






LLM四阶段技术
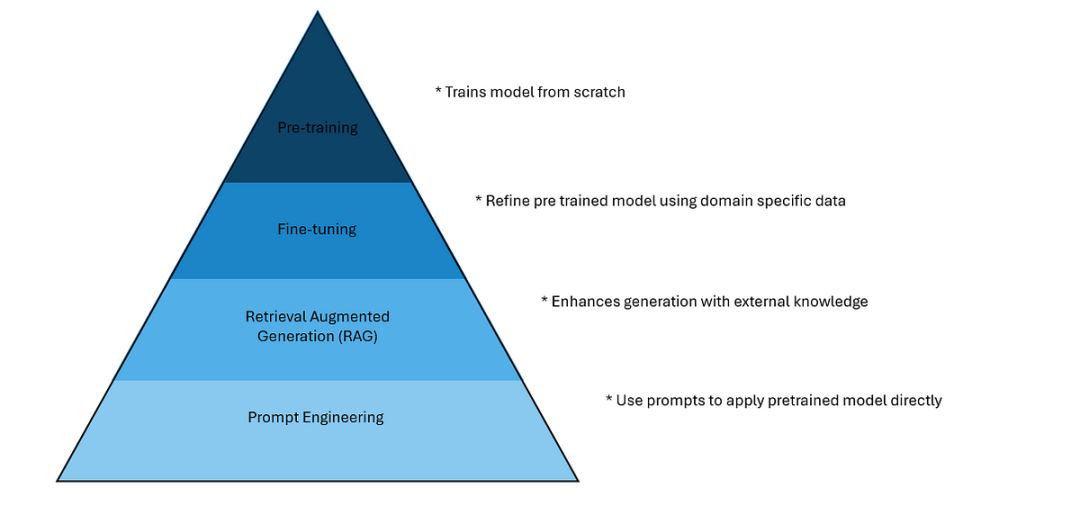
**在探讨大模型(LLM)的四阶段技术时,我们可以从****Prompt Engineering(提示工程)、AI Agent(人工智能代理)、Fine-tuning(微调)以及Pre-training(预训练)**这四个关键阶段来详细阐述,这四个阶段技术层层递进。

LLM四阶段技术
阶段一:Prompt Engineering
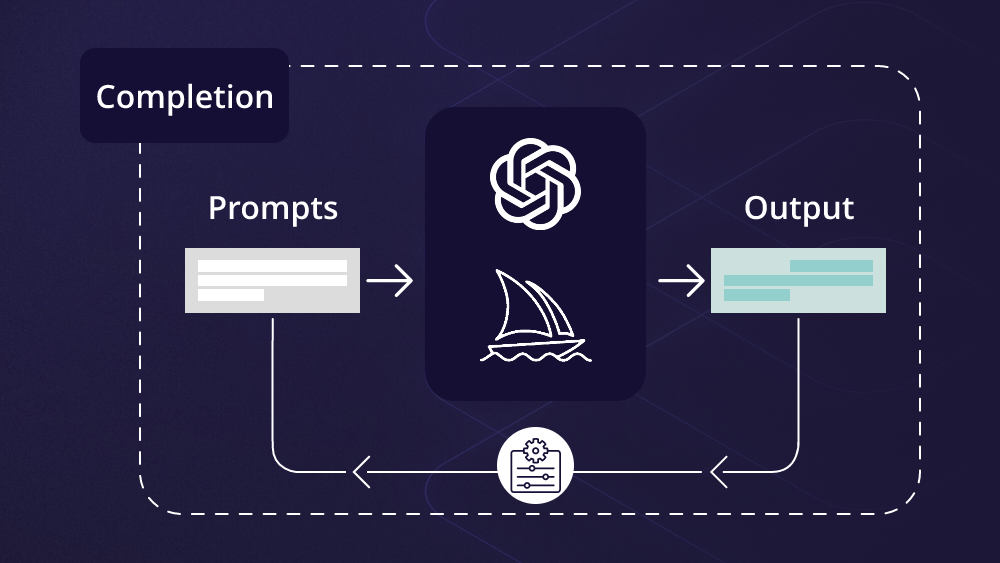
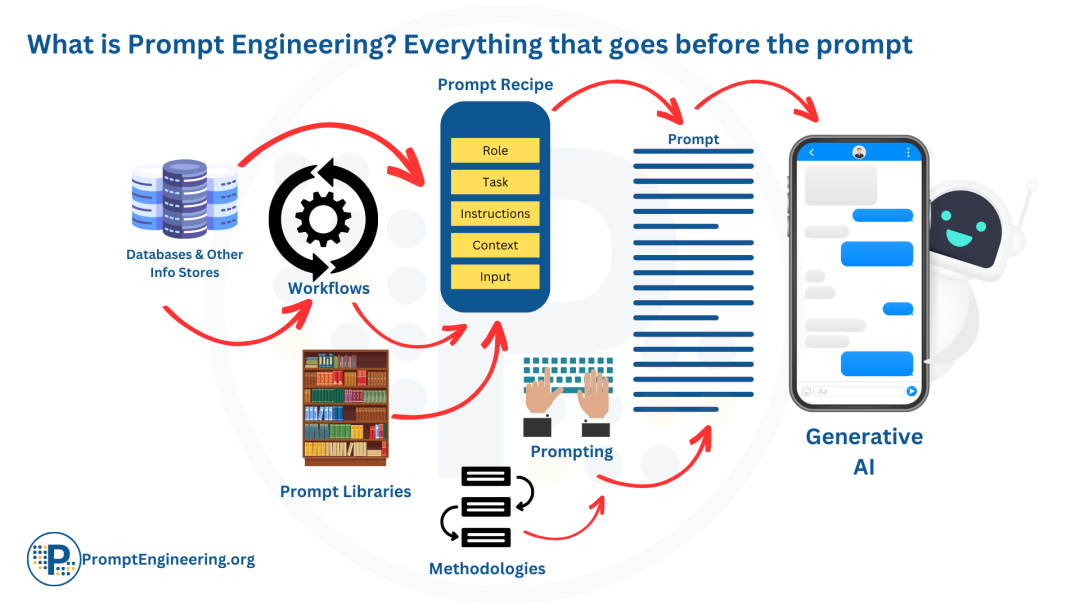
什么是Prompt Engineering**?Prompt Engineering,即提示工程,是指设计和优化输入给大型语言模型(LLM)的文本提示(Prompt)****的过程。**这些提示旨在引导LLM生成符合期望的、高质量的输出。
Prompt Engineering
Prompt Engineering的核心要素在于通过明确的指示、相关的上下文、具体的例子以及准确的输入来精心设计提示,从而引导大语言模型生成符合预期的高质量输出。
Prompt Engineering
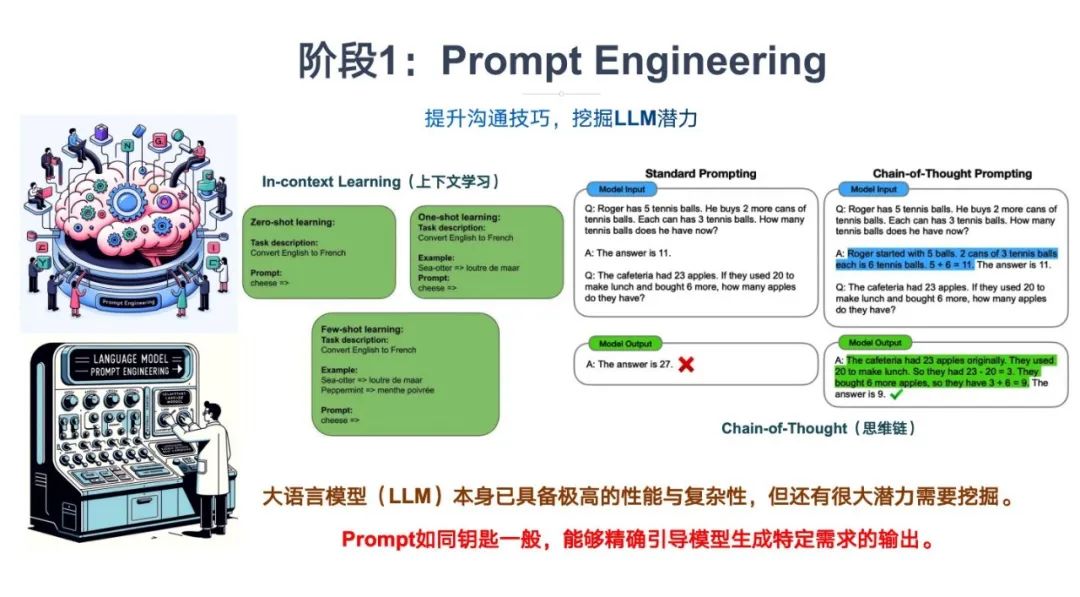
**为什么需要Prompt Engineering?**通过不断优化prompt,我们可以建立更加清晰、有效的沟通渠道,充分发挥LLM在语言理解和生成方面的优势。
****提升沟通技巧,挖掘LLM潜力。******大语言模型(LLM)本身已具备极高的性能与复杂性,但还有很大潜力需要挖掘。**Prompt如同钥匙一般,能够精确引导模型生成特定需求的输出。
Prompt Engineering
一文彻底搞懂大模型 - Prompt Engineering(提示工程)
阶段二:AI Agent
**什么是AI Agent?******大模型Agent是一种构建于大型语言模型(LLM)之上的智能体,它具备环境感知能力、自主理解、决策制定及执行行动的能力。
****
****AI Agent
Agent是能够模拟独立思考过程,灵活调用各类工具,逐步达成预设目标。在技术架构上,Agent从面向过程的架构转变为面向目标的架构,旨在通过感知、思考与行动的紧密结合,完成复杂任务。
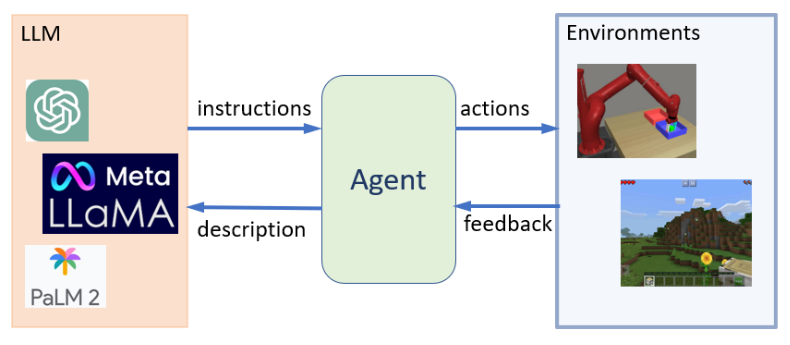
AI Agent
****Agent关键技术-LLM:****在Agent技术中,大语言模型(LLM)作为核心计算引擎,不仅限于文本生成,还能够进行对话、完成任务、推理,并展示一定程度的自主行为。
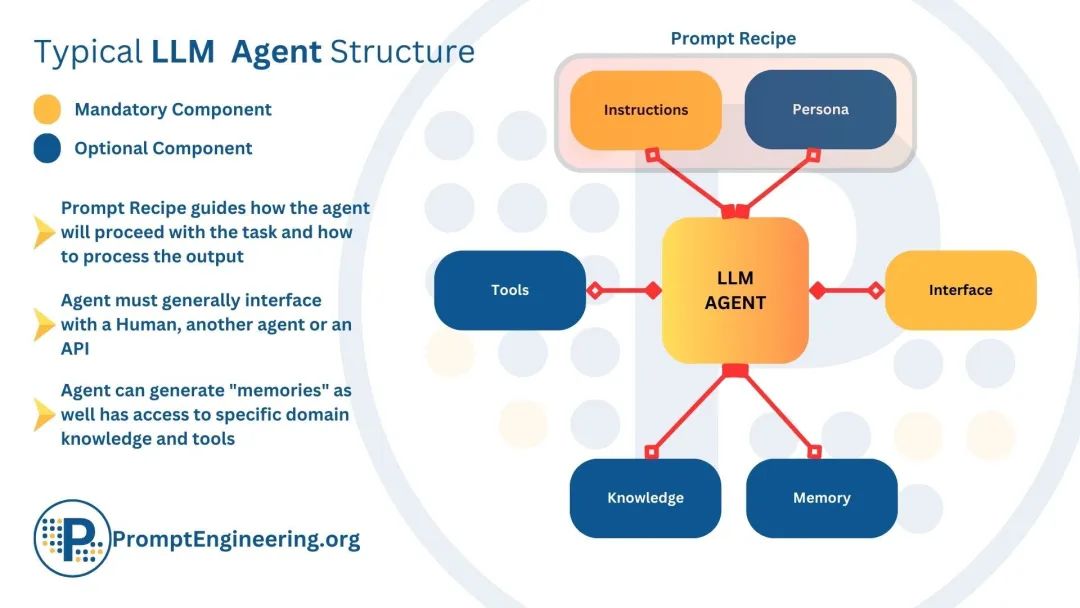
LLM
**Agent关键技术-Function Calling:**********Function Calling在智能助手和自动化流程中的应用场景中,************LLM通过调用外部API或预设函数来集成多样化服务与复杂操作,以满足用户请求并自动化执行流程。
Function Calling
-
在构建智能助手时,LLM可能需要根据用户的请求调用外部服务(如天气查询API、数据库查询等),并将结果整合到其响应中。
-
在自动化流程中,LLM可以通过调用预设的函数来执行一系列复杂的操作,如数据处理、文件生成等。
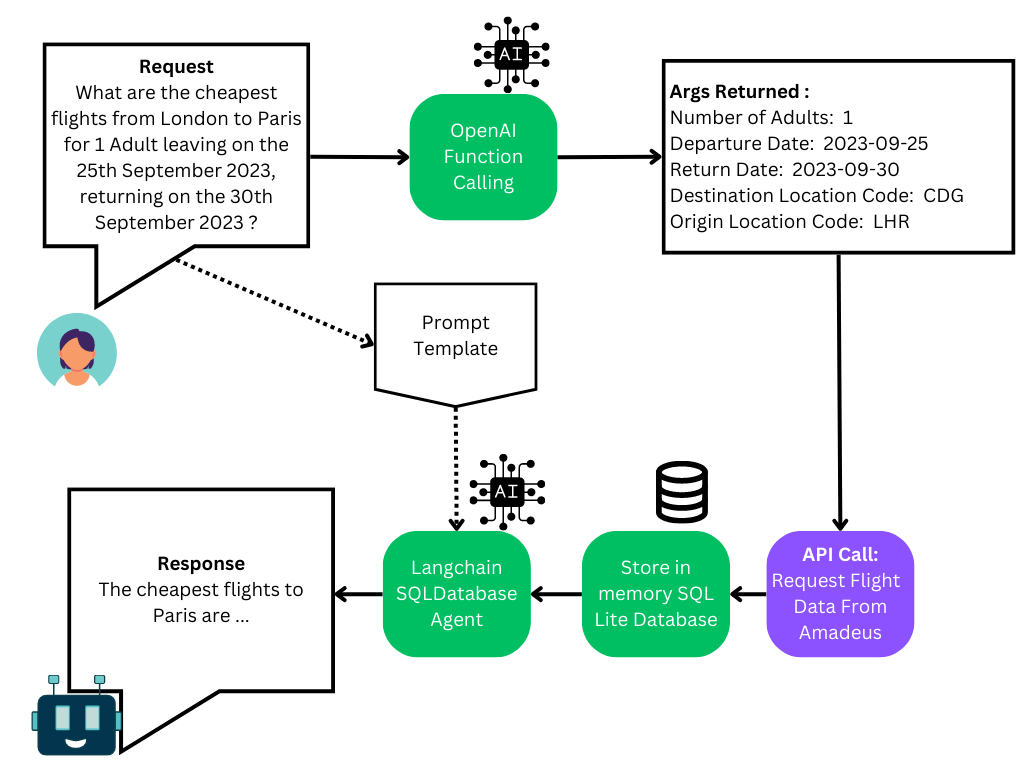
Function Calling
****Agent关键技术-RAG:通过引入RAG,LLM Agent能够在需要时查询外部知识库,如专业数据库、学术论文、行业报告等,从而增强其知识广度和深度。

RAG
为什么需要AI Agent?AI Agent作为LLM能力的整合者与定制化服务提供者,通过NLP和HCI技术增强交互体验,使用户能够轻松享受LLM带来的智能服务。
-
整合LLM能力:AI Agent作为平台,能够无缝整合LLM的文本生成、理解、推理等能力。通过Agent,用户可以直接与LLM进行交互,而无需深入了解LLM的复杂性和技术细节。
-
定制化服务:AI Agent可以根据不同用户的需求和场景,定制化地利用LLM的能力。例如,在客户服务领域,Agent可以根据用户的查询和问题,利用LLM生成准确的回答和解决方案;在个性化推荐系统中,Agent可以分析用户的偏好和行为,利用LLM生成定制化的推荐内容。
-
增强交互体验:AI Agent通过自然语言处理(NLP)和人机交互(HCI)技术,能够提供更自然、流畅的交互体验。用户可以通过自然语言与Agent进行对话,而Agent则能够理解和回应用户的意图和需求,从而增强用户的满意度和忠诚度。

AI Agent
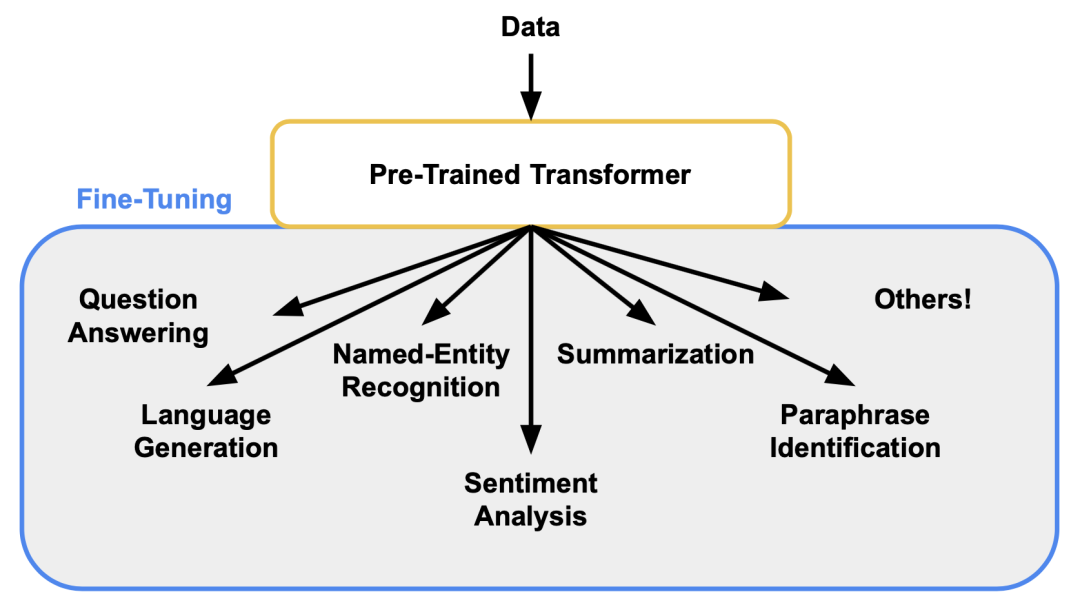
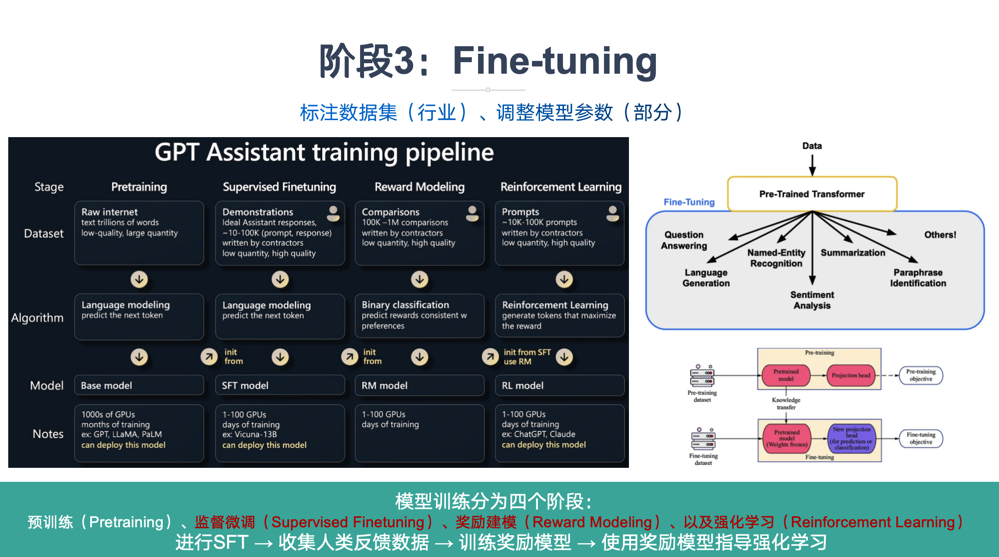
阶段三:Fine-tuning
****什么是Fine-tuning?****Fine-Tuning是指使用特定领域的数据集对预训练的大型语言模型进行进一步训练的过程。通过微调,模型可以学习到特定领域的知识和模式,从而在相关任务上表现更好。
在预训练模型的基础上,针对特定任务或数据领域,通过在新任务的小规模标注数据集上进一步训练和调整模型的部分或全部参数,使模型能够更好地适应新任务,提高在新任务上的性能。
Fine-tuning
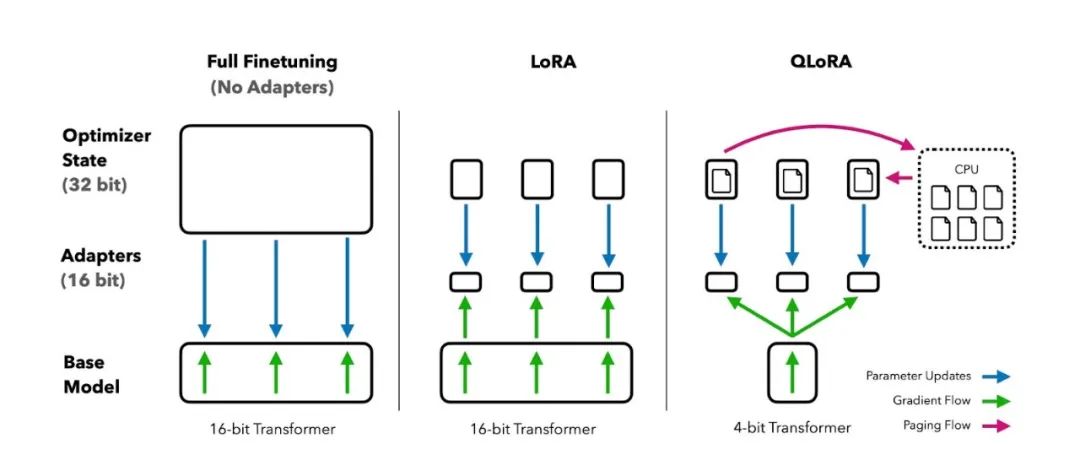
****为什么需要Fine-tuning?****尽管预训练模型已经在大规模数据集上学到了丰富的通用特征和先验知识,但这些特征和知识可能并不完全适用于特定的目标任务。
Fine-tuning
微调通过在新任务的少量标注数据上进一步训练预训练模型,使模型能够学习到与目标任务相关的特定特征和规律,从而更好地适应新任务。
Fine-tuning
一文彻底搞懂Fine-tuning - 预训练和微调(Pre-training vs Fine-tuning)
阶段四:Pre-training
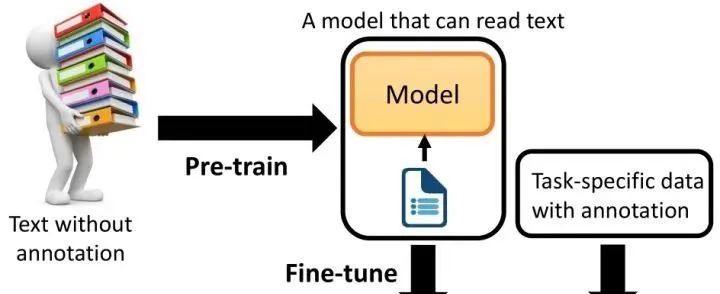
****什么是Pre-training?********预训练是语言模型学习的初始阶段。********在预训练期间,模型会接触大量未标记的文本数据,例如书籍、文章和网站。****目标是捕获文本语料库中存在的底层模式、结构和语义知识。
Pre-training
预训练利用大量无标签或弱标签的数据,通过某种算法模型进行训练,得到一个初步具备通用知识或能力的模型。********
-
****无监督学习:****预训练通常是一个无监督学习过程,模型在没有明确指导或标签的情况下从未标记的文本数据中学习。
-
******屏蔽语言建模:******模型经过训练可以预测句子中缺失或屏蔽的单词、学习上下文关系并捕获语言模式。
-
******Transformer 架构:******预训练通常采用基于 Transformer 的架构,该架构擅长捕获远程依赖关系和上下文信息。
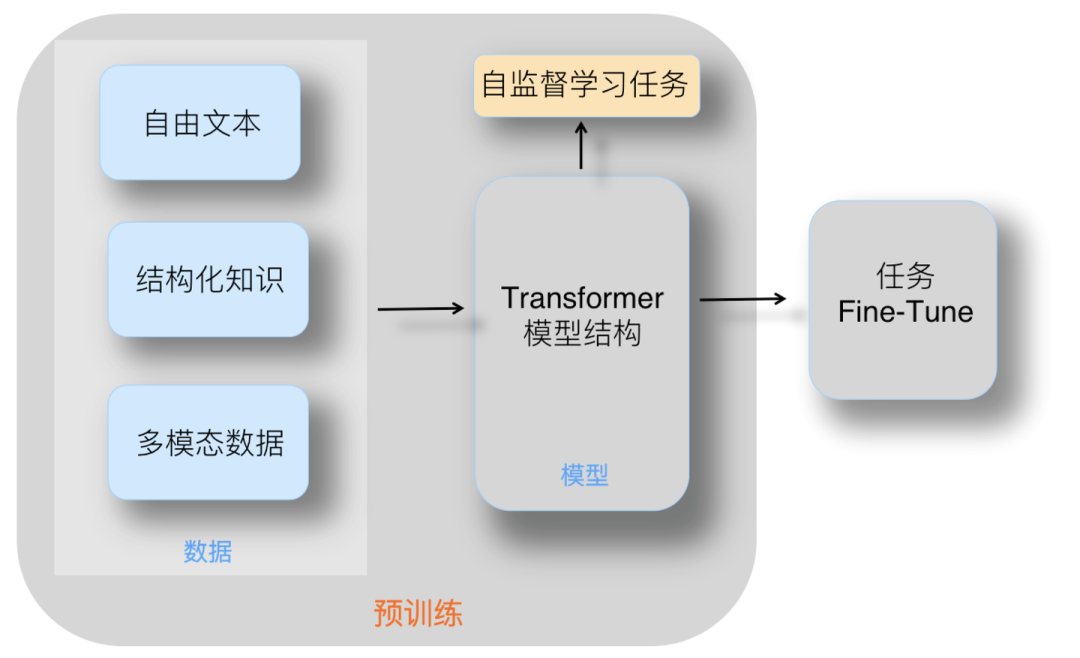
Pre-training
**为什么需要Pre-training :******预训练是为了让模型在见到特定任务数据之前,先通过学习大量通用数据来捕获广泛有用的特征,从而提升模型在目标任务上的表现和泛化能力。
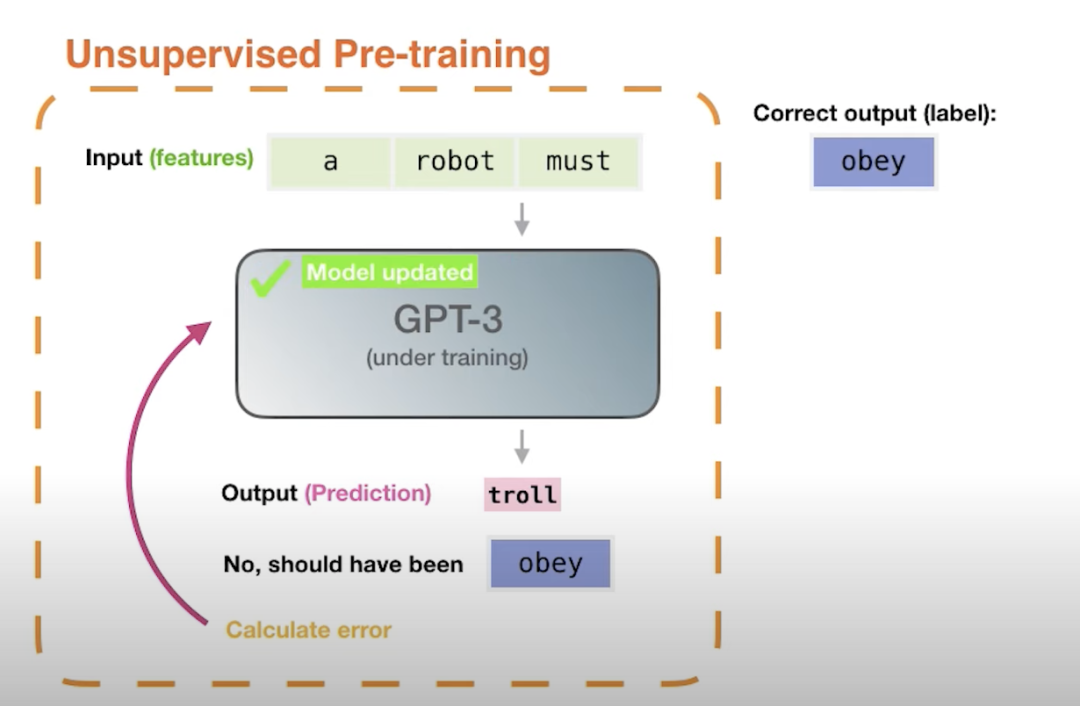
Pre-training
预训练技术通过从大规模未标记数据中学习通用特征和先验知识,减少对标记数据的依赖,加速并优化在有限数据集上的模型训练。

Pre-training
一文彻底搞懂Fine-tuning - 预训练和微调(Pre-training vs Fine-tuning)















 970
970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









