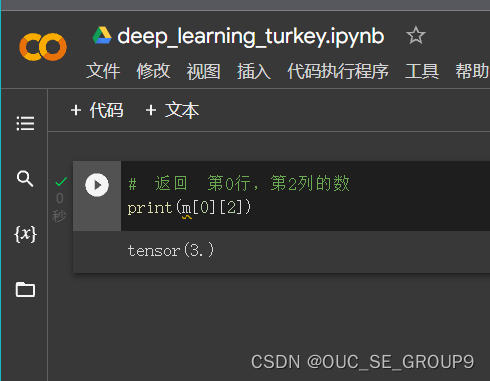
-
返回第1列的全部元素
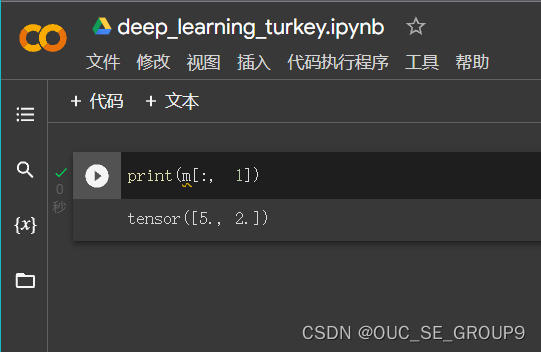
-
返回第0行的全部元素
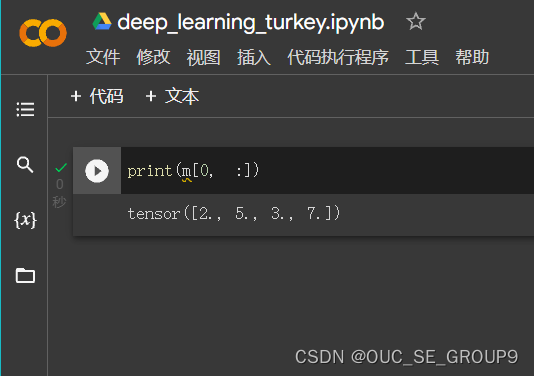
-
Create tensor of numbers from 1 to 5(生成从1to4的数)
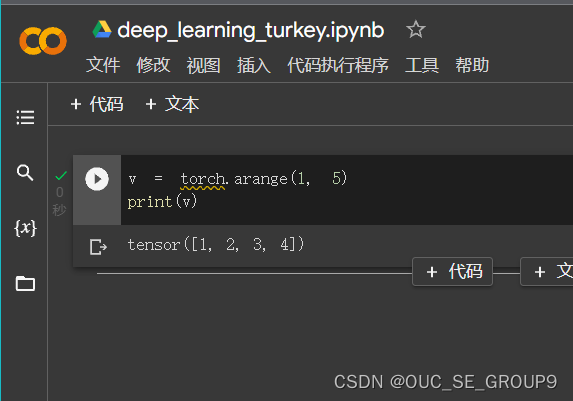
-
Scalar product(标量积)
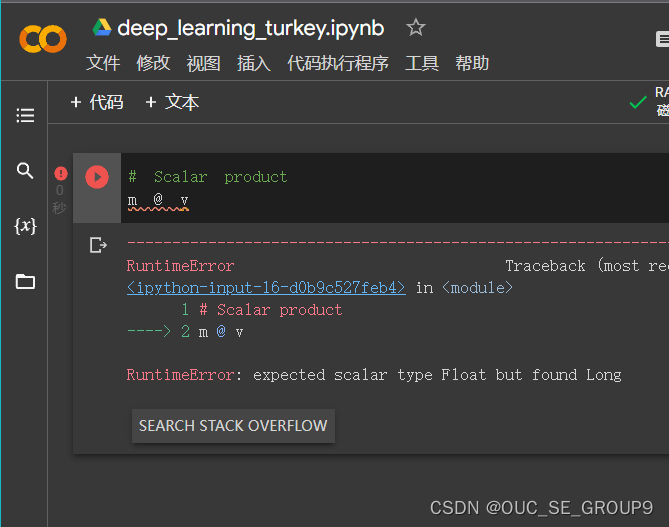
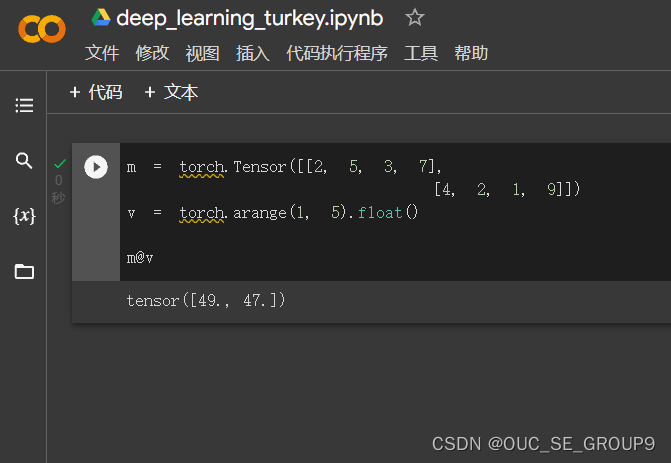
-
Calculated by 12 + 25 + 33 + 47
-
Add a random tensor of size 2x4 to m
-
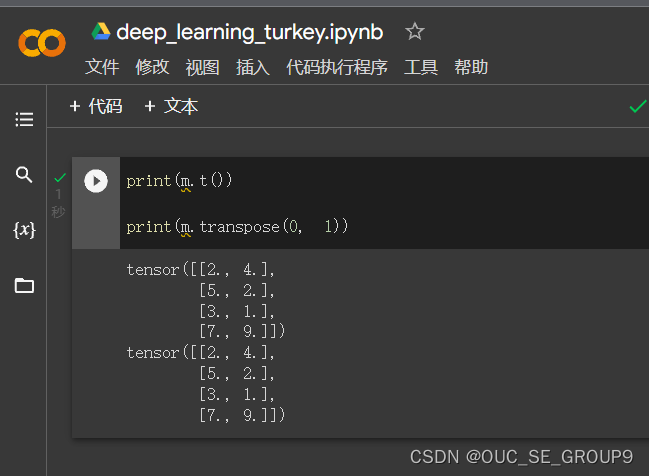
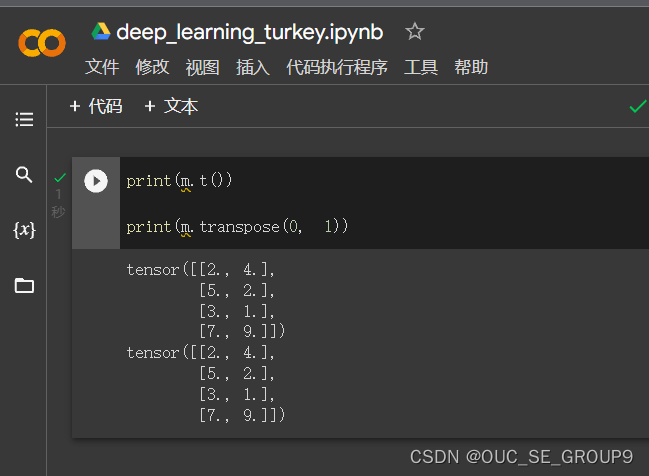
转置,由 2x4 变为 4x2;或者用transpose也可以
-
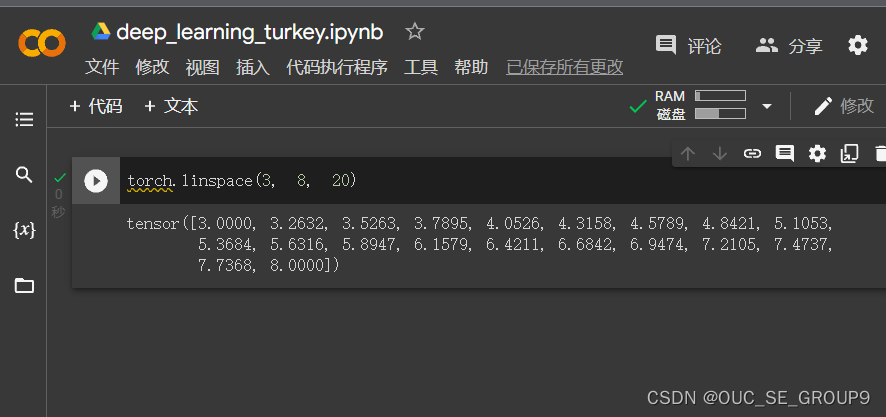
returns a 1D tensor of steps equally spaced points between start=3, end=8 and steps=20在这里插入图片描述
-
下面是生成 1000 个随机数,并按照 100 个 bin 统计直方图在这里插入图片描述
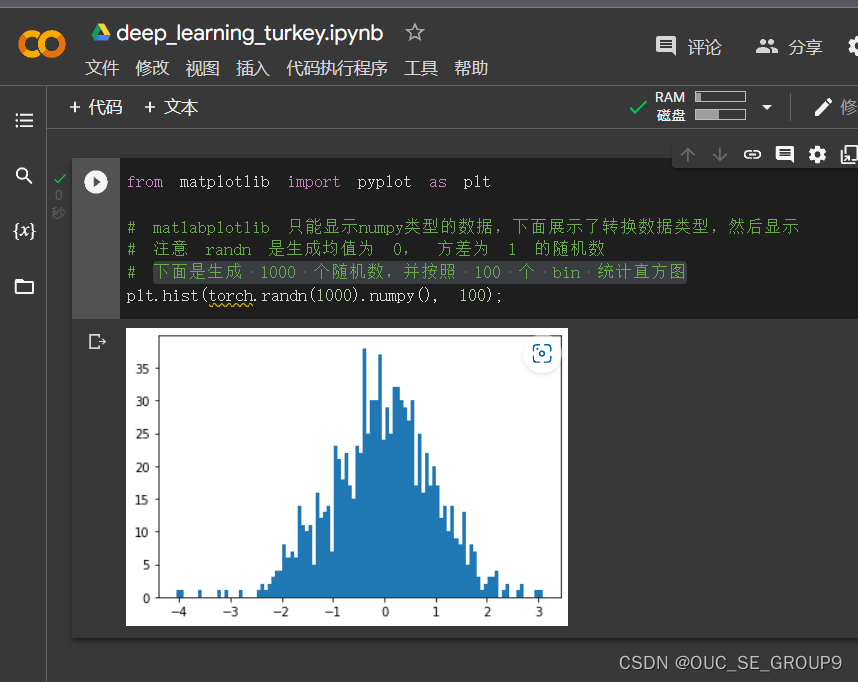
-
当数据非常非常多的时候,正态分布会体现的非常明显*
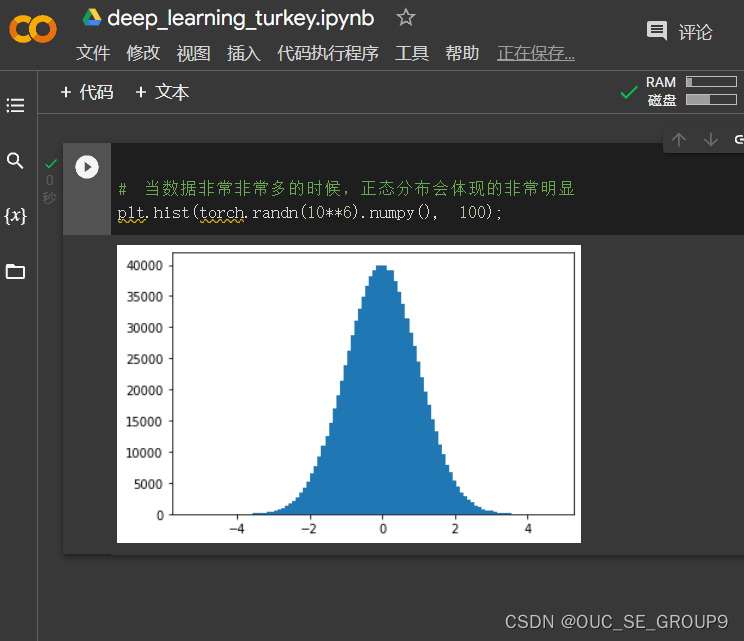
-
创建两个 1x4 的tensor。在 0 方向拼接 (即在 Y 方各上拼接), 会得到 2x4 的矩阵
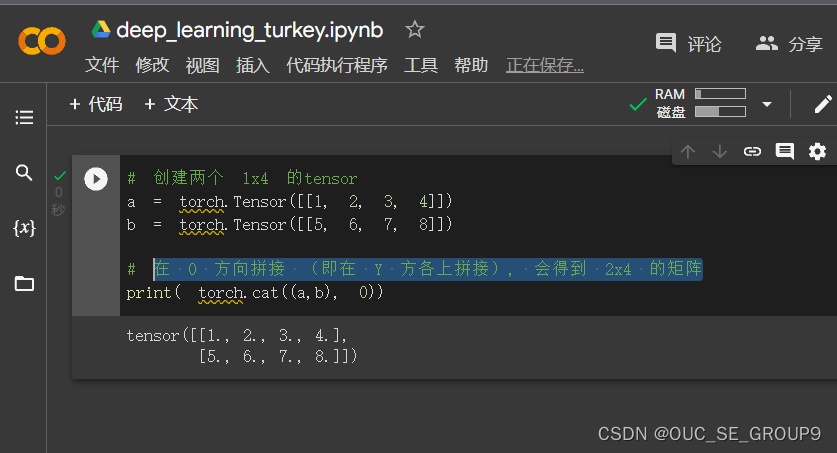
-
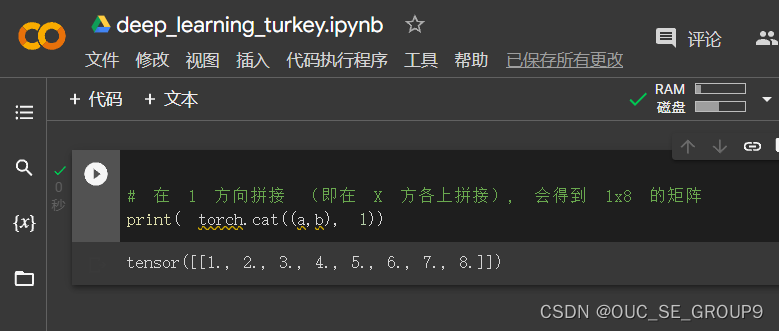
在 1 方向拼接 (即在 X 方各上拼接), 会得到 1x8 的矩阵
2.1.3. 实验体会:
- 学习了pytorch 的一些基础操作,但是由于是按照操作手册做的,对于其中一些函数的具体调用如参数传递和返回值的类型等等还有待进一步深入学习。
- 在2.7运行代码时发现了报错,查阅csdn相关博客发现是数据类型出错,torch.arange()产生的数据类型为Long型,而torch.Tensor()产生的为float型。
解决方法参考了:http://t.csdn.cn/SE1hf
经过查找之后发现可以通过float()函数将v中的数据从Long转为float型再与m实现标量积
- 还有一些疑惑:
创建的空张量和随机初始化的张量一样???
随机数的生成是就按照高斯分布(正态分布)函数来生成的,还是任意一组足够多的随机数都符合高斯分布???
2.2、 螺旋数据分类
一、实验过程:
1.下面代码是下载绘图函数到本地
2.引入基本的库,然后初始化重要参数
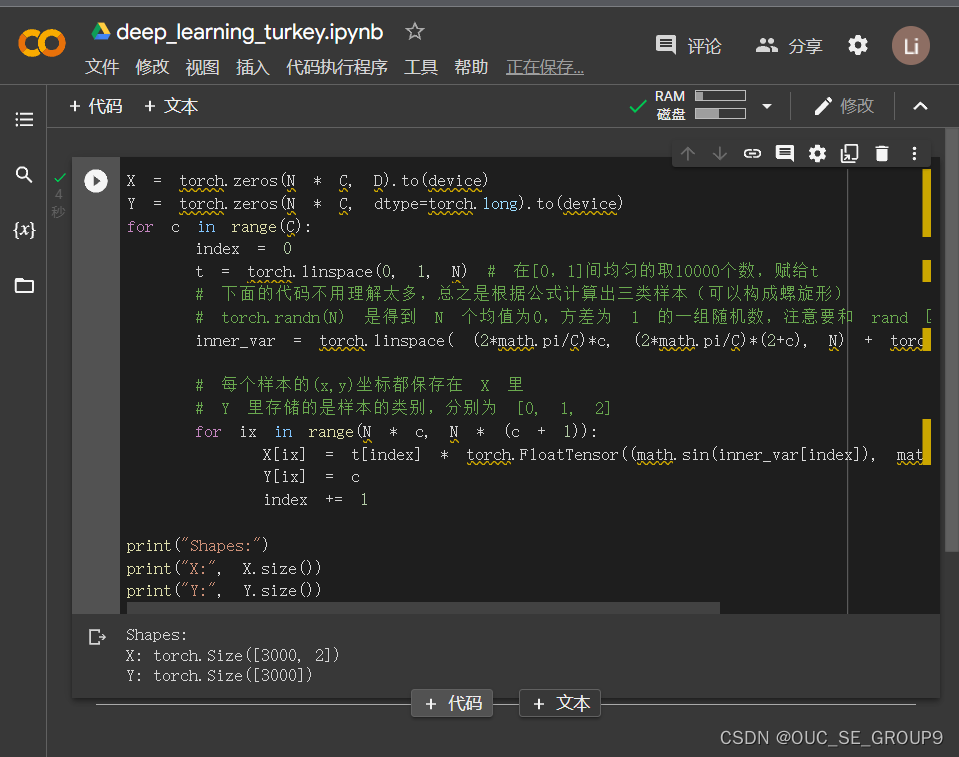
3.初始化 X 和 Y
X 可以理解为特征矩阵,Y可以理解为样本标签。 结合代码可以看到,X的为一个 NxC 行, D 列的矩阵。C 类样本,每类样本是 N个,所以是 N*C 行。每个样本的特征维度是2,所以是 2列。
在 python 中,调用 zeros 类似的函数,第一个参数是 y方向的,即矩阵的行;第二个参数是 x方向的,即矩阵的列,大家得注意下,不要搞反了。下面结合代码看看 3000个样本的特征是如何初始化的。
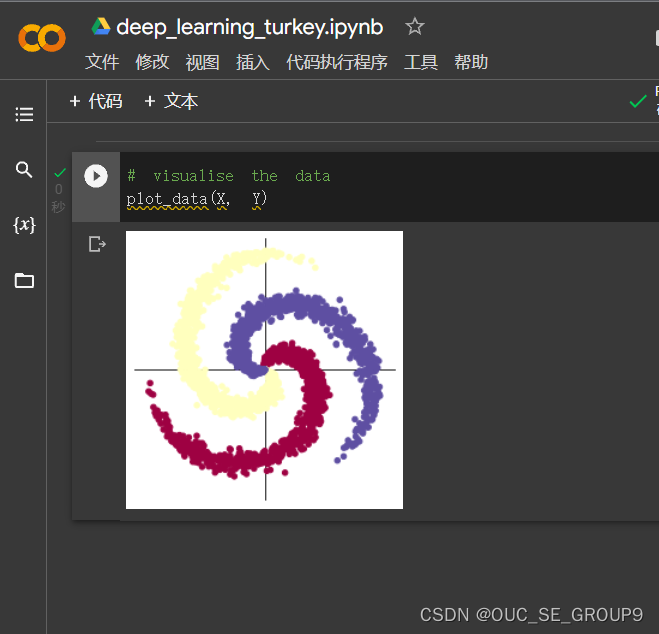
4.打印图像
5.构建线性模型分类
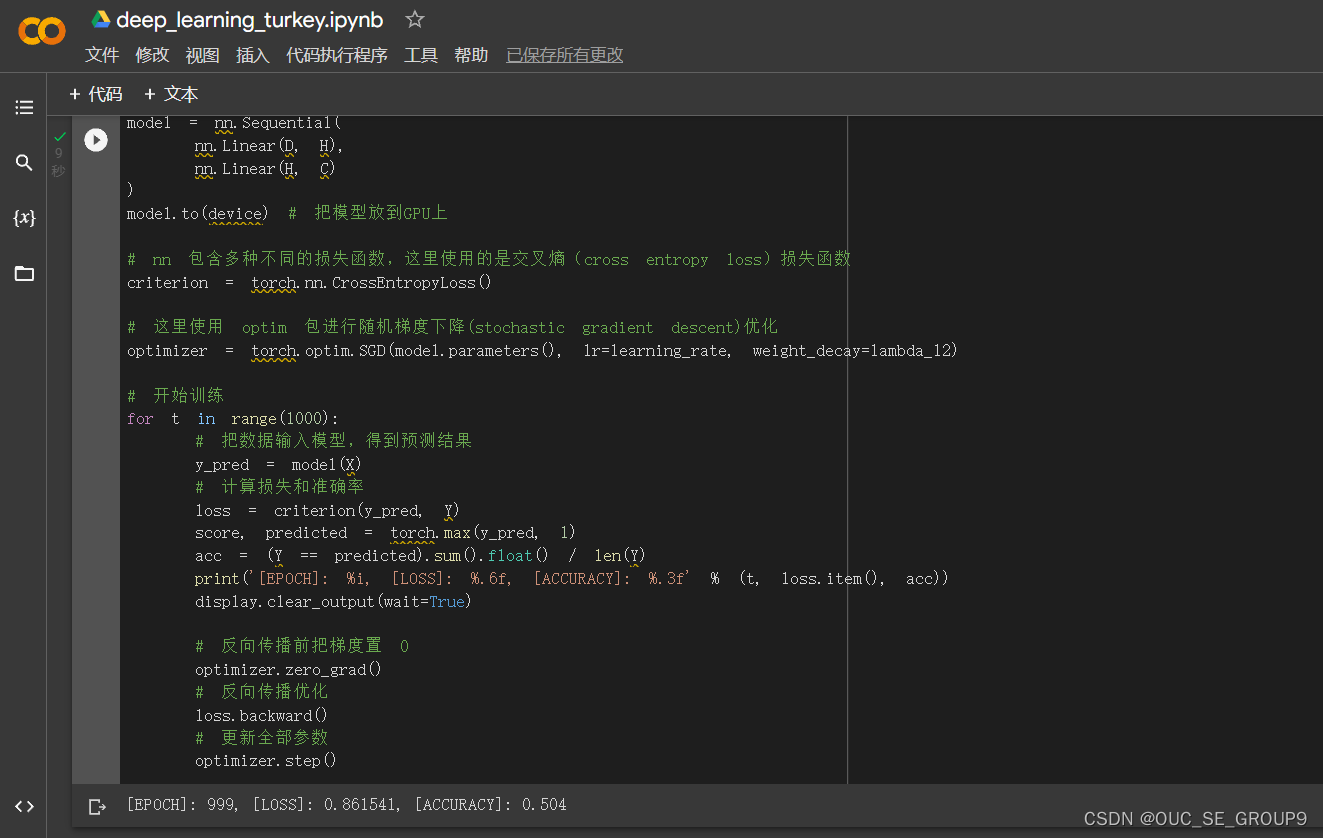
6.模型的预测结果
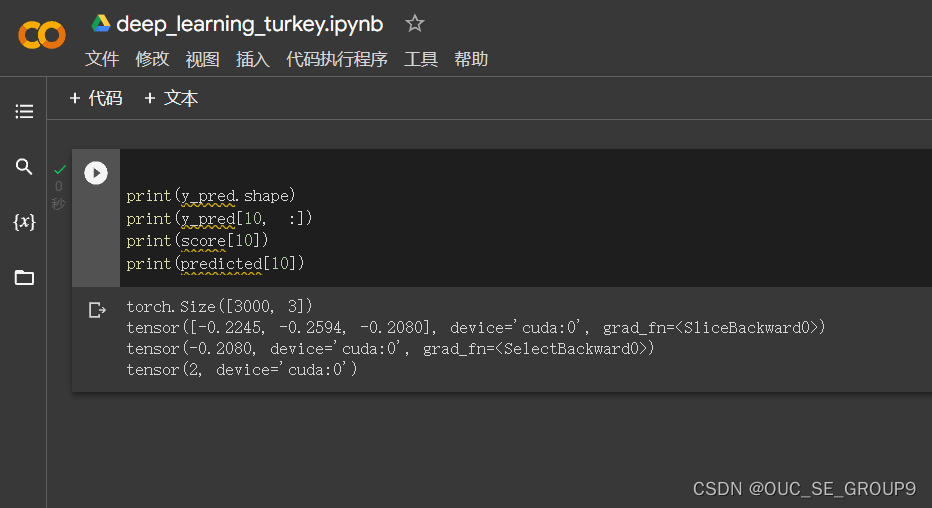
使用 print(y_pred.shape) 可以看到模型的预测结果,为[3000, 3]的矩阵。每个样本的预测结果为3个,保存在 y_pred 的一行里。值最大的一个,即为预测该样本属于的类别
score, predicted = torch.max(y_pred, 1) 是沿着第二个方向(即X方向)提取最大值。最大的那个值存在 score 中,所在的位置(即第几列的最大)保存在 predicted 中。下面代码把第10行的情况输出
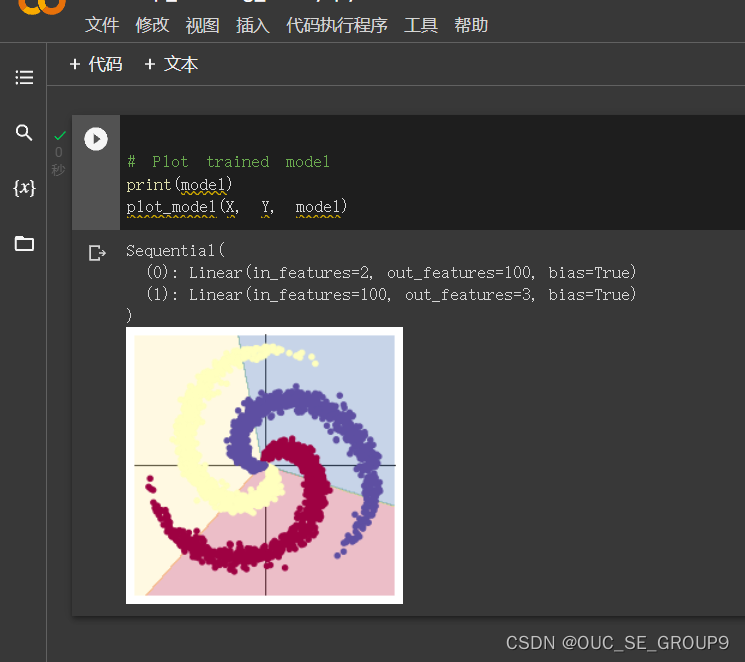
7.Plot trained model
8.构建两层神经网络分类
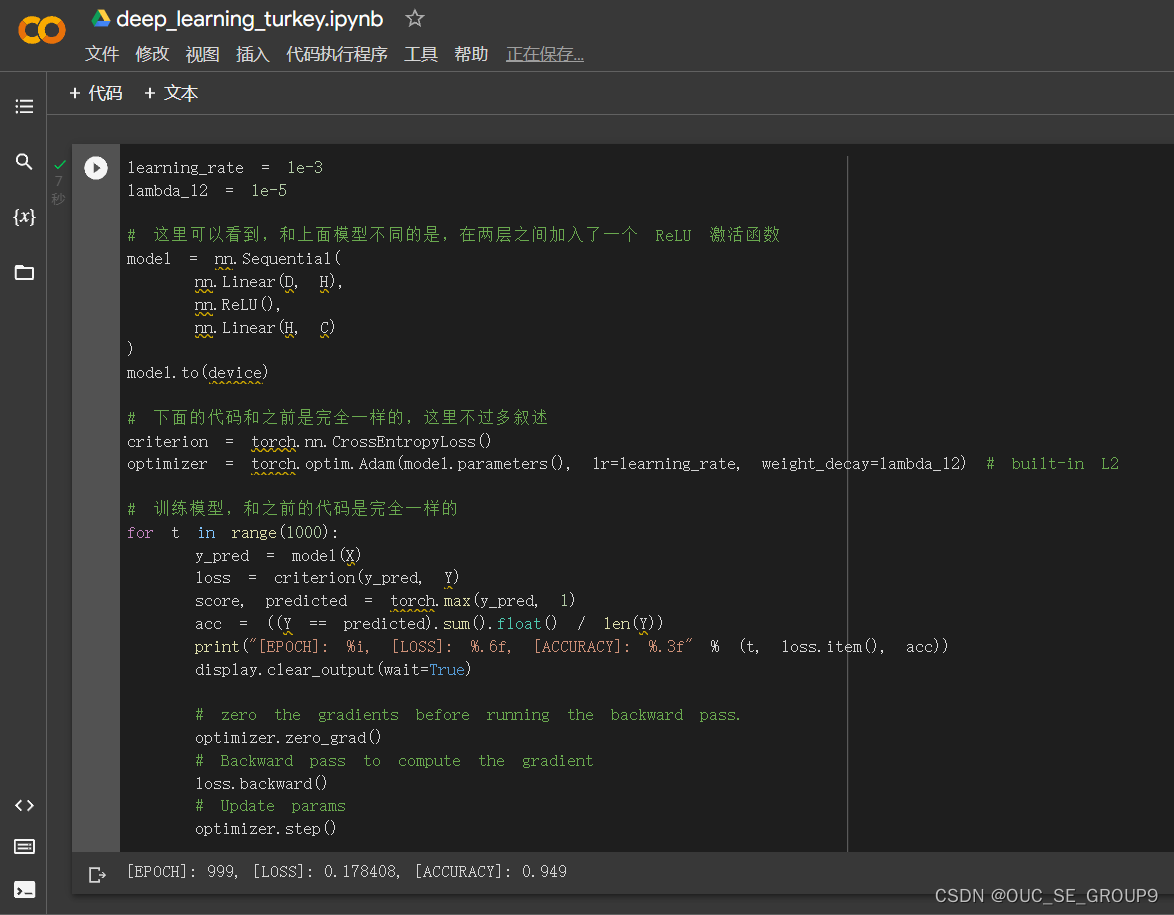
9.Plot trained model
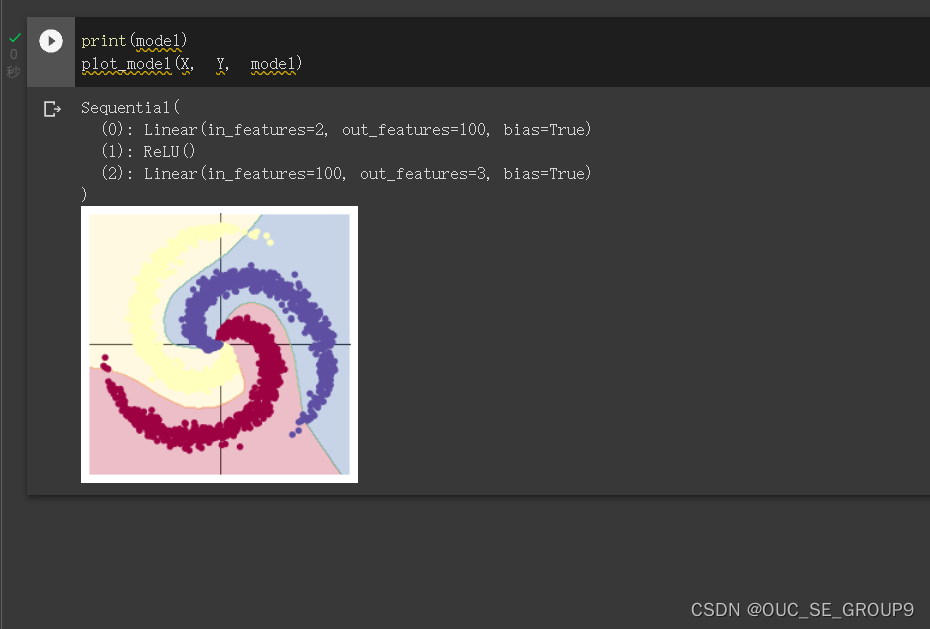
二、实验体会:
-
ReLU激活函数(线性整流函数)
通过查询资料(https://cloud.tencent.com/developer/article/1747601#3.1)对ReLU激活函数(线性整流函数)有了初步的了解。通过ReLU函数实现了单侧抑制的操作,使得神经网络中的神经元具有了稀疏激活性。通过ReLU实现稀疏后的模型能够更好地挖掘相关特征,拟合训练数据。这也是前后两次打印模型所显示出差别的重要原因。
-
这个数据分类感觉有点像抠图或者是边缘检测,就是把某一块相似的或者属于某一整体的抠出来,但是这个可能有稍微有点不一样,就是数据离散化,不像图像中一般要扣的图像或者边缘都是连接在一起的。
-

这个问题没有思路,为什么会都是大约,一个是+, 而另一个是 - ?















 2165
2165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









