






Encoder-Decoder框架
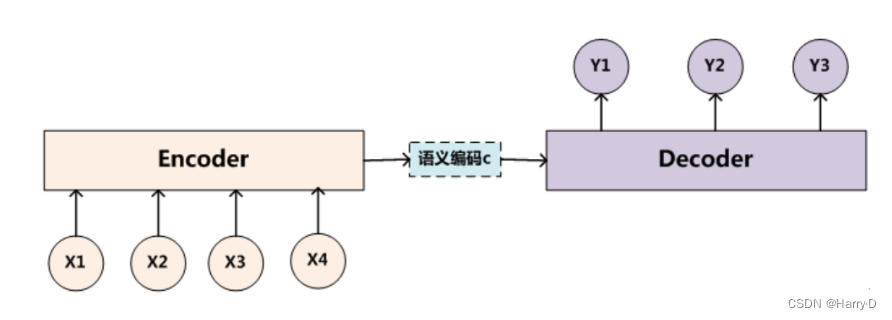
Encoder-Decoder框架是一种深度学习领域的研究模式,应用场景非常广泛。上图是文本处理领域里常用的Encoder-Decoder框架最抽象的一种表示。
文本处理领域的Encoder-Decoder框架可以这么直观地去理解:可以把它看作适合处理由一个句子(或篇章)生成另外一个句子(或篇章)的通用处理模型。对于句子对<Source,Target>,我们的目标是给定输入句子Source,期待通过Encoder-Decoder框架来生成目标句子Target。Source和Target可以是同一种语言,也可以是两种不同的语言。而Source和Target分别由各自的单词序列构成: 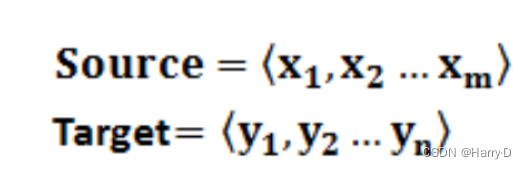
Encoder顾名思义就是对输入句子Source进行编码,将输入句子通过非线性变换转化为中间语义表示C:
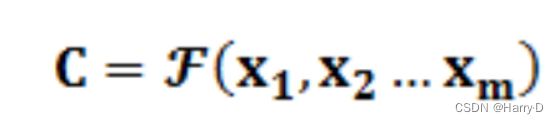
对于解码器Decoder来说,其任务是根据句子Source的中间语义表示C和之前已经生成的历史信息y1,y2,…yi-1来生成i时刻要生成的单词yi:
每个yi都依次这么产生,那么看起来就是整个系统根据输入句子Source生成了目标句子Target。如果Source是中文句子,Target是英文句子,那么这就是解决机器翻译问题的Encoder-Decoder框架;如果Source是一篇文章,Target是概括性的几句描述语句,那么这是文本摘要的Encoder-Decoder框架;如果Source是一句问句,Target是一句回答,那么这是问答系统或者对话机器人的Encoder-Decoder框架。由此可见,在文本处理领域,Encoder-Decoder的应用领域相当广泛。
Attention模型
引例:
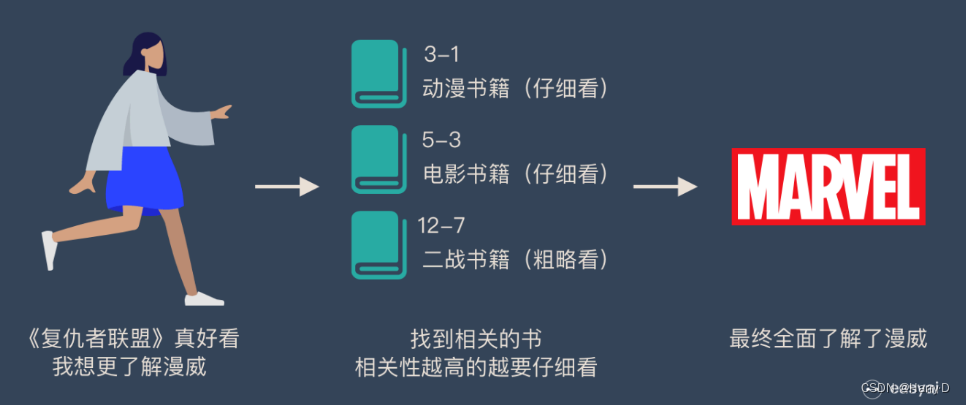
图书管(source)里有很多书(value),为了方便查找,我们给书做了编号(key)。当我们想要了解漫威(query)的时候,我们就可以看看那些动漫、电影、甚至二战(美国队长)相关的书籍。
为了提高效率,并不是所有的书都会仔细看,针对漫威来说,动漫,电影相关的会看的仔细一些(权重高),但是二战的就只需要简单扫一下即可(权重低)。当我们全部看完后就对漫威有一个全面的了解了。
Attention机制的本质思想:
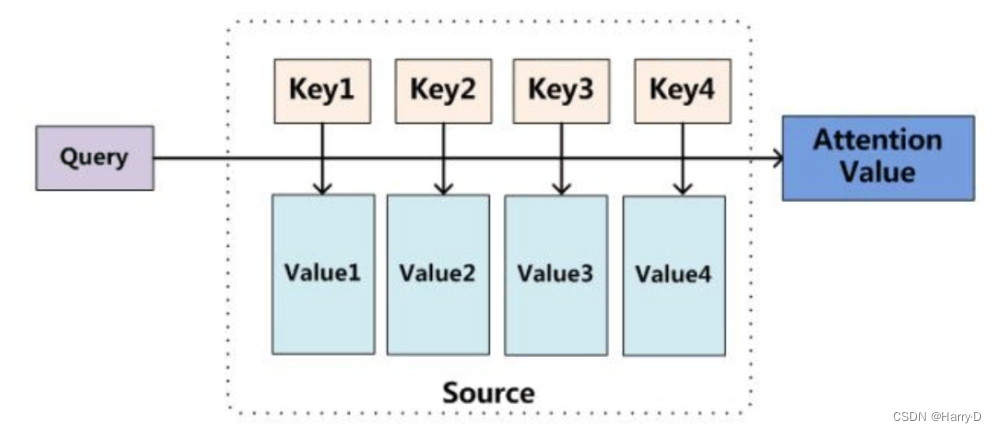
本质上Attention机制是对Source中元素(将Source中的构成元素想象成是由一系列的<Key,Value>数据对构成)的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。即可以将其本质思想改写为如下公式: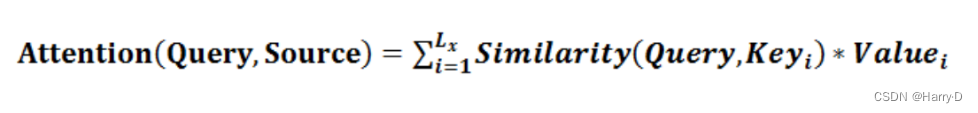
其中,Lx代表Source的长度,公式含义即如上所述。上文所举的机器翻译的例子里,因为在计算Attention的过程中,Source中的Key和Value合二为一,指向的是同一个东西,也即输入句子中每个单词对应的语义编码,所以可能不容易看出这种能够体现本质思想的结构。
Attention 原理的3步分解:
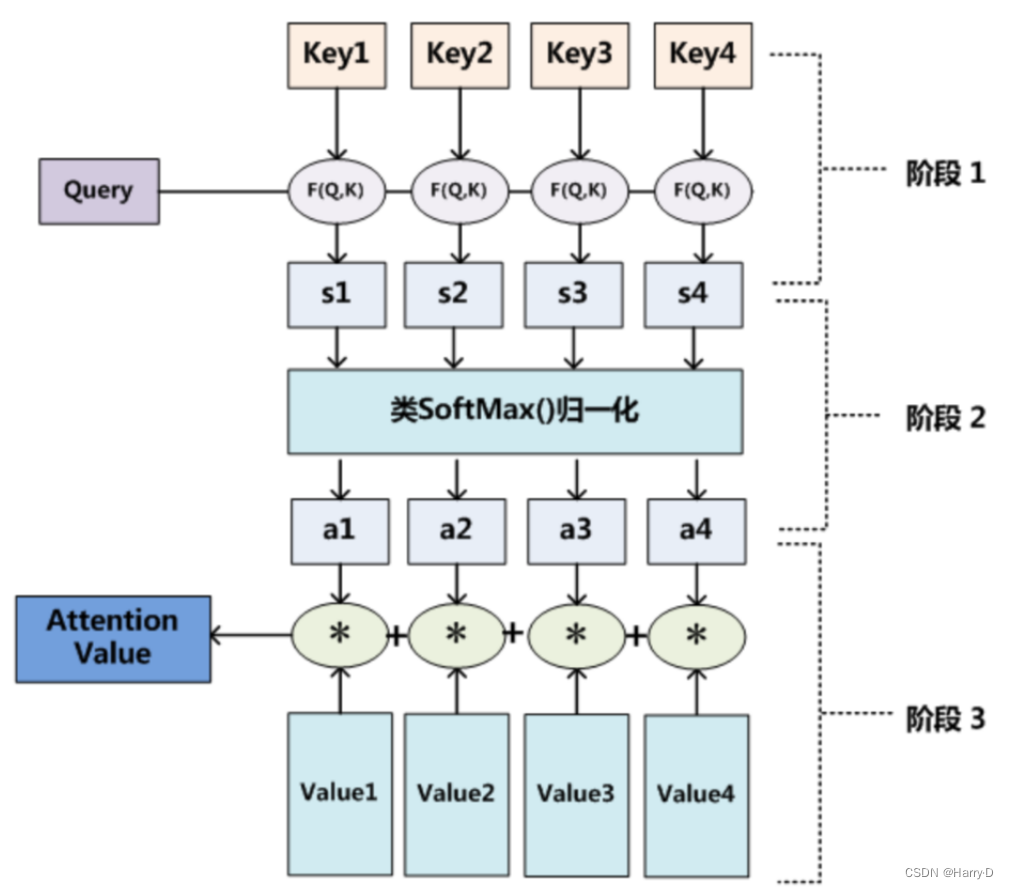
第一步: query 和 key 进行相似度计算,得到权值
第二步:将权值进行归一化,得到直接可用的权重
第三步:将权重和 value 进行加权求和
Self Attention自注意力模型
在一般任务的Encoder-Decoder框架中,输入Source和输出Target内容
是不一样的,比如对于英-中机器翻译来说,Source是英文句子,Target是
对应的翻译出的中文句子,Attention机制发生在Target的元素Query和
Source中的所有元素之间。而Self Attention顾名思义,指的不是Target和
Source之间的Attention机制,而是Source内部元素之间或者Target内部元
素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下
的注意力计算机制。其具体计算过程是一样的,只是计算对象发生了变化而
已。
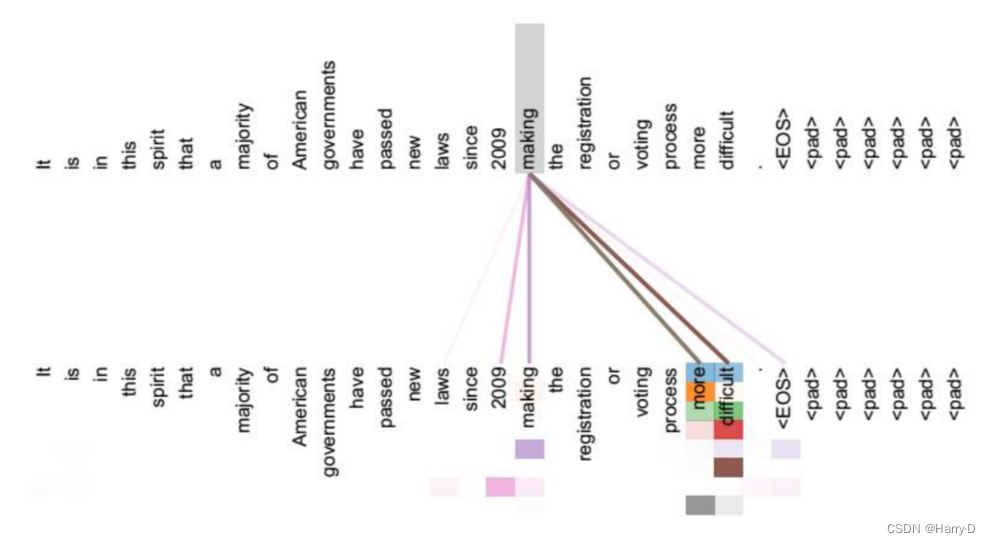
引入Self Attention后会更容易捕获句子中长距离的相互依赖的特征,因为如果是RNN或者LSTM,需要依次序序列计算,对于远距离的相互依赖的特征,要经过若干时间步步骤的信息累积才能将两者联系起来,而距离越远,有效捕获的可能性越小。
自注意力示例
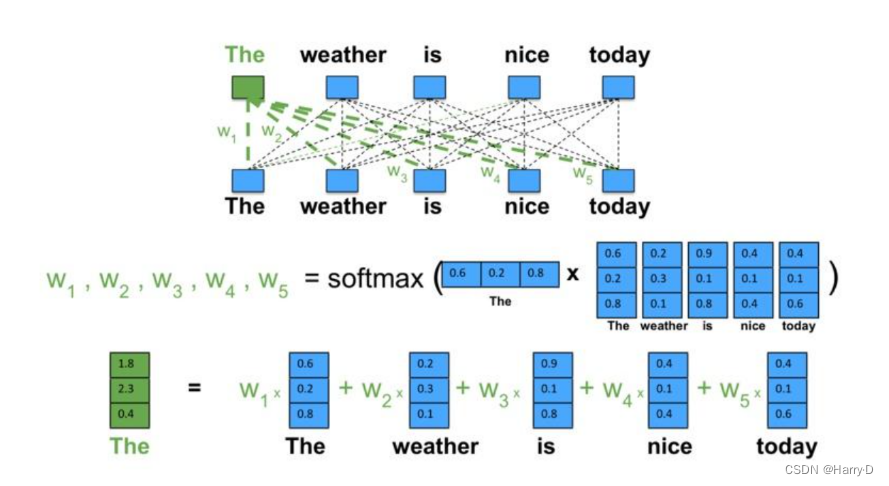
也就是说,The这个词的表示,实际上是整个序列加权求和的结果——权重从哪来?点积之后Softmax得到——这里Softmax(QK)就是求权重的体现。向量点积的值可以表征词与词之间的相似性,而此处的“整个序列”包括The这个词自己(再一次强调这是Self-Attention),所以最后输出的词的表示,其“主要成分”就主要地包含它自身和跟它相似的词的表示,其他无关的词的表示对应的权重就会比较低。
再看一例
The animal didn’t cross the street because it was too tired
这个句子中的 it 指的是什么?是指 animal 还是 street ?对人来说,这是一个简单的问题,但是算法来说却不那么简单。
当模型在处理 it 时,Self-Attention 机制使其能够将 it 和 animal 关联起来。
当模型处理每个词(输入序列中的每个位置)时,Self-Attention 机制使得模型不仅能够关注当前位置的词,而且能够关注句子中其他位置的词,从而可以更好地编码这个词。Transformer 使用 Self-Attention 机制将其他词的理解融入到当前词中。

Transformer模型
Transformer模型是在论文《Attention Is All You Need》里面提出来的,用来生成文本的上下文编码,传统的上下问编码大多数是由RNN来完成的,不过,RNN很难处理相隔比较远的两个单词之间的信息。
基本原理
Transformer 是一种使用注意力机制(attention mechanism)的神经网络模型,能够有效地处理序列数据,如句子或文本。
它的设计灵感来自于人类在理解上下文时的方式。
简单来说,Transformer 会将输入的序列分成若干个小块,并通过计算注意力得分来决定每个块在输出中的重要性。
它能够同时处理整个序列,而不需要依赖循环神经网络(RNN)等逐步处理的方法。
- Transformer模型中包含了多层encoder和decoder,每一层都由多个注意力机制模块和前馈神经网络模块组成。encoder用于将输入序列编码成一个高维特征向量表示,decoder则用于将该向量表示解码成目标序列。
- Transformer模型的核心是自注意力机制(Self-Attention Mechanism),其作用是为每个输入序列中的每个位置分配一个权重,然后将这些加权的位置向量作为输出。
详细过程参考文档:https://zhuanlan.zhihu.com/p/338817680















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









