






一、abstract
为把人们所理解的自然语言让计算机也能够认识并且操作,需要将人的语言(即文字)转换成计算机的语言(即数字)
二 、词的两种表示方法
1.1离散表示(one-hot representation)
缺点:编码过程中并不考虑词的顺序,无法衡量词与词之间的关系
包括:
one-hot
bag of words
TF-IDF
N-gram
one-hot:
假设有一个词库,其大小为V,则词库中的每一个词可以用一个[V,1]的向量表示,在词库中,在出现该词的地方标记为1,其它地方标记为0,这样,每一个词就唯一表示为一个向量,但是这种表示方式受限于词库的大小,当词库过于庞大时,每一个one-hot向量的维度也会很大,对于计算机的存储和计算来说是灾难性的。而且这种表示无法度量词语之间的相似性。
举个例子:

缺点:词矩阵太稀疏,并且没有考虑词出现的频率。
Bag Of Words: 词袋模型,会统计词在语料中出现的次数

是one hot词向量的加和。用元素的频率表示文本的特征。
TF-IDF:是一种统计方法 用以评估一个词对于一个文本的重要程度
其中 TF是衡量一个词在文档中出现的多频繁
TF(t)=(t在文档中出现的次数)/(文档中总的词数)
IDF是衡量一个词有多重要
IDF(t)=log(文档总数/(包含有t的文档数+1))
TF-IDF =TF*IDF

词的重要性随着 词在文档中出现的次数正比增加,并且随着词在语料库中出现的频率呈反比下降。
即词在文本中出现的频率越高,而在其他文档中出现的频率越低 ,越能更好做分类。
N-gram,N代表是几元分词,(比如 如果是bi-gram就是二元分词, 用每两个相邻的词作为一个词作 构建向量)

离散表示具有的缺点:
1 词表维度随着语料库增长膨胀
2 n-gram词序列随着语料库膨胀更快
3 数据稀疏的问题
1.2分布式表示(distribution representation)
word embedding指的是将词转化成一种分布式表示,又称词向量。分布式表示将词表示成一个定长的连续的稠密向量。
分布式表示的优点
(1)可以表示词语之间的相似关系,这种相似关系包括自然语言中词语之间的顺序以及是否是同义词等
(2)词向量包含更多信息,并且每一维都有特定的含义。在采用one-hot特征时,可以对特征向量进行删减,词向量则不能。
包括:
共现矩阵
NNLM 神经网络语言模型
CBOW(continue bag of words)
skip-gram
共现矩阵: 主要用于发现主题,(n个词共同出现的次数),使用一个对称的局域窗,窗口的大小表示词左右的几个词,将共现矩阵的行 或者 列作为词向量,

缺点:
向量维数随词典大小线性增长 解决方法:降维 PCA SVD
存储整个词典所需空间消耗巨大
矩阵稀疏
NNLM: 神经网络语言模型 用前N个词去推测最后一个词


CBOW :用左右附近的词去推测中间的词,相比NNLM 去掉了隐层,用求和代替拼接。

skip-gram与CBOW完全相反的思路 ,是通过 当前这个词去预测其之前之后的词。

缺点:对多义词无法很好的表示。
三、如何生成词向量
以上离散表示和分布式表示可以说都是词向量的表示形式,常用的有:CBOW、skip-gram
生成词向量的方法有很多,这些方法都依照一个思想:任一词的含义可以用它的周边词来表示。生成词向量的方式可分为:基于统计的方法和基于语言模型(language model)的方法。这里主要讲解基于语言模型的方法。
两个重要模型
原理:拥有差不多上下文的两个单词的意思往往是相近的
1、Continuous Bag-of-Words(CBOW)
功能:通过上下文预测当前词出现的概率BOW的思想:
v(“abc”)=1/3(v(“a”)+v(“b”)+v(“c”))v(“abc”)=1/3(v(“a”)+v(“b”)+v(“c”))
原理分析:假设文本如下:“the florid prose of the nineteenth century.”
想象有个滑动窗口,中间的词是关键词,两边为相等长度(m,是超参数)的文本来帮助分析。文本的长度为7,就得到了7个one-hot向量,作为神经网络的输入向量,训练目标是:最大化在给定前后文本7情况下输出正确关键词的概率,比如给定("prose","of","nineteenth","century")的情况下,要最大化输出"the"的概率,
用公式表示就是P("the"|("prose","of","nineteenth","century"))
P("the"|("prose","of","nineteenth","century"))特性hidden layer只是将权重求和,传递到下一层,是线性的


Input layer
x1k,x2k,...,xCk表示上下文中的词语,每一个词用1个维数为1xV的one-hot向量表示,则input layer用向量INPUT_LAYER表示,其维数为CxV,在input layer和hidden layer中间有一个权重矩阵W,
INPUT_LAYER(CxV)xW(VxN)=HIDDEN_LAYER(CxN)
则HIDDEN_LAYER矩阵表示C个词语的分布式表示(词向量)
定义输出矩阵OUTPUT_LAYER(CxV),权重矩阵W'(NxV)
HIDDEN_LAYER(CxN)xW'(NxV)=OUTPUT_LAYER(CxV)
OUTPUT_LAYER(CxV)表示将某一个词作为中心词的概率
2、Skip-gram

功能:根据当前词预测上下文
原理分析
和CBOW相反,则我们要求的概率就变为P(Context(w)|w)P(Context(w)|w)
以上面的句子为例,数据集的构成,(input,output),(input,output)就是(the,prose),(the,of),(the,nineteenth),(the,century)(the,prose),(the,of),(the,nineteenth),(the,century)
损失函数
如果假设当前词为ww,那么可以写成P(wt+j|wt)(−m<=j<=m,j≠0)P(wt+j|wt)(−m<=j<=m,j≠0),每个词都会有一个概率,训练的目标就是最大化这些概率的乘积
也就是:L(θ)=∏(−m≤j≤m,j≠0)P(wt+j|wt;θ)L(θ)=∏(−m≤j≤m,j≠0)P(wt+j|wt;θ),表示准确度,要最大化
在概率中也经常有:J(θ)=−1TlogL(θ)=−1T∑Tt=1∑log(P(wt+j|wt;θ))J(θ)=−1TlogL(θ)=−1T∑t=1T∑log(P(wt+j|wt;θ)),加个负号就改成最小
概率示意P(o|c)=exp(uTovc)∑vw=1exp(uTwvc)P(o|c)=exp(uoTvc)∑w=1vexp(uwTvc)
vcvc:当cc为中心词时用vv
ucuc:当cc在ContextContext里时用uu
优点
在数据集比较大的时候结果更准确
四、word2vec的训练
以下这两个方法是训练技巧,目的是为了加速模型训练
hierarchical softmax,本质是把 N 分类问题变成 log(N)次二分类
negative sampling(负采样),本质是预测总体类别的一个子集
faq问答代码:
import gensim
import jieba
import numpy as np
from gensim.models import Word2Vec, word2vec
import json
import multiprocessing
def stopwordslist():
stopwords = [line.strip() for line in open('stopword.txt', 'r', encoding='utf-8').readlines()]
return stopwords
def main():
cnt = 0
question = {}
sentences_list = []
with open('train.json', 'r', encoding='utf-8') as f:
for line in f:
json_obj = json.loads(line)#获得train.json中的每一行,改行包含id,question,candidates,answer
question[cnt] = json_obj#question中存储train.json中一行所包含的所有信息,包含id,question,candidates,answer
sentences_list.append(question[cnt]['question'])#sentences_list中存储train.json中每行所对应的question的信息
cnt=cnt+1#cnt+1,下一个问题
#加载停用词
stopwords = stopwordslist()
#print(f"stopwords:{stopwords}")
# 结巴分词
sentences_cut = []
for ele in sentences_list:#对train.json中每个问题分词
cuts = jieba.cut(ele, cut_all=False)#cuts中存储问题分词后的列表,类似于['','','','',...]
new_cuts = []
for cut in cuts:#cut用于遍历cuts中的元素,类似于:''
if cut not in stopwords:#如果cut不在停用词中
new_cuts.append(cut)#new_cuts是cuts过滤掉停用词之后的结果
sentences_cut.append(new_cuts)#过滤掉停用词时候,将列表new_cuts加入到记录分词结果的sentences_cut列表中,其中每个元素都是一个列表
#print(f"sentences_cut:{sentences_cut}")
# 分词后的文本保存在data.txt中
with open('data.txt', 'w', encoding='utf-8') as f:
for ele in sentences_cut:#sentences_cut中每个元素都是一个列表
ele = ele + list('\n')
line = ' '.join(ele)#给ele中给个元素之间加一个' '
f.write(line)
# 可以用BrownCorpus,Text8Corpus或lineSentence来构建sentences,一般大语料使用这个
sentences = list(word2vec.LineSentence('data.txt'))#将data.txt中的数据转换成一个规范的列表
# sentences = list('data.txt')
# sentences = list(word2vec.Text8Corpus('data.txt'))
# 小语料可以不使用
# sentences = sentences_cut
print(f"sentences:{sentences}")
# 训练方式1
model = Word2Vec(sentences, min_count=1, window=5, sg=1, workers=multiprocessing.cpu_count())
print(f"model:{model}")
# 训练方式2
# 加载一个空模型
# model2 = Word2Vec(min_count=1)
# 加载词表
# model2.build_vocab(sentences)
# 训练
# model2.train(sentences, total_examples=model2.corpus_count, epochs=10)
# print(model2)
# 保存
# 方式一
# model.save('word2vec.model')
# 方式二
model.wv.save_word2vec_format('word2vec.vector')
model.wv.save_word2vec_format('word2vec.bin')
# 计算相似度
# sent1 = ['奇瑞', '新能源', '运营', '航天', '新能源汽车', '平台', '城市', '打造', '技术', '携手']
# sent2 = ['新能源', '奇瑞', '新能源汽车', '致力于', '支柱产业', '整车', '汽车', '打造', '产业化', '产业基地']
# sent3 = ['辉瑞', '阿里', '互联网', '医师', '培训', '公益', '制药', '项目', '落地', '健康']
# sent4 = ['互联网', '医院', '落地', '阿里', '健康', '就医', '流程', '在线', '支付宝', '加速']
#
# sim1 = model.wv.n_similarity(sent1, sent2)
# sim2 = model.wv.n_similarity(sent1, sent3)
# sim3 = model.wv.n_similarity(sent1, sent4)
#
# print('sim1', sim1)
# print('sim2', sim2)
# print('sim3', sim3)
# 词移距离
# distance1 = model.wv.wmdistance(sent1, sent2)
# distance2 = model.wv.wmdistance(sent1, sent3)
# distance3 = model.wv.wmdistance(sent1, sent4)
#
# print(distance1)
# print(distance2)
# print(distance3)
sent1 = '被车撞,对方负全责,我该找车主还是保险公司来买单?'
# 对用户提出的问题分词
new_cuts_first = []
cuts = jieba.cut(sent1, cut_all=False)
for cut in cuts:
if cut not in stopwords:
new_cuts_first.append(cut)
print(new_cuts_first)
#遍历train.json中的每一个问题
length = len(sentences_list)#sentences_list中存储train.json中每行所对应的question的信息
similar_max = 0
sign = -1
for i in range(length):
sent = sentences_list[i]
cuts = jieba.cut(sent, cut_all=False)
new_cuts_second = []
for cut in cuts:
if cut not in stopwords:
new_cuts_second.append(cut)
if len(new_cuts_first) != 0 and len(new_cuts_second) != 0:
similar = model.wv.n_similarity(new_cuts_first, new_cuts_second)
if similar >= similar_max:
similar_max = similar
sign = i
print(question[sign]["answer"])
print(sign)
if __name__ == '__main__':
main()上述faq问答的精确度不高,上述代码文本相似度计算调用的函数为:
similar = model.wv.n_similarity(new_cuts_first, new_cuts_second)
其计算的是两列单词之间的余弦相似度
将计算文本相似度调用的函数改为:
similarity=model.wv.cosine_similarities(vec1, vec2)
其中计算余弦相似度的函数可以自己定义,其定义如下:
def cos_sim(vector_a, vector_b):
"""
计算两个向量之间的余弦相似度
:param vector_a: 向量 a
:param vector_b: 向量 b
:return: sim
"""
vector_a = np.mat(vector_a)
vector_b = np.mat(vector_b)
num = float(vector_a * vector_b.T)
denom = np.linalg.norm(vector_a) * np.linalg.norm(vector_b)
sim = num / denom
return sim
余弦相似度
用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。
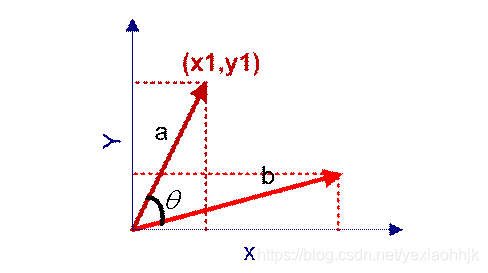
计算公式如下:

该公式中有一个错误的点,应该是最大化,而不是最小化
利用余弦相似度,可以得到以下基于余弦相似度计算文本相似度的代码:
import gensim
import jieba
import numpy as np
from gensim.models import Word2Vec, word2vec
import json
import multiprocessing
def stopwordslist():
stopwords = [line.strip() for line in open('stopword.txt', 'r', encoding='utf-8').readlines()]
return stopwords
def cos_sim(vector_a, vector_b):
"""
计算两个向量之间的余弦相似度
:param vector_a: 向量 a
:param vector_b: 向量 b
:return: sim
"""
vector_a = np.mat(vector_a)
vector_b = np.mat(vector_b)
num = float(vector_a * vector_b.T)
denom = np.linalg.norm(vector_a) * np.linalg.norm(vector_b)
sim = num / denom
return sim
def main():
cnt = 0
question = {}
sentences_list = []
with open('train.json', 'r', encoding='utf-8') as f:
for line in f:
json_obj = json.loads(line)#获得train.json中的每一行,改行包含id,question,candidates,answer
question[cnt] = json_obj#question中存储train.json中一行所包含的所有信息,包含id,question,candidates,answer
sentences_list.append(question[cnt]['question'])#sentences_list中存储train.json中每行所对应的question的信息
cnt=cnt+1#cnt+1,下一个问题
#加载停用词
stopwords = stopwordslist()
#print(f"stopwords:{stopwords}")
# 结巴分词
sentences_cut = []
for ele in sentences_list:#对train.json中每个问题分词
cuts = jieba.cut(ele, cut_all=False)#cuts中存储问题分词后的列表,类似于['','','','',...]
new_cuts = []
for cut in cuts:#cut用于遍历cuts中的元素,类似于:''
if cut not in stopwords:#如果cut不在停用词中
new_cuts.append(cut)#new_cuts是cuts过滤掉停用词之后的结果
sentences_cut.append(new_cuts)#过滤掉停用词时候,将列表new_cuts加入到记录分词结果的sentences_cut列表中,其中每个元素都是一个列表
#print(f"sentences_cut:{sentences_cut}")
# 分词后的文本保存在data.txt中
with open('data.txt', 'w', encoding='utf-8') as f:
for ele in sentences_cut:#sentences_cut中每个元素都是一个列表
ele = ele + list('\n')
line = ' '.join(ele)#给ele中给个元素之间加一个' '
f.write(line)
# 可以用BrownCorpus,Text8Corpus或lineSentence来构建sentences,一般大语料使用这个
sentences = list(word2vec.LineSentence('data.txt'))#将data.txt中的数据转换成一个规范的列表
# sentences = list('data.txt')
# sentences = list(word2vec.Text8Corpus('data.txt'))
# 小语料可以不使用
# sentences = sentences_cut
#print(f"sentences:{sentences}")
# 训练方式1
model = Word2Vec(sentences, vector_size=256,min_count=1, window=5, sg=1, workers=multiprocessing.cpu_count())
#print(f"model:{model}")
# 训练方式2
# 加载一个空模型
# model2 = Word2Vec(min_count=1)
# 加载词表
# model2.build_vocab(sentences)
# 训练
# model2.train(sentences, total_examples=model2.corpus_count, epochs=10)
# print(model2)
# 保存
# 方式一
model.save('word2vec.model')
# 方式二
model.wv.save_word2vec_format('word2vec.vector')
model.wv.save_word2vec_format('word2vec.bin')
# 计算相似度
# sent1 = ['奇瑞', '新能源', '运营', '航天', '新能源汽车', '平台', '城市', '打造', '技术', '携手']
# sent2 = ['新能源', '奇瑞', '新能源汽车', '致力于', '支柱产业', '整车', '汽车', '打造', '产业化', '产业基地']
# sent3 = ['辉瑞', '阿里', '互联网', '医师', '培训', '公益', '制药', '项目', '落地', '健康']
# sent4 = ['互联网', '医院', '落地', '阿里', '健康', '就医', '流程', '在线', '支付宝', '加速']
#
# sim1 = model.wv.n_similarity(sent1, sent2)
# sim2 = model.wv.n_similarity(sent1, sent3)
# sim3 = model.wv.n_similarity(sent1, sent4)
#
# print('sim1', sim1)
# print('sim2', sim2)
# print('sim3', sim3)
# 词移距离
# distance1 = model.wv.wmdistance(sent1, sent2)
# distance2 = model.wv.wmdistance(sent1, sent3)
# distance3 = model.wv.wmdistance(sent1, sent4)
#
# print(distance1)
# print(distance2)
# print(distance3)
sent1 = '被车撞,对方负全责,我该找车主还是保险公司来买单?'
sent2='我出车祸,对方全责,对方应该样理赔我'
sent3='您好,我产假将结束时被公司劝退,公司答应给赔偿金,但是签订的赔偿协议金额不对,有进行了第二次谈话,公司人事经理承认有差额答应给我,可是现在又不承认有差额了,这种情况我可以申请仲裁吗?'
# 对用户提出的问题分词
new_cuts_first = []
cuts = jieba.cut(sent3, cut_all=False)
for cut in cuts:
if cut not in stopwords:
new_cuts_first.append(cut)
print(new_cuts_first)
vec1=np.zeros_like(model.wv[str(new_cuts_first[0])])
for i in range(len(new_cuts_first)):
word1=new_cuts_first[i]
if word1!='\n' and word1!='\r\n':
vec1=vec1+np.array(model.wv[word1])
vec1=1.0/len(new_cuts_first)*vec1
length=len(sentences_list)
similarity_max=0
sign=-1
for i in range(length):
sent = sentences_list[i]
cuts = jieba.cut(sent, cut_all=False)
new_cuts_second = []
for cut in cuts:
if cut not in stopwords:
new_cuts_second.append(cut)
#计算用户提出的问题和train.json中question的词向量cos_similarity
#文本词向量用文本分词词向量的均值代替
vec2 = np.zeros((256))
for j in range(len(new_cuts_second)):
word1 = new_cuts_second[j]
if word1!='\n' and word1!='\r\n':
vec2 = vec2 + np.array(model.wv[word1])
if len(new_cuts_second)!=0:
vec2 = 1.0/len(new_cuts_second)*vec2
similarity=cos_sim(vec1,vec2)
if similarity>similarity_max:
similarity_max=similarity
sign=i
print(f"similarity_max:{similarity_max}")
print(question[sign]["answer"])
print(sign)
if __name__ == '__main__':
main()














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









