







多模态理解是大模型理解复杂现实世界的关键能力之一,早在去年10月,微软就发表了一篇166页论文,阐述多模态不断进化下,大模型迎来黎明:“GPT-4V 在处理任意交错的多模态信息方面具有前所未有的能力,是当今最强大的多模态通用人工智能系统。”
如今,大半年过去了,在被称为“大模型落地元年”、“技术井喷年”的2024年,多模态领域又完成了哪些进化?在哪些方面取得了重要突破?哪些玩家又将领跑下一轮多模态角逐?
这些让人好奇已久的行业问题,如今,迎来了“答案揭晓时刻”。2024年8月2日,中文多模态大模型SuperCLUE-V基准8月榜单发布。据介绍,本次测评涵盖国内外最具代表性的12个多模态理解大模型,考察面包括基础能力和应用能力两个方向,以开放式问题形式对多模态大模型进行评估。
而随着这场多模态竞技发榜,行业也得以管窥当下大模型选手的多模态实力:
其中,GPT-4o以74.36分摘金,领跑多模态基准,基础多模态认知能力和应用能力均有70+分的表现;而国内多模态大模型腾讯混元(hunyuan-vision)和InternVL2-40B分别摘取银牌、铜牌,取得70+分的成绩,仅次于GPT-4o。
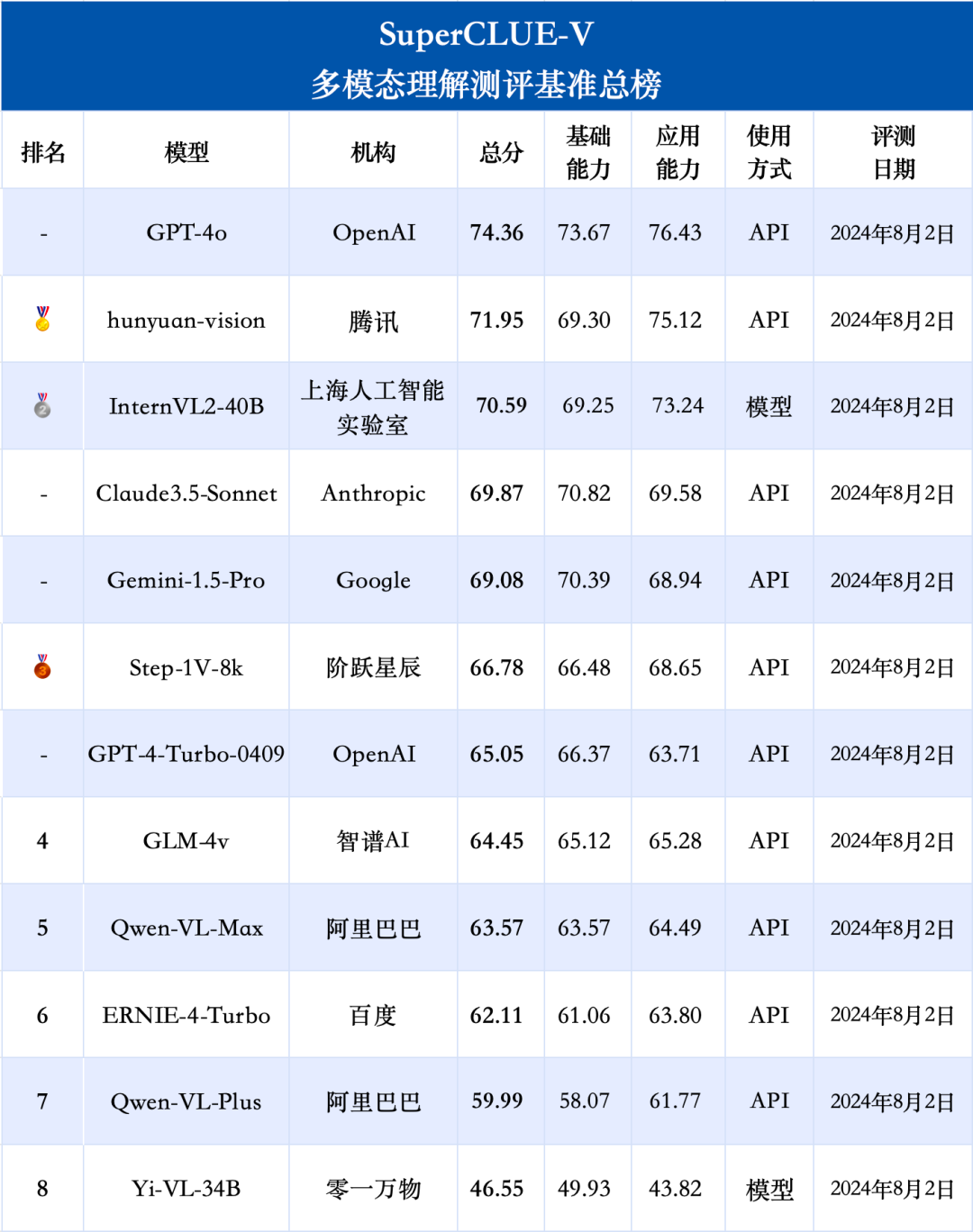
值得一提的是,得益于对中文语境的深刻理解,以及在通用、常识、图像等多领域的综合能力,我国大模型在应用方面领先Claude3.5-Sonnet和Gemini-1.5-Pro,展现出较强的应用优势。
众所周知,在大模型大考中,多模态往往是压轴题的存在——不仅要求大模型能够精准地识别图像中的每一个元素,更要深刻理解这些元素之间的关系,进而生成准确、生动的自然语言描述,对应到底层能力,则要求其具备强大的特征提取与表征能力、复杂的注意力机制与全局建模能力、知识迁移与泛化能力等等。

那么,具体而言,大模型想要在多模态方面表现出彩,需要具备哪些基础能力、知识储备,又需要hold住哪些应用场景?展望未来,多模态在生产、生活中又有哪些落地空间?
德智体美全面发展:玩转多模态不容易!
多模态理解俗称“图生文”,要求模型能准确识别图像元素,理解它们的关系,并生成自然语言描述,这就分“输入-理解并分析-输出”三步走。第一步,就是“听指令、看图”的输入环节:这需要大模型全面理解场景关系、深度洞察细节,和现实世界的复杂性“同频共振”,才能不“已读乱回”。
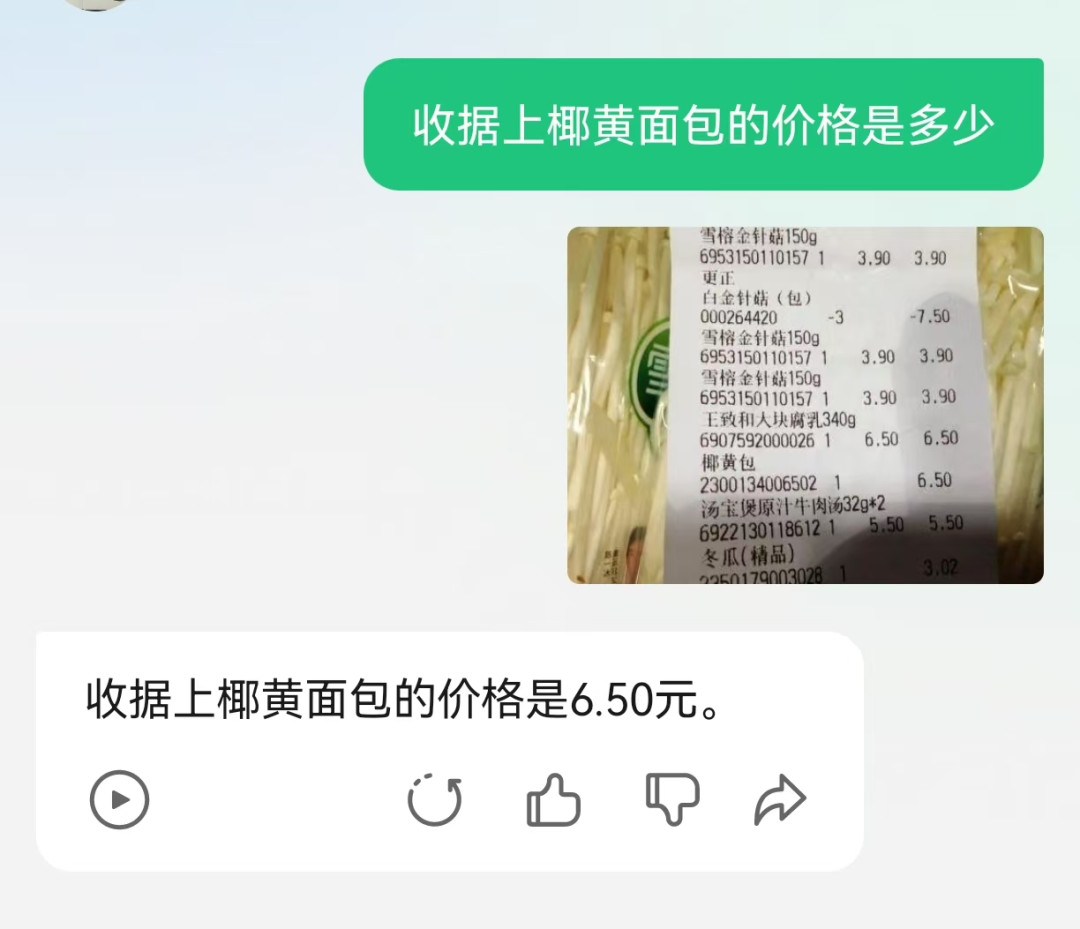
首先,大模型得“听得懂人话”,以腾讯元宝为例,问元宝“收据上椰黄包的价格是多少”,大模型得准确理解“椰黄包”“价格”等关键词,并迅速找到图片中匹配的信息。
再比如,问元宝“图片中有哪些植物,分别有几个”,要求其充分理解图片上的“荷花”“莲蓬”等细节。

而上难度后,问元宝“图片中最突出的位置是什么植物”,就要求其不仅能“识百草”,还需要准确理解“突出位置”这一意图。

事实上,对应到底层能力上,想回答这些问题,大模型要具备出色的视觉提取能力,即通过视觉编码器将图像中的信息转化为模型可理解的视觉特征,包括颜色、形状、纹理等基本信息,并能够捕捉到图像中的关键区域。
尤其是在难度升级的细粒度视觉认知方面,要求模型能够区分同一类别中的不同个体或细微差别。比如,在考察细粒度视觉认知的对象计数环节,问大模型“图上有多少立方体”?元宝也给出了准确的回答和“解题过程”。

不止如此,在识别出图像中的立方体后,大模型需要具备一定的推理能力,结合空间位置关系以及立方体的形状和大小等因素,进行综合判断,最终得出结论。
随后,重头戏来了:理解过程中,需要大模型拥有丰富的知识储备,既要理解中华文化传统知识,又要掌握当下生活常识,还不能纯“书呆子”,得玩得了互联网热梗、看得懂meme。
比如,发一张中国元素建筑图片,问“图片中的是什么”——这不仅考验大模型图像识别的精确度、对场景的理解力、对细节的洞察力,更考验模型在中文语境的积淀深度。
尤其是在中文特色文化知识理解维度,要求其不仅得理解“脊兽”等建筑符号,还要分得清材质、颜色、工艺细节、建筑背景,并具有相应的文化底蕴,能条条是道地分析,讲一讲龙象征着权力和吉祥,凤象征着和平和繁荣,狮子象征着威严、守护宫殿和庙宇,而不至于“奈何大模型没文化,一句好美行天下”。

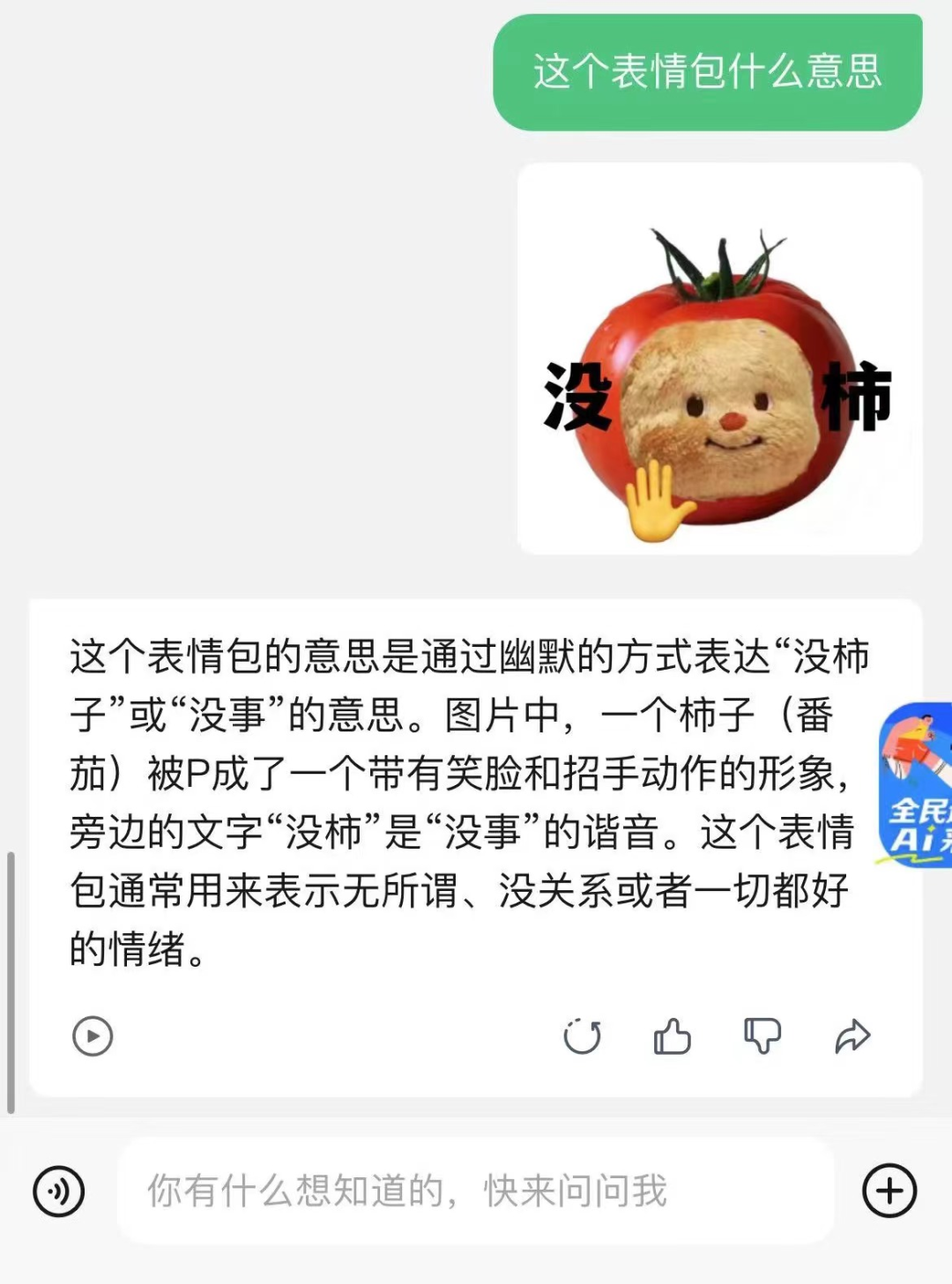
当然,好看的logo千篇一律,有趣的灵魂万里挑一,对这届大模型来说,还得有大量互联网场域积淀,玩得了谐音梗,看得懂“没柿”这样兼具无厘头和阴阳怪气、有“淡淡疯感”的表情包:
而理科方面,则要无缝切换“理工男模式”,看得懂图表,比如,在数理逻辑分析、图表推理环节,问其“广州在2015年的人口是多少”,元宝也能对答如流。

同时,逻辑推理能力也要到位,比如,让元宝描述一下图片中的内容,并分析图片之间的关联,其不仅基于体育知识储备,详细描述出了运动员跳水动作的姿态,还分析出“三张图片展示了跳水动作的连贯过程,从起跳、空中姿态到入水,体现了运动员的技术和力量”的相关性。

这背后是大模型的逻辑推理做底层支撑:在模态对齐的基础上,迅速根据内容上的相似性(如相似的物体、场景或主题)、逻辑上的连续性(如时间序列中的连续帧)或情感上的共鸣(如相似的氛围或情感表达),识别出多张图片之间的潜在关联,并在输出维度进成流畅、全面的语言描述。
而在应用层面,“AI挑瓜”等名场面,大模型也得hold住,不能乱挑,得有理有据:元宝仔细分析了外观颜色、条纹清晰度、表皮光滑程度等,给出了“7号西瓜最好吃”的建议。

而这背后,除了考察大模型外观特征识别、细节捕捉能力外,还考验了大模型的“聪明程度”,也就是知识应用及迁移能力:其需要利用互联网上的语料和已有的知识库,将西瓜的外观信息与味道、甜度等属性联系起来。例如,通过识别西瓜的色泽和纹理,推断出其可能的甜度和口感。
这也让行业再次看到了多模态在应用场域的巨大潜力,以及不断打开的想象空间。那么,在生产生活领域,“聪明的大模型”能打开哪些想象空间呢?
“聪明的大模型”:
有望在生产、生活应用场景加速落地
事实上,多模态能力大规模应用后,对生产生活改变将不容小觑。
生活端,除了挑西瓜外,大模型的多模态能力还有望在电商等场景加速落地,给出用户服装搭配建议,即用户拍摄自己的照片或上传衣物图片,大模型根据用户的体型、肤色、风格等信息,结合衣物图片的特征,生成搭配建议的文本描述,帮助用户打造个性化的穿搭。
比如,剁手时两件都想要、选择困难症?上传两件衣服的图片,元宝根据“胳膊粗”的描述,选择了左边能遮肉的泡泡袖,不仅让买家避免了钱包受罪,还有望提升买家满意度、降低退货率,利好商家。

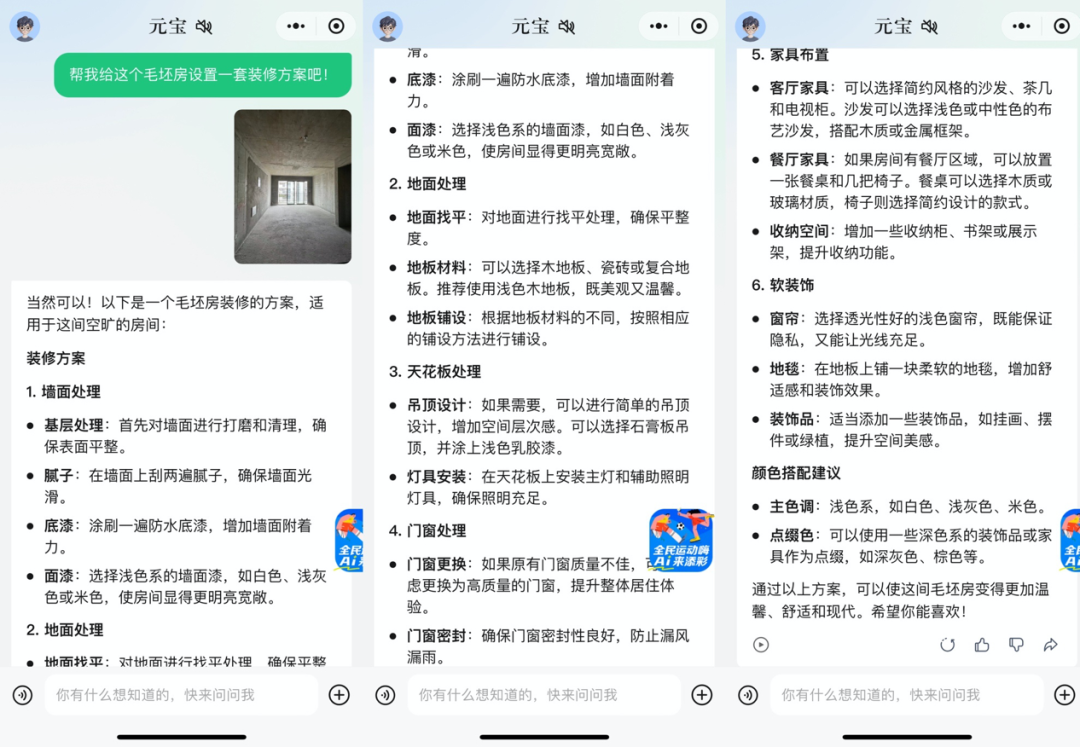
而在家居领域,刚买的毛坯房不知道如何精准?可以听听元宝的建议,看看能不能“爆改精装”。
展望未来,智能家居时代,图生文能力的落地,还有望让用户通过拍摄家中设备图片,并结合语音指令或文本输入,实现对设备的远程控制。
生产端,大模型则可以帮助打工人读财报、解析报表,比如,投喂元宝一张某公司2023年的财报,它能从营收、利润、经营前景等方面分析得条条是道,成为打工人的小助手:
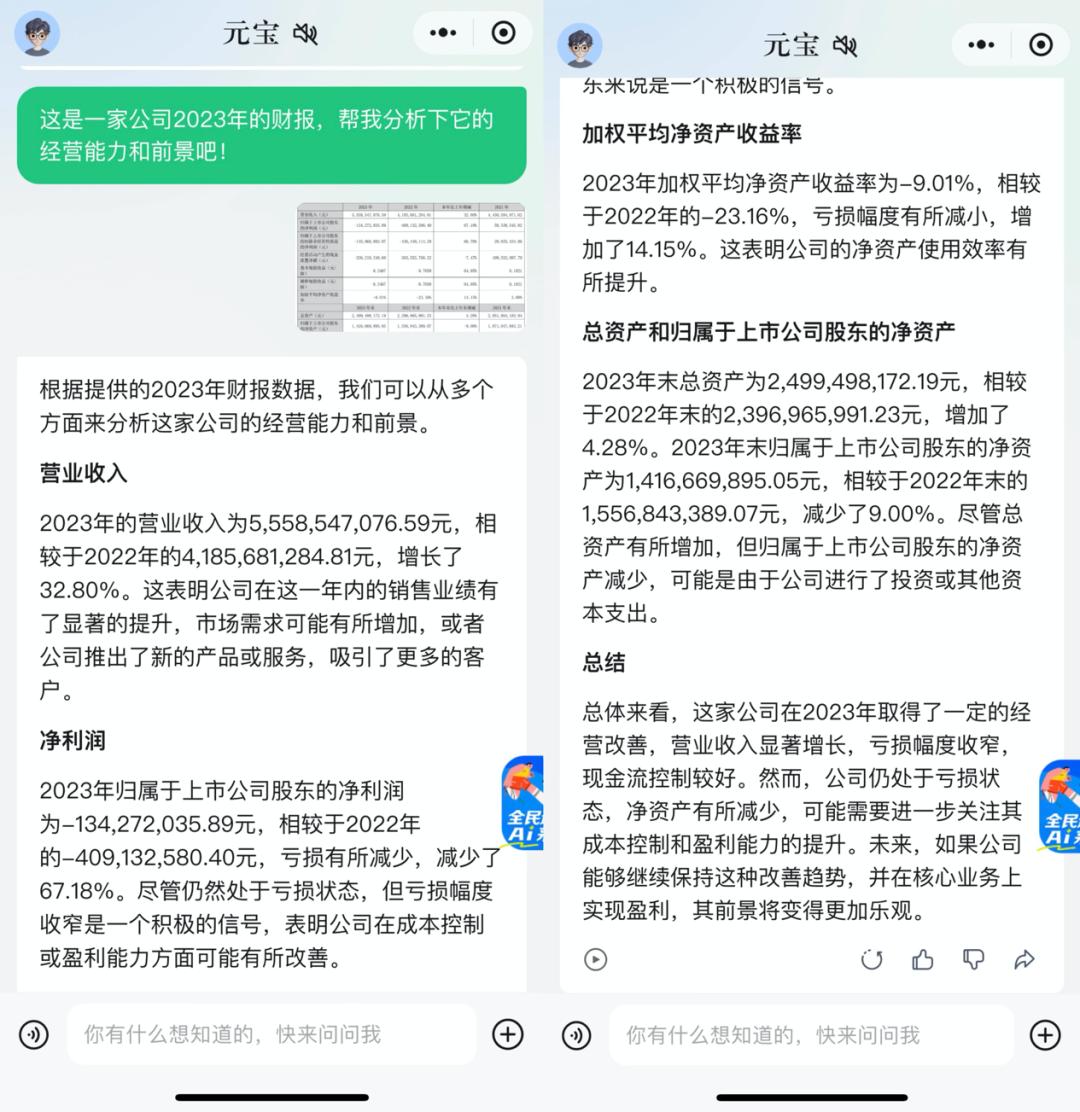
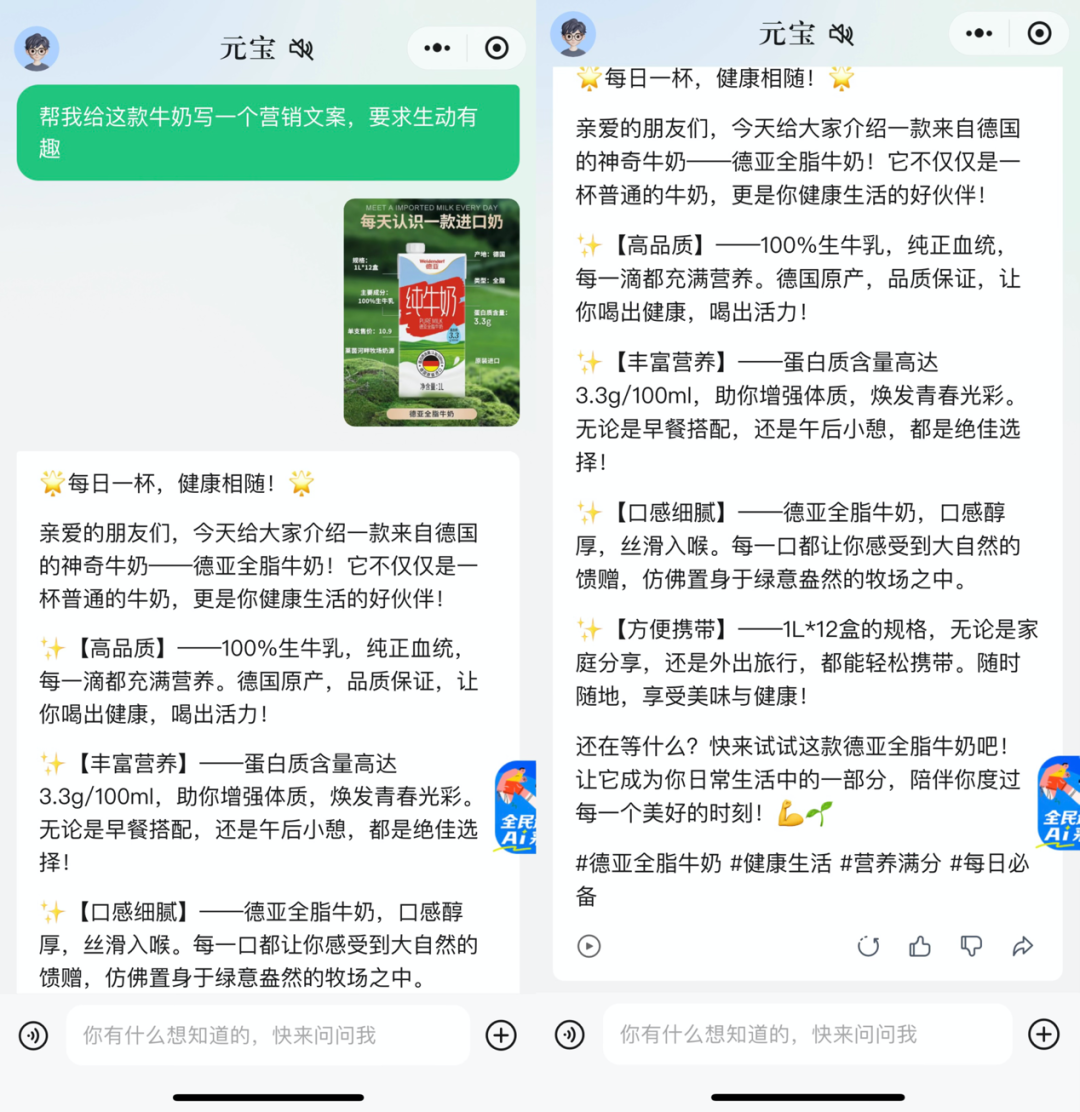
再比如,发给元宝一张产品图,让其根据产品图片生成创意文案或广告口号,随机拯救一个抓耳挠腮的秃头文案人。
而在产业端,多模态的应用前景也得到了多方认可,机构人士认为,多模态大模型将成为生成式AI的重点发展方向,拥有更大的应用想象力。
东吴证券表示,多模态是AI商业宏图的起点,有望真正为企业降本增效;长城证券认为,多模态能力的突破有助于拓展AI应用场景,传媒行业中游戏、影视、广告营销、数字媒体等板块均有望受益于AI多模态能力的提升;中信证券更是点出,多模态大模型算法的突破将带来自动驾驶、机器人等技术的革命性进步,对科技产业产生长周期影响和改变。
诚如所言,在未来,多模态将在传媒、医疗、教育、办公场景、剧本创作、自动驾驶等领域加速落地 。如在健康医疗领域,有望让患者上传皮肤照片,一键get自身皮肤状况(如痘痘、色斑、皱纹等),生成关于皮肤问题的文本描述和改善建议。

而随着多模态在医疗影像领域纷纷开花,大模型更有可能精准分析CT、MRI等医疗影像图片,生成关于病灶位置、大小、形态等信息的文本描述,为医生提供辅助诊断支持。
而在当下炙手可热的智慧城市等赛道,视觉大模型有希望在城市治理和电力行业加速应用,辅助可视化管理和高效运营管理。如今,得益于其丰富的互联网应用场景,我国多模态大模型发展迅速,并有望掀起新一轮应用落地场景革命,完成从“黎明”到“朝霞满天”的飞跃。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









