








我用Python独立开发了一款爬虫软件,作用是:通过搜索关键词采集YouTube的搜索结果,包含14个关键字段:关键词,页码,视频标题,视频id,视频链接,发布时间,视频时长,频道名称,频道id,频道链接,播放数,点赞数,评论数,视频简介。
软件是利用官方API实现,并非网页爬虫,稳定性较高!
软件界面截图: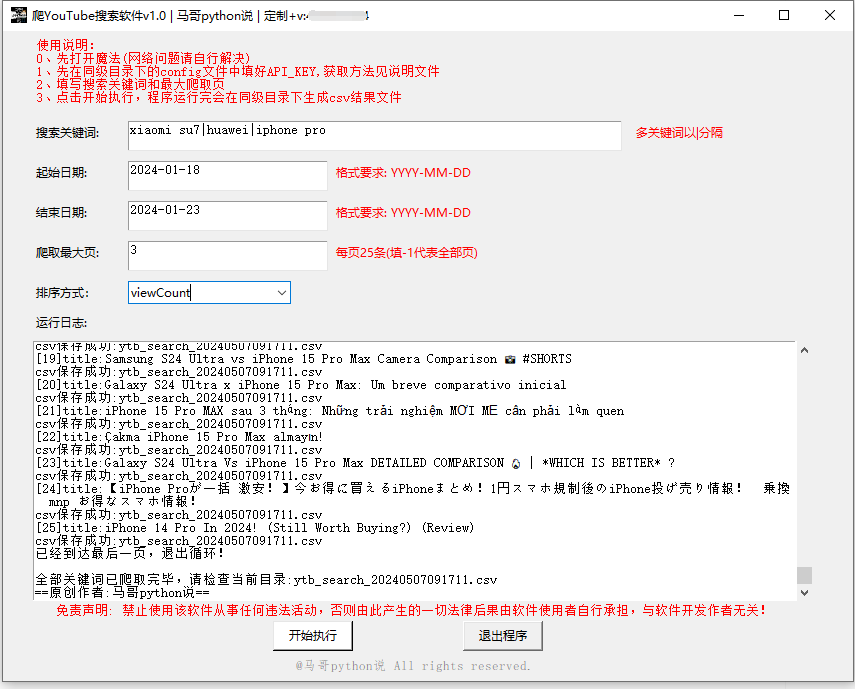
爬取结果截图:
结果截图1: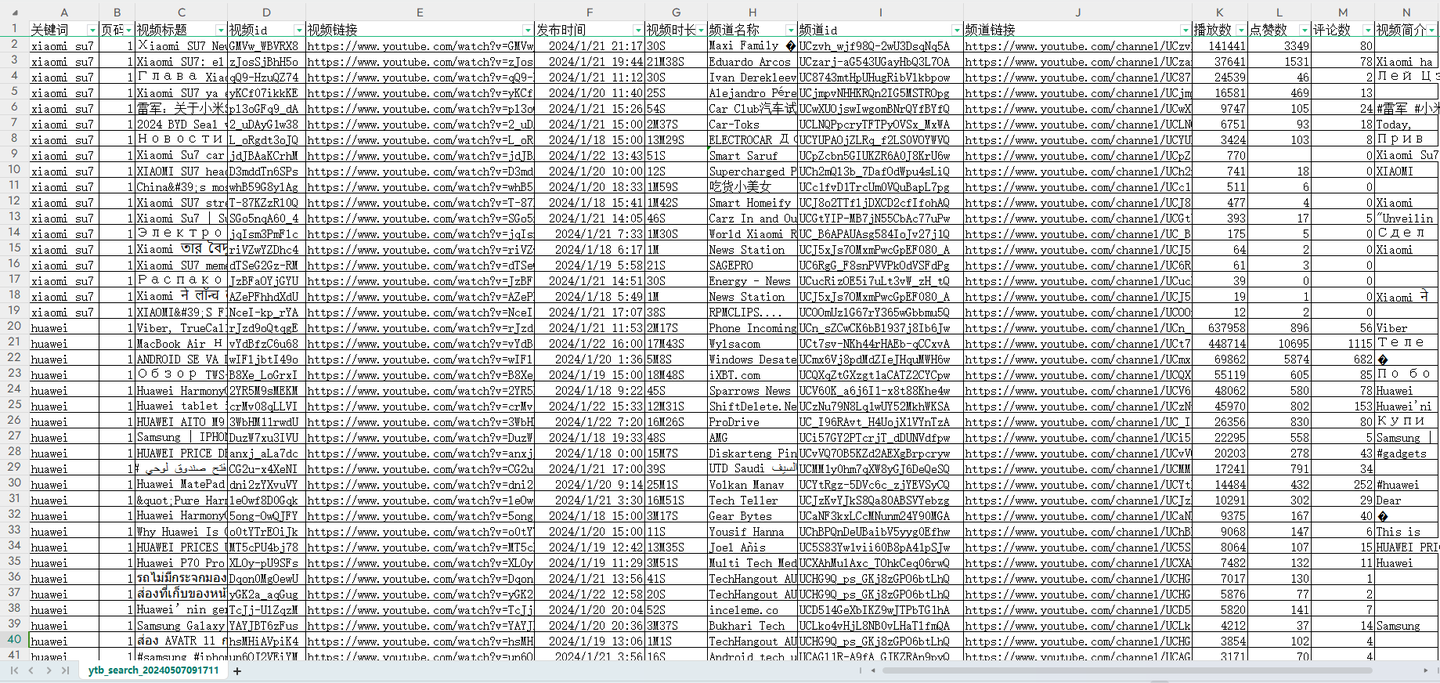
软件使用过程演示:(不懂编程的小白直接看视频,了解软件作用即可,无需看代码)
演示视频:
https://www.bilibili.com/video/BV1TZ421E7kU
重要说明:
·
完整讲解、想你所想:
https://www.bilibili.com/read/cv34506025

















 838
838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









