










12月6日至10日,自然语言处理领域的国际顶级会议EMNLP(自然语言处理中的经验方法会议)在新加坡召开,研究人员、学者和业界专业人士齐聚一堂,展示和讨论该领域的最新研究成果、进展和创新。
会上公布了各项任务竞赛的获奖名单,深兰科技团队凭借丰富的经验,以多个预训练模型为基础,并结合多种自然语言处理技术,最终在“PragTag-2023”和“Violence Inciting Text Detection(VITD)”两项任务竞赛中脱颖而出,夺得了冠军。

PragTag-2023”任务竞赛
其中,“PragTag-2023”任务竞赛的要求,是在论文评审过程中,对同行评审内容中的每一句话,按照摘要、优点、不足、建议、结构、其他这六个类别进行分类,以实现评审内容细粒度的自动分类,并通过整合各方的评审意见,为经验不足的评审人提供评议帮助,该项任务的主要难点在于可参考的数据量少,缺少统一的分类标准。
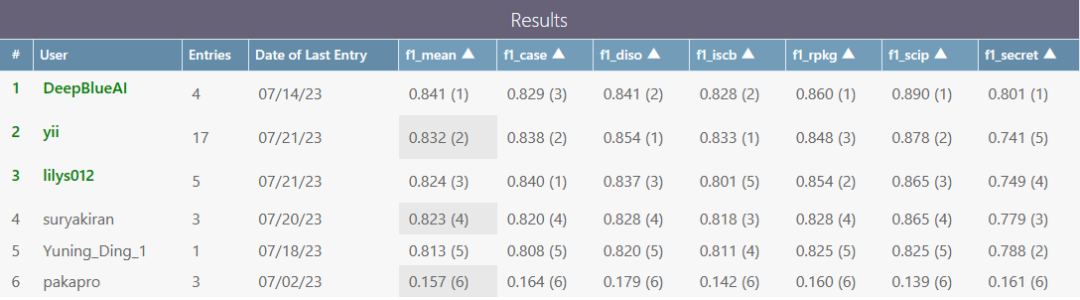
为此,深兰科技技术团队采用了两个出色的预训练模型“RoBERTa”和“DeBERTa”作为语言模型底座,在对其进行调整优化的基础上,同时融入了诸如注意力池化、最大池化、多折交叉验证、对抗训练等技术,并经过多组数据实验,通过使用多个模型投票得到结果的方式,解决了相关难题,赢得这项任务竞赛的冠军。
Violence Inciting Text Detection任务竞赛
“Violence Inciting Text Detection(暴力煽动文本检测)”任务竞赛的内容,则是检测社交媒体上的文本是否包含暴力信息,并按照主动暴力、被动暴力、非暴力三个类别做分类,目的是对发生在孟加拉国和印度西孟加拉邦的各种形式的社区暴力行为进行分类甄别,以及阐明发生这一复杂现象的缘由,并阻止同类事件的再次发生,缓解社会上的暴力倾向。
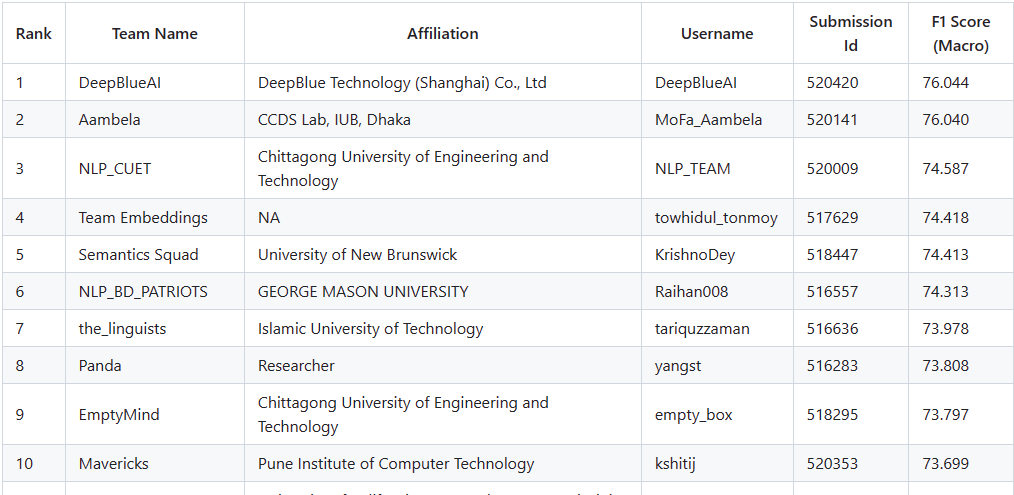
该任务的难点主要在于文本语言的特性,因为孟加拉语虽然有2亿多的使用人口,但本身还是属于小语种,使用范围小,可参考的文本数据也少,同时孟加拉语有着句子普遍超长、文本差异小、语意语境难以辨别的特点,这就对计算机自然语言处理技术有着更高的要求。
为了解决以上难题,深兰科技技术团队采用了“分而治之”的策略。针对小语种问题,团队选用了“XLM-RoBERTa”和“banglabert”两个与孟加拉语的语言特点相适配的预训练模型;为了解决句子超长的问题,则采用了多种裁剪策略分别进行实验,不断优化语句裁剪效果;为了提升语言预训练模型的鲁棒性,则通过在模型中加入注意力池化、最大池化、多折交叉验证、对抗训练、伪标签、multi-sample dropout等技术,以增强模型承受故障和干扰的能力。
最终,深兰科技团队以0.004分的优势,战胜了包括弗吉尼亚大学、加利福尼亚大学、詹姆斯库克大学等美国知名高校在内的来自全球的27支参赛队伍,夺得该任务竞赛的冠军。
关于EMNLP
EMNLP是计算机语言学和自然语言处理领域的顶级国际会议,由ACL旗下SIGDAT组织,每年举办一次,在Google Scholar计算语言学刊物指标中排名第二。















 283
283











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









