






数据来源:kaggle
编译器:pycharm
心脏病是一类比较常见的循环系统疾病。它作为全球第一大杀手,是我们不得不提前防御的疾病。利用数据分析找出一些规律,来预防心脏病发生
目录
导入数据
import pandas as pd
data = pd.read_csv('/Users/cengmeili/Documents/简历/项目资料/python数据分析案例,心脏病预测/heart.csv')
print(data.head())
print(data.info())可以看到数据基本情况的统计:
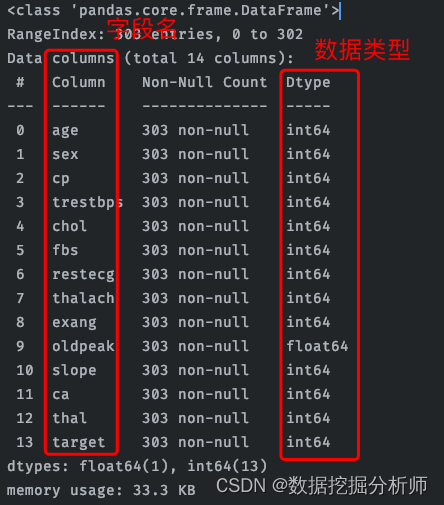
下面对字段进行介绍:
age: 该朋友的年龄
sex: 该朋友的性别 (1 = 男性, 0 = 女性)
cp: 经历过的胸痛类型(值1:典型心绞痛,值2:非典型性心绞痛,值3:非心绞痛,值0:无症状)
trestbps: 该朋友的静息血压(入院时的毫米汞柱)
chol: 该朋友的胆固醇测量值,单位 :mg/dl
fbs: 人的空腹血糖(> 120 mg/dl,1=真;0=假)
restecg: 静息心电图测量(0=正常,1=患有ST-T波异常,2=根据Estes的标准显示可能或确定的左心室肥大)
thalach: 这朋友达到的最大心率
exang: 运动引起的心绞痛(1=有过;0=没有)
oldpeak: ST抑制,由运动引起的相对于休息引起的
slope: 最高运动ST段的斜率(值0:上坡,值1:平坦,值2:下坡)
ca: 萤光显色的主要血管数目(0-4)
thal: 一种称为地中海贫血的血液疾病(1=正常;2=固定缺陷;3=可逆缺陷)
target: 心脏病(0=否,1=是)
对数据进行统计:
print(data.describe())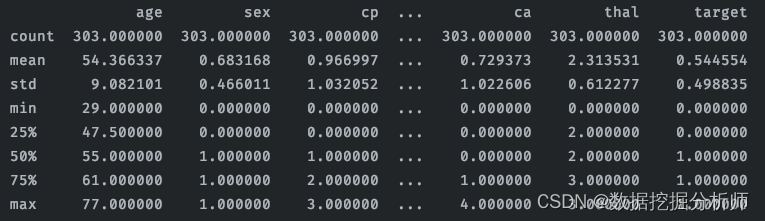
数据初步分析
countNoDisease = len(data[data.target == 0])
countHaveDisease = len(data[data.target == 1])
countfemale = len(data[data.sex == 0])
countmale = len(data[data.sex == 1])
print(f'没患病人数:{countNoDisease }',end=' ,')
print("没有得心脏病比率: {:.2f}%".format((countNoDisease / (len(data.target))*100)))
print(f'有患病人数:{countHaveDisease }',end=' ,')
print("患有心脏病比率: {:.2f}%".format((countHaveDisease / (len(data.target))*100)))
print(f'女性人数:{countfemale }',end=' ,')
print("女性比例: {:.2f}%".format((countfemale / (len(data.sex))*100)))
print(f'男性人数:{countmale }',end=' ,')
print("男性比例: {:.2f}%".format((countmale / (len(data.sex))*100)))通过运行可以得到以上结果,为了更加直观体现,采用使用的是matplotlib+seaborn进行可视化。
# 设置中文字体
zhfont1 = matplotlib.font_manager.FontProperties(fname="/Users/cengmeili/PycharmProjects/pythonProject4/配置文件/SourceHanSansSC-Bold.otf")
plt.subplot(1, 2, 1)
a = [138, 165]
explode=(0,0.1)
label1 = ['Not sick','be ill']
plt.pie(a,labels=label1,explode=explode, autopct='%1.1f%%')
plt.title("患病比例",fontproperties=zhfont1)
plt.subplot(1, 2, 2)
b = [207, 96]
explode=(0,0.1)
label2 = ['man','women']
plt.pie(b,labels=label2,explode=explode, autopct='%1.1f%%')
plt.title("男女患病比例",fontproperties=zhfont1)
plt.show()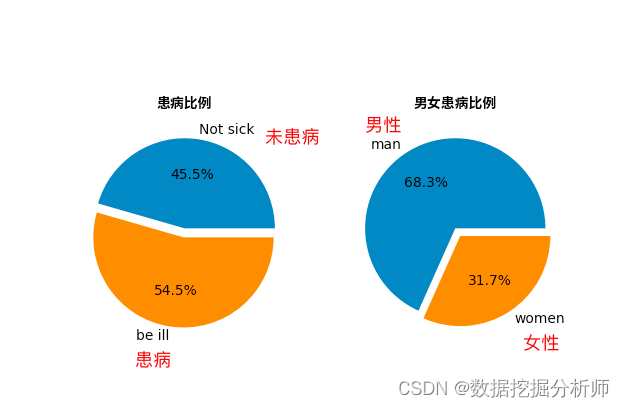
心脏病数据各字段的相关性
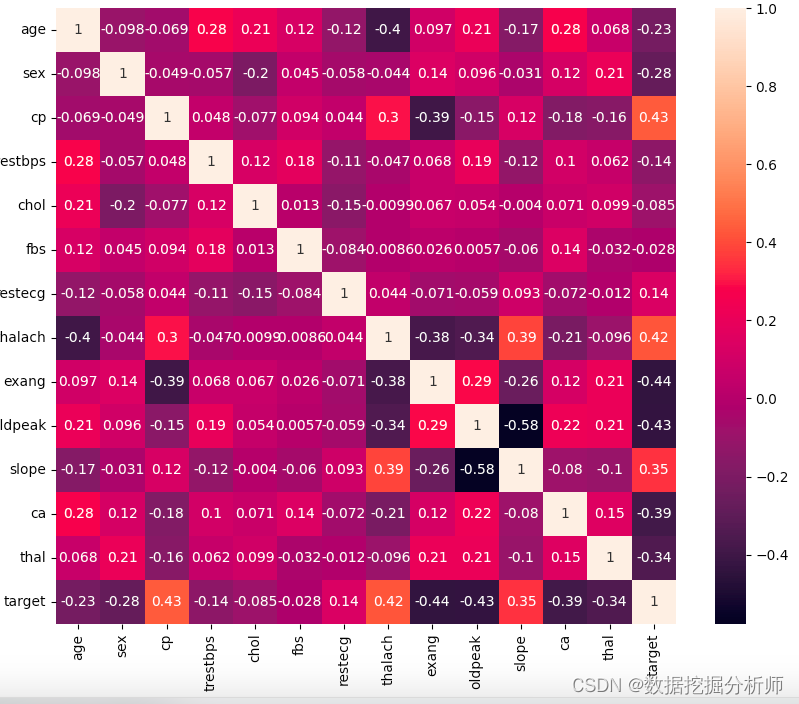
从上面的图形中我们可以发现,slope与oldpeak呈高度负相关(0.58)。这意味着如果坡度值增加,旧峰值将减少,反之亦然。Target与cp(胸痛)呈正相关最高,为0.43,其次是thalach(心率),为0.42,然后是slope(最高运动ST段的斜率),为0.35.
性别和患病的关系
gender_dict = data['sex'].value_counts()
plt.figure(figsize=(8, 6))
plt.pie(gender_dict.values, labels=['man', 'women'], autopct="%0.2f%%", explode=(0, 0.05), \
shadow=False, pctdistance=0.8, \
startangle=90, textprops={'fontsize': 16})
plt.show()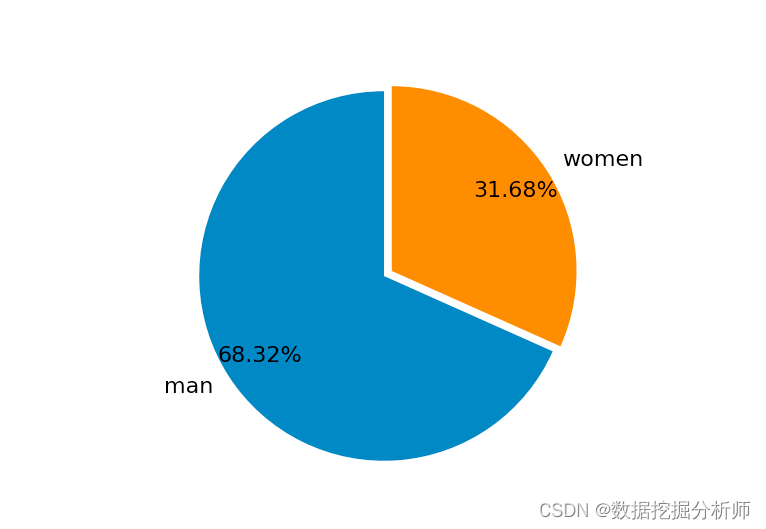
可视化解读:从图中可以看出男性的患病率是大于女性的
患心脏病随年龄分布图
zhfont1 = matplotlib.font_manager.FontProperties(fname="/Users/cengmeili/PycharmProjects/pythonProject4/配置文件/SourceHanSansSC-Bold.otf")
pd.crosstab(data.age, data.target).plot(kind="bar", figsize=(25, 8))
plt.title('患病变化随年龄分布图',fontproperties=zhfont1)
plt.xlabel('岁数',fontproperties=zhfont1)
plt.ylabel('人数',fontproperties=zhfont1)
plt.show()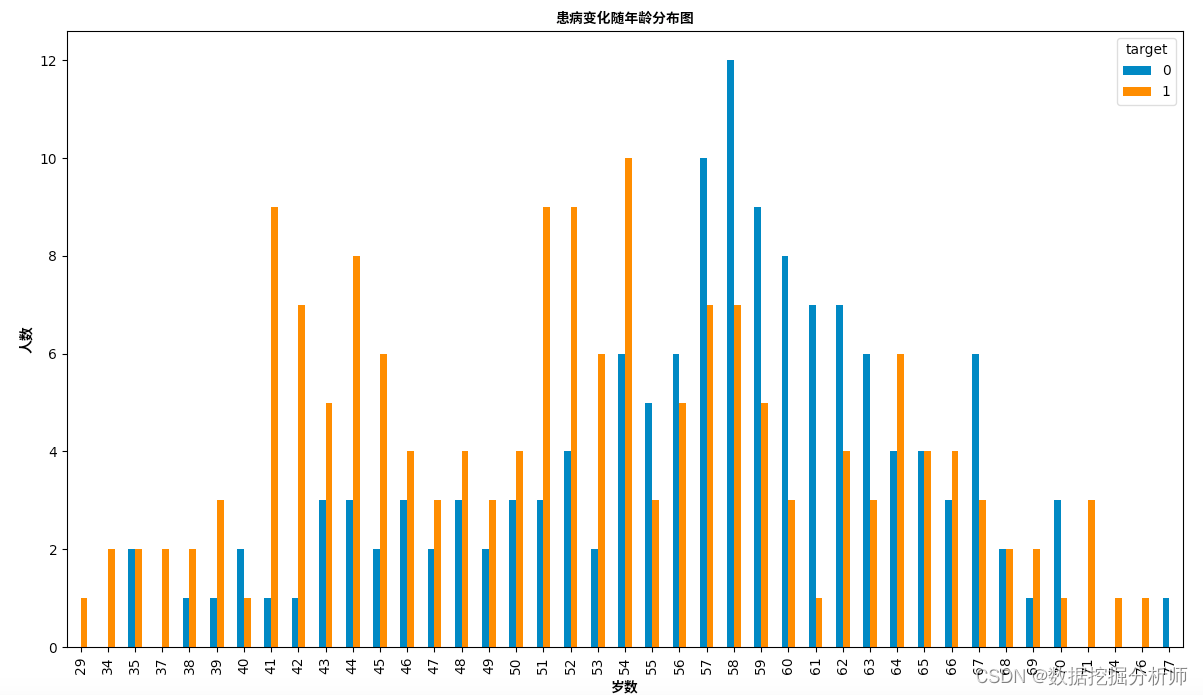
血压-患病关系
# 画个提琴图
sns.violinplot(x=data.target,y=data.trestbps,data=data)
plt.show()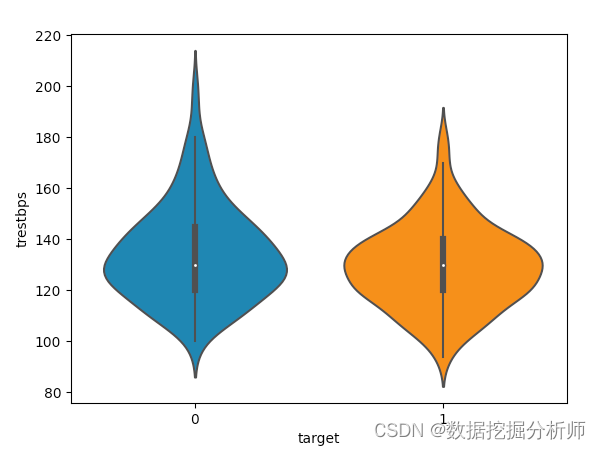
运动引起的心绞痛-心率-患病关系
sns.swarmplot(x='exang', y='thalach', hue='target', data=data, size=6)
plt.xlabel('有无运动引起的心绞痛')
plt.show()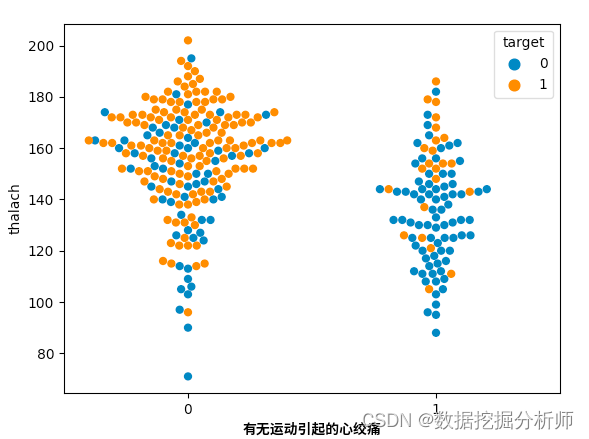
大血管数量ca-年龄age-患病关系
plt.figure(figsize=(15, 8))
sns.swarmplot(x='ca', y='age', hue='target', data=data, size=6)
plt.xlabel('大血管数量',fontproperties=zhfont1)
plt.ylabel('年龄',fontproperties=zhfont1)
plt.show()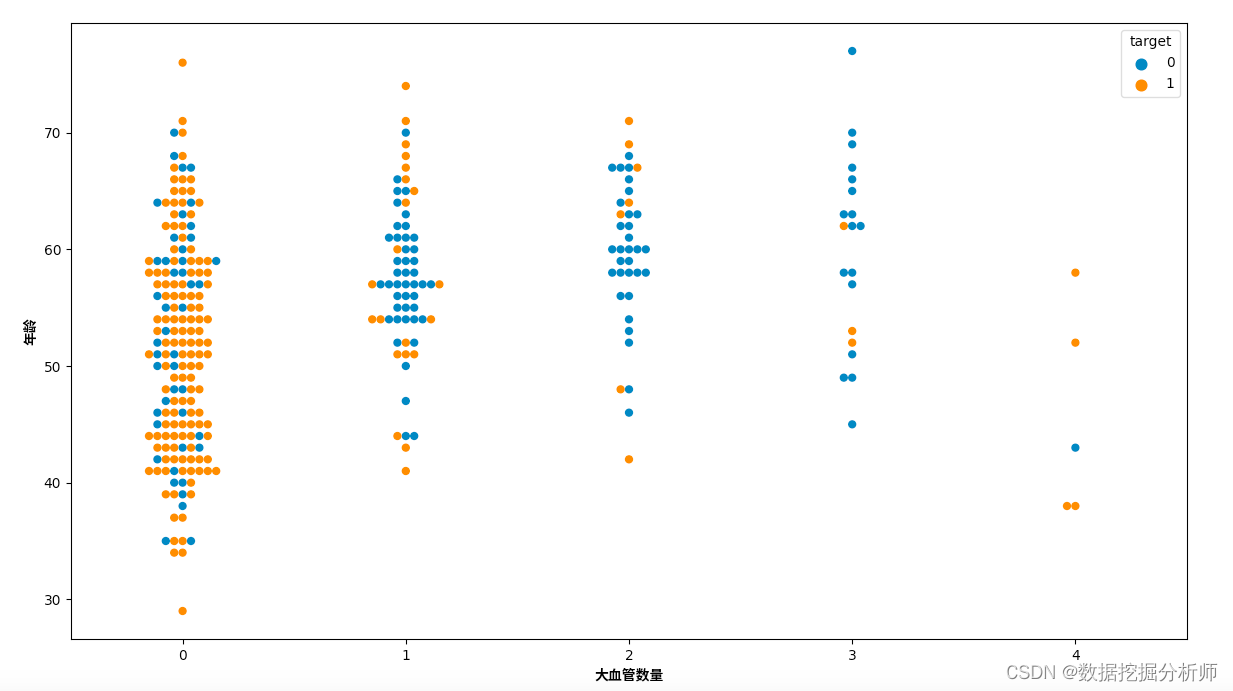
模型预测
数据预处理
#目标值和特征值
x = data.drop(['target'], axis=1)
y = data['target']
#导入库
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
#划分数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=20)
#特征预处理
cc = StandardScaler()
#标准化
x_train = cc.fit_transform(x_train)
x_test = cc.transform(x_test)KNN
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=2)
knn.fit(x_train, y_train)
y_pred2 = knn.predict(x_test)
#计算准确率
score2 = knn.score(x_test, y_test)
print("准确率为:", score2)
#查看精确率、召回率、F1-score
report2 = classification_report(y_test, y_pred2, labels=[0,1], target_names=['Not sick','sick'])
print(report2)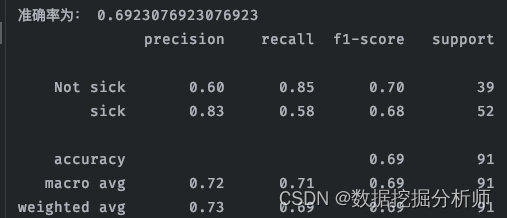
朴素贝叶斯
from sklearn.naive_bayes import GaussianNB
bayesmodel = GaussianNB()
bayesmodel.fit(x_train, y_train)
y_pred3 = bayesmodel.predict(x_test)
# 计算准确率
score3 = bayesmodel.score(x_test, y_test)
print("准确率为:\n", score3)
#查看精确率、召回率、F1-score
report3 = classification_report(y_test, y_pred3, labels=[0,1], target_names=['Not sick','sick'])
print(report3)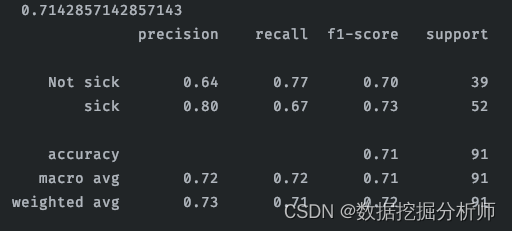
决策树
#导入相关库
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report
classifier = DecisionTreeClassifier(criterion="gini") #CART算法
classifier.fit(x_train,y_train.ravel())
y_pred1 = classifier.predict(x_test)
# 计算准确率
score1 = classifier.score(x_test, y_test)
print("准确率为:\n", score1)
#查看精确率、召回率、F1-score
report1 = classification_report(y_test, y_pred1, labels=[0,1], target_names=['Not sick','sick'])
print(report1)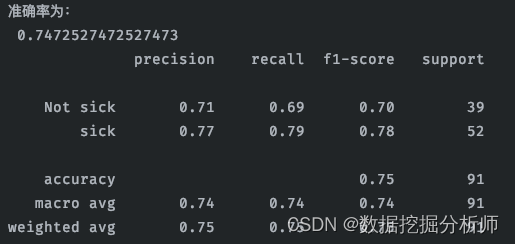
随机森林
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier(n_estimators=200)
rfc.fit(x_train, y_train)
y_pred4 = rfc.predict(x_test)
# 计算准确率
score4 = rfc.score(x_test, y_test)
print("准确率为:\n", score4)
#查看精确率、召回率、F1-score
report4 = classification_report(y_test, y_pred4, labels=[0,1], target_names=['Not sick','sick'])
print(report4)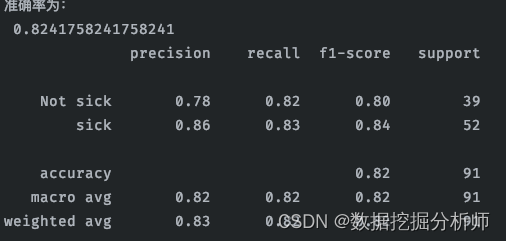
模型评估
model = ['决策树','knn','朴素贝叶斯','随机森林']
score = [score1, score2, score3, score4]
plt.figure(figsize = (15, 10))
sns.barplot(x = score, y = model)
plt.show()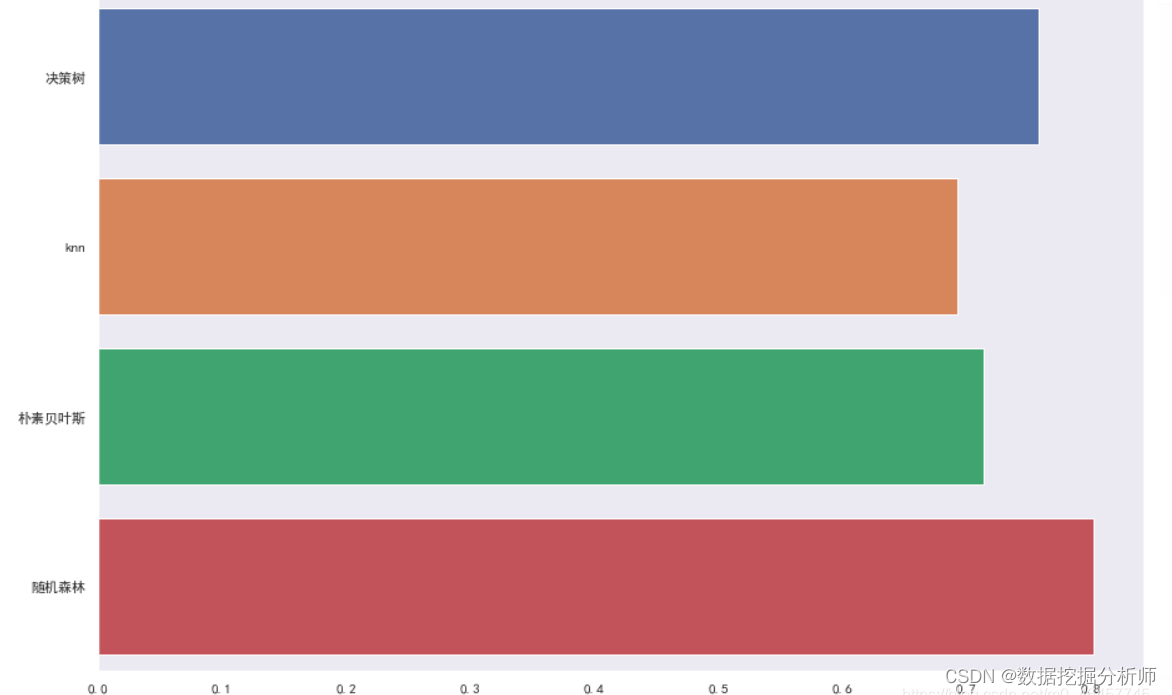
以上就是我做的一些数据分析,由于数据集量比较少,所以不能根据以上分析就一概而论 。需要大量数据进行训练才更加具有代表性。从图上大致初步判断随机森林准确率相对较高。


















 209
209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









