







一、实验目的:
1.掌握对中文语料进行预处理的方法。
2.掌握使用Word2Vec模型进行词向量训练的方法。
3.掌握使用Word2Vec模型计算词向量之间的相似度的方法。
二、实验设备及分组
1. PC机或笔记本电脑若干;
2. Window 7及以上版本操作系统;
3. Python 运行环境;
4.安装和配置Anaconda。
三、实验任务及要求:
实验任务:
1.使用文件夹“20190102”里的《人民日报》每日新闻的语料进行预处理,并使用Word2Vec模型实现词语的向量化。
2.输出'努力'和'建设'这2个词的相似度,并找出与'努力'这个词最相似的10个词语。
3.保存训练后词向量模型。
4.保存处理好的数据集。
实验要求:
1.会利用jieba分析进行文本的切分。
2.会利用gensim库中的函数训练词向量。
3.整理数据,撰写实验报告。
四、实验过程及实验步骤:
注意修改文件的位置
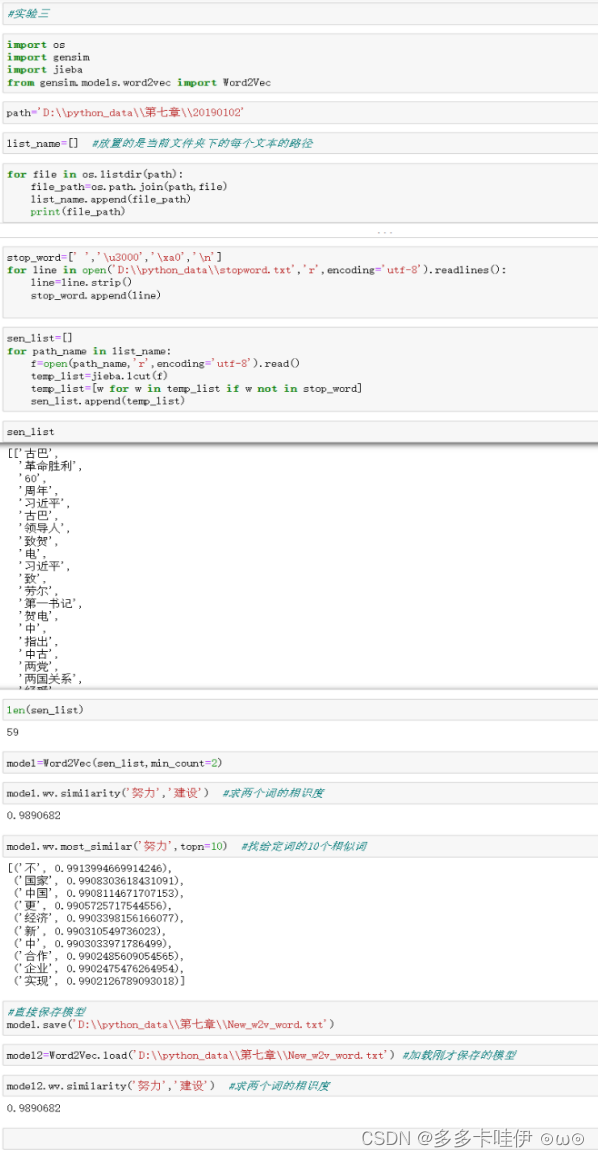

import os
import gensim
import jieba
from gensim.models.word2vec import Word2Vec
path='D:\\python_data\\第七章\\20190102'
list_name=[] #放置的是当前文件夹下的每个文本的路径
for file in os.listdir(path):
file_path=os.path.join(path,file)
list_name.append(file_path)
print(file_path)
stop_word=[' ','\u3000','\xa0','\n']
for line in open('D:\\python_data\\stopword.txt','r',encoding='utf-8').readlines():
line=line.strip()
stop_word.append(line)
sen_list=[]
for path_name in list_name:
f=open(path_name,'r',encoding='utf-8').read()
temp_list=jieba.lcut(f)
temp_list=[w for w in temp_list if w not in stop_word]
sen_list.append(temp_list)
len(sen_list)
model=Word2Vec(sen_list,min_count=2)
model.wv.similarity('努力','建设') #求两个词的相识度
model.wv.most_similar('努力',topn=10) #找给定词的10个相似词
#直接保存模型
model.save('D:\\python_data\\第七章\\New_w2v_word.txt')
#加载刚才保存的模型
model2=Word2Vec.load('D:\\python_data\\第七章\\New_w2v_word.txt') model2.wv.similarity('努力','建设') #求两个词的相识度
f=open('D:\\python_data\\第七章\\201902w2v_word.txt','w',encoding='utf-8')
for text in sen_list:
f.write(' '.join(text)+'\n')
f.close() #每一行是一个文本,每一行的词必须空格进行连接
from gensim.models.word2vec import LineSentence
sentences=LineSentence('D:\\python_data\\第七章\\201902w2v_word.txt')
list(sentences)














 9068
9068











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









