







预备知识:欧式距离与余弦相似度计算方法
1、欧式距离
随机取出两个词向量A和B,A的词向量表示为[A1,A2,A3…An],B的词向量表示为[B1,B2,B3…Bn]。对于词向量A和B,其欧式距离计算公式如下:
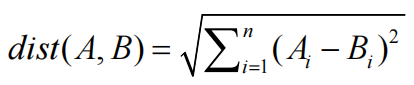
2、余弦相似度
对于词向量A和B,其余弦相似度计算公式如下:

词向量的内在联系
词向量可以表示单词间的内在联系,即两个单词的词向量通过计算可以得出其关联程度,词向量相似度计算公式主要有:欧氏距离、余弦相似度、Jaccard距离、编辑距离等几种,本文主要介绍欧式距离与余弦相似度。
首先我们提出两个问题:
- 为什么词向量可以通过欧式距离和余弦相似度得出单词间的内在联系。
- 欧式距离和余弦相似度的差别又是什么。
接下来我们对此进行解析。
1、直观理解
根据word2vec的同义可替换原则,某两个单词的上下文单词相同,训练出来的这两个单词的词向量也相近,所以可以使用欧式距离和余弦相似度表示词汇之间的关联程度。
以下面两个句子为例,采用skip-gram方法训练模型:
1.The cat stayed well out of range of the children.
2.The dog stayed well out of range of the children.
用cat和dog作为数据分别预测the、stayed、well 这三个单词,当反向传播更新参数时,因为其预测的单词相同,更新参数后其词向量也会更加相似。
2、公式解析
某两个词汇的词向量欧式距离转换如下:
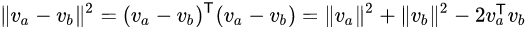
如果设它们都是单位向量,则
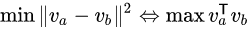
我们神经网络训练的过程就是最小化其欧式距离,最大化其余弦值,即我们可以使用欧式距离和余弦值表示单词相似度。
3、欧式距离和余弦相似度比较
欧式距离注重两个词向量位置的差异,余弦相似度更看重两个词向量在方向上的差异。
如下图所示,欧式距离dist(A,B)表示词向量的空间距离,余弦cosθ显示词向量在方向上的差距。

举个例子:
X和Y用户对两个内容评分,按5分制,X用户对内容1和内容2的评分分别为1和4,Y用户对内容1和内容2的评分分别为2和5。令A=[1,2],B=[4,5]。此时dist(A,B)=4.24,在5分制的评级中,该距离较大,表示用户对内容1和2的总体看法区别较大。cosθ=0.99,余弦相似度较大,表示两个用户的偏好基本一致,即相对于内容1,两个用户都稍加喜欢内容2。
基于余弦算法的词汇相似度比较
1、任务介绍
- 网上下载 http://nlp.stanford.edu/data/glove.6B.zip ,选取其中300d维度的预训练词向量。
- 里面一共有40万大小的词表,词表中每一个词,都和词表中的其它所有词计算余弦相似度,也就是说计算次数应该是(40万 x 40万)级别的。
- 词表中的每一个词,根据第二步计算的结果,找出和其最相似的100个词,即每个词都要返回一个100词的list。
(因为本人电脑配置的显卡为1050ti,如此庞大的数据,我的电脑无法计算出其欧式距离,所以这里只计算其余弦相似度)
2、公式变更
原始计算公式为:
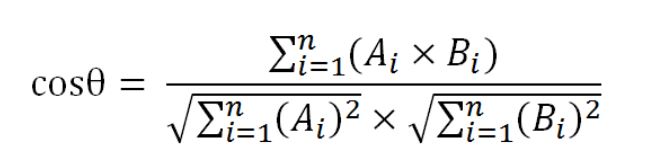
我们的任务是找出每个词最相似的100个词,即我们的任务是计算每个词与另外40万个词(同时计算自身的相似度,作为检验)的余弦值,并取其最大的100个余弦值对应的词汇作为最终结果进行保存。计算某个词与另外40w个词的余弦相似度时,其
∑
i
=
1
n
(
A
i
)
2
\sqrt {\sum\nolimits_{i = 1}^n {{{({A_i})}^2}} }
∑i=1n(Ai)2值是相同的,并不影响计算结果的排序,所以我们计算过程中可以将其省略。
即计算公式变更为:
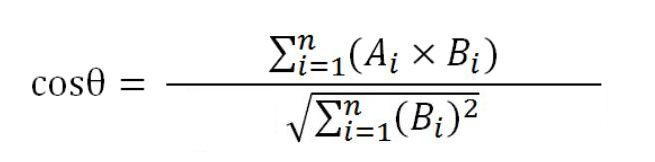
3、计算过程
对于40万 x 40万级别的运算量,本人无法一次性对其进行矩阵计算(gpu显存不足),所以多处使用分块的思想。
每个单词用长度为300的词向量进行表示,所以总数据可以表示为[40w,300]大小的矩阵。
总体运算为:[40w,300]大小的词向量矩阵与其转置矩阵相乘,生成大小为[40w,40w]的矩阵,此矩阵再除以每个词向量对应的
∑
i
=
1
n
(
B
i
)
2
\sqrt {\sum\nolimits_{i = 1}^n {{{({B_i})}^2}} }
∑i=1n(Bi)2值,再计算并取出每一行最大的100个数及其对应词表中的单词,最后将这100个单词保存到本地。
分块计算过程如下:
- 将[40w,300]大小的矩阵按行拆分为1000个大小为[400,300]的矩阵,即每次只计算400个单词的相似词。
- 拆分为[400,300]的矩阵后,用其与原始矩阵的转置矩阵相乘其计算量仍然过大。我们将大小为[300,40w]的转置矩阵按列拆分40个[300,1w]大小的矩阵。
- [400,300]大小的矩阵与40个[300,1w]大小的矩阵分别相乘后除以各自对应的 ∑ i = 1 n ( B i ) 2 \sqrt {\sum\nolimits_{i = 1}^n {{{({B_i})}^2}} } ∑i=1n(Bi)2,再将其拼接。
- 拼接后的矩阵大小为[400,40w],每行对应的为其公式变更后的余弦相似度计算结果,我们计算并取出每一行最大的100个数对应的词。此处我们再次进行拆分,将其拆分为8个[50,40w]大小的矩阵,即我们每次只计算出50个单词对应的最相似的100个词,这里我们使用torch的argsort进行全排序后取出最大的101个数(每个词与其最相似的为其本身,所以多取1个)对应的位置。40w个数据取出前100,按道理来说使用python编写大顶堆取数会更快,实际上因为python本身的特点(只考虑快速开发,而忽略其运行速度),以及torch可调用gpu进行并行运算,使用torch自带的argsort进行全排序反而会更快。
- 将该101个位置的词取出,形成大小为[50,101]的矩阵。拼接8次,组成大小为[400,101]的矩阵,矩阵中包含400个原始词及与之对应最相似的100个词,将该数据保存到本地。
- 每次只计算并保存400个单词的相似词,迭代1000次完成40w词的计算任务后,结束运行,完成任务。
完整代码
import torch
import pandas as pd
class Similarity():
def __init__(self,filename):
self.book=1#用于后期存储文件时的命名
self.device='cuda' if torch.cuda.is_available() else 'cpu'#如果电脑有gpu则使用gpu,否则使用cpu
self.filename=filename#文件名
self.word=[]#保存40w词序列
self.take_word()#获得字符序列
def take_word(self):#字符序列获取函数
self.frword = open(self.filename,'r',encoding='UTF-8')#frword:读取数据文件
for lineWord in self.frword.readlines():
self.word.append(lineWord.split(" ")[0])#获取40w词序列
self.frword.close()#关闭文件
def serch_and_save(self):#存储数据
self.nearWord=[]#保存相似词
#对于任意单词,其余弦最大值为本身,所以取101个数,第一个数为其本身。
for line in range(0,self.seqResult.size()[0],50):#每次取50个单词进行排序,共取8次
#此处可考虑使用大顶堆代替argsort函数,减少时间复杂度.pytorch内核代码为c++编写,且考虑到并行机制,单纯使用python语言写堆排序求topk反而会降低求解速度(本人亲测)
self.sortedResult=torch.argsort(self.seqResult[line:line+50],dim=1,descending=True)[:,0:101]
for i in range(self.sortedResult.size()[0]):
self.midWord=[]
for j in range(self.sortedResult.size()[1]):
self.midWord.append(self.word[self.sortedResult[i,j]])
self.nearWord.append(self.midWord)
self.data= pd.DataFrame(self.nearWord, columns=["原始单词"]+["第%d相似"%(i) for i in range(1,len(self.nearWord[0]))])#形成列表文件
self.data.to_csv('./data%d.csv'%(self.book),columns=None)#保存数据
self.book+=1
"""
该问题可归纳为40w*300和300*40w大小的矩阵相乘,再除以||B||,然后取矩阵每一行最大的100个数字的问题
40w*40w的矩阵乘法,先将其切分为1000个400*40w的矩阵乘法,
对每一个400*40w的矩阵乘法,再将其切分为40个400*1w的矩阵乘法
记左矩阵为A,右矩阵为B
"""
def calculation(self):
self.frA = open(self.filename,'r',encoding='UTF-8')#frA:读取A矩阵文件
self.lengthA=0#记录A矩阵的长度
self.seqA=[]#存储A矩阵的数据
for lineA in self.frA.readlines():
self.seqA.append([float(i) for i in lineA.split(" ")[1:]])#读取一列数据,即读取某一字符的全部数据
self.lengthA+=1
if self.lengthA%400==0:#左矩阵每取400词的数据,进行1次400*40w的矩阵乘法,取出该400词中最相似(即计算结果最大)的100词
self.lengthB=0#记录B矩阵的长度
self.seqB=[]
self.seqResult=torch.tensor([])#存储400个字符的所有余弦值,用于后期求最相似的100个词
self.seqA=torch.tensor(self.seqA).to(self.device)
self.frB = open(self.filename,'r',encoding='UTF-8')#frB:读取B矩阵文件
for lineB in self.frB.readlines():
self.seqB.append([float(i) for i in lineB.split(" ")[1:]])
self.lengthB+=1
if self.lengthB%10000==0:#右矩阵每取10000个数据进行一次400*1w的矩阵运算,总共运算40次,即最终为400*40w的矩阵
self.seqB=torch.tensor(self.seqB).to(self.device)
self.tranB=torch.transpose(self.seqB,0,1)#进行转置,用于A*B
#接下来几步计算:||B||(因为只需求最相似的100个词,对于同一个词,其||A||是相同的,所以不用除以||A||)
self.mulB=self.tranB*self.tranB#平方
self.sumB=torch.sum(self.mulB,dim=0)#相加
self.sqrtB=torch.sqrt(self.sumB)#开方
if self.seqResult.size()[0]==0:
self.seqResult=torch.mm(self.seqA,self.tranB)/self.sqrtB#矩阵相乘后除以||B||
else:
self.mid=torch.mm(self.seqA,self.tranB)/self.sqrtB
#通过拼接,不断存入400*1w的运算结果,最终形成400*40w的矩阵
self.seqResult=torch.cat((self.seqResult,self.mid),1)
self.seqB=[]#用于取新值,运算结果已经保存到self.seqResult
self.frB.close()
if self.lengthA%4000==0:#每取4000个词,保存其中800个词,共将80000个词保存到100个文件上
self.serch_and_save()#保存数据
self.seqA=[]#归0,重新取400个词
torch.cuda.empty_cache()#释放显存
self.frA.close()
if __name__== '__main__':
s_word=Similarity('data\glove.6B.300d.txt')
s_word.calculation()
运行结果
运行完成后,取出部分结果进行查看。对于原始单词,计算出的相似度较大的单词与原始单词实际上关联也比较密切,甚至不少单词与原始单词只是单复数的区别。

参考资料
1、https://www.zhihu.com/question/361999946/answer/1019671032(公式理解)
2、http://www.cxyzjd.com/article/qq_28851503/97616249(计算方法讲解)
3、https://www.cnblogs.com/bymo/p/8489037.html(欧式距离和余弦相似度比较)















 3098
3098











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









