






一、卷积神经网络
1、卷积神经网络(CNN)
卷积神经网络:一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一。
卷积:
。它是通过两个函数f和g生成第三个函数的一种数学运算,表征函数f与g经过翻转和平移的重叠部分的面积。
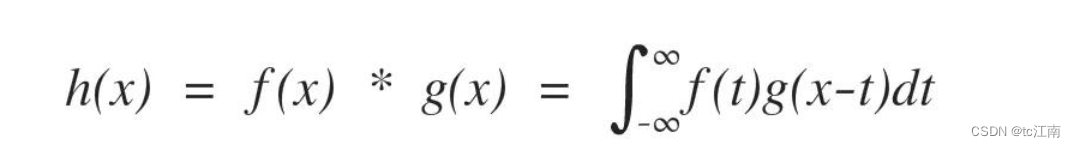
2、前馈神经网络
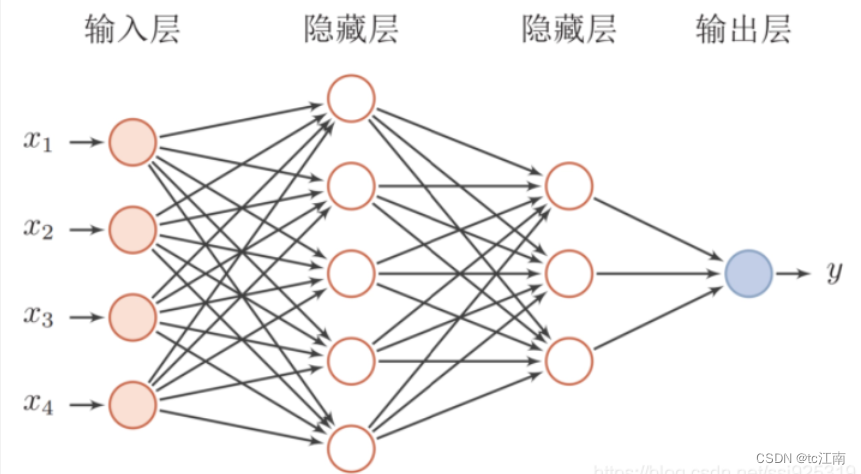
前馈神经网络是一种最简单的神经网络,各神经元分层排列。每个神经元只与前一层的神经元相连。接收前一层的输出,并输出给下一层.各层间没有反馈。
其中每一层包含若干个神经元,各神经元可以接收前一层神经元的信号,并产生输出到下一层。第0层叫输入层,最后一层叫输出层,其他中间层叫做隐含层(或隐藏层、隐层),隐层可以是一层。也可以是多层。
一个典型的多层前馈神经网络如下图所示
3、卷积神经网络
卷积神经网络是在前馈神经网络的隐藏层做的改变,它的隐藏层包括卷积层、池化层、全连接层三部分。
卷积神经网络的输入层可以处理多维数据:
| n维卷积神经网络 | 处理数据类型 |
|---|---|
| 一维卷积神经网络 | 一维或二维数组 |
| 二维卷积神经网络 | 二维或三维数组 |
| 三维卷积神经网络 | 四维数组 |
由于卷积神经网络在计算机视觉领域应用较广,因此许多研究在介绍其结构时预先假设了三维输入数据,即平面上的二维像素点和 RGB 通道。
卷积层(包含有卷积核、卷积层参数、激励函数):使用卷积核进行特征提取和特征映射。
卷积核 类似于一个前馈神经网络的神经元,组成卷积核的每个元素都对应一个权重系数核一个偏差量,含义可类比视觉皮肤细胞的感受野
卷积层参数 包括卷积核大小、步长、填充,三者共同决定了卷积层输出特征图的尺寸,是卷积神经网络的超参数
激励函数 协助表达复杂的特征,类似于其它深度学习算法。
在卷积层进行特征提取后,输出的特征图会被传递至池化层进行特征选择和信息过滤。
池化层包含预设定的池化函数,其功能是将特征图中单个点的结果替换为其相邻区域的特征图统计量。
池化层选取池化区域与卷积核扫描特征图步骤相同,由池化大小、步长和填充控制。
最大池化——>它只是输出在区域中观察到的最大输入值。
均值池化——>它只是输出在区域中观察到的平均输入值。
两者最大区别在于卷积核的不同(池化是一种特殊的卷积过程)。
二、配置环境
1、安装anoconda
网上有相关的教程。
2、打开cmd终端,创建虚拟环境。
conda create -n tf1 python=3.6
3、激活环境
activate
conda activate tf1

4、安装 tensorflow、keras 库。
pip install tensorflow==1.14.0 -i “https://pypi.doubanio.com/simple/”
pip install keras==2.2.5 -i “https://pypi.doubanio.com/simple/”
5、安装 nb_conda_kernels 包
conda install nb_conda_kernels

6、打开Jupyer
创建Python文件
三、猫狗数据分析
图片数据集下载:
链接: link
提取码:ruyn
下载后,放在没有中文路径的文件下
1、预处理
代码如下:
import os, shutil
# 原始目录所在的路径
original_dataset_dir = 'E:\\Cat_And_Dog\\train\\'
# 数据集分类后的目录
base_dir = 'E:\\Cat_And_Dog\\train1'
os.mkdir(base_dir)
# # 训练、验证、测试数据集的目录
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
# 猫训练图片所在目录
train_cats_dir = os.path.join(train_dir, 'cats')
os.mkdir(train_cats_dir)
# 狗训练图片所在目录
train_dogs_dir = os.path.join(train_dir, 'dogs')
os.mkdir(train_dogs_dir)
# 猫验证图片所在目录
validation_cats_dir = os.path.join(validation_dir, 'cats')
os.mkdir(validation_cats_dir)
# 狗验证数据集所在目录
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
os.mkdir(validation_dogs_dir)
# 猫测试数据集所在目录
test_cats_dir = os.path.join(test_dir, 'cats')
os.mkdir(test_cats_dir)
# 狗测试数据集所在目录
test_dogs_dir = os.path.join(test_dir, 'dogs')
os.mkdir(test_dogs_dir)
# 将前1000张猫图像复制到train_cats_dir
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_cats_dir, fname)
shutil.copyfile(src, dst)
# 将下500张猫图像复制到validation_cats_dir
fnames = ['cat.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_cats_dir, fname)
shutil.copyfile(src, dst)
# 将下500张猫图像复制到test_cats_dir
fnames = ['cat.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_cats_dir, fname)
shutil.copyfile(src, dst)
# 将前1000张狗图像复制到train_dogs_dir
fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_dogs_dir, fname)
shutil.copyfile(src, dst)
# 将下500张狗图像复制到validation_dogs_dir
fnames = ['dog.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_dogs_dir, fname)
shutil.copyfile(src, dst)
# 将下500张狗图像复制到test_dogs_dir
fnames = ['dog.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_dogs_dir, fname)
shutil.copyfile(src, dst)
2、查看数量
#输出数据集对应目录下图片数量
print('total training cat images:', len(os.listdir(train_cats_dir)))
print('total training dog images:', len(os.listdir(train_dogs_dir)))
print('total validation cat images:', len(os.listdir(validation_cats_dir)))
print('total validation dog images:', len(os.listdir(validation_dogs_dir)))
print('total test cat images:', len(os.listdir(test_cats_dir)))
print('total test dog images:', len(os.listdir(test_dogs_dir)))

四、猫狗分类的实例——基准模型
1、构建网络模型
#网络模型构建
from keras import layers
from keras import models
#keras的序贯模型
model = models.Sequential()
#卷积层,卷积核是3*3,激活函数relu
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
#最大池化层
model.add(layers.MaxPooling2D((2, 2)))
#卷积层,卷积核2*2,激活函数relu
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
#最大池化层
model.add(layers.MaxPooling2D((2, 2)))
#卷积层,卷积核是3*3,激活函数relu
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
#最大池化层
model.add(layers.MaxPooling2D((2, 2)))
#卷积层,卷积核是3*3,激活函数relu
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
#最大池化层
model.add(layers.MaxPooling2D((2, 2)))
#flatten层,用于将多维的输入一维化,用于卷积层和全连接层的过渡
model.add(layers.Flatten())
#全连接,激活函数relu
model.add(layers.Dense(512, activation='relu'))
#全连接,激活函数sigmoid
model.add(layers.Dense(1, activation='sigmoid'))
如果报错,使用如下命令:
pip install numpy==1.16.4 -i "https://pypi.doubanio.com/simple/"
再运行,就不会报错了
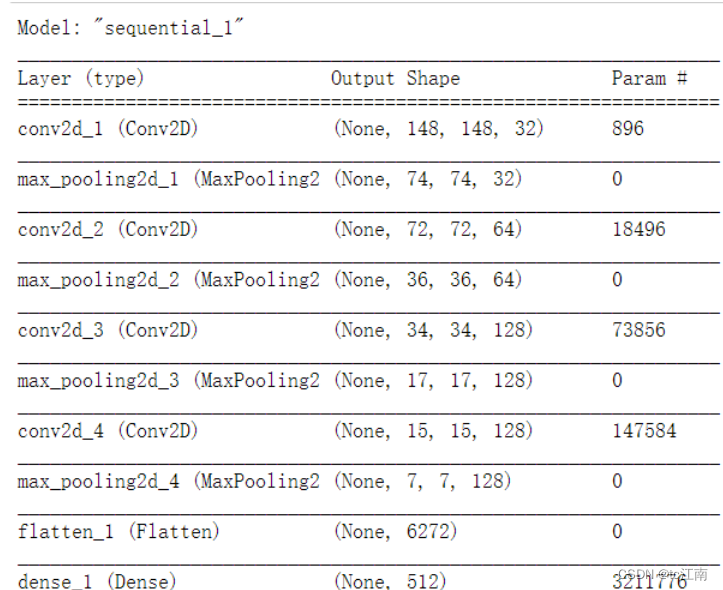
查看参数状况:
#输出模型各层的参数状况
model.summary()
结果如下:
2、配置优化器
代码如下:
from keras import optimizers
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
3、图片格式转化
代码:
from keras.preprocessing.image import ImageDataGenerator
# 所有图像将按1/255重新缩放
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# 这是目标目录
train_dir,
# 所有图像将调整为150x150
target_size=(150, 150),
batch_size=20,
# 因为我们使用二元交叉熵损失,我们需要二元标签
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
结果如下:

查看上述图像预处理过程中生成器的输出:
#查看上面对于图片预处理的处理结果
for data_batch, labels_batch in train_generator:
print('data batch shape:', data_batch.shape)
print('labels batch shape:', labels_batch.shape)
break
结果如下:

4、开始训练模型
#模型训练过程
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50)

5、保存模型
#保存训练得到的的模型
model.save('G:\\Cat_And_Dog\\kaggle\\cats_and_dogs_small_1.h5')
6、结果可视化
#对于模型进行评估,查看预测的准确性
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()

五、总结
1、什么是overfit
给定一个假设空间 H HH,一个假设 h hh 属于 H HH,如果存在其他的假设 h ’ h’h’ 属于 H HH,使得在训练样例上 h hh 的错误率比 h ’ h’h’ 小,但在整个实例分布上 h ’ h’h’ 比 h hh 的错误率小,那么就说假设 h hh 过度拟合训练数据。
2、数据增强
数据集增强主要是为了减少网络的过拟合现象,通过对训练图片进行变换可以得到泛化能力更强的网络,更好的适应应用场景。
由于数据量的增加,对比基准模型,可以很明显的观察到曲线没有过度拟合了,训练曲线紧密地跟踪验证曲线,这也就是数据增强带来的影响,但是可以发现它的波动幅度还是比较大的。
相比于只使用数据增强的效果来看,额外添加一层 dropout 层,仔细对比,可以发现训练曲线更加紧密地跟踪验证曲线,波动的幅度也降低了些,训练效果更棒了。














 3639
3639











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









