






数据源概况:
本案例将对某大型超市的零售数据进行数据分析,通过了
解运营状况,做出合理的决策。详细字段是:
- Row ID:行编号;
- Order ID:订单ID;
- Order Date:订单日期;
- Ship Date:发货日期;
- Ship Mode:发货模式;
- Customer ID:客户ID;
- Customer Name:客户姓名;
- Segment:客户类别;
- City:客户所在城市;
- State:客户城市所在州;
- Country:客户所在国家;
- Postal Code:邮编;
- Market:商店所属区域;
- Region:商店所属州;
- Product ID:产品ID;
- Category:产品类别;
- Sub-Category:产品子类别;
- Product Name:产品名称;
- Sales:销售额;
- Quantity:销售量;
- Discount:折扣;
- Profit:利润;
- Shipping Cost:发货成本;
- Order Priority:订单优先级;
一.读取、清洗数据:
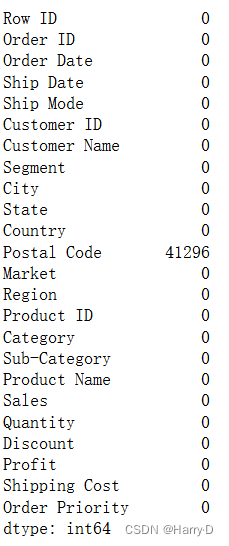
- 使用pandas的read_csv读取数据后,查看各列数据的空值情
况,发现Postal Code字段(邮编字段)有空值,而且这一
列不重要,所以首先删除掉Postal Code列;
导入库,以及一些设置
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from pylab import mpl
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体为中文黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示为方块的问题
读数据
df = pd.read_csv('market.csv',encoding='ISO-8859-1')
df.head()
查看空值
df.isnull().sum()
df.drop('Postal Code',axis=1,inplace=True)
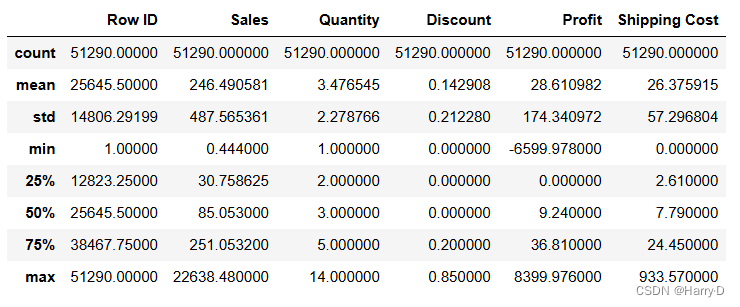
- 使用DataFrame对象的describe()方法,没有发现异常数
据,所以,不必处理;
df.describe()
- 将Order Date订单日期字段的数据修改为datetime类型;
df['Order Date']
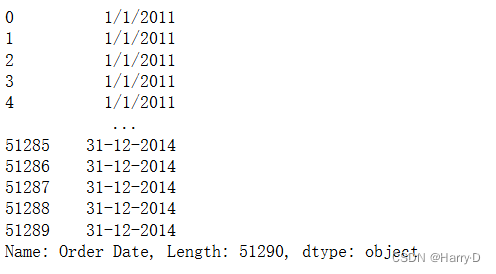
我们会发现前面的数据格式是 月日年 后面的是年月日 ,所以后面转换格式要注意。
- 为了后续分析方便,从订单日期中分别提取年、月、季度数
据,并添加三个列用来存取年、月、季度信息,分别
为:’Order-year’,’Order-month’,’quarter’
。
temp = pd.to_datetime(df['Order Date'], format='%m/%d/%Y',errors='coerce').fillna(pd.to_datetime(df['Order Date'], format='%d-%m-%Y',errors='coerce'))
df['Order Date'] = temp.dt.date
df['Order Date']
df['Order-year'] = temp.dt.year
df['Order-month'] = temp.dt.month
df['Order-quarter'] = temp.dt.quarter
保存文件
# 将 DataFrame 中的数据保存到 CSV 文件中
df.to_csv('market_cleaned.csv', index=False)
# 读取 CSV 文件
df = pd.read_csv('market_cleaned.csv')
二.问题:利润分析
先根据年和月进行分组,再分别提取各年份(2011-2014年)的数据,分析各年份对应月的利润情况。
# 根据年和月进行分组,分析每年的月利润情况
profit_monthly = df.groupby(['Order-year', 'Order-month'])
['Profit'].sum().unstack()
# 设置图形大小
plt.figure(figsize=(12, 6))
# 绘制利润分析的热力图
sns.heatmap(profit_monthly, annot=True, fmt=".2f", cmap="YlGnBu")
# 设置标题和轴标签
plt.title('每年的月利润情况 (2011-2014)')
plt.xlabel('月份')
plt.ylabel('年份')
# 显示图形
plt.show()
三.客单价分析
客单价指商场(超市)每一个顾客平均购买商品的金额,客单
价反映顾客的购买水平;
客单价=销售额÷成交顾客数
通过计算并展示每年的客单价数据,可以反映每年的顾客购买
水平
# 去除重复行
df = df.drop_duplicates()
# 计算每年的总销售额
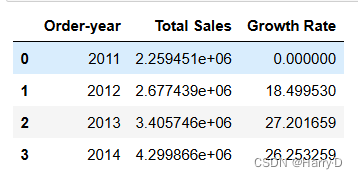
sales_yearly = df.groupby('Order-year')['Sales'].sum().reset_index()
sales_yearly.columns = ['Order-year', 'Total Sales']
sales_yearly
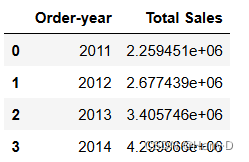
# 合并销售额和顾客数据,并计算客单价:客单价=销售额÷成交顾客数
data_yearly = pd.merge(sales_yearly, customers_yearly, on='Order-year')
data_yearly['Average Order Value'] = data_yearly['Total Sales'] / data_yearly['Unique Customers']
# 创建图表
fig2, ax3 = plt.subplots(figsize=(12, 6))
# 绘制客单价的柱状图
ax3.bar(data_yearly['Order-year'], data_yearly['Average Order Value'], color='blue', alpha=0.6, label='客单价')
ax3.set_xlabel('年份/年')
ax3.set_ylabel('销售额/元')
ax3.legend(loc='upper left')
# 设置横坐标刻度间隔
ax3.xaxis.set_major_locator(plt.MaxNLocator(integer=True))
plt.title('每年客单价分布')
plt.show()
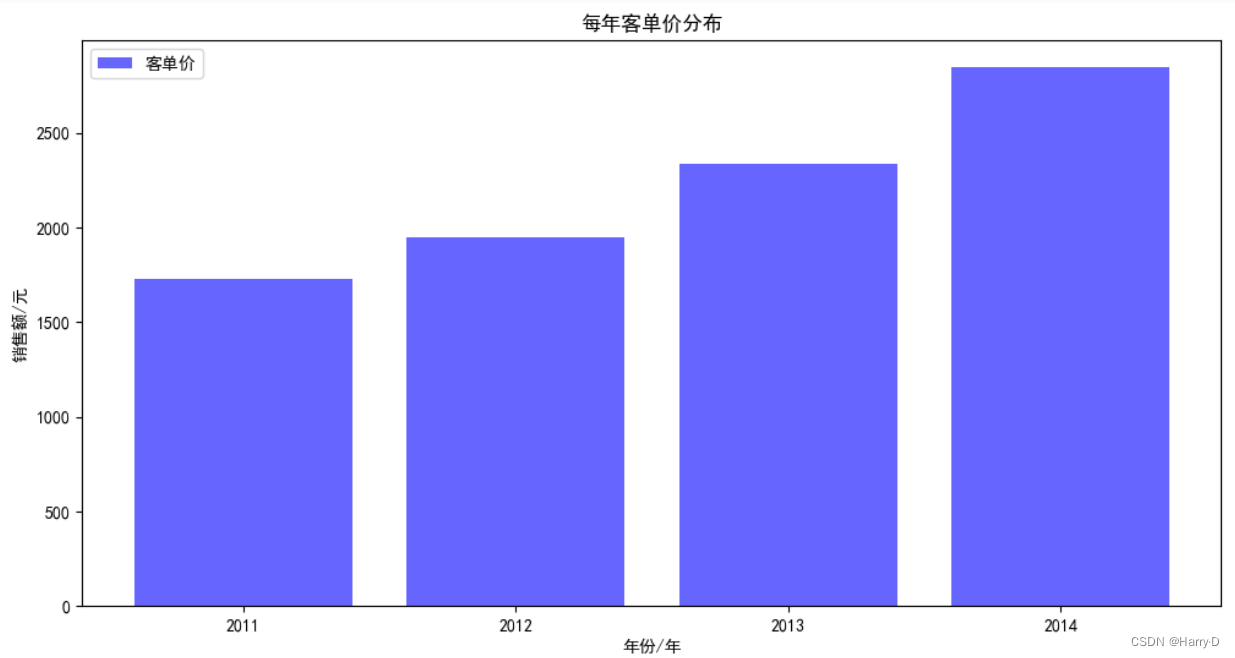
可以看出:客单价逐年上升,说明顾客的购买水平是逐年增加
的。
四.每年销售额与销售额的增长率分析
通过年份分组,计算每年的销售额总和
销售额增长率 = (本年销售额-上年销售额) / 上年销售额 * 100%
= 本年销售额 / 上年销售额 - 1
# 计算销售额增长率,销售额增长率 = (本年销售额-上年销售额) / 上年销售额 * 100%
sales_yearly['Growth Rate'] = sales_yearly['Total Sales'].pct_change() * 100
# 在2011年时设置增长率为零
sales_yearly.loc[sales_yearly['Order-year'] == 2011, 'Growth Rate'] = 0
#pct_change() 方法计算了每个元素与其前一个元素之间的变化百分比
sales_yearly
# 绘制总销售额和增长率
fig1, ax1 = plt.subplots(figsize=(12, 6))
# 绘制总销售额的柱状图
ax1.bar(sales_yearly['Order-year'], sales_yearly['Total Sales'], color='blue', alpha=0.6, label='总销售额')
ax1.set_xlabel('年份/年')
ax1.set_ylabel('销售额/元', color='blue')
ax1.tick_params(axis='y', labelcolor='blue')
ax1.yaxis.set_major_formatter(plt.FuncFormatter(lambda x, _: f'{int(x/1e6)}'))
# 绘制销售额增长率的折线图
ax2 = ax1.twinx()
ax2.plot(sales_yearly['Order-year'], sales_yearly['Growth Rate'], color='red', marker='*', label='增长率')
ax2.set_ylabel('增长率 (%)', color='red')
ax2.tick_params(axis='y', labelcolor='red')
# 设置纵坐标范围,确保0值与底部有一定距离
min_value = sales_yearly['Growth Rate'].min() - 5 # 设置一个负值来确保0值与底部有一定距离
max_value = sales_yearly['Growth Rate'].max() + 5
ax2.set_ylim(min_value, max_value)
ax2.yaxis.set_major_locator(plt.MultipleLocator(5))
ax2.yaxis.set_major_formatter(plt.FuncFormatter(lambda x, _: f'{int(x)}%'))
# 添加图例
fig1.legend(loc='upper left', bbox_to_anchor=(0.13, 0.88))
# 添加轻微的网格线
plt.grid(alpha=0.3)
plt.title('销售额与增长率')
plt.show()
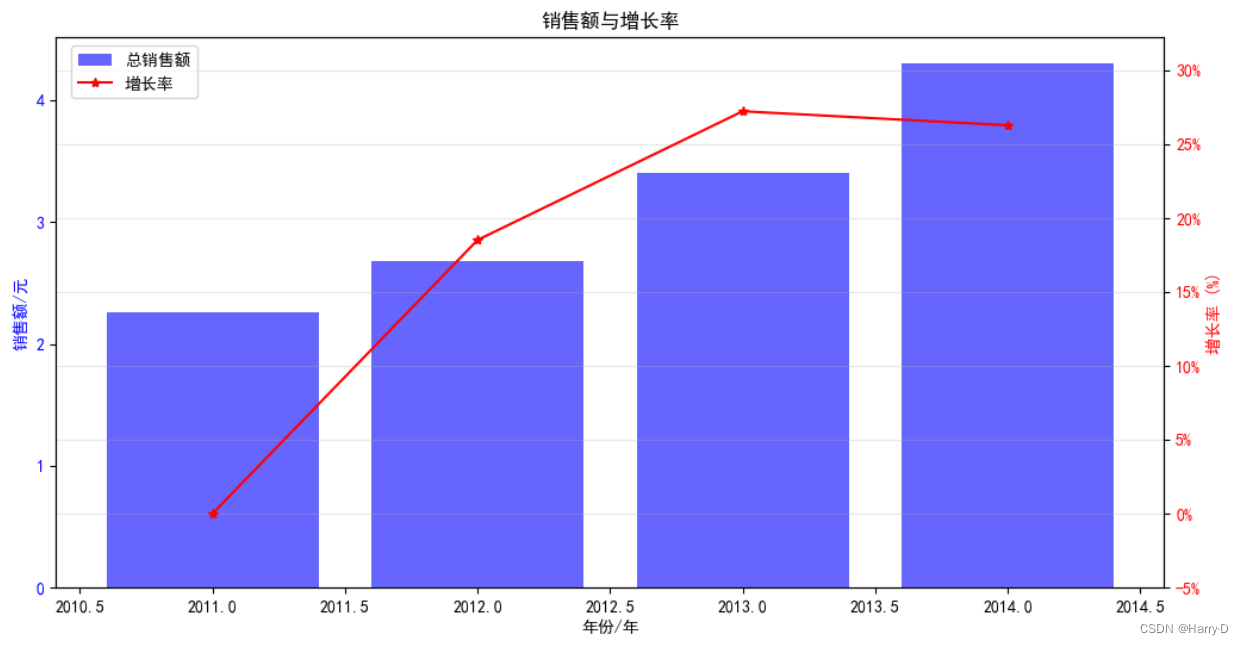
可以看出:该超市在2011-2014年销售额在稳步上升,说明企
业市场占有能力在不断提 高; 2012-2014年的增长率在增长后
趋于平稳,说明企业经营在逐步稳定
五.分析各个地区分店的销售额
- 查看不同区域分店的总销售额占比
df_market=df.groupby('Market')['Sales'].sum()
df_market

df_market.index
df_market.values
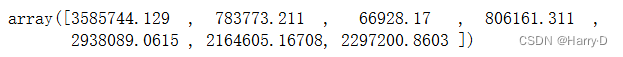
plt.pie(df_market,labels=df_market.index,autopct='%1.1f%%')
plt.title('各区域的销售额对比')
plt.show()
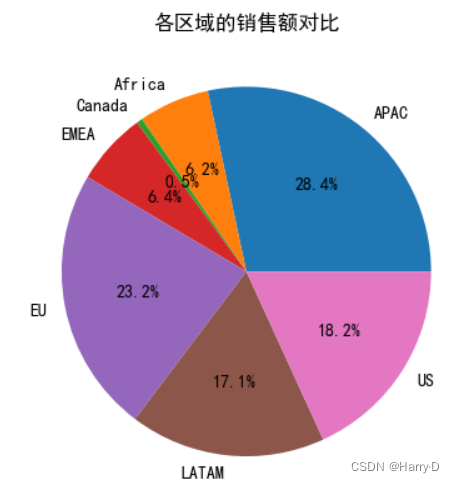
从该饼图可以看出:APAC、BJ两个地区的销售额比例很高,
总计占51.6%,Canada的销售总额占比最小,只有0.5%,可以
增加对该地区的营销
- 分别对各个区域每年销售额分析
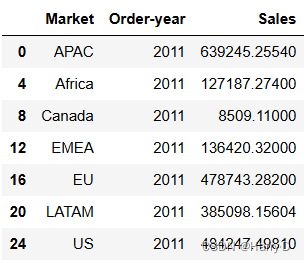
df_sales_yearly =df.groupby(['Market','Order-year'])['Sales'].sum()
df_sales_yearly = df_sales_yearly.reset_index()
y1 = df_sales_yearly[df_sales_yearly['Order-year']==2011]
y2 = df_sales_yearly[df_sales_yearly['Order-year']==2012]
y3 = df_sales_yearly[df_sales_yearly['Order-year']==2013]
y4 = df_sales_yearly[df_sales_yearly['Order-year']==2014]
y1
x = np.arange(1,8,1)#['APAC', 'Africa', 'Canada', 'EMEA', 'EU', 'LATAM', 'US']
plt.bar(x-0.4,y1['Sales'],0.2,label='2011')
plt.bar(x-0.2,y2['Sales'],0.2,label='2012')
plt.bar(x,y3['Sales'],0.2,label='2013')
plt.bar(x+0.2,y4['Sales'],0.2,label='2014')
name = ['APAC', 'Africa', 'Canada', 'EMEA', 'EU', 'LATAM', 'US']
#plt.bar(['APAC', 'Africa', 'Canada', 'EMEA', 'EU', 'LATAM', 'US'],y2['Sales'])
# 添加轻微的网格线
plt.grid(alpha=0.3)
plt.legend()
plt.xticks(x,name,fontsize=15)
plt.show()
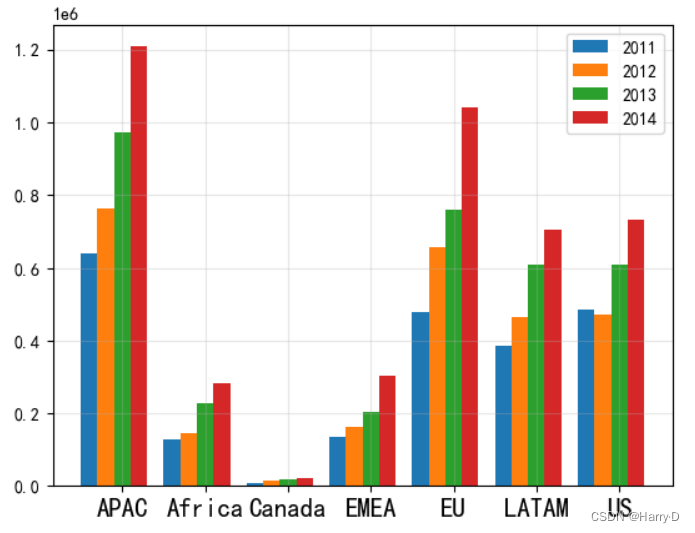
由上面的条形图可看出,各个地区2011-2014年的销售总
额均是增长趋势, 其中APAC地区和EU地区的增长速度较快,
市场前景较好,下一年可以适当 加大运营成本
- 分别对各个区域的不同类型产品销售额分析
df_sales_prod =df.groupby(['Market','Category'])['Sales'].sum()
df_sales_prod = df_sales_prod.reset_index()
p1 = df_sales_prod[df_sales_prod['Category']=='Furniture']
p2 = df_sales_prod[df_sales_prod['Category']=='Office Supplies']
p3 = df_sales_prod[df_sales_prod['Category']=='Technology']
plt.bar(x-0.2,p1['Sales'],0.2,label='Furniture')
plt.bar(x,p2['Sales'],0.2,label='Office Supplies')
plt.bar(x+0.2,p3['Sales'],0.2,label='Technology')
name = ['APAC', 'Africa', 'Canada', 'EMEA', 'EU', 'LATAM', 'US']
#plt.bar(['APAC', 'Africa', 'Canada', 'EMEA', 'EU', 'LATAM', 'US'],y2['Sales'])
# 添加轻微的网格线
plt.grid(alpha=0.3)
plt.legend()
plt.xticks(x,name,fontsize=15)
plt.show()
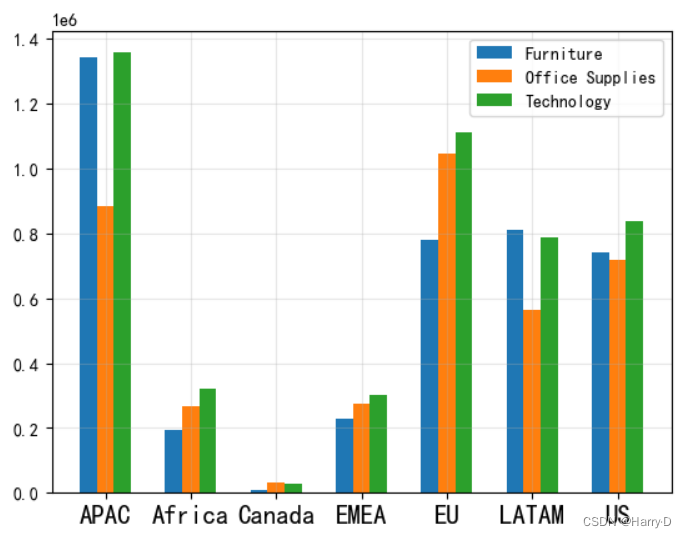
由上图可看出,除了Canada地区以外,各大地区销售额都比较
高的是电子产品,可 以适当加大对各地区(除Canada地区)
该种类的投入,以便扩大优势。
六.销量分析与销售淡旺季分析
- 销量分析
通过表格展示,2011-2014年各月份的详细销量数据
# 根据年和月进行分组,分析每年的月销量情况
quantity_monthly = df.groupby(['Order-year', 'Order-month'])['Quantity'].sum().unstack()
# 设置图形大小
plt.figure(figsize=(12, 6))
# 绘制利润分析的热力图
sns.heatmap(quantity_monthly, annot=True, fmt=".2f", cmap="YlGnBu")
# 设置标题和轴标签
plt.title('每年的月销量情况 (2011-2014)')
plt.xlabel('月份')
plt.ylabel('年份')
# 显示图形
plt.show()
- 淡旺季分析
# 根据年和月进行分组,分析每年的月销售额情况
sale_monthly = df.groupby(['Order-year', 'Order-month'])['Sales'].sum().unstack()
sale_monthly

years = sale_monthly.index
years

# 创建一个折线图
plt.figure(figsize=(12, 6))
years = sale_monthly.index # 假设年份信息存储在索引中
for year in years:
data_year = sale_monthly.loc[year]
plt.plot(data_year.index, data_year.values, label=str(year))
# 设置图表标题和坐标轴标签
plt.title('年月销售额的变化趋势分析淡旺季')
plt.xlabel('月份')
plt.ylabel('销售额')
plt.legend(title='年份')
# 添加轻微的网格线
plt.grid(alpha=0.3)
plt.legend()
plt.show()
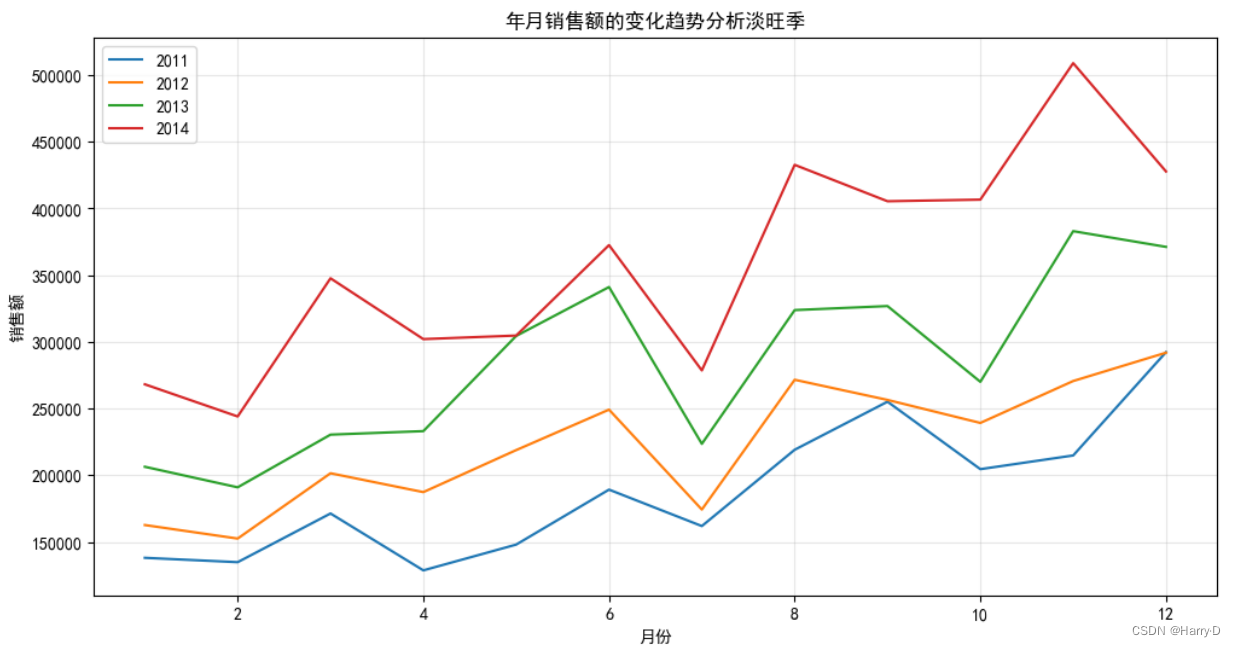
由上面的折线图可以看出,该超市2011-2014年每一年的销售
额同比上一年都是上升趋势,而且该超市的旺季是下半年;在
上半年的销售额中发现6月份的销售额较高,可以在6月份开始
加大一些运营成本;尤其需要注意,下半年的7月份和10月份
销售额会有明显下降,可以针对这两个月份举行一些营销活
动,以期提高销售额
七.分析新老客户数
新老客户的定义:将只要消费过的客户定义为老客户,否则就
是新客户
根据Customer ID列数据进行重复行的删除, 保证数据集中所
有的客户ID都是唯一的,根据此数据再通过年、月进行分组,
通过透视表分析新老客户数
# 删除重复的Customer ID
unique_customers = df.drop_duplicates(subset='Customer ID')
创建了一个名为"Customer Type"的新列,该列基于"Order Date"列是否存在来判断客户类型。第二行将布尔值转换为字符串,并用"New Customer"和"Old Customer"替换相应的值。
# 标识新老客户
unique_customers['Customer Type'] = unique_customers['Order Date'].notna().astype('str')
unique_customers['Customer Type'] = unique_customers['Customer Type'].replace({'False': 'New Customer', 'True': 'Old Customer'})
unique_customers[unique_customers['Customer Type']=='Old Customer']
从数据中删除那些没有购买日期的记录,因为新客户通常没有购买日期。 代码中的dropna函数将根据"Order Date"列删除包含缺失值的行, 并将结果保存在名为"customers_with_purchases"的新数据框中。
# 仅保留包含购买日期的记录,因为新客户没有购买日期
customers_with_purchases = unique_customers.dropna(subset=['Order Date'])
customers_with_purchases
# 创建透视表
pivot_table = pd.pivot_table(
customers_with_purchases,
values='Customer ID',
index='Order-month',
columns='Order-year',
aggfunc='count',
fill_value=0)
pivot_table
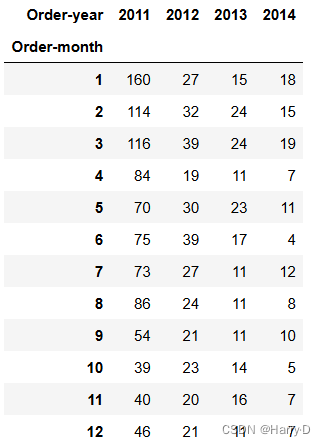
由于上述透视表的人数和远远小于总的记录数,说明超市对保
持老客户较为有效 ,也间接说明了超市的运营状况较为稳定;
还可以发现,2011-2014年每年的新增客户数呈逐年减少的趋
势,新客户获取率比较低,因此,可以进行主动推广营销,从
而增加新客户数;
八.用户数据分析
- 客户类型占比分析
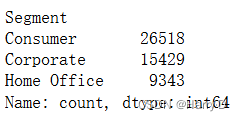
# 计算不同客户类型的数量
customer_type_counts = df['Segment'].value_counts()
customer_type_counts
绘制饼图查看不同客户的类型占比,其中,'Segment’字段
代表客户类别
# 绘制饼图
plt.figure(figsize=(6, 6))
plt.pie(customer_type_counts, labels=customer_type_counts.index, autopct='%1.2f%%', startangle=140)
plt.axis('equal') # 使饼图比例相等
plt.title('客户类型占比分析')
plt.show()
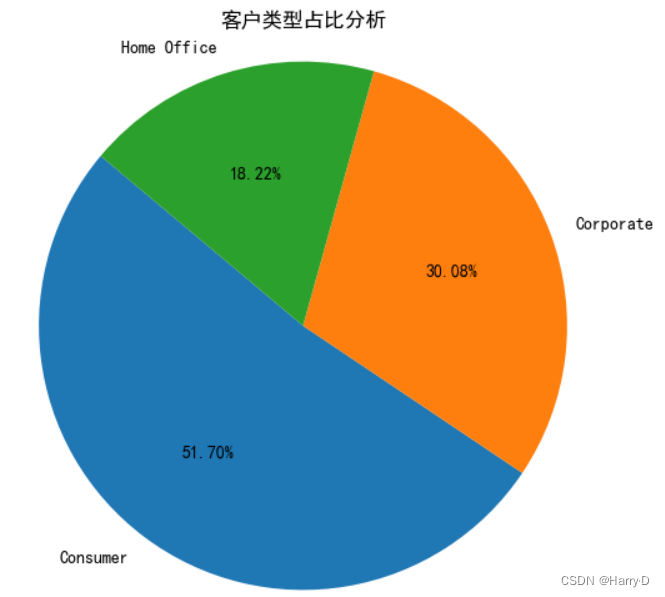
可知:Consumer类型的消费者的客户占比最多,达51.7%,
Home Office占比最小,可加强对该类型的客户进行营销宣
传。
- 各年不同类型消费者数量分析
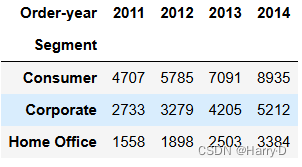
# 按照客户种类和年份分组,并计算每组的用户数量
grouped = df.groupby(['Segment', 'Order-year'])['Customer ID'].count().unstack()
grouped
grouped.index

grouped.columns
for i, year in enumerate(grouped.columns):
print(i,year)
# 绘制条形图
fig, ax = plt.subplots(figsize=(12, 6))
bar_width = 0.2
index = np.arange(len(grouped.index))
for i, year in enumerate(grouped.columns):
ax.bar(index + i * bar_width, grouped[year], width=bar_width, label=year)
ax.set_xticks(index + 1.5 * bar_width)
ax.set_xticklabels(grouped.index)
ax.set_xlabel('客户类别')
ax.set_ylabel('客户数量')
ax.set_title('各年不同类型消费者数量分析')
ax.legend(title='年份')
plt.show()
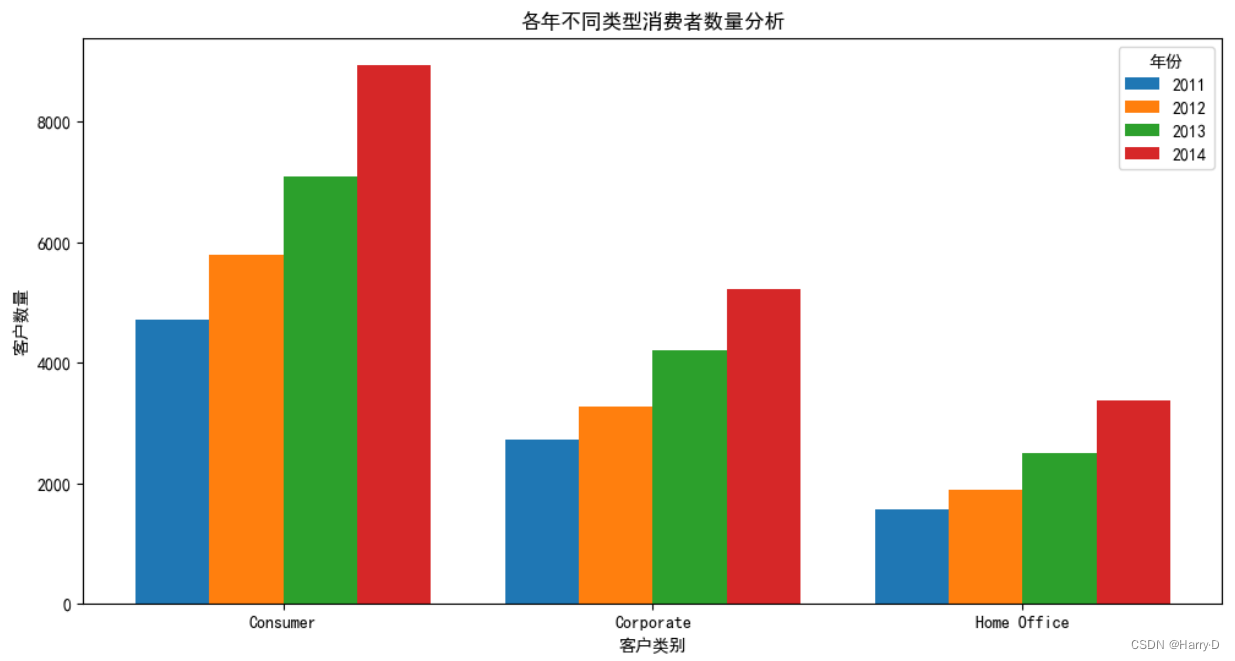
由上面可分析出,每种类型的客户数量在逐年增长,说明客户
的结构类型趋于良好
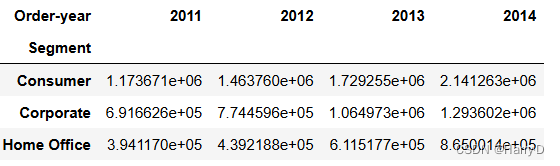
- 不同类型的客户每年的销售额分析
# 按照客户种类和年份分组,并计算每组的销售额之和
grouped = df.groupby(['Segment', 'Order-year'])['Sales'].sum().unstack()
grouped
grouped.index

# 绘制条形图
fig, ax = plt.subplots(figsize=(12, 6))
bar_width = 0.2
index = np.arange(len(grouped.index))
for i, year in enumerate(grouped.columns):
ax.bar(index + i * bar_width, grouped[year], width=bar_width, label=year)
ax.set_xticks(index + 1.5 * bar_width)
ax.set_xticklabels(grouped.index)
ax.set_xlabel('客户类别')
ax.set_ylabel('销售额')
ax.set_title('不同类型的客户每年的销售额分析')
ax.legend(title='年份')
plt.show()
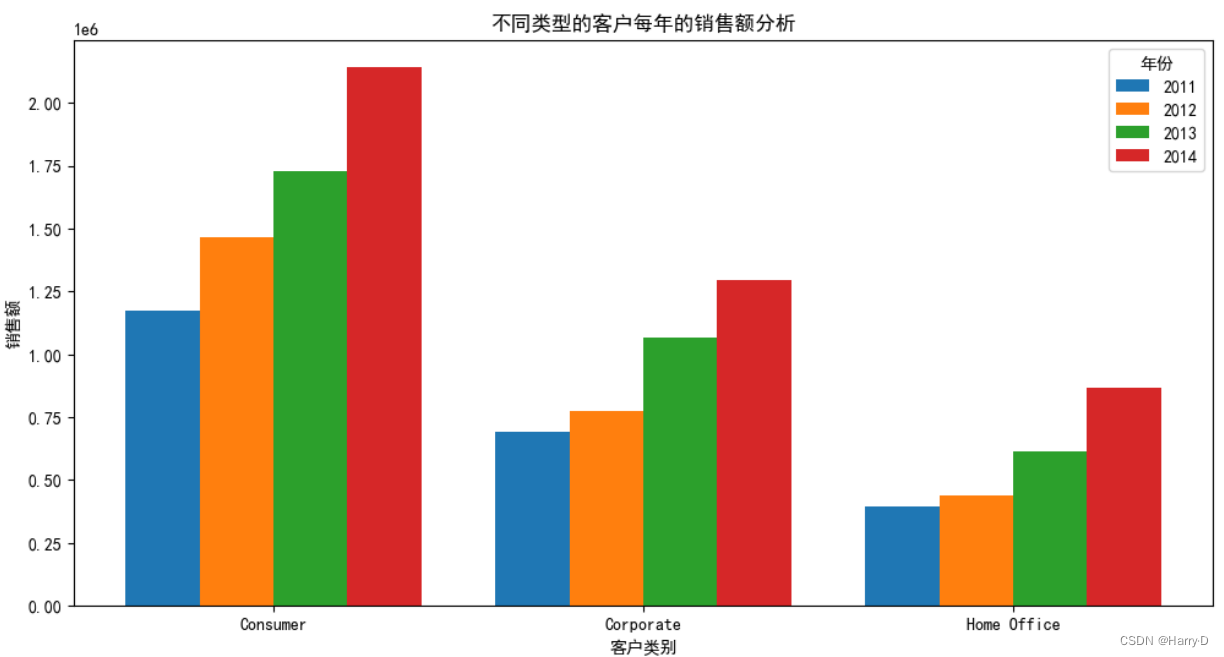
由上面可知,各类型的消费者的销售额在逐步上升,其中以普
通消费者的销售额最多, 可能是因为普通消费者最多的缘故。
九.用户价值度RFM模型分析
RFM是一个经典的客户分群模型,含义如下:
R——Recency:客户最近一次消费时间
F——Frequency:客户消费的频次
M——Monetary:消费金额
客户价值类型:
- 重要价值客户:RFM3个值都很高,是平台重点维护的客户
- 重要保持客户:最近一次消费时间较远,消费金额和消费频
次比较高 - 重要发展客户:最近有消费,且整体消费金额高,但是购买
不频繁 - 重要挽留客户:消费金额较高,消费频次偏低,而且已经很
久没有消费行为了 - 一般价值客户:多次频繁购买,但是购买的商品价格都较低
- 一般保持客户:频繁浏览,但是很久没有成交了
- 一般发展客户:有近期购买行为,但购买商品利润低而且不
活跃 - 一般挽留客户:RFM3个值都低,已经是流失的客户
根据客户对平台的贡献度的排序是:重要价值客户 > 重要保
持客户 > 重要发展客户 > 重要挽留客户 > 一般价值客户 > 一
般保持客户 > 一般发展客户 > 一般挽留客户
以2014年的消费数据为例(其他年份类似)
提取出2014年的订单数据后,分别添加F、M、R三个维度的数
据列,然后再分别对三个维度划定评级,添加三个列,并将每
条记录的三个维度的评分进行0、1标记(大于平均分记为1,
小于平均分的记为0),最后对每个客户进行价值类型标记;对
不同价值的客户类型进行占比分析
df_2014 = df[df['Order-year'] == 2014]
# 将 'Order Date' 列转换为日期时间类型
df_2014['Order Date'] = pd.to_datetime(df_2014['Order Date'])
df_2011 = df[df['Order-year'] == 2011]
# 将 'Order Date' 列转换为日期时间类型
df_2011['Order Date'] = pd.to_datetime(df_2011['Order Date'])
df_2012 = df[df['Order-year'] == 2012]
# 将 'Order Date' 列转换为日期时间类型
df_2012['Order Date'] = pd.to_datetime(df_2012['Order Date'])
df_2013 = df[df['Order-year'] == 2013]
# 将 'Order Date' 列转换为日期时间类型
df_2013['Order Date'] = pd.to_datetime(df_2013['Order Date'])
# 计算RFM值
current_date = df_2014['Order Date'].max() + pd.Timedelta(days=1)
# R值(最近一次消费时间)
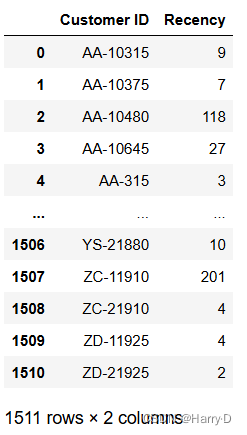
recency = df_2014.groupby('Customer ID')['Order Date'].apply(lambda x: (current_date - x.max()).days).reset_index()
recency.columns = ['Customer ID', 'Recency']
# F值(消费频次)
frequency = df_2014.groupby('Customer ID')['Order ID'].count().reset_index()
frequency.columns = ['Customer ID', 'Frequency']
# M值(消费金额)
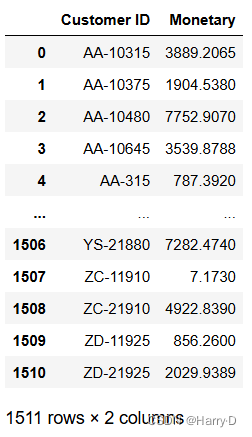
monetary = df_2014.groupby('Customer ID')['Sales'].sum().reset_index()
monetary.columns = ['Customer ID', 'Monetary']
recency
frequency

monetary
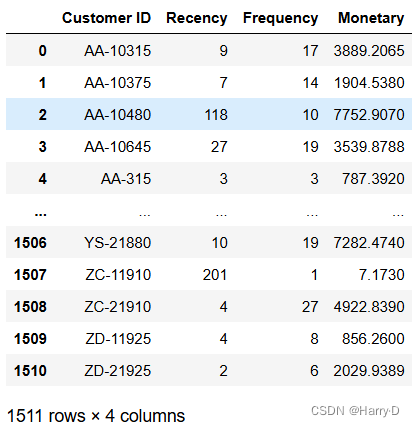
# 合并R、F、M值
rfm_2014 = recency.merge(frequency, on='Customer ID').merge(monetary, on='Customer ID')
rfm_2014
# RFM值评级(大于平均值记为1,小于等于平均值记为0)
rfm_2014['R_Score'] = (rfm_2014['Recency'] <= rfm_2014['Recency'].mean()).astype(int)
rfm_2014['F_Score'] = (rfm_2014['Frequency'] > rfm_2014['Frequency'].mean()).astype(int)
rfm_2014['M_Score'] = (rfm_2014['Monetary'] > rfm_2014['Monetary'].mean()).astype(int)
# 客户价值类型标记
def rfm_segment(row):
if row['R_Score'] == 1 and row['F_Score'] == 1 and row['M_Score'] == 1:
return '重要价值客户'
elif row['R_Score'] == 0 and row['F_Score'] == 1 and row['M_Score'] == 1:
return '重要保持客户'
elif row['R_Score'] == 1 and row['F_Score'] == 0 and row['M_Score'] == 1:
return '重要发展客户'
elif row['R_Score'] == 0 and row['F_Score'] == 0 and row['M_Score'] == 1:
return '重要挽留客户'
elif row['R_Score'] == 1 and row['F_Score'] == 1 and row['M_Score'] == 0:
return '一般价值客户'
elif row['R_Score'] == 0 and row['F_Score'] == 1 and row['M_Score'] == 0:
return '一般保持客户'
elif row['R_Score'] == 1 and row['F_Score'] == 0 and row['M_Score'] == 0:
return '一般发展客户'
elif row['R_Score'] == 0 and row['F_Score'] == 0 and row['M_Score'] == 0:
return '一般挽留客户'
else:
return '未知'
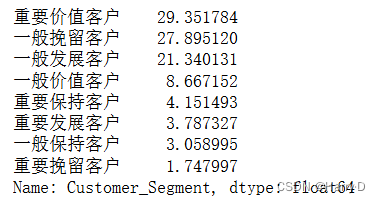
rfm_2014['Customer_Segment'] = rfm_2014.apply(rfm_segment, axis=1) # 客户类型占比分析
segment_counts = rfm_2014['Customer_Segment'].value_counts(normalize=True) * 100 # 输出结果
print(segment_counts)

# 绘制客户类型占比分析图
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 8))
segment_counts.plot.pie(autopct='%1.1f%%', startangle=90)
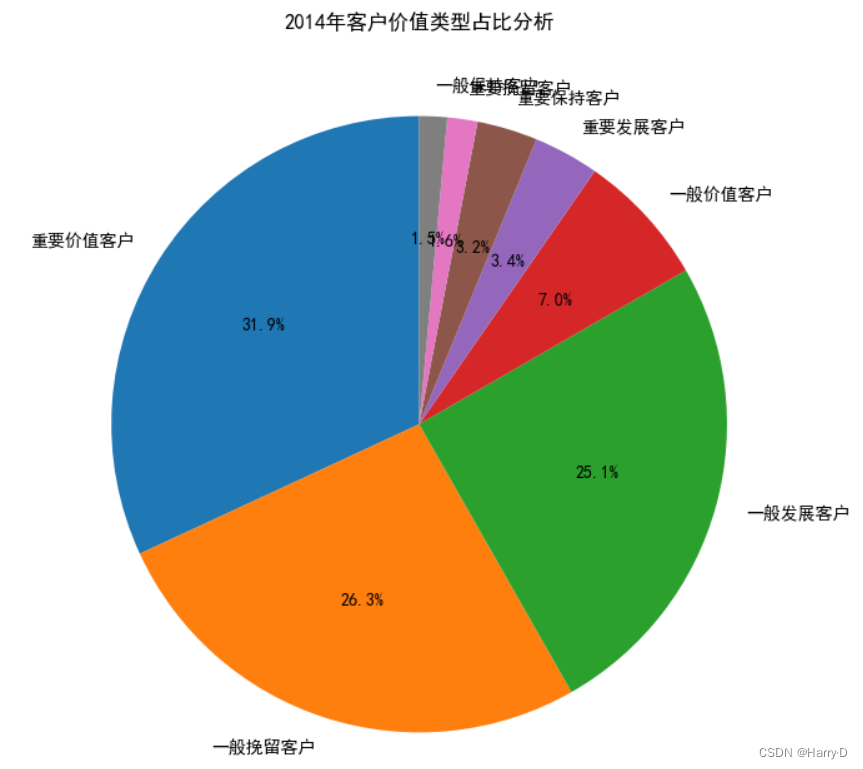
plt.title('2014年客户价值类型占比分析')
plt.ylabel(' ')
plt.show()
# 计算RFM值
current_date = df_2011['Order Date'].max() + pd.Timedelta(days=1)
# R值(最近一次消费时间)
recency = df_2011.groupby('Customer ID')['Order Date'].apply(lambda x: (current_date - x.max()).days).reset_index()
recency.columns = ['Customer ID', 'Recency']
# F值(消费频次)
frequency = df_2011.groupby('Customer ID')['Order ID'].count().reset_index()
frequency.columns = ['Customer ID', 'Frequency']
# M值(消费金额)
monetary = df_2011.groupby('Customer ID')['Sales'].sum().reset_index()
monetary.columns = ['Customer ID', 'Monetary']
# 合并R、F、M值
rfm_2011 = recency.merge(frequency, on='Customer ID').merge(monetary, on='Customer ID')
# RFM值评级(大于平均值记为1,小于等于平均值记为0)
rfm_2011['R_Score'] = (rfm_2011['Recency'] <= rfm_2011['Recency'].mean()).astype(int)
rfm_2011['F_Score'] = (rfm_2011['Frequency'] > rfm_2011['Frequency'].mean()).astype(int)
rfm_2011['M_Score'] = (rfm_2011['Monetary'] > rfm_2011['Monetary'].mean()).astype(int)
rfm_2011['Customer_Segment'] = rfm_2011.apply(rfm_segment, axis=1) # 客户类型占比分析
segment_counts = rfm_2011['Customer_Segment'].value_counts(normalize=True) * 100 # 输出结果
print(segment_counts)

# 绘制客户类型占比分析图
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 8))
segment_counts.plot.pie(autopct='%1.1f%%', startangle=90)
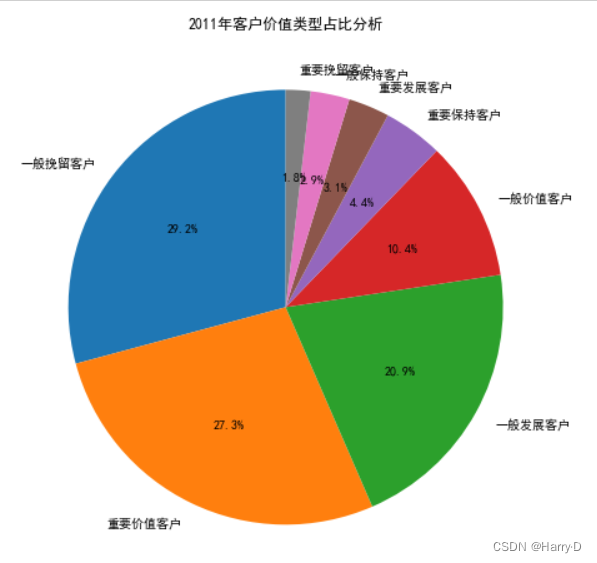
plt.title('2011年客户价值类型占比分析')
plt.ylabel(' ')
plt.show()
# 计算RFM值
current_date = df_2012['Order Date'].max() + pd.Timedelta(days=1)
# R值(最近一次消费时间)
recency = df_2012.groupby('Customer ID')['Order Date'].apply(lambda x: (current_date - x.max()).days).reset_index()
recency.columns = ['Customer ID', 'Recency']
# F值(消费频次)
frequency = df_2012.groupby('Customer ID')['Order ID'].count().reset_index()
frequency.columns = ['Customer ID', 'Frequency']
# M值(消费金额)
monetary = df_2012.groupby('Customer ID')['Sales'].sum().reset_index()
monetary.columns = ['Customer ID', 'Monetary']
# 合并R、F、M值
rfm_2012 = recency.merge(frequency, on='Customer ID').merge(monetary, on='Customer ID')
# RFM值评级(大于平均值记为1,小于等于平均值记为0)
rfm_2012['R_Score'] = (rfm_2012['Recency'] <= rfm_2012['Recency'].mean()).astype(int)
rfm_2012['F_Score'] = (rfm_2012['Frequency'] > rfm_2012['Frequency'].mean()).astype(int)
rfm_2012['M_Score'] = (rfm_2012['Monetary'] > rfm_2012['Monetary'].mean()).astype(int)
rfm_2012['Customer_Segment'] = rfm_2012.apply(rfm_segment, axis=1) # 客户类型占比分析
segment_counts = rfm_2012['Customer_Segment'].value_counts(normalize=True) * 100 # 输出结果
print(segment_counts)
# 绘制客户类型占比分析图
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 8))
segment_counts.plot.pie(autopct='%1.1f%%', startangle=90)
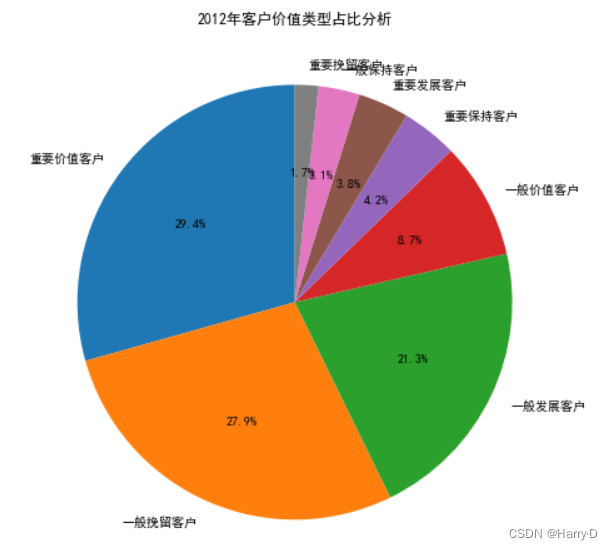
plt.title('2012年客户价值类型占比分析')
plt.ylabel(' ')
plt.show()
# 绘制客户类型占比分析图
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 8))
segment_counts.plot.pie(autopct='%1.1f%%', startangle=90)
plt.title('2012年客户价值类型占比分析')
plt.ylabel(' ')
plt.show()
# 计算RFM值
current_date = df_2013['Order Date'].max() + pd.Timedelta(days=1)
# R值(最近一次消费时间)
recency = df_2013.groupby('Customer ID')['Order Date'].apply(lambda x: (current_date - x.max()).days).reset_index()
recency.columns = ['Customer ID', 'Recency']
# F值(消费频次)
frequency = df_2013.groupby('Customer ID')['Order ID'].count().reset_index()
frequency.columns = ['Customer ID', 'Frequency']
# M值(消费金额)
monetary = df_2013.groupby('Customer ID')['Sales'].sum().reset_index()
monetary.columns = ['Customer ID', 'Monetary']
# 合并R、F、M值
rfm_2013 = recency.merge(frequency, on='Customer ID').merge(monetary, on='Customer ID')
# RFM值评级(大于平均值记为1,小于等于平均值记为0)
rfm_2013['R_Score'] = (rfm_2013['Recency'] <= rfm_2013['Recency'].mean()).astype(int)
rfm_2013['F_Score'] = (rfm_2013['Frequency'] > rfm_2013['Frequency'].mean()).astype(int)
rfm_2013['M_Score'] = (rfm_2013['Monetary'] > rfm_2013['Monetary'].mean()).astype(int)
rfm_2013['Customer_Segment'] = rfm_2013.apply(rfm_segment, axis=1) # 客户类型占比分析
segment_counts = rfm_2013['Customer_Segment'].value_counts(normalize=True) * 100 # 输出结果
print(segment_counts)

# 绘制客户类型占比分析图
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 8))
segment_counts.plot.pie(autopct='%1.1f%%', startangle=90)
plt.title('2013年客户价值类型占比分析')
plt.ylabel(' ')
plt.show()
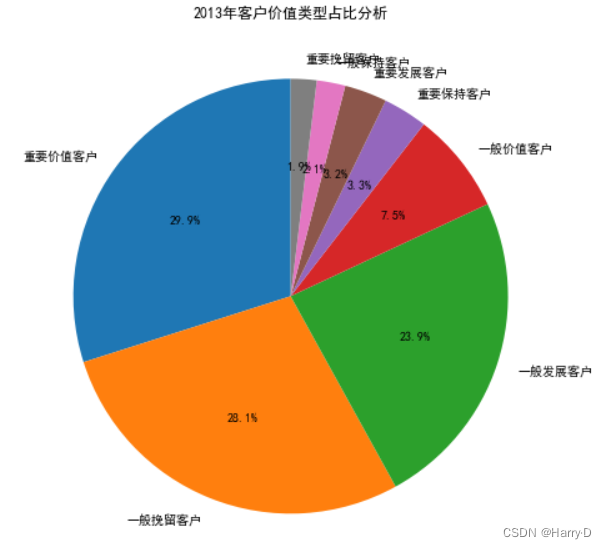
由上面的分析可知:对于该超市来说,重要价值客户和重要保
持客户的总和已经超过45%;但是一般发展客户的比例也很
高,这种客户很可能是刚注册的客户或者接近流失的客户,针
对刚注册的用户可以采取各种新人优惠福利,提高新客户了解
平台的动力,针对接近流失的客户应该追溯客户过去不满的原
因,对平台进一步完善。
十.客户群体与产品种类的关系分析
通过客户群体类别(Segment字段)与产品类别(Category字
段)分组,对销售额数据进行分析
df['Segment'] = df['Segment'].astype('category')
df['Category'] = df['Category'].astype('category')
grouped_data = df.groupby(['Category','Segment'])['Sales'].sum().reset_index()
grouped_data
# 创建 catplot
cat_plot = sns.catplot(x='Segment', y='Sales', hue='Category', kind='bar', data=grouped_data, dodge=True)
# 显示图形
plt.show()
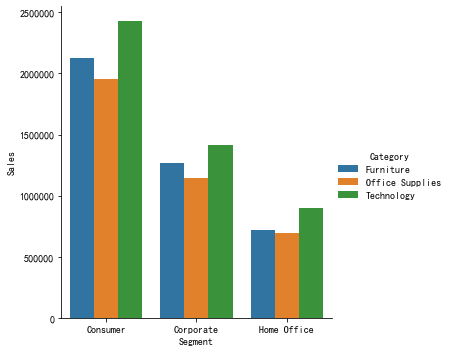
通过上图展示的结果可以看出,不同客户群体对各种产品的消
费额次序由高到低是: 科技产品(Technology)> 家具产品
(Furniture)>办公用品产品(Office Supplies)。因此,可
以2加大对科技产品的推广;在三种客户类型中,个人消费者
(Consumer)对各种产品的消费都是最高的,因此,可以保
持对个人消费者群体的策略;而居家办公群体(Home
Office)在三种产品的销售额较低,可以针对该用户群体进行
更好的营销推广
十一.发货时间与发货成本分析
提取发货日期字段(Ship Date字段)的年、月信息,并整理发货
年、发货月的销售总额,分析发货成本,并预测进货成本
temp = pd.to_datetime(df['Ship Date'], format='%m/%d/%Y',errors='coerce').fillna(
pd.to_datetime(df['Ship Date'], format='%d-%m-%Y',errors='coerce'))
df['Ship Date'] = temp.dt.date
df['Ship Date']
df['Ship-year'] = temp.dt.year
df['Ship-month'] = temp.dt.month
df[['Ship-year','Ship-month']]
sales_by_year_month = df.groupby(['Ship-year', 'Ship-month'])['Sales'].sum().reset_index()
shipping_costs = df.groupby(['Ship-year', 'Ship-month'])['Shipping Cost'].sum().reset_index()
# 合并销售额和运输成本数据
merged_data = pd.merge(sales_by_year_month, shipping_costs, on=['Ship-year', 'Ship-month'], suffixes=('_sales', '_shipping'))
# 创建透视表
pivot_table = pd.pivot_table(
merged_data,
values='Shipping Cost',
index='Ship-month',
columns='Ship-year',
fill_value=0
)
pivot_table
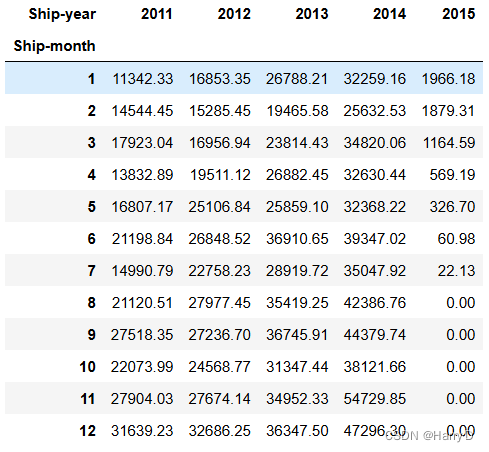
years = merged_data['Ship-year'].unique()
years
# 创建一个折线图
plt.figure(figsize=(12, 6))
years = merged_data['Ship-year'].unique()
for year in years:
data_year = merged_data[merged_data['Ship-year'] == year]
plt.plot(data_year['Ship-month'], data_year['Shipping Cost'], label=str(year))
plt.xlabel('月份')
plt.ylabel('发货成本')
plt.title('发货时间和发货成本的关系')
# 添加轻微的网格线
plt.grid(alpha=0.3)
plt.legend()
plt.show()
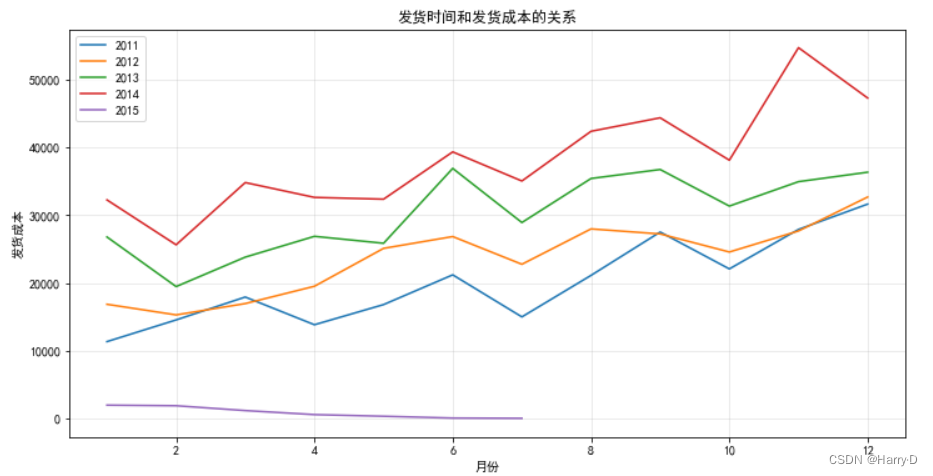
由上面的透视表和折线图可以看出,2011-2014年的发货成本
逐年上升,而且每年的各个月份的发货成本也呈上升趋势;但
是,2015年出现了新的情况!2015年只有7个月的统计数据,
但是这7个月的发货成本逐月降低,而且远远小于前4年的发货
成本,这很可能是由于2015年物流业的飞速发展使得发货成本
大大降低,所以,之后的进货成本也极有可能大大降低!















 1631
1631

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









