







卖模型就像感恩节卖火鸡,快才能赚钱。
最近的AI社区,关于模型规模的讨论有些活跃。
一方面,此前在大模型开发奉为“圣经”的Scaling Law,似乎正在褪去光环。去年大家还在猜测GPT-5的规模“可能会大到想不到”,现在这种讨论几乎绝迹。大神Andrej Karpathy,则是在感慨大模型规模正在“倒退”。
另一方面,近期市场上性能优秀的小型模型层出不穷,参数规模、任务处理、反应速度、安全性能,各公司在不同方面卷了又卷。
究竟是往大做探索极限,还是往小做迎合市场?
这最终汇总成一个问题:在这样模型快速更迭的市场中,要怎么才能把LLM模型的商业价值最大化?
1
唯快不破的模型业态
最近发起讨论的是X.ai创始成员之一的Toby Pohlen。他认为如果模型以指数级速度改进,那么训练模型的价值也会以指数级速度折旧。这也导致人们需要赶在模型更迭前就迅速采取行动获取商业价值,一旦模型产生更新,上一代模型就基本一文不值了。

Toby的这番言论深得老板Elon Musk之心,大笔一挥打了一个“100分”。

贾扬清也参与到了这场讨论中来,他用感恩节火鸡做了一个有趣的比喻。他提出,售卖模型就像是感恩节火鸡促销,必须在感恩节前夕抓紧时间售卖,避免在感恩节到来后的贬值。新模型的技术更新就是一个又一个感恩节,只有销售得更快才能赚到更多的利润。
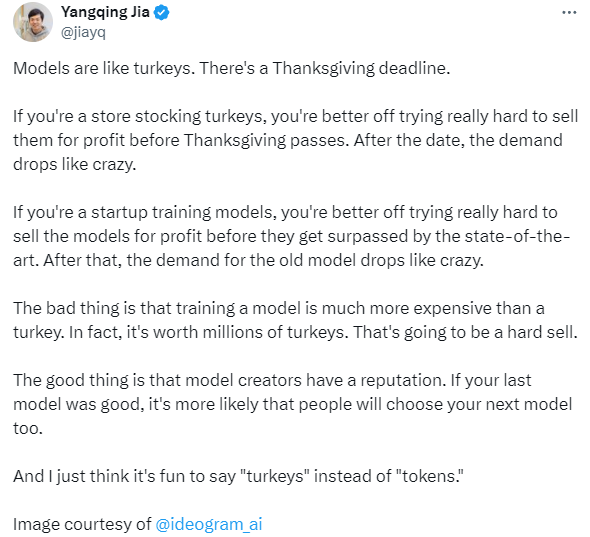
(emmm…如果对火鸡不好了解,换成中秋节前抢月饼的故事大家或许应该容易理解一些?)
评论区也有不少人表达了对此观点的赞同。
有人说只要不断地开发新产品和迭代新模型,就能从中持续获得商业价值。

还有人说,模型改进的频率将直接决定模型本身的商业价值。

但是,模型的商业价值由什么决定,又该如何实现?
2
模型发展在走CNN老路吗?
模型必须做小,用起来才顺手。
比起大型模型,小型模型成本低应用便利,更能收获商业市场的青睐。贾扬清就发现,行业趋势在于研发和使用尺寸更小性能强大的模型,人们也更愿意把规模参数在7B-70B之间的中小型模型作为商业使用的选择。

作为前大模型时代的亲历者,贾扬清在当下LLM模型市场上嗅到了熟悉的味道,先变大再变小变高效,这和CNN时期的模型发展简直一模一样。
贾扬清还对CNN的发展历程做了一个简单的介绍。
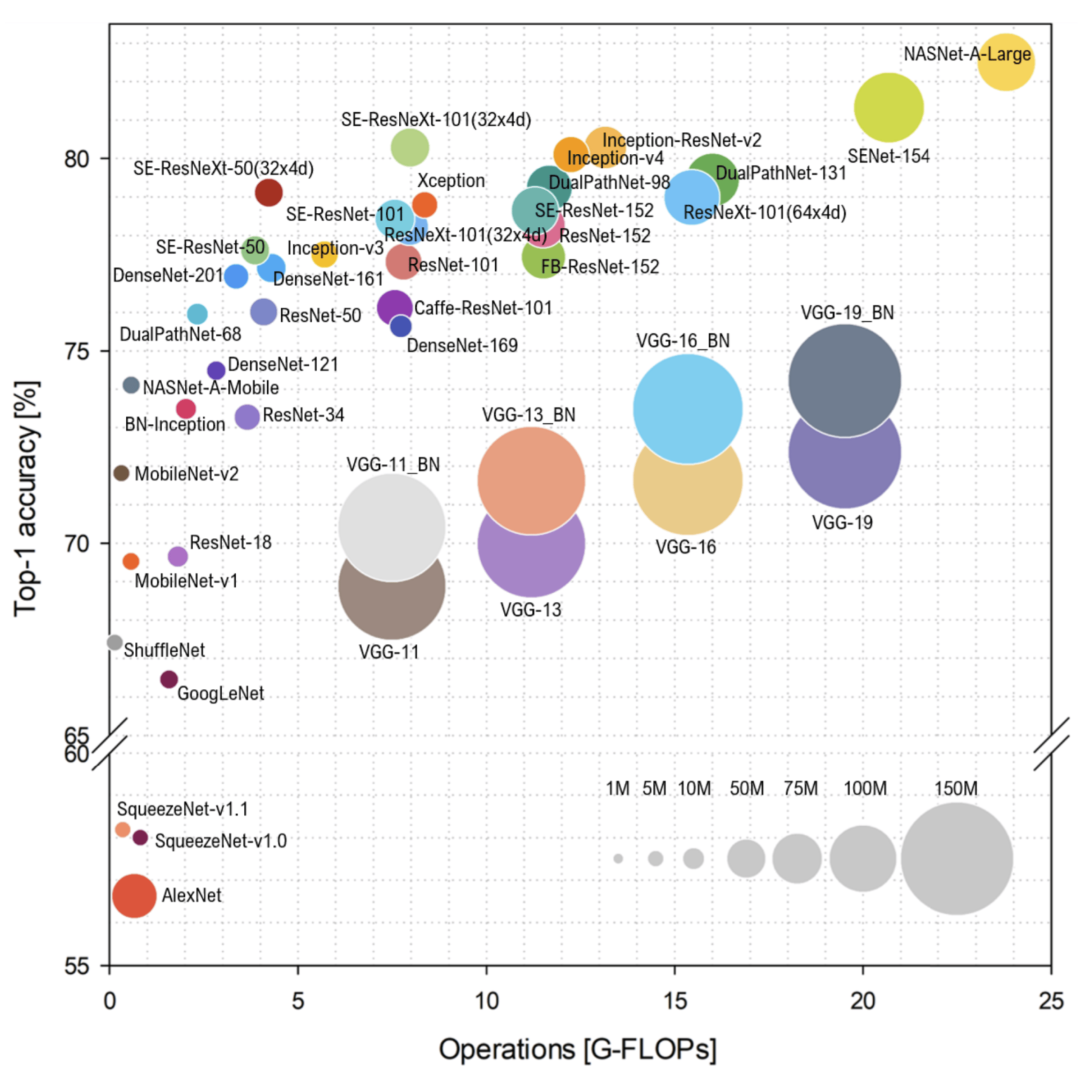
首先是2012年,AlexNet开启了模型大小增长的序幕。2014年的VGGNet就是一个规模较大的高性能模型。
到了2015年,模型尺寸开始缩小。GoogleNet 将模型大小从GB降至MB,缩小了100倍,还同时保持了良好的性能。同年面世的SqueezeNet也遵循了追求更小尺寸的趋势。
在此之后,模型发展的重点转移到了维持平衡。比如如 ResNet(2015)、ResNeXT(2016)等模型都保持了一个适中的规模,注重计算效率。
贾扬清还介绍了CNN的一个有趣的应用,Google的MobileNet(2017),占用空间小性能优越,还具有出色的特征嵌入泛化。
最后,贾扬清引用了Ghimire 等人在《高效卷积神经网络和硬件加速调查》里的一张图:
他还进一步发问,LLM模型未来会遵循和CNN一样的发展趋势吗?
3
大型模型的盈利思考
不过贾扬清也补充道,虽然行业趋势是模型小型化,但并不意味着号召大家放弃尺寸更大的模型。

但这随之而来的是另一个问题:大型模型的成本会更高。
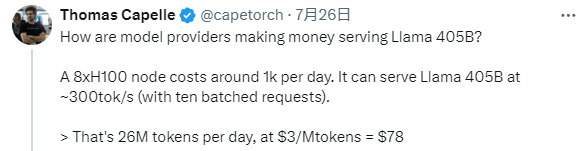
此前也有人提出质疑,对大型模型服务商的运营成本和营运收益做了简单的计算,每天8张H100显卡运营节点的成本约为1000美元,每天可以提供2600万token的服务,但按Llama 405B每一百万token 3美元的价格,怎么算都是亏本的,无法盈利的大型模型不会被市场抛弃吗?
贾扬清表示,哎你说这个我就不困了,我熟我来说:)
贾扬清认为,虽然每个请求大约每秒输出30个token,但通过批量处理(同时处理多个请求)可以显著提高总吞吐量,可以达到比单个请求高出10倍或更高的吞吐量。
同时他还指出,每秒大约30个token指的是输出token,大模型对于输入token的处理速度更快,这也增加了处理的总token数,大模型通常对输入和输出分别计费,也正是这个道理。
在后续的另一个回复,贾扬清做了更详细的量化计算:
批量输出速度:单并发405b推理通常有每秒30个token的输出速度。合理的并发可以使总吞吐量提高10倍,达到每秒300个token的输出吞吐量。
输入token:输入token也被计费,通常输入token的数量远大于输出token。一个常见的聊天机器人应用可能有2048个输入token和128个输出token。假设输入输出token比率为10:1,那么每秒300个输出token的处理量相当于每秒3000个输入token。
价格:每天总共处理285,120,000个token,按当前Lepton价格每百万token2.8美元计算,收入为798.34美元。
机器成本:以lambda按需价格为基准,每张H100卡每小时3.49美元,8张H100卡一天的成本为670.08美元。
收入798.34美元,成本670.08美元,因此通过整合多种技术方法,在合理流量下(像Lepton这样的大模型技术服务商)是可能盈利的。
当然,这只是一个简单的推算,实际的盈利还会受到流量稳定性、计费方式、按需使用GPU的机器成本控制、解码、提示缓存以及其他因素的影响。
但某种程度上说,类似深度学习时代对CNN的不断优化,在大模型时代,也需要技术人员对于模型进行种种优化,来保证性能提高的同时不断降低成本,这正是贾扬清看好的创业路线。
4
One more thing
我们不妨再多讨论一下,对于贾扬清这样的AI Infra创业者,模型大小的潮流变化对他的商业模式有什么影响?
这个问题,要分不同情况分析。
如果模型参数量越大,提供模型服务的门槛越高(参考Llama 405B),其客单价自然也就越大;
另一方面,由于很多小模型实际是在大模型的基础上蒸馏而得到,模型小了,所需的计算资源并没有等幅度减少
由于较小的模型更容易部署在不同的设备和平台上,这可能会带来应用场景的增加,虽然客单价可能降低,但在需求数量上的增加反而可能使得总收入增加;
对于贾扬清来说,META的开源路线使得贾扬清的服务对象扩大,因此开源对他来说更有利。
看来不管未来模型规模怎么不变化,贾扬清都有机会凭借技术升级稳坐钓鱼台。这有点像之前的中国股市,不管什么消息,都是“利好茅台”啊。
这恐怕就是贾扬清最近在推特上为什么这么活跃发表看法的原因?你看好贾扬清这种AI Infra的创业路线吗?















 1584
1584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









