






项目实战 ,无非于准备数据(数据预处理),加载数据,准备模型,设置损失函数,设置优化器,开始训练,最后验证,结果聚合展示。
详细分享一下模型训练经验,新手且好久没有跑深度学习项目了,可能会有些错误
项目案例:时尚服饰判别:FashionMNIST
准备数据集:
数据预处理:Fashion-MNIST 数据集中每个图像都是一个 28x28 的灰度图像,所以无需进行任何修改。
transform_data = transforms.Compose([
transforms.Resize((28, 28)), # 调整图像大小为28x28
transforms.ToTensor()
])
train_data = torchvision.datasets.FashionMNIST(root="../data", train=True, transform=transform_data,
download=True)
valid_data = torchvision.datasets.FashionMNIST(root="../data", train=False, transform=transform_data,
download=True)加载数据集:
用Dataloader加载处理即可
train_dataloader = DataLoader(train_data, batch_size=64)
valid_dataloader = DataLoader(valid_data, batch_size=64)准备模型:
在网上找的一个模型,不过训练后准确率只在70%左右,可能是我的问题。
from torch import nn
# 定义一个用于服装分类的卷积神经网络
class clothfishion(nn.Module):
def __init__(self):
super(clothfishion, self).__init__()
# 定义第一个卷积层,输入通道数为1,输出通道数为6,卷积核大小为5x5
self.conv1 = nn.Conv2d(in_channels=1,out_channels= 6,kernel_size= 5,padding=2)
self.sig =nn.Sigmoid()
# 定义最大池化层,池化窗口大小为2x2
self.pool2 = nn.AvgPool2d(kernel_size=2,stride=2)
# 定义第二个卷积层,输入通道数为6,输出通道数为16,卷积核大小为5x5
self.conv3 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5)
self.pool4 = nn.AvgPool2d(kernel_size=2, stride=2)
# 定义第一个全连接层,输入大小为16*4*4,输出大小为120
self.flatten = nn.Flatten()
# 定义第二个全连接层,输入大小为120,输出大小为84
self.f5 = nn.Linear(5*5*16, 120)
# 定义第三个全连接层,输入大小为84,输出大小为10(对应10个类别)
self.f6 = nn.Linear(120, 84)
self.f7 = nn.Linear(84, 10)
def forward(self, x):
# 通过第一个卷积层和ReLU激活函数,然后通过最大池化层
x = self.sig(self.conv1(x))
# 通过第二个卷积层和ReLU激活函数,然后通过最大池化层
x = self.pool2(x)
x = self.sig(self.conv3(x))
x = self.pool4(x)
x = self.flatten(x)
x = self.f5(x)
x = self.f6(x)
x = self.f7(x)
return x
设置损失函数与优化器
# 定义损失函数为交叉熵损失,用于多类分类问题。
def define_loss_function():
return nn.CrossEntropyLoss()
# 定义优化器为随机梯度下降(SGD),并设置学习率和动量。
def define_optimizer(model_ft):
return optim.SGD(model_ft.parameters(), lr=0.001,momentum=0.8)模型训练:
训练前的一些准备工作,推荐看小土堆的pytorch教程关于tensorboard使用
SummaryWriter:简洁方便观察曲线的变化
有gpu就用,会节省很多时间
model_ft = clothfishion()
total_train_step = 0
total_test_step = 0
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_ft = model_ft.to(device)
train_losses = [] # 记录训练损失
val_losses = [] # 记录验证损失
val_accuracies = [] # 记录验证准确率
best_acc = 0.0 # 初始化最佳准确率
criterion = define_loss_function() # 定义损失函数
optimizer = define_optimizer(model_ft) # 定义优化器
num_epochs = 20 # 设置训练轮数开始训练模型: y=wx+b
for epoch in range(num_epochs):
print("-------第 {} 轮训练开始-------".format(epoch + 1))
# 训练阶段
model_ft.train()
running_loss = 0.0
for inputs, labels in train_dataloader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model_ft(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
# 每 200 个 batch 打印一次训练损失
total_train_step += 1
if total_train_step % 200 == 0:
print("训练次数:{}, Loss: {:.4f}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 计算训练集平均损失
epoch_train_loss = running_loss / len(train_data)
train_losses.append(epoch_train_loss)
print("训练集平均 Loss: {:.4f}".format(epoch_train_loss))
# 验证阶段
model_ft.eval()
total_test_loss = 0.0
total_accuracy = 0
with torch.no_grad():
for inputs, labels in valid_dataloader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model_ft(inputs)
loss = criterion(outputs, labels)
total_test_loss += loss.item() * inputs.size(0)
accuracy = (outputs.argmax(1) == labels).sum().item()
total_accuracy += accuracy
# 计算验证集平均损失和准确率
avg_val_loss = total_test_loss / len(valid_data)
avg_val_accuracy = total_accuracy / len(valid_data) # 使用验证集样本总数
val_losses.append(avg_val_loss)
val_accuracies.append(avg_val_accuracy)
# 打印验证集结果
print("验证集 Loss: {:.4f}".format(avg_val_loss))
print("验证集正确率: {:.2f}%".format(avg_val_accuracy * 100))
# 保存最佳模型
if avg_val_accuracy > best_acc:
best_acc = avg_val_accuracy
torch.save(model_ft.state_dict(), f"best_model_epoch{epoch+1}_acc{avg_val_accuracy:.2f}.pth")
print("已保存最佳模型")训练结果:可能是训练次数比较少,最佳训练效果在第20轮才73%,再训练的话应该会更高一点
训练验证:
用它自带的验证集(随机选取里面的100个数据)来验证一下训练结果(隐藏的代码为网上随机找图验证),模型选择最佳的那一个best_model_epoch20_acc0.73.pth
import torch
import torchvision
from PIL import Image
from torch import nn
import torch.nn.functional as F
from torch.utils.data import DataLoader, random_split
from torchvision import datasets, transforms
class_label =['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor(),
torchvision.transforms.Grayscale(num_output_channels=1),
])
# image_path = r"D:\pytorch_test\fashion_example\test_photo.png"
# image = Image.open(image_path)
# print(image)
# image = image.convert('RGB')
# image = transform(image)
# print(image.shape)
# 数据集验证测试
val_data =datasets.FashionMNIST(root='./data',train=False, download=True,transform=transforms.ToTensor())
test_size = int(0.01 * len(val_data))
train_size = int(0.99 * len(val_data))
test_data,train_data= random_split(val_data,[test_size,train_size])
test_data_loader = DataLoader(test_data,batch_size=64)
test_data_size = len(test_data)
print(test_data_size)
class clothfishion(nn.Module):
def __init__(self):
super(clothfishion, self).__init__()
# 定义第一个卷积层,输入通道数为1,输出通道数为6,卷积核大小为5x5
self.conv1 = nn.Conv2d(in_channels=1,out_channels= 6,kernel_size= 5,padding=2)
self.sig =nn.Sigmoid()
# 定义最大池化层,池化窗口大小为2x2
self.pool2 = nn.AvgPool2d(kernel_size=2,stride=2)
# 定义第二个卷积层,输入通道数为6,输出通道数为16,卷积核大小为5x5
self.conv3 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5)
self.pool4 = nn.AvgPool2d(kernel_size=2, stride=2)
# 定义第一个全连接层,输入大小为16*4*4,输出大小为120
self.flatten = nn.Flatten()
# 定义第二个全连接层,输入大小为120,输出大小为84
self.f5 = nn.Linear(5*5*16, 120)
# 定义第三个全连接层,输入大小为84,输出大小为10(对应10个类别)
self.f6 = nn.Linear(120, 84)
self.f7 = nn.Linear(84, 10)
def forward(self, x):
# 通过第一个卷积层和ReLU激活函数,然后通过最大池化层
x = self.sig(self.conv1(x))
# 通过第二个卷积层和ReLU激活函数,然后通过最大池化层
x = self.pool2(x)
x = self.sig(self.conv3(x))
x = self.pool4(x)
x = self.flatten(x)
x = self.f5(x)
x = self.f6(x)
x = self.f7(x)
return x
model_ft = clothfishion()
model_ft.load_state_dict(torch.load(r"D:\pytorch_test\fashion_example\best_model_epoch20_acc0.73.pth"))
j=0
model_ft.eval()
with torch.no_grad():
for inputs, labels in test_data_loader:
output = model_ft(inputs)
predicted_classes = output.argmax(1) # 获取每个样本的预测类别索引
# 遍历每个样本
for i in range(len(labels)):
predicted_class = predicted_classes[i].item() # 获取单个预测类别索引
true_label = labels[i].item() # 获取单个真实标签
print(f"Predicted class: {class_label[predicted_class]}, True label: {class_label[true_label]}")
if predicted_class != true_label:
j+=1
print(f"正确率为:{float((len(test_data)-j)/len(test_data))},预测错误的有{j}个,总数为{len(test_data)}")
# model_ft.eval()
# with torch.no_grad():
# output = model_ft(image)
# predicted_classes = output.argmax(1)
# print(f"Predicted class: {predicted_classes}")运行结果:截了一段,错误率确实有点高
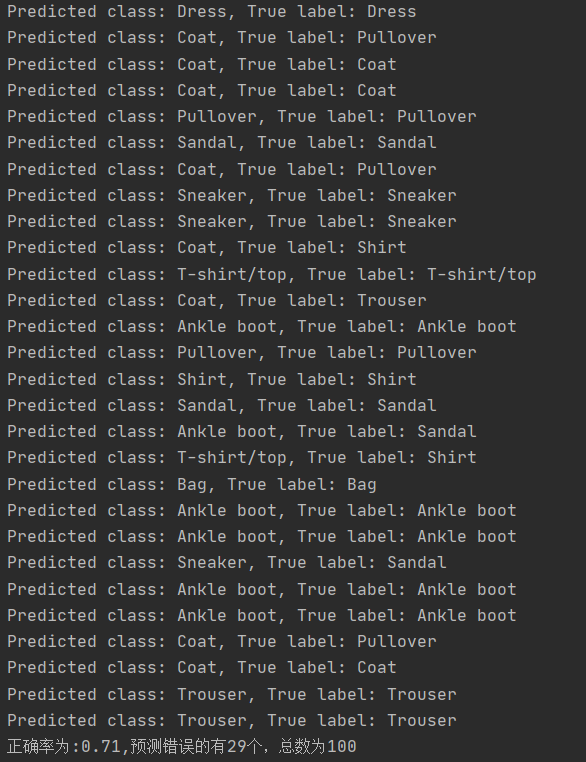

















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









