






一、字符串函数
1.strtok 函数的使用
char * strtok ( char * str, const char * sep);
• sep参数指向⼀个字符串,定义了⽤作分隔符的字符集合
• 第⼀个参数指定⼀个字符串,它包含了0个或者多个由sep字符串中⼀个或者多个分隔符分割的标 记。
• strtok函数找到str中的下⼀个标记,并将其⽤ \0 结尾,返回⼀个指向这个标记的指针。
• strtok函数的第⼀个参数不为 NULL ,函数将找到str中第⼀个标记,strtok函数将保存它在字符串 中的位置。
• strtok函数的第⼀个参数为 NULL ,函数将在同⼀个字符串中被保存的位置开始,查找下⼀个标 记。
• 如果字符串中不存在更多的标记,则返回 NULL 指针。
int main()
{
char arr[] = "zhangsan@163.com#hehehehe";
char arr2[30] = { 0 };
strcpy(arr2,arr);
char* sep = "@.#";
char* s = NULL;
// 初始化部分只执行一次
for (s=strtok(arr2,sep);s!=NULL;s = strtok(NULL, sep))
{
printf("%s\n",s);
}
return 0;
}
2.strerror 函数的使用
char * strerror ( int errnum );
strerror函数可以把参数部分错误码对应的错误信息的字符串地址返回来。 在不同的系统和C语⾔标准库的实现中都规定了⼀些错误码,⼀般是放在 errno.h 这个头⽂件中说明 的,C语⾔程序启动的时候就会使⽤⼀个全⾯的变量errno来记录程序的当前错误码,只不过程序启动 的时候errno是0,表⽰没有错误,当我们在使⽤标准库中的函数的时候发⽣了某种错误,就会讲对应 的错误码,存放在errno中,⽽⼀个错误码的数字是整数很难理解是什么意思,所以每⼀个错误码都是 有对应的错误信息的。strerror函数就可以将错误对应的错误信息字符串的地址返回。
#include <errno.h>
int main()
{
int i = 0;
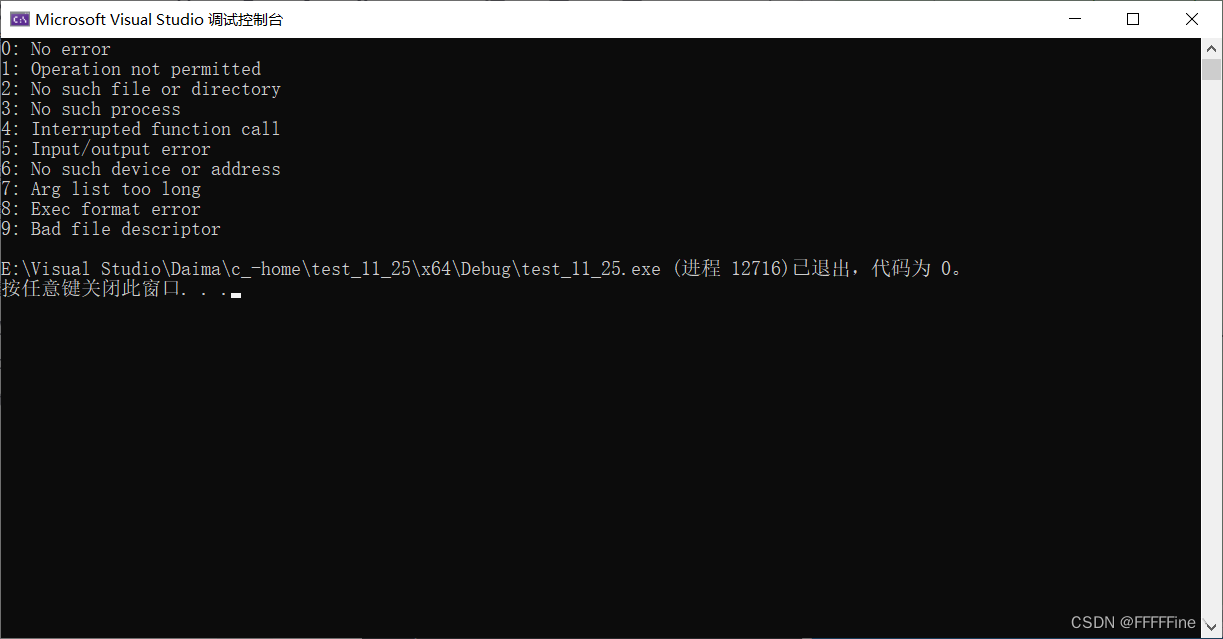
for (i = 0; i < 10; i++)
{
printf("%d: %s\n", i,strerror(i));
}
return 0;
}
二、内存函数
1.memcpy 使用
void * memcpy ( void * destination, const void * source, size_t num );
• 函数memcpy从source的位置开始向后复制num个字节的数据到destination指向的内存位置。
• 这个函数在遇到 '\0' 的时候并不会停下来。
• 如果source和destination有任何的重叠,复制的结果都是未定义的。
int main()
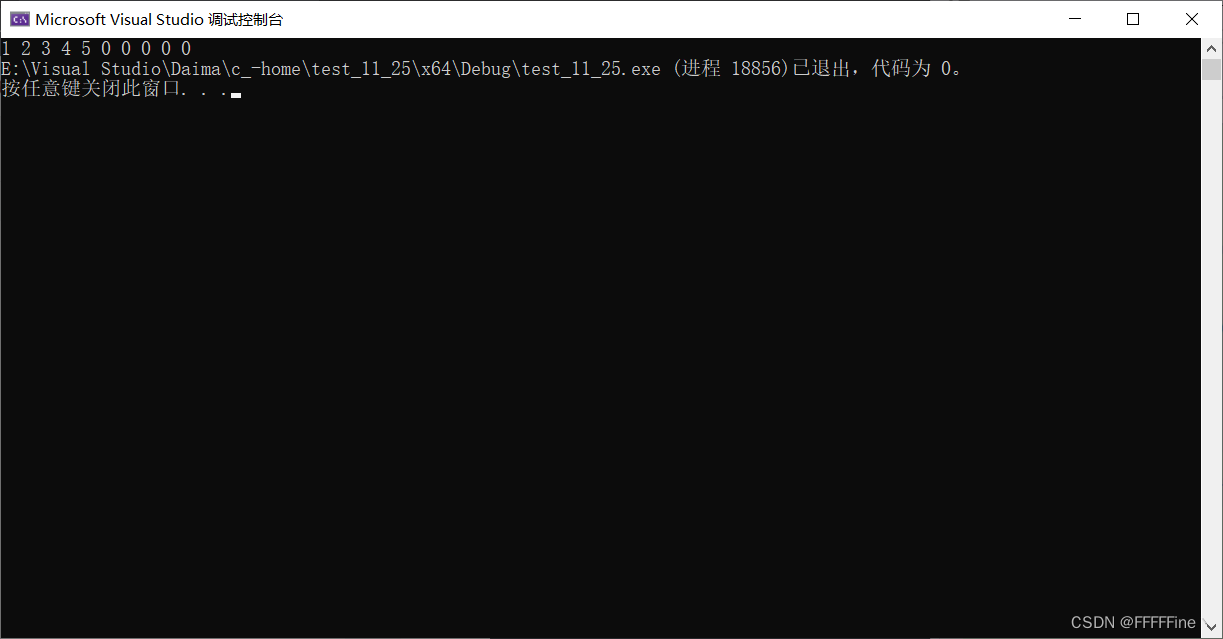
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int arr2[10] = {0};
//将arr1的1 2 3 4 5,拷贝到arr2中
memcpy(arr2,arr,20);//20 是20个字节 一个int 为4个字节
for (int i = 0; i < 10; i++)
{
printf("%d ", arr2[i]);
}
return 0;
}
2.memmove 使用
void * memmove ( void * destination, const void * source, size_t num );
• 和memcpy的差别就是memmove函数处理的源内存块和⽬标内存块是可以重叠的。
• 如果源空间和⽬标空间出现重叠,就得使⽤memmove函数处理。
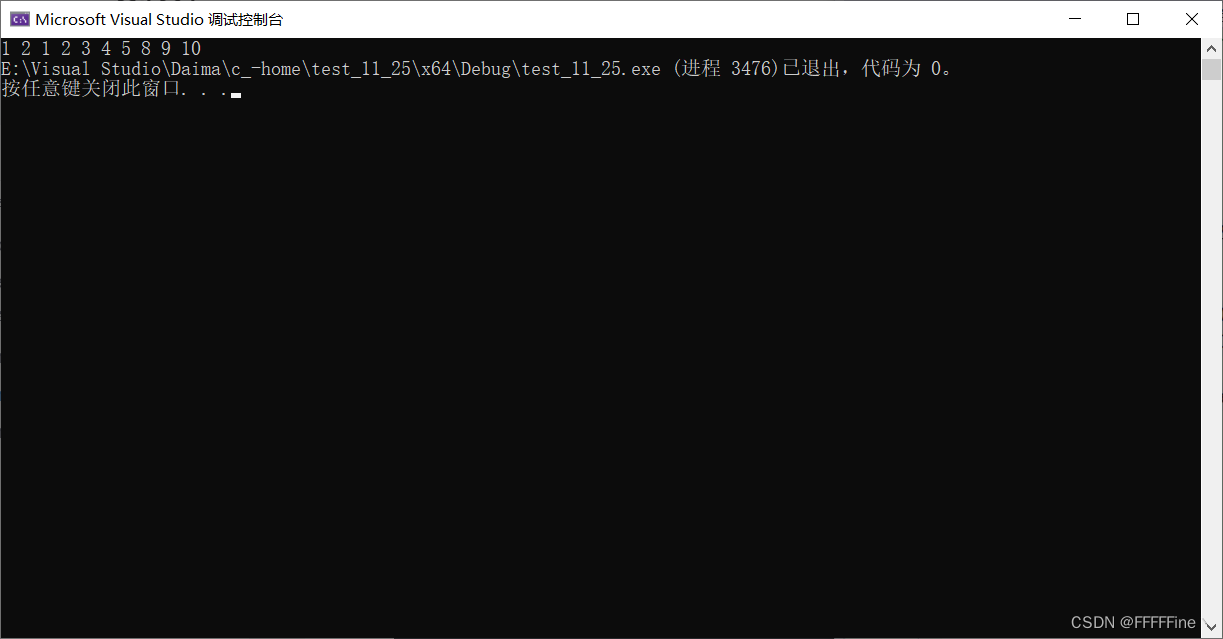
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
memcpy(arr+2,arr,20);//20 是20个字节 一个int 为4个字节
for (int i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
3.memset 函数的使用
void * memset ( void * ptr, int value, size_t num );
memset是⽤来设置内存的,将内存中的值以字节为单位设置成想要的内容。
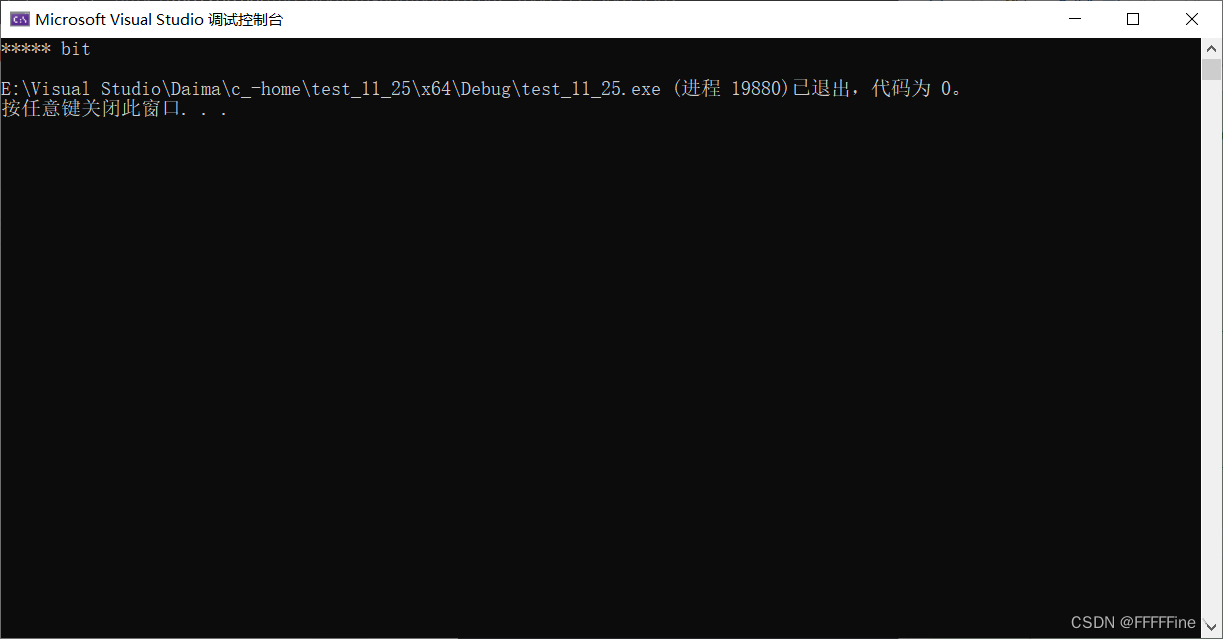
int main()
{
char arr[10] = "hello bit";
memset(arr, '*', 5);
//memset 在设置的时候,是以字节为单位来设置的
printf("%s\n",arr);
return 0;
}
4.memcmp 函数的使用
int memcmp ( const void * ptr1, const void * ptr2, size_t num );
• 比较从ptr1和ptr2指针指向的位置开始,向后的num个字节
• ptr1>ptr2 返回大于0的数,ptr1=ptr2 返回等于0,ptr1<ptr2 返回小于0的数
int main()
{
int arr1[10] = { 1,2,3,4,5,6,7,8,9,10 };
int arr2[10] = { 1,2,3,4,8 };
int ret=memcmp(arr1,arr2,20);
printf("%d\n", ret);
return 0;
}
二、大小端字节序和字节序判断
1.什么是大小端
其实超过⼀个字节的数据在内存中存储的时候,就有存储顺序的问题,按照不同的存储顺序,我们分 为⼤端字节序存储和⼩端字节序存储,下⾯是具体的概念:
⼤端(存储)模式:是指数据的低位字节内容保存在内存的⾼地址处,⽽数据的⾼位字节内容,保存 在内存的低地址处。
⼩端(存储)模式:是指数据的低位字节内容保存在内存的低地址处,⽽数据的⾼位字节内容,保存 在内存的⾼地址处。
2.为什么有大小端
这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着⼀个字节,⼀个字节为8 bit 位,但是在C语⾔中除了8 bit 的 char 之外,还有16 bit 的 short 型,32 bit 的 long 型(要看 具体的编译器),另外,对于位数⼤于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度⼤ 于⼀个字节,那么必然存在着⼀个如何将多个字节安排的问题。因此就导致了⼤端存储模式和⼩端存 储模式。
3.如何设计一个判断大小端的代码
int main()
{
int a = 1;
char* p= (char*)&a;
if (*p == 1)
{
printf("小端");
}
else
{
printf("大端");
}
return 0;
}














 2167
2167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









