







说明:本文为本人学习本课程的笔记,课程链接为
【(强推|双字)2022吴恩达机器学习Deeplearning.ai课程】
https://www.bilibili.com/video/BV1Pa411X76sp=8&vd_source=1a7101e2cd4837c57a0824d2cc5a5e56

如需要更深层次地掌握知识,请自行学习视频课程。
第四章 梯度下降法及其在线性回归模型中的应用
4.1 梯度下降法
梯度下降法(gradient descent)是一种常用的一阶(first-order)优化方法,是求解无约束优化问题最简单、最经典的方法之一。
————————————————
梯度下降法在机器学习中应用十分的广泛,主要目的是通过迭代的方式找到目标函数的最小值(极小值)。
其基本思想是: 以所处的位置为基准,寻找这个位置最陡峭的地方,然后朝着下降方向走一步,然后又继续以当前位置为基准,再找最陡峭的地方,再走直到最后到达最低处。
梯度: 在单变量的函数中,梯度其实就是函数的微分,代表着函数在某个给定点的切线的斜率;在多变量函数中,梯度是一个向量,向量有方向,梯度的方向就指出了函数在给定点的上升最快的方向。
————————————————
版权声明:本文为CSDN博主「ha_lee」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/ha_lee/article/details/122363325
对于代价函数J(w,b),欲通过某种方法法找到最合适的(w,b),使得代价函数J取得最小值,以得到最合适的线性回归模型,这种方法需要:
1. 从(w,b)的某个初值开始
2. 每一步骤调整(w,b)的值,使得代价函数始终减小,直到得到或接近最小值

下面详细介绍梯度下降法
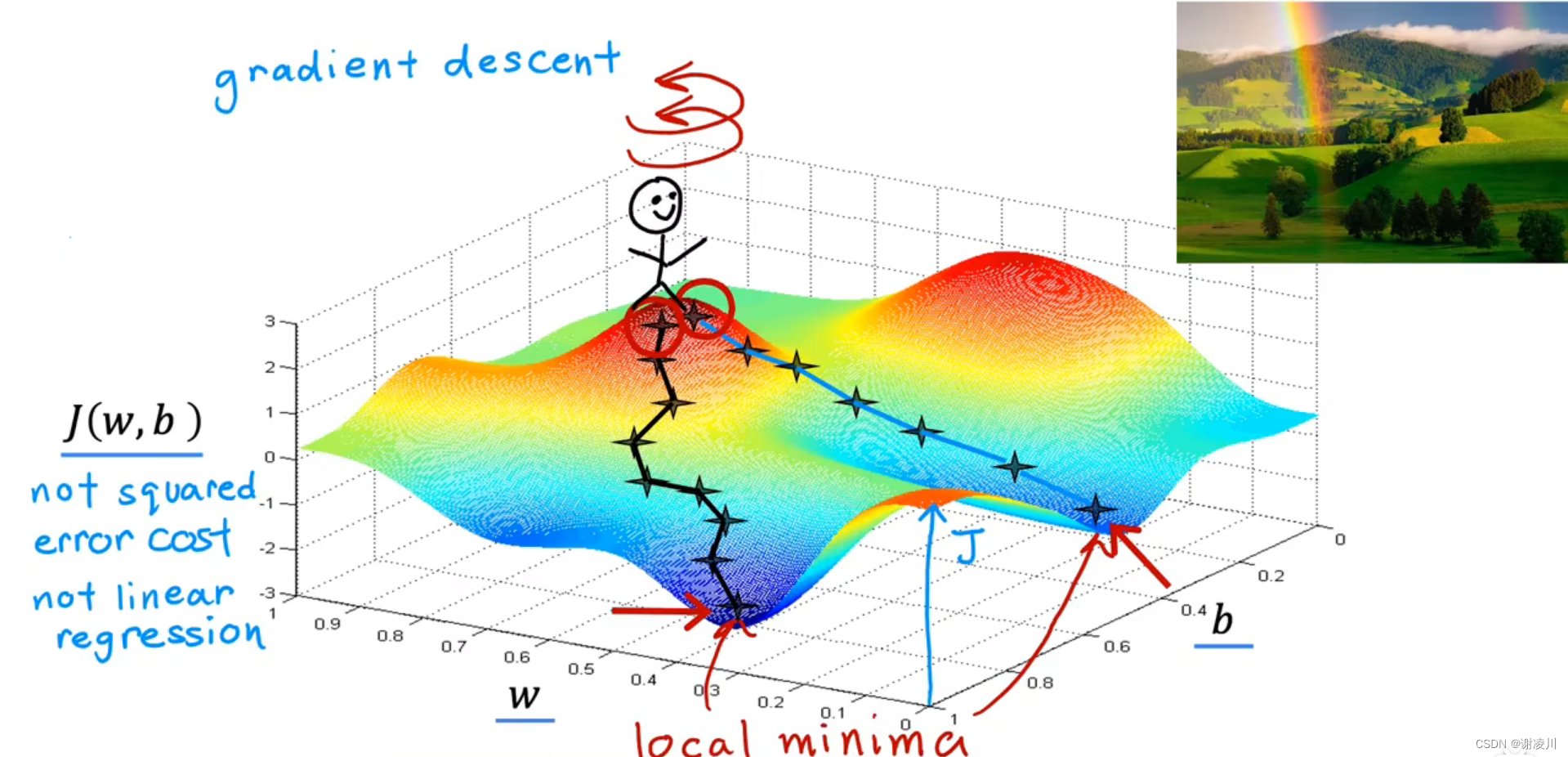
如图,思考问题,将图中曲面代表的函数看成一座小山,那么位于其上任意一点的人,如何规划其行动路线,能使得他较快地到达这座山的某个最低点?
上文指出
梯度: 在单变量的函数中,梯度其实就是函数的微分,代表着函数在某个给定点的切线的斜率;在多变量函数中,梯度是一个向量,向量有方向,梯度的方向就指出了函数在给定点的上升最快的方向。
梯度所在直线的方向是函数变化最快的方向,也就是“小山最陡峭的位置”,因此,只要在当前位置沿梯度的反方向(山的高度下降最快的方向)移动一小段距离,待新位置确定后再确定新位置的梯度方向,重复上述步骤,就能够找到函数的局部最小值(山的某个最低点)。
像这样,沿梯度所在直线的方向逐步迭代求解极值的方法称为梯度下降法。
4.2 梯度下降法的实现

如图,梯度下降法的迭代公式如下:
其中,w(i)表示第i次迭代,i为自然数。
实现梯度下降的伪代码如下:
其中,“=”的含义为赋值符号。
注意,w和b的变化必须同时进行,否则迭代的值会不准确。
α称为学习率,满足 。

使用梯度下降法时,不停重复上述步骤,直到(w,b)收敛(Converges)于其局部最小值。
4.3 理解梯度下降法
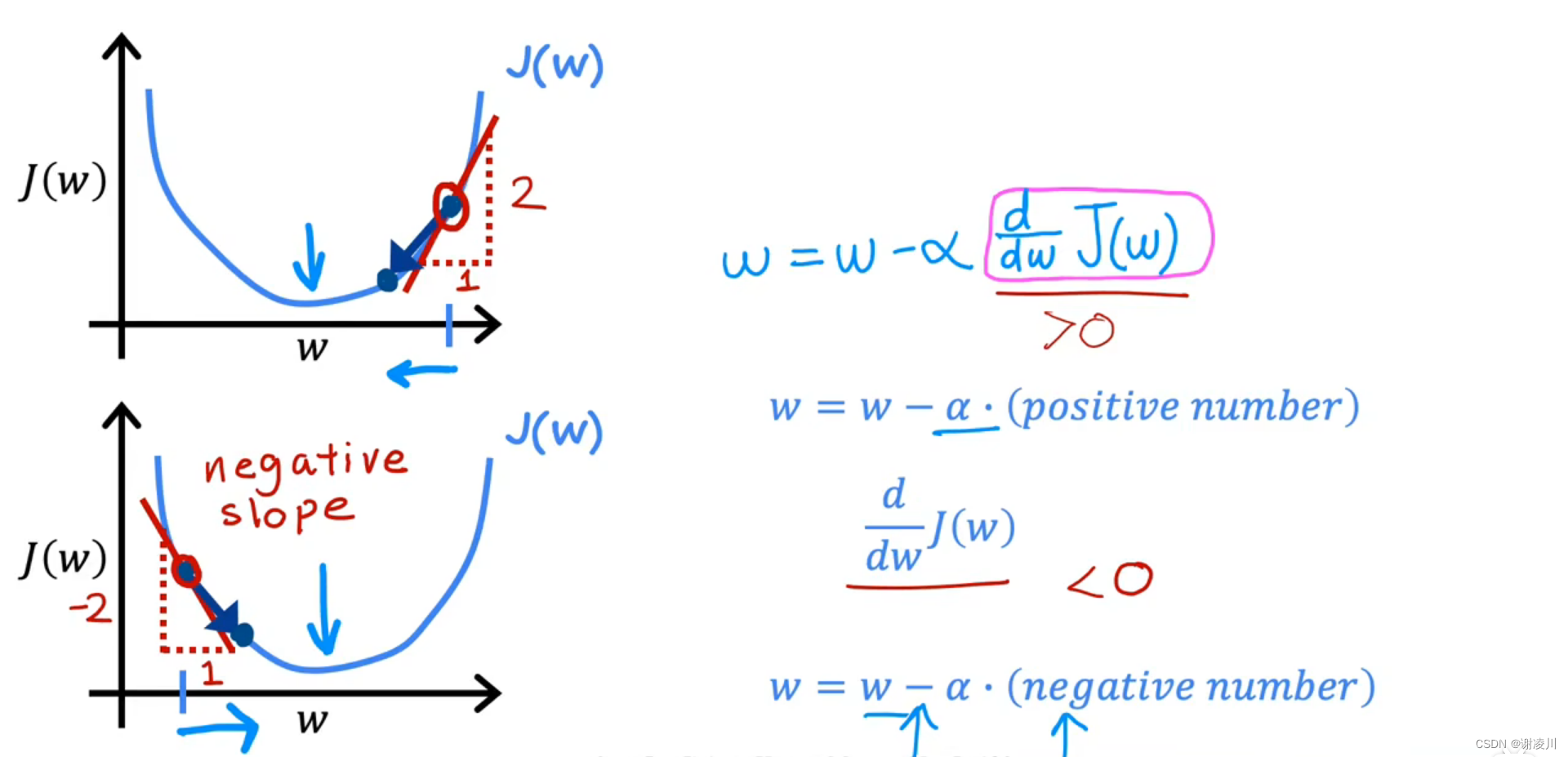
如图,在线性回归中置b=0,研究迭代中w大小变化趋势和其所在位置导数关系,能够得出结论:
梯度下降法能让参数的值朝有利于其达到局部最小值的方向变化。
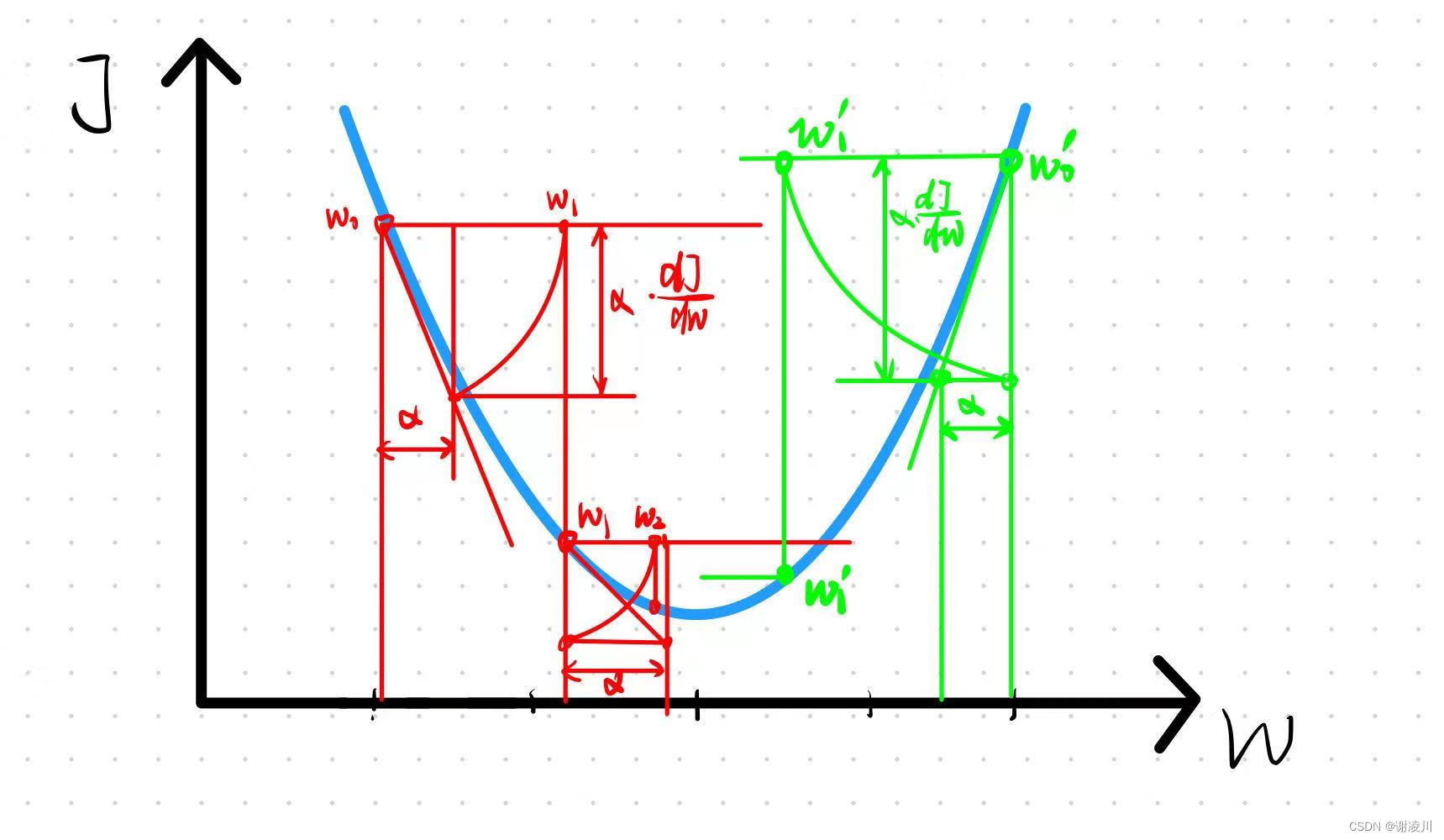
如图,设定α为固定值,结合导数的几何意义,观察w在迭代中的变化,能够得出结论:
在α取值合理的情况下,随着梯度下降法的迭代的进行,w逐渐趋近于其理想值。
4.4 学习率α的选择与注意事项
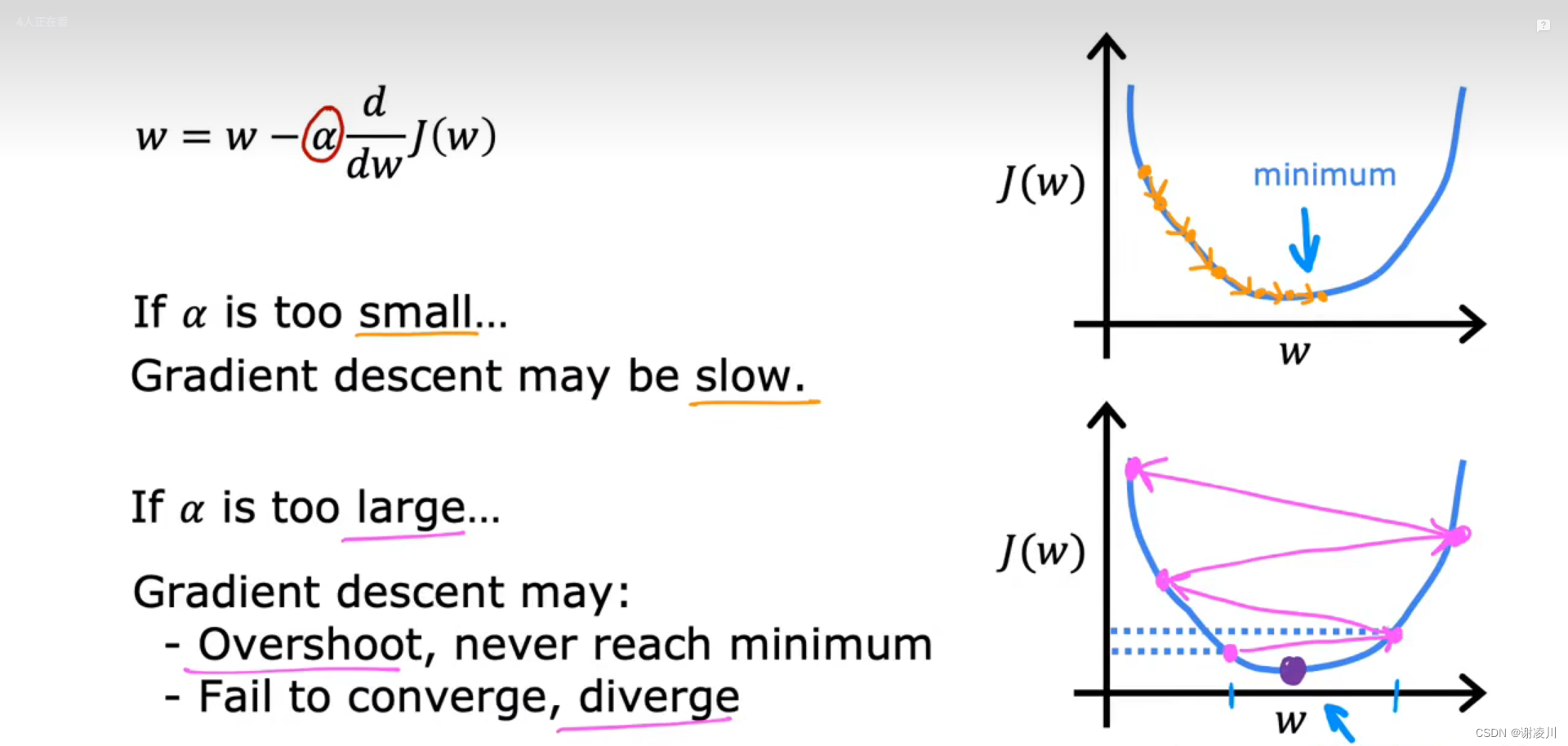
如图,当学习率α过大或者过小时,梯度下降法的效果均不好。
α过小,迭代难以进行下去,w每次变化的值都很小。
α过大,可能导致方法的收敛速度变慢甚至发散(Diverge)。
因此,α的选择不能过小或者过大。
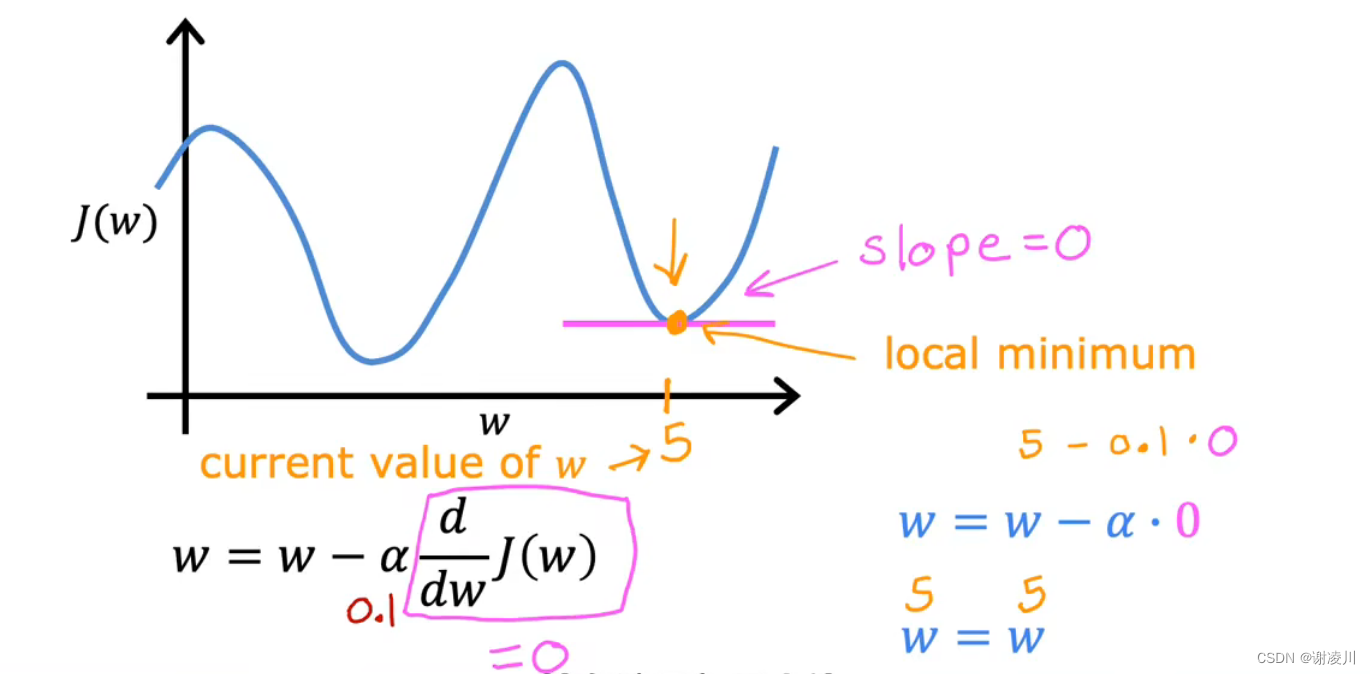
如图,需要注意,当w已经是极小值点时,方法始终收敛,因为该点切线斜率(Slope)为0。
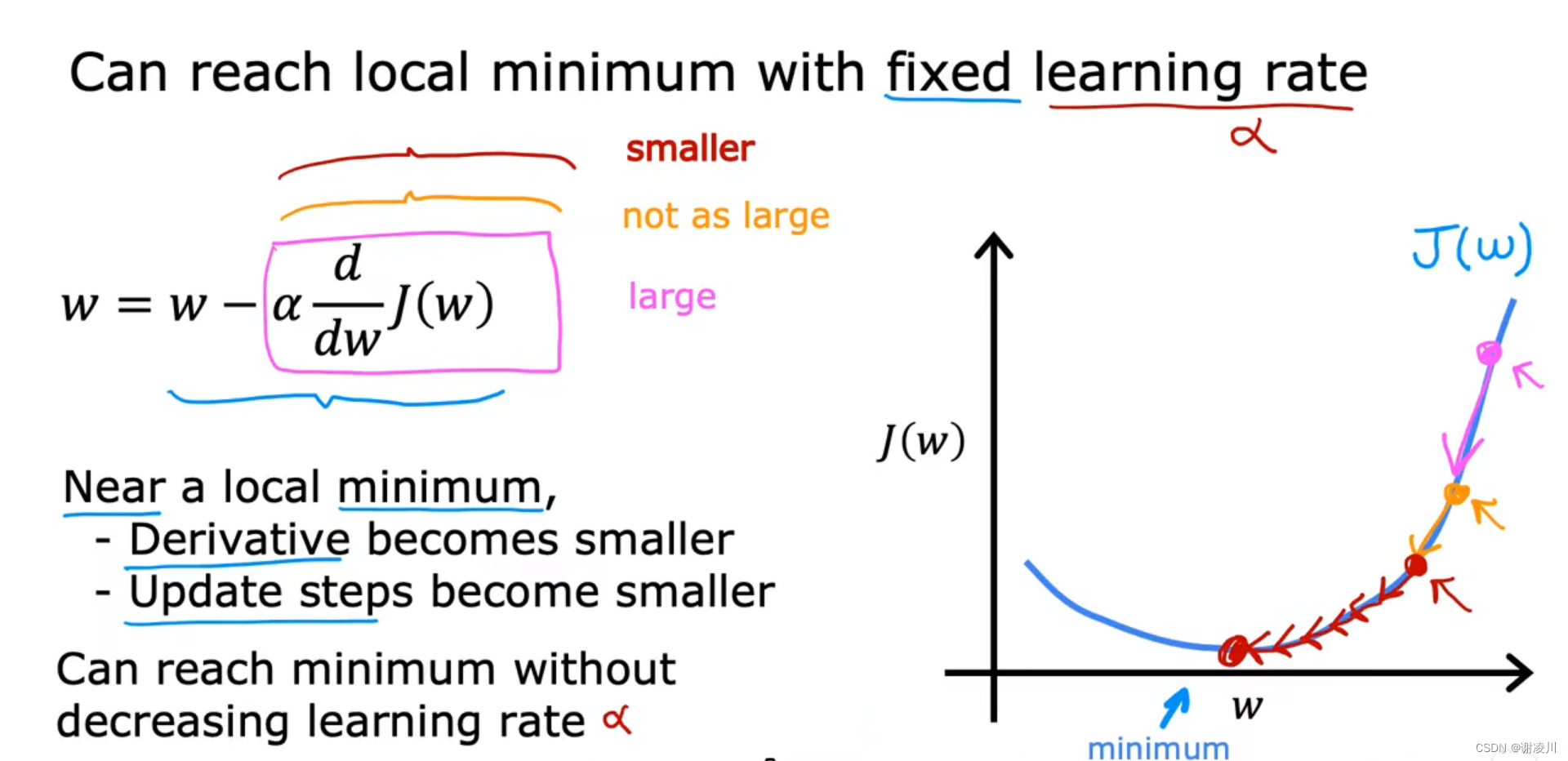
如图,梯度下降法在学习律选择合适时,能够收敛于最小值点,但在随着迭代进行,在收敛过程中,w在每次迭代中逼近最小值点的幅度会变小,因为该点对应的切线斜率的绝对值较小。这个特点也让梯度下降法具有了较高的精度和普适性。
4.5 线性回归的梯度下降法

如图,根据第三章内容展开线性回归的迭代公式。
得到如下公式
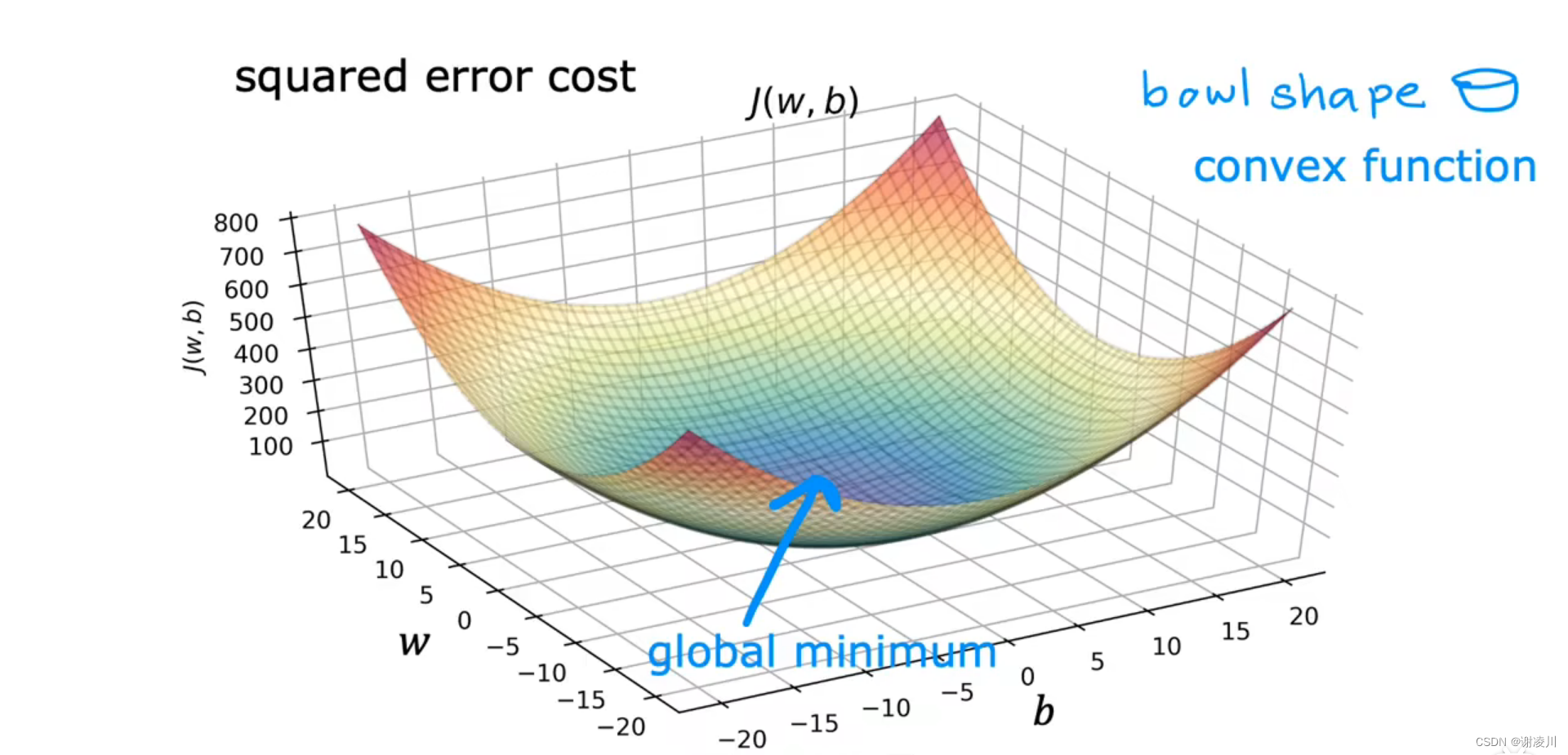
如图,线性回归的代价函数图像是一个抛物面,其具有唯一全局最小值(Global minmum),是一个凸函数(Convex function),敛散性与学习律α的取值无关。
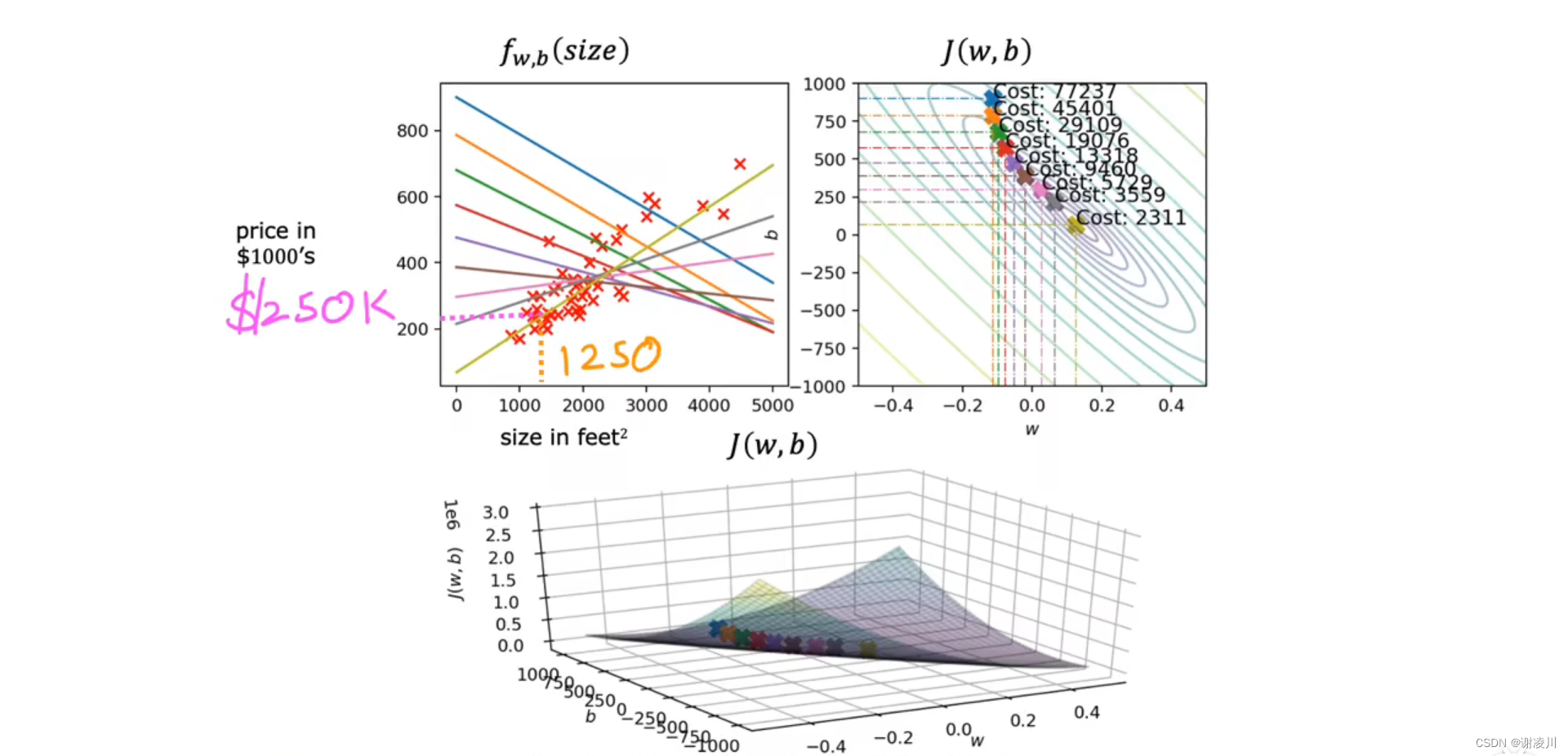
如图体现了线性回归的梯度下降迭代过程,随着迭代的进行,(w,b)从蓝色点移动到接近最低点的黄色点,黄色点代表的黄色回归直线能够反映样本的变化情况。

像这样,每一步都用到所有样本数据点的迭代过程,称为批处理(Batch)。















 247
247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









