







一、背景调查
1.1 API接口介绍
采集youtube数据,大体分为两种方案:一种是基于爬虫,一种是基于API接口。
说人话就是:爬虫相当于走后门、爬窗户(利用技术手段窃取,人家没说给,但我硬拿),API接口相当于走正门(人家同意给了,咱也正大光明的拿,但是要按照人家的要求拿,也就是接口规范)
基于爬虫的案例,我之前分享过几个:
下面介绍的是基于API接口的采集方案。
YouTube Data API v3是YouTube提供的一种API接口,允许开发人员访问和与YouTube的数据进行交互,包括视频、频道、播放列表和评论等内容。通过该API,开发人员可以检索和管理YouTube的内容,进行搜索操作以及访问用户数据。
API v3使用RESTful HTTP请求与YouTube的服务器进行通信,并返回JSON格式的响应。它是构建与YouTube平台集成并利用其大量数据的应用程序的强大工具。
youtube于2006年被Google公司高价收购,以下教程是Google开发者链接就顺理成章了。
废话不多说了,进入正题!!!

添加图片注释,不超过 140 字(可选)
二、申请接口权限
帮助文档:https://developers.google.com/youtube/v3/getting-started?hl=zh-cn
2.1、注册Google账号
首先,要注册一个自己的Google账号,这一步有手就行,就不多说了哈。
2.2、创建项目
打开Google开发者控制台:https://console.cloud.google.com/projectselector2/apis/dashboard?hl=zh-cn&supportedpurview=project,如下: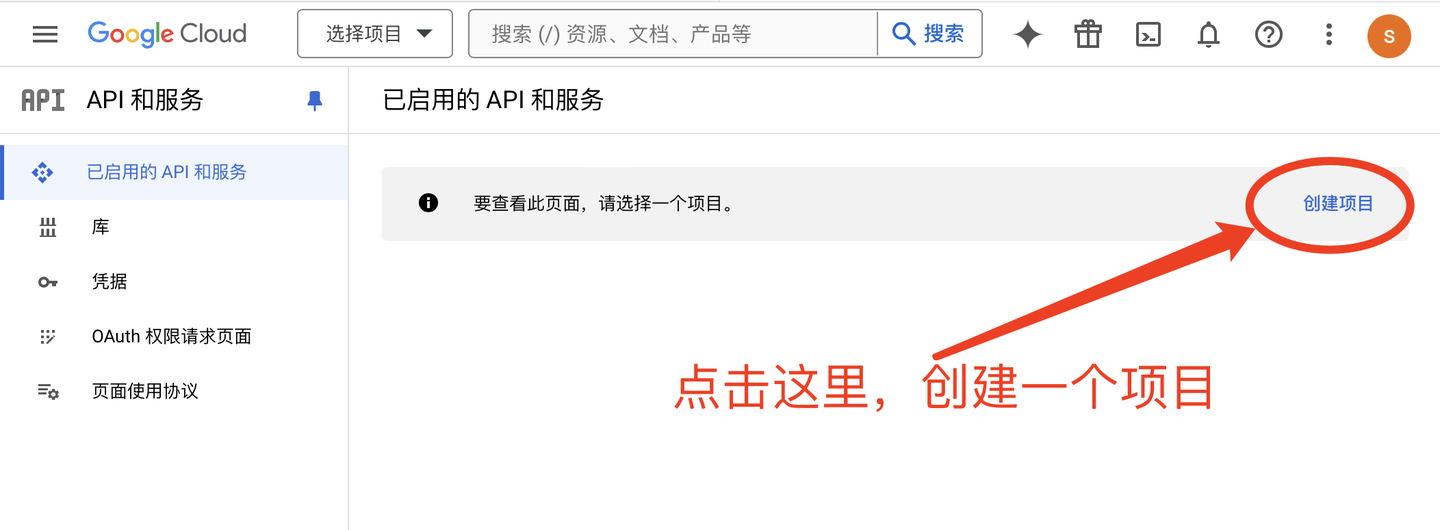
进入创建项目界面,开始创建: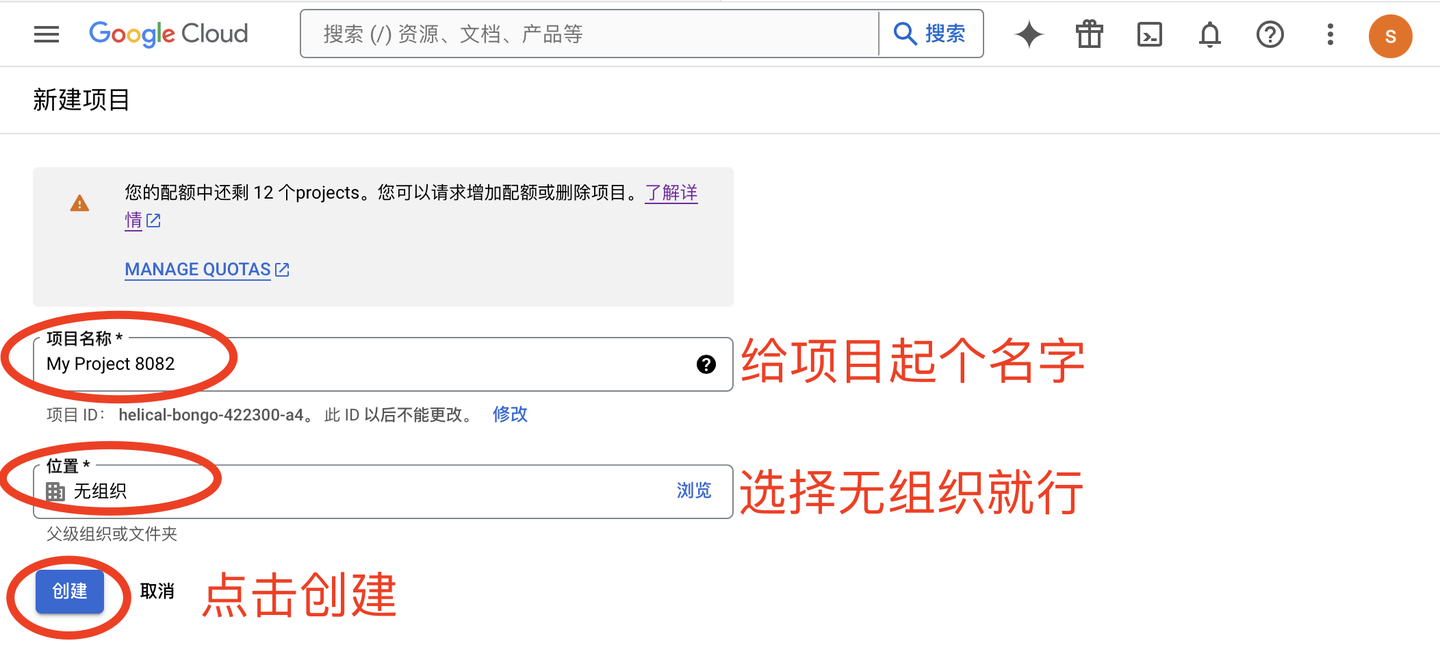
2.3、启用youtube data api v3服务
点击创建按钮之后,启用YouTube的api服务,如下: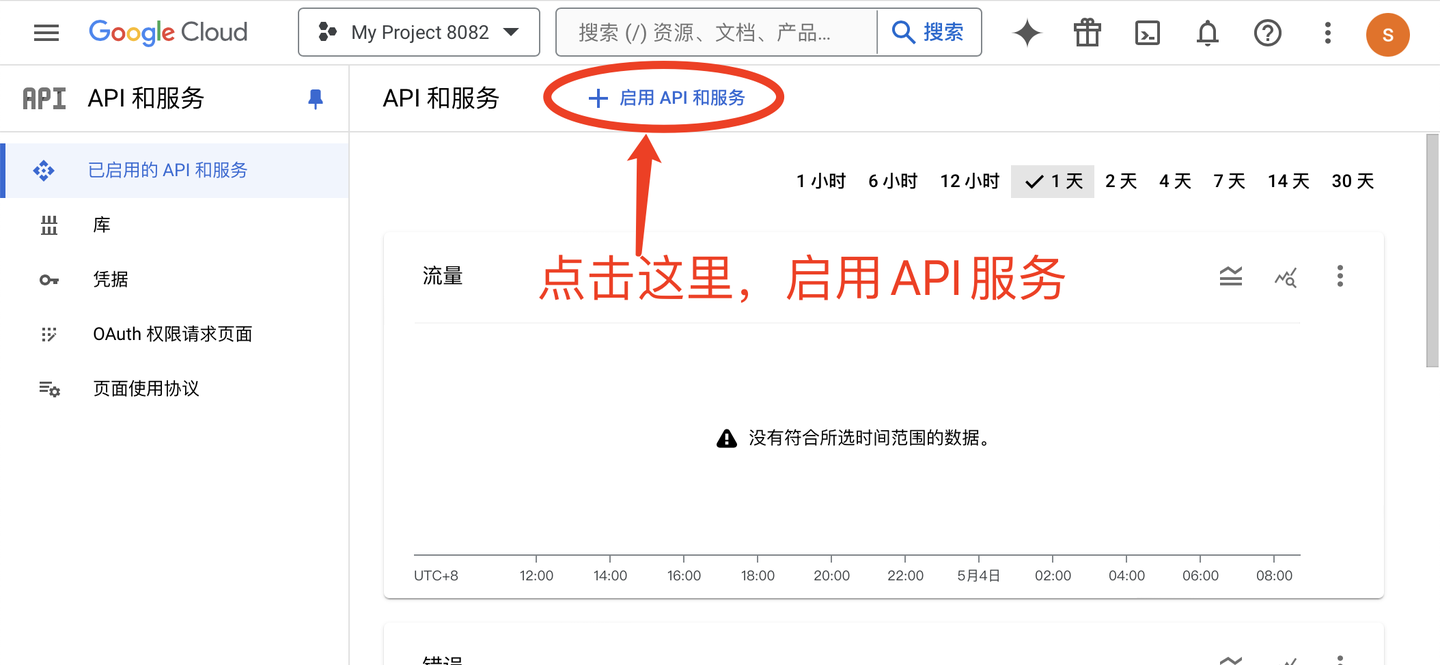
在弹出的界面中,输入搜索框,选择youtube的api,如下: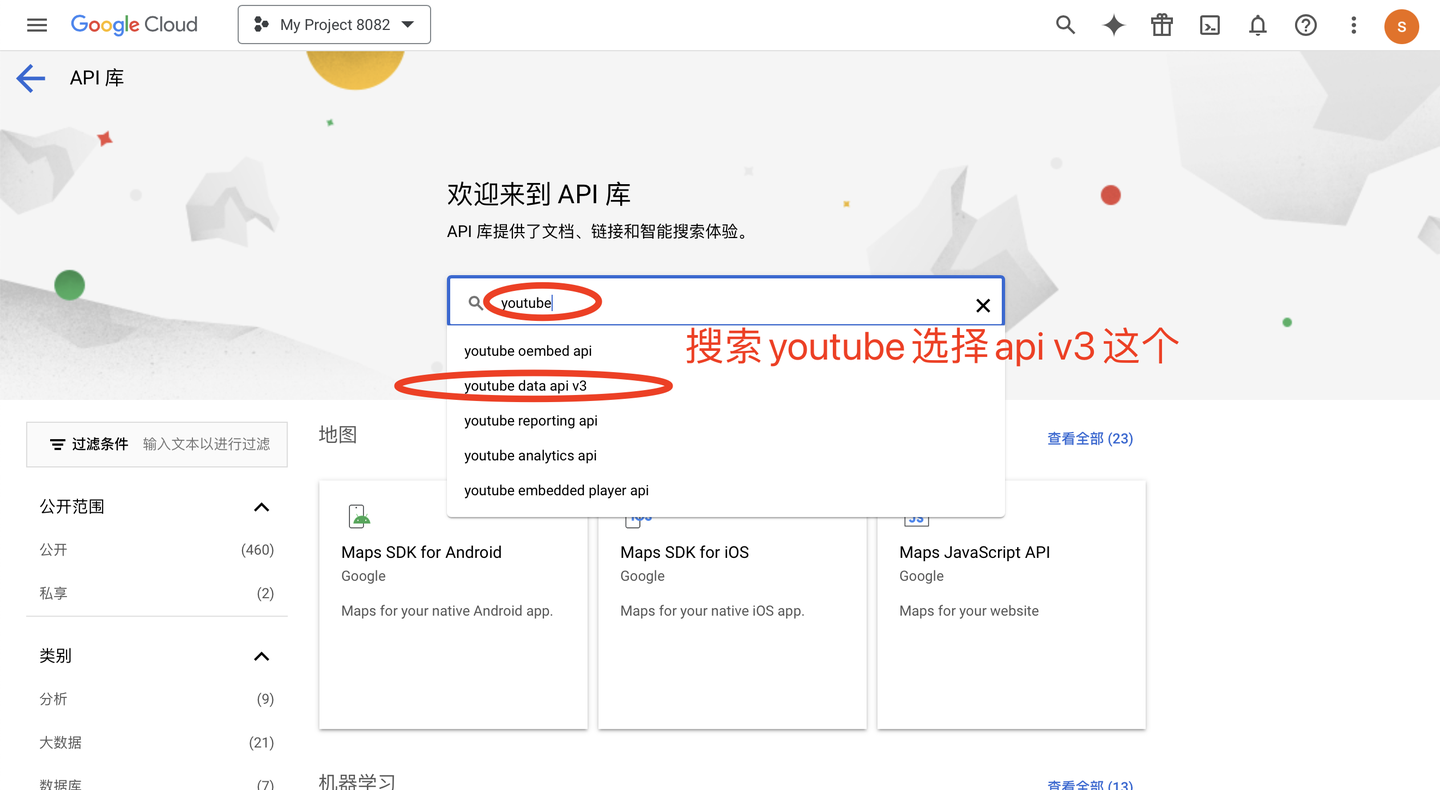
搜到的结果,点击跳转: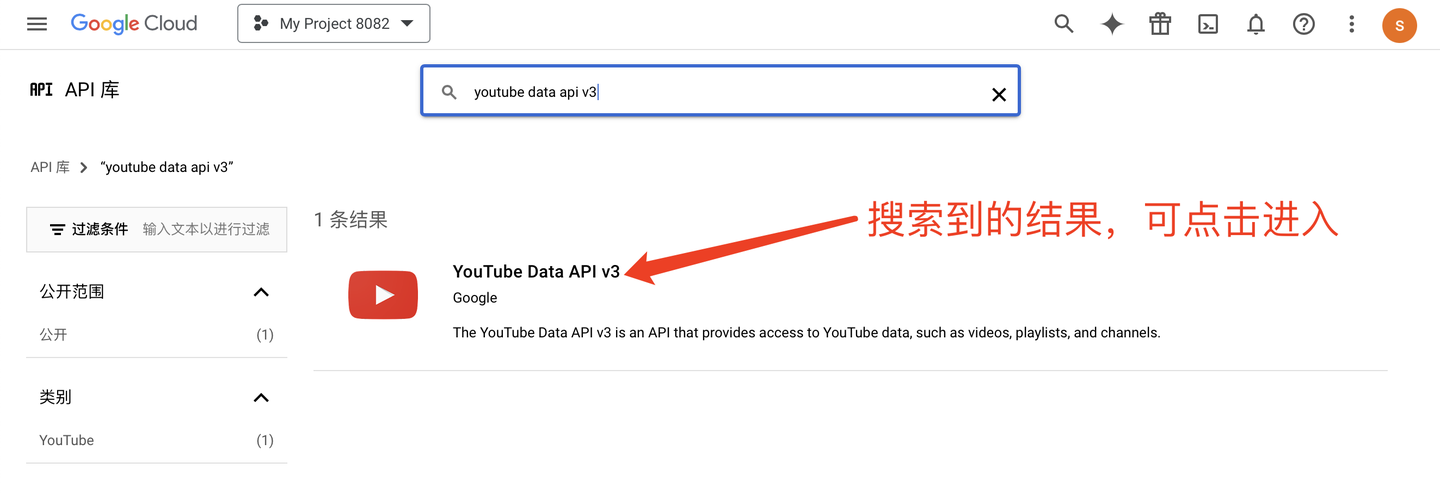
启用API服务: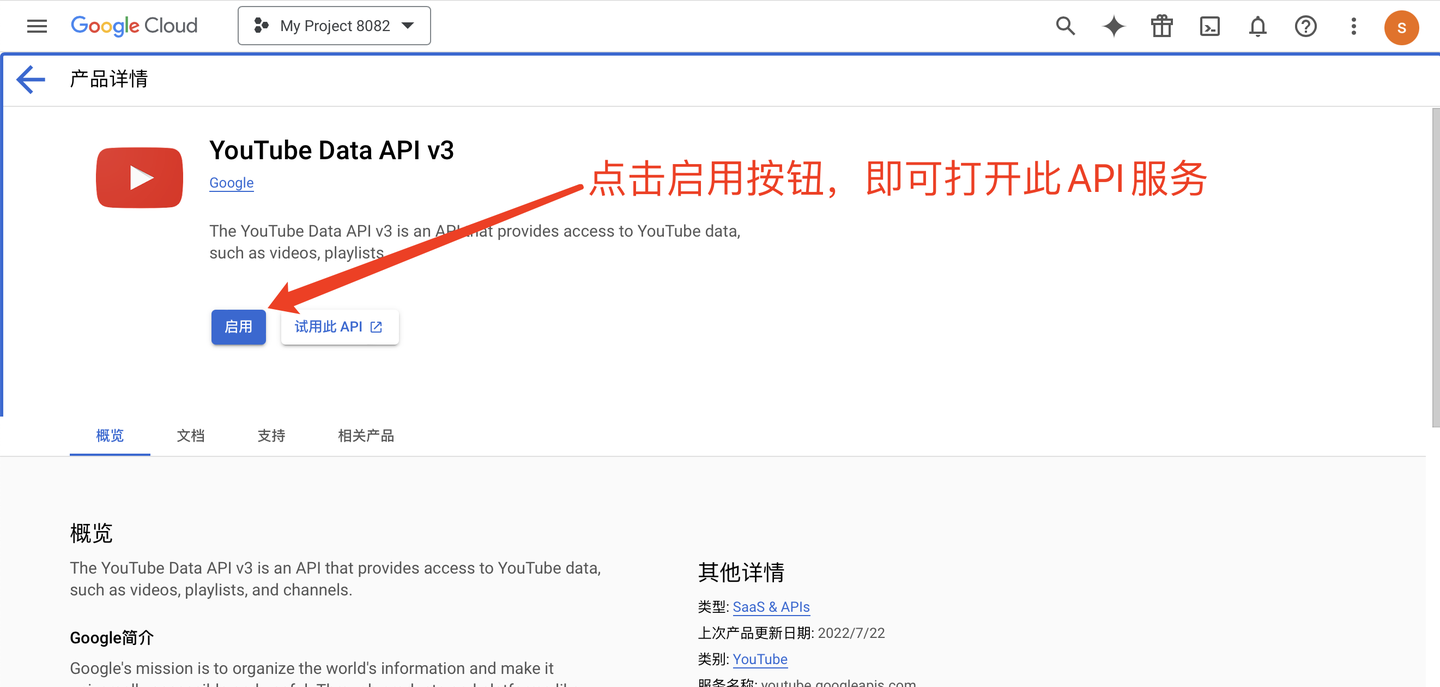
2.4、创建凭据
创建凭据(也就是API的key):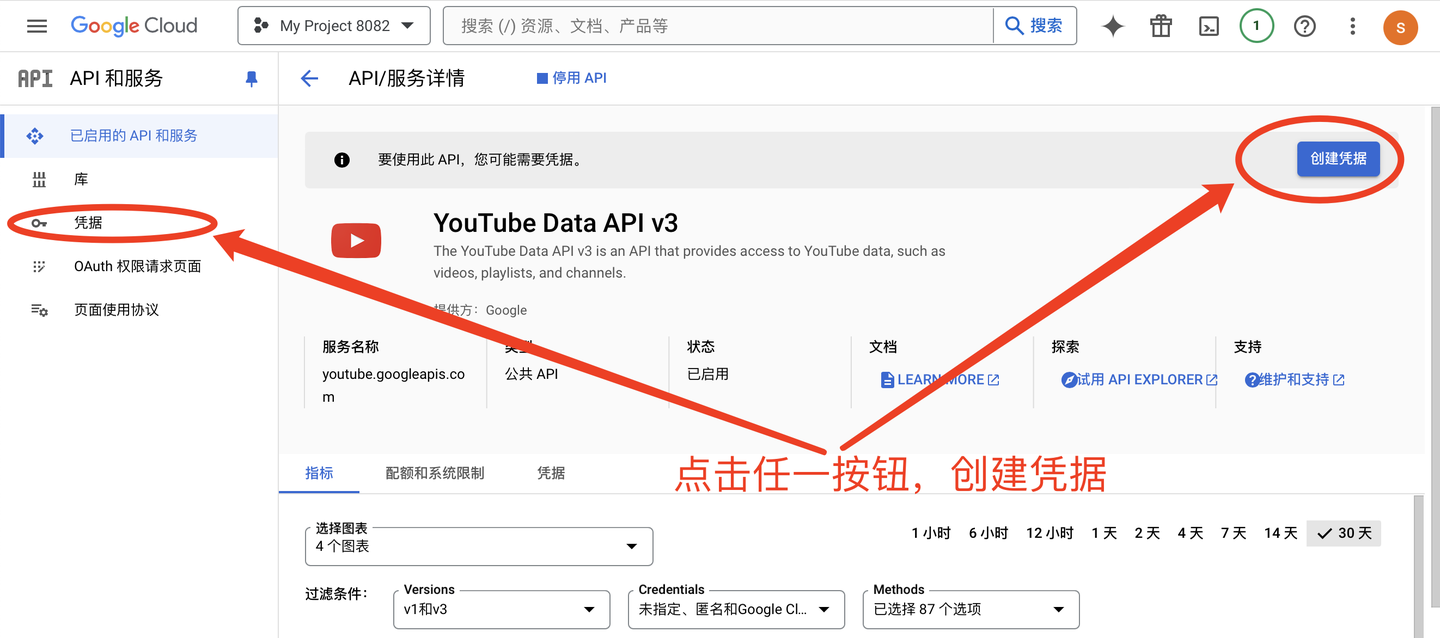
完成创建: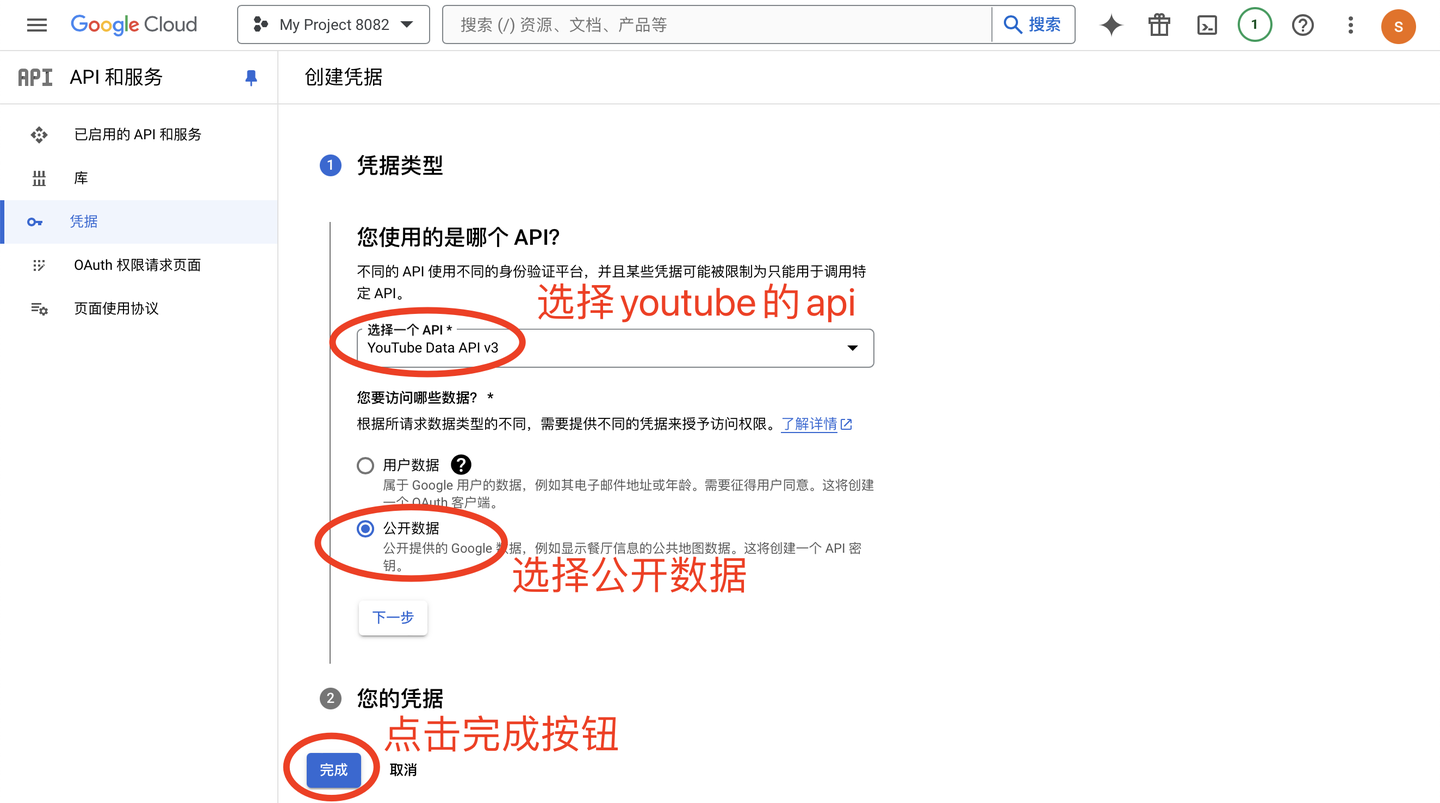
创建成功界面: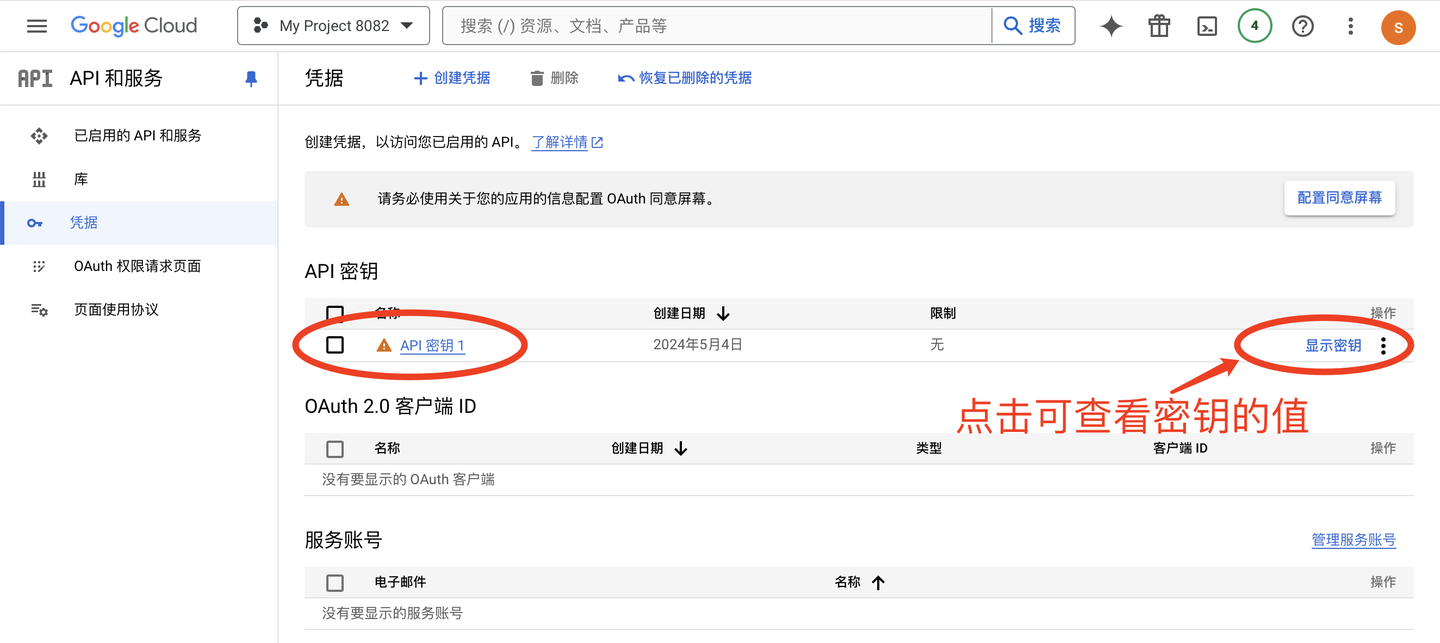
查看密钥: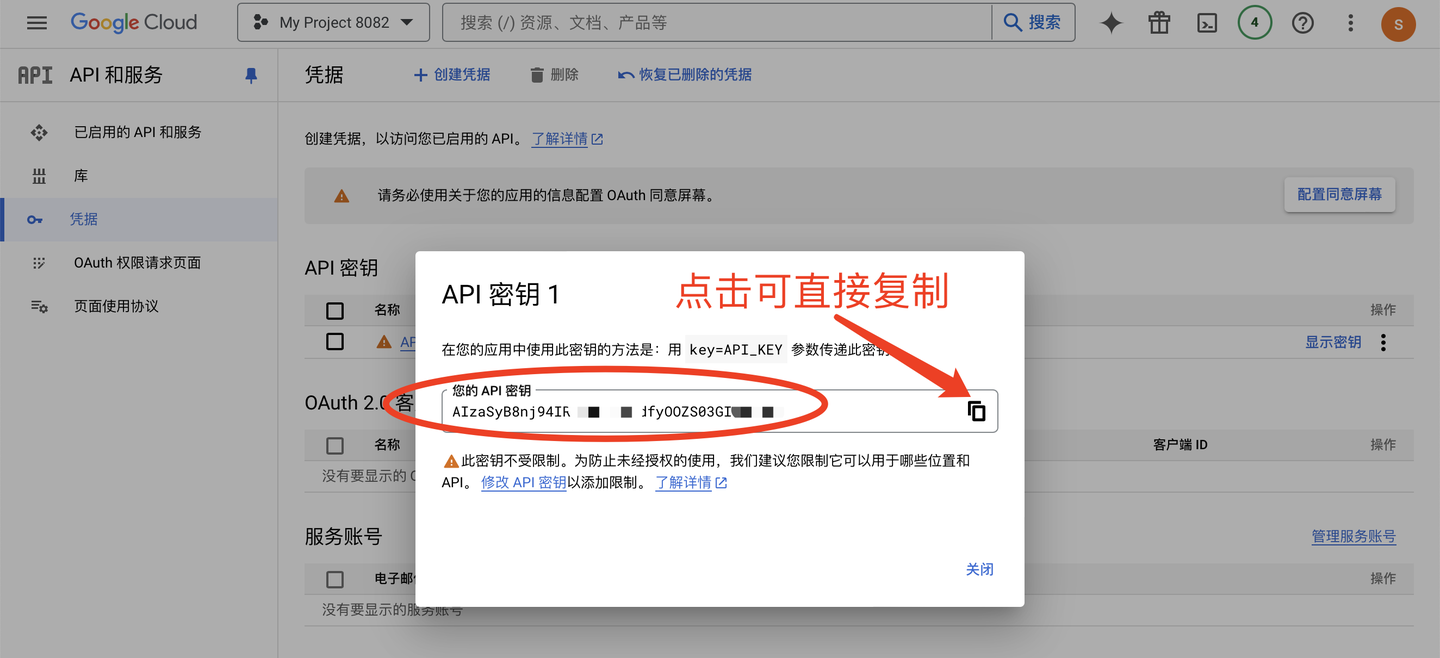
这样,就可以把key粘贴到代码里使用了!
至此,结束!
三、后续发布
基于此API密钥,并结合API帮助文档,通过Python代码,可以开发一系列的YouTube数据采集工具,我已经有思路了,你呢?
后续会逐一发布,敬请期待!
其他爬虫源码/爬虫软件,来我主页查看哦!

















 384
384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









