







Hadoop运行环境搭建
一、Linux环境准备
1.搭建模板虚拟机
(1)相关软件下载
虚拟机运行环境:VMware-workstation-full-16.2.2-19200509.exe
映像文件:CentOS-7-x86_64-DVD-2009.iso
远程登录工具:Xshell-7.0.0090.exe
Xftp传输工具:Xftp-7.0.0111p.exe
(2)模板虚拟机安装(略)
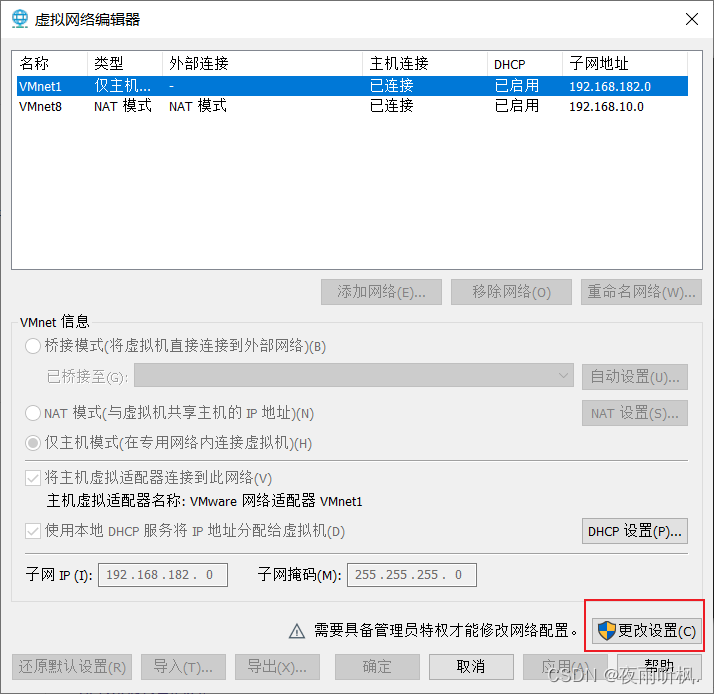
(3)查看当前网络信息
查看修改VMware网络信息
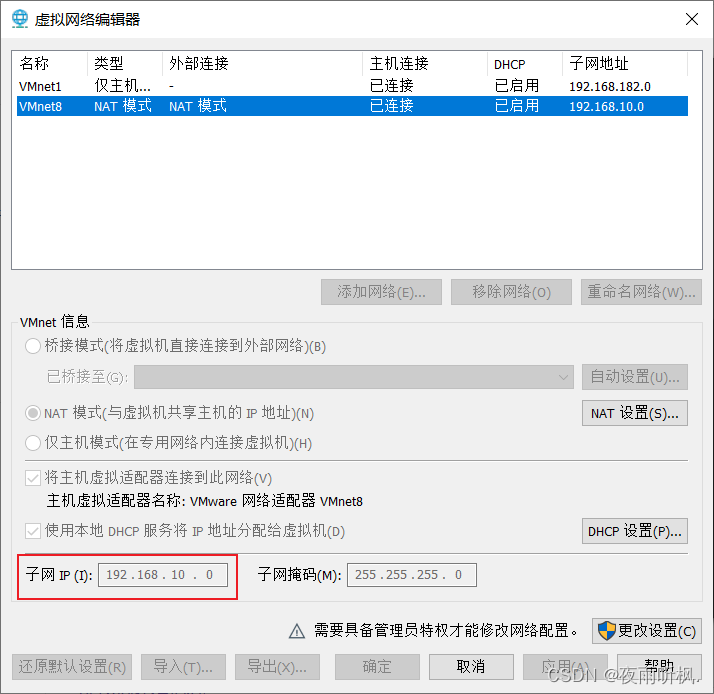
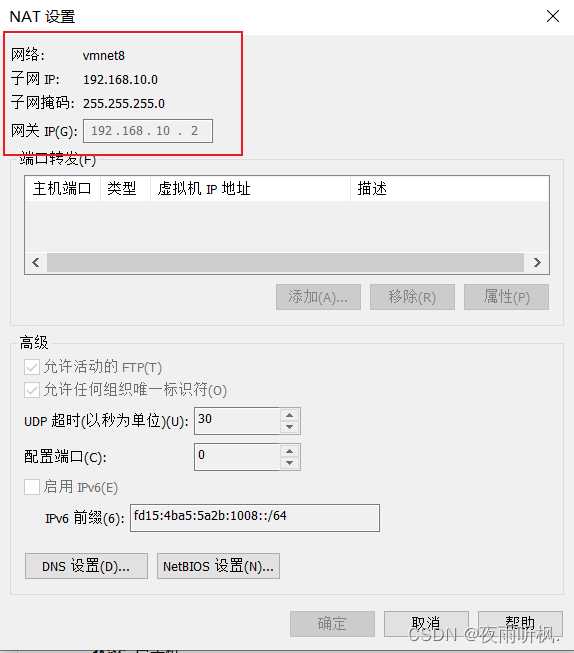
查看网关ip
如需更改网段,点击更改设置
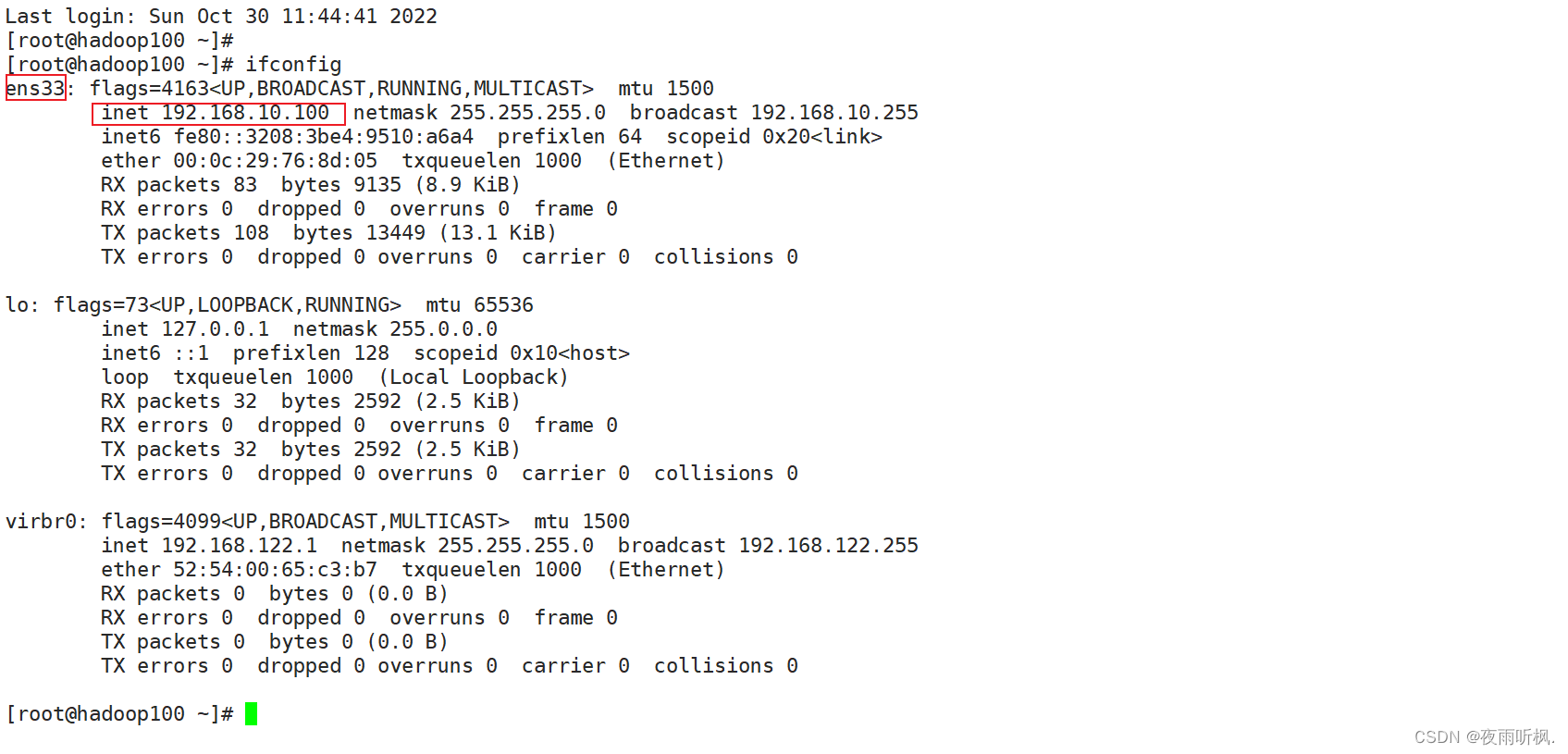
输入命令:ifconfig,查看当前网络ip
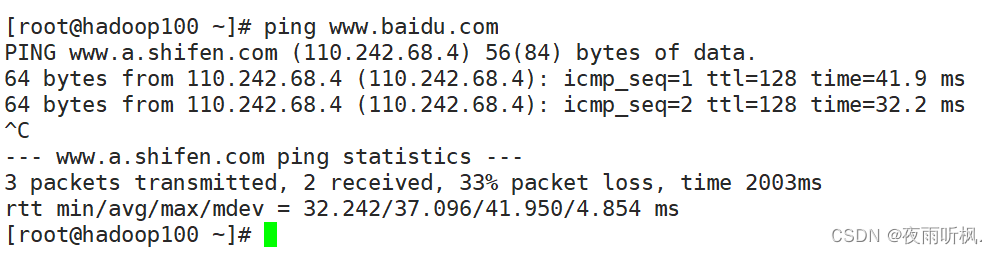
测试当前服务器是否可以连接百度
(4)修改ip地址
- 查看ip配置文件
[root@hadoop100 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
- 修改ip配置信息
- 将dhcp自动分配模式改为static
- 添加ip地址,网络类型、网络范围和网络位(即ip地址前三部分)必须和虚拟网络编辑器中相同,主机位(最后一部分)自定义,这里用192.168.10.100。
- 添加网关和域名解析器,和虚拟网络编辑器中相同。

3. 重启网络
[root@hadoop100 ~]# service network restart
Restarting network (via systemctl): [ 确定 ]
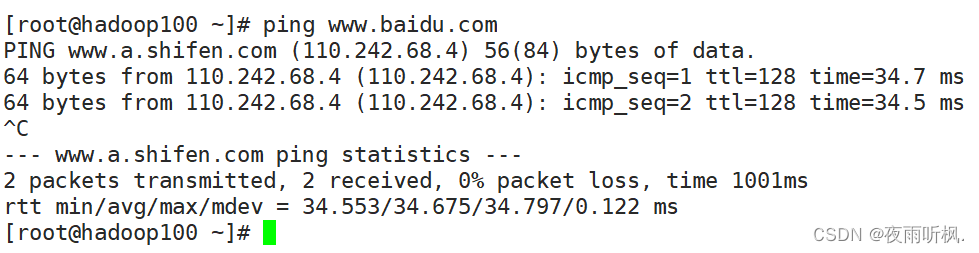
再次查看网络ip,确定ip地址修改成功,并测试能否连接外网

(5)修改主机名和hosts映射文件
- 查看主机名
[root@hadoop100 ~]# hostname
hadoop100
- 如果想要修改主机名,可以通过编辑/etc/hostname 文件
[root@hadoop100 ~]# vim /etc/hostname

3. 修改hosts映射文件
后续在hadoop阶段虚拟机比较多,每次访问类似192.168.10.100的ip地址比较麻烦,通常会采用主机名的方式进行配置。
- 打开/etc/hosts
[root@hadoop100 ~]# vim /etc/hosts
- 添加如下内容(多添加几个,为搭建集群做准备)
192.168.10.100 hadoop100
192.168.10.101 hadoop101
192.168.10.102 hadoop102
192.168.10.103 hadoop103
192.168.10.104 hadoop104
192.168.10.105 hadoop105
192.168.10.106 hadoop106
192.168.10.107 hadoop107
- 修改windows的hosts文件
windows的hosts文件路径在C:\Windows\System32\drivers\etc,打开hosts文件并添加如下内容并保存。
如果无法保存成功,可以复制一个hosts文件到别的路径下,修改完成后覆盖原文件。
192.168.10.100 hadoop100
192.168.10.101 hadoop101
192.168.10.102 hadoop102
192.168.10.103 hadoop103
192.168.10.104 hadoop104
192.168.10.105 hadoop105
192.168.10.106 hadoop106
192.168.10.107 hadoop107
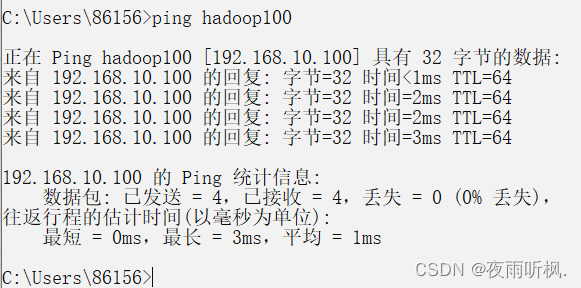
打开命令提示符窗口,测试直接ping主机名,如果成功,说明修改完成。
(6)关闭防火墙,防止防火墙开机自启动
[root@hadoop100 ~]# systemctl stop firewalld
[root@hadoop100 ~]# systemctl disable firewalld.service
(7)创建一个普通用户,方便后期登录普通用户加sudo命令执行root权限
- 创建用户并修改密码
useradd user
passwd user - 修改配置文件,让user用户具有root权限
[root@hadoop100 ~]# vim /etc/sudoers
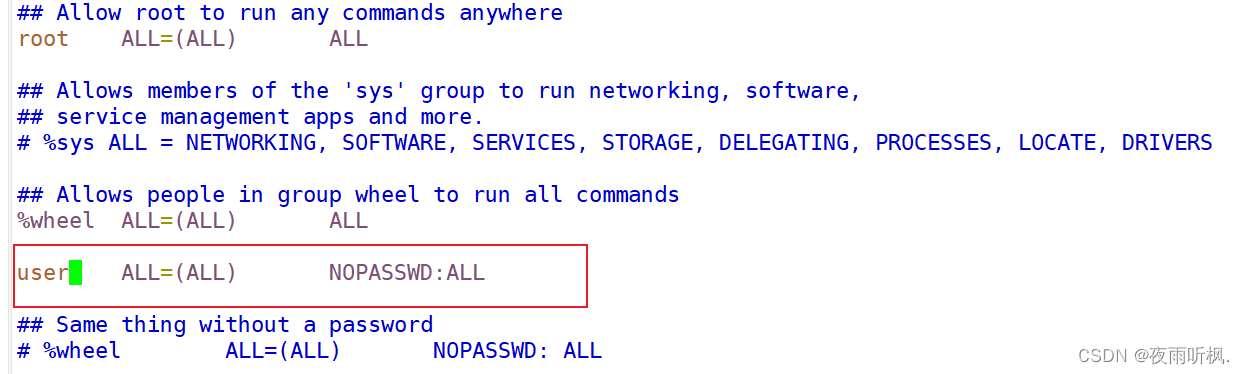
注意:user这一行必须放在%wheel这一行下面,因为所有用户都属于wheel组,如果先配置了user的权限和免密登陆,当执行到wheel这一行,权限和功能又会被覆盖。
(8)创建在/opt下创建两个文件夹并修改所属主和所属组
- 创建module和software文件夹`
[root@hadoop100 ~]# mkdir /opt/module
[root@hadoop100 ~]# mkdir /opt/software
- 修改新创建的文件夹所属主和所属组为user用户
[root@hadoop100 ~]# chown user:user /opt/module
[root@hadoop100 ~]# chown user:user /opt/software
- 查看module和software的所属主和所属组
[root@hadoop100 opt]# ll
总用量 55136
-rw-r--r--. 1 root root 0 10月 25 20:24 hello
drwxr-xr-x. 2 user user 6 10月 29 17:58 module
drwxr-xr-x. 2 root root 6 10月 31 2018 rh
drwxr-xr-x. 2 user user 6 10月 29 17:59 software
drwxr-xr-x. 4 root root 47 10月 27 19:15 test
-rw-------. 1 root root 56457489 7月 18 2020 VMwareTools-10.3.23-16594550.tar.gz
drwxr-xr-x. 9 root root 145 7月 18 2020 vmware-tools-distrib
[root@hadoop100 opt]#
(9)安装epel-release
Extra Packages for Enterprise Linux是为“红帽系”的操作系统提供额外的软件包,适用于RHEL、CentOS和Scientific Linux,相当于是一个软件仓库。
[root@hadoop100 ~]# yum install -y epel-release
(10)卸载虚拟机自带的jdk
[root@hadoop100 ~]# rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
重启虚拟机
[root@hadoop100 ~]# reboot
2.克隆虚拟机
(1)用创建好的模板机hadoop100克隆三台虚拟机hadoop102、hadoop103和hadoop104,克隆时必须关闭hadoop100。在hadoop上单击右键,管理,点击“克隆”。
(2)点击下一页
(3)勾选虚拟机中的当前状态,下一页
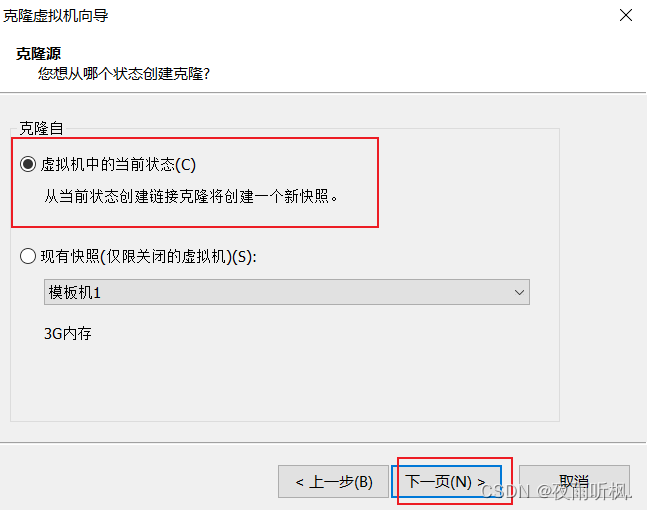
(4)勾选创建完整克隆,下一页
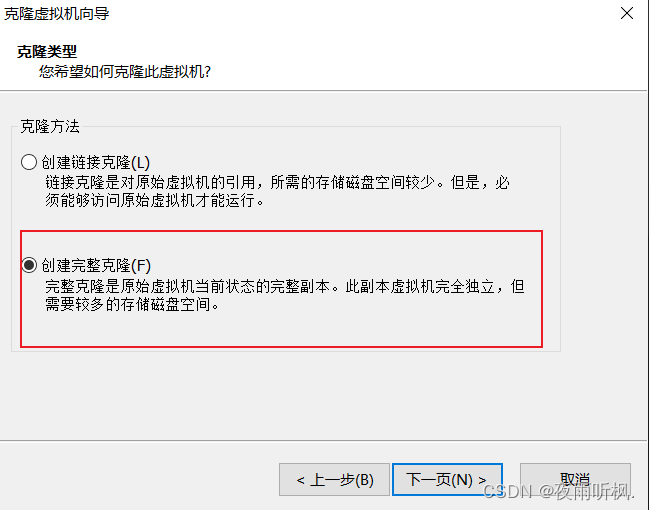
(5)修改新虚拟机名称和存储路径,点击完成即可。
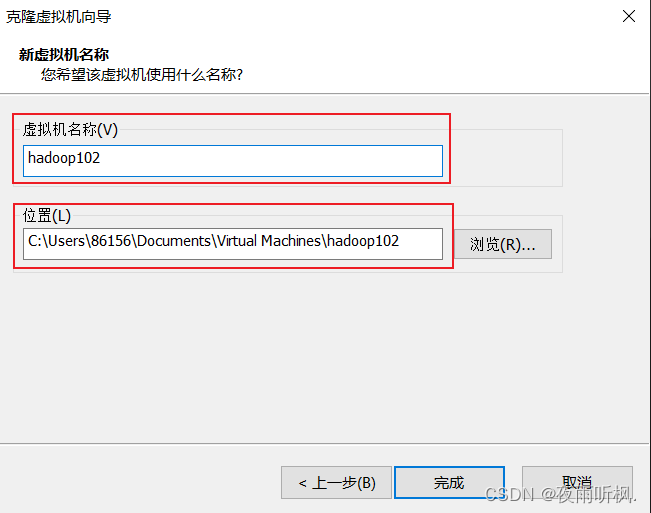
(6)修改新克隆出来的hadoop102、hadoop103、hadoop104的静态ip、主机名、映射文件,步骤和模板机修改方法完全相同,分别测试网络。
二、在虚拟机中安装JDK
- 卸载虚拟机自带的JDK
上一节中已经卸载 - 使用Xftp传输工具将JDK导入/opt/software
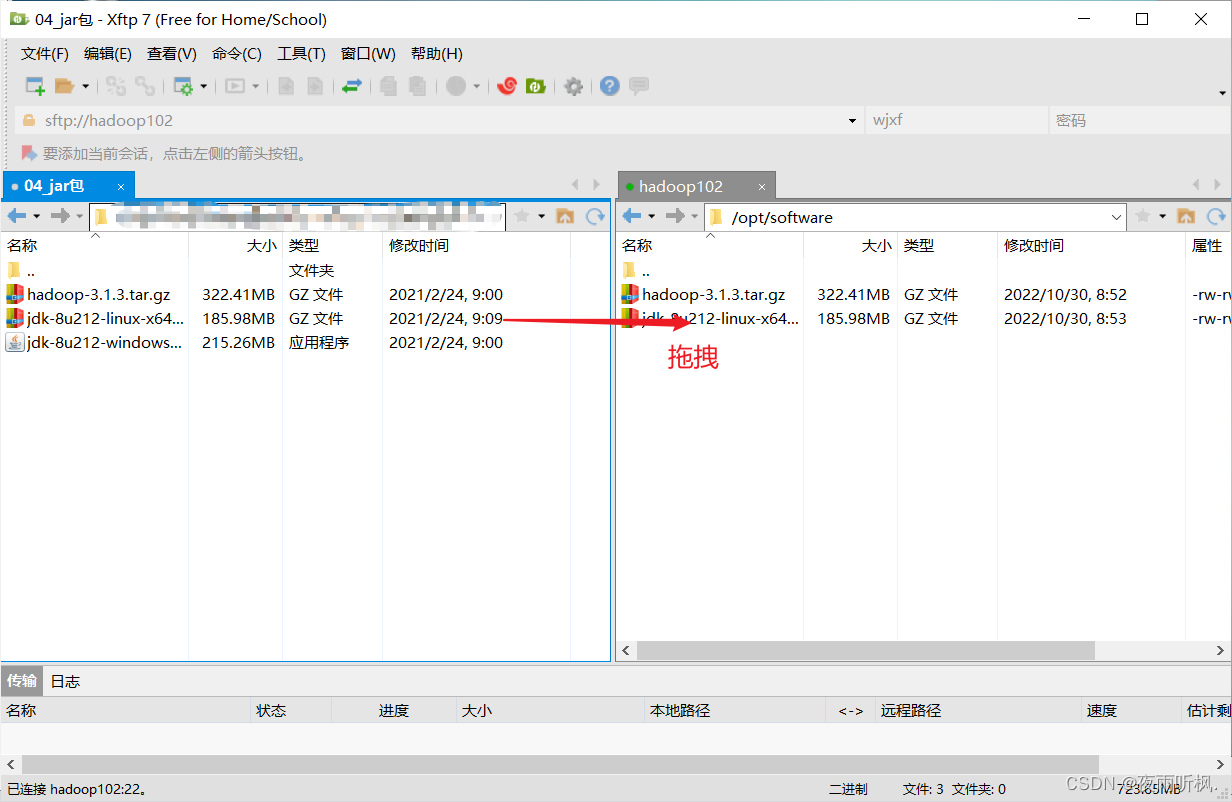
- 确认软件包是否导入成功
[root@hadoop102 software]# ll
总用量 520600
-rw-rw-r--. 1 user user 338075860 10月 30 08:52 hadoop-3.1.3.tar.gz
-rw-rw-r--. 1 user user 195013152 10月 30 08:53 jdk-8u212-linux-x64.tar.gz
[root@hadoop102 software]#
- 将JDK解压到/opt/module中
[atguigu@hadoop102 software]$ tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
- 配置JDK环境变量
- 新建/etc/profile.d/my_env.sh文件
[user@hadoop102 ~]$ sudo vim /etc/profile.d/my_env.sh
- 在my_env.sh中添加如下内容
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
- 保存后退出:wq
- 让新配的环境变量生效
[user@hadoop102 ~]$ source /etc/profile
- 输入java -version测试JDK是否安装成功
[root@hadoop102 software]# java -version
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)
[root@hadoop102 software]#
三、在虚拟机中安装Hadoop
- 使用Xftp传输工具将hadoop-3.1.3.tar.gz导入/opt/software
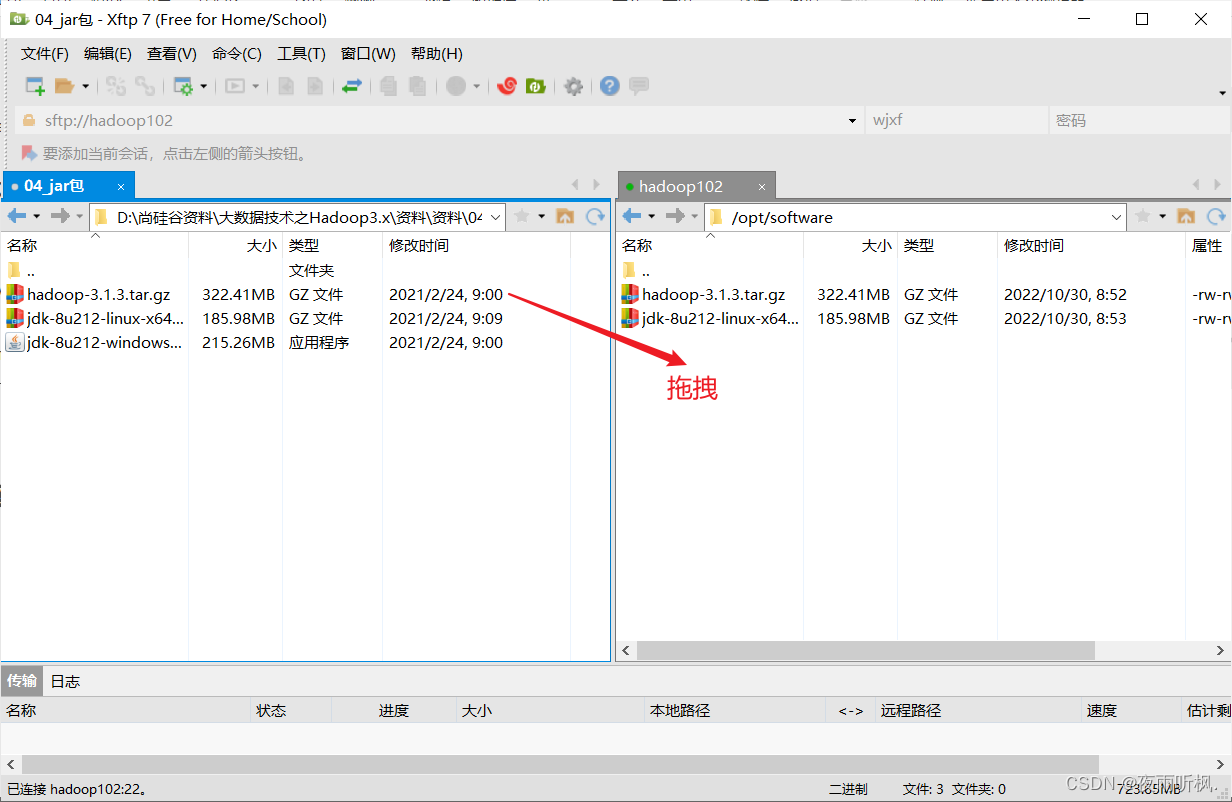
- 确认软件包是否导入成功
[root@hadoop102 software]# ll
总用量 520600
-rw-rw-r--. 1 user user 338075860 10月 30 08:52 hadoop-3.1.3.tar.gz
-rw-rw-r--. 1 user user 195013152 10月 30 08:53 jdk-8u212-linux-x64.tar.gz
[root@hadoop102 software]#
- 将hadoop解压到/opt/module中
[user@hadoop102 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
- 配置Hadoop环境变量
- 打开/etc/profile.d/my_env.sh文件
[user@hadoop102 hadoop-3.1.3]$ sudo vim /etc/profile.d/my_env.sh
- 追加以下内容,保存退出:wq
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
- 让新配的环境变量生效
[user@hadoop102 ~]$ source /etc/profile
- 输入hadoop version确认是否安装成功
[root@hadoop102 software]# hadoop version
Hadoop 3.1.3
Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r ba631c436b806728f8ec2f54ab1e289526c90579
Compiled by ztang on 2019-09-12T02:47Z
Compiled with protoc 2.5.0
From source with checksum ec785077c385118ac91aadde5ec9799
This command was run using /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-common-3.1.3.jar
[root@hadoop102 software]#















 2272
2272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









