






大脑活动到图像,Stable Diffusion 能重建。
如果人工智能可以解读你的想象,将你脑海中的图像变成现实,那会怎样?

虽然这听起来有点赛博朋克。但最近发表的一篇论文,让 AI 圈吵翻了天。

这篇论文发现,他们使用最近非常火的 Stable Diffusion,就能重建大脑活动中的高分辨率、高精准图像。作者写道,与之前的研究不同,他们不需要训练或微调人工智能模型来创建这些图像。

- 论文地址:https://www.biorxiv.org/content/10.1101/2022.11.18.517004v2.full.pdf
- 网页地址:https://sites.google.com/view/stablediffusion-with-brain/
他们是怎么做到的呢?
在此研究中,作者基于 Stable Diffusion 来重建通过功能磁共振成像 (fMRI) 而获得的人脑活动图像。作者也表示,通过研究与大脑相关功能的不同组成部分(例如图像 Z 的潜在向量等),也有助于了解隐扩散模型的机制。
这篇论文也已经被 CVPR 2023 接收。
该研究的主要贡献包括:
- 证明了其简单框架可以从具有高语义保真度的大脑活动中重建高分辨率(512×512)图像,而无需训练或微调复杂的深度生成模型,如下图所示;
- 通过将特定组成部分映射到不同的大脑区域,该研究从神经科学的角度定量解释了 LDM 的每个组成部分;
- 该研究客观地解释了 LDM 实现的文本到图像转换过程如何结合条件文本表达的语义信息,同时保持原始图像的外观。

方法概览
该研究的总体方法如下图 2 所示。图 2(上)是该研究中使用的 LDM 示意图,其中,ε 表示图像编码器,D 表示图像解码器,τ 表示文本编码器(CLIP)。
图 2(中)是该研究的解码分析示意图。研究者分别从早期(蓝色)和高级(黄色)视觉皮层内的 fMRI 信号中解码了呈现图像 (z) 和相关文本 c 的潜在表征。这些潜在表征被用作生成重建图像 X_zc 的输入。
图 2(下)是该研究的编码分析示意图。研究者构建了编码模型来预测来自 LDM 不同组成部分的 fMRI 信号,包括 z、c 和 z_c。

有关 Stable Diffusion 这里就不做过多介绍,相信很多人都比较了解。
结果
我们来看一下该研究的视觉重建结果。
解码
下图 3 展示了一个主体(subj01)的视觉重建结果。研究者为每个测试图像生成了五个图像,并选择了具有最高 PSM 的图像。一方面,只用 z 重建的图像在视觉上与原始图像一致,但未能抓住其语义内容。另一方面,只用 c 重建的图像生成的图像具有很高的语义保真度,但在视觉上却不一致。最后,使用 z_c 重建的图像可以生成具有高语义保真度的高分辨率图像。

图 4 展示了所有测试者对同一图像的重建图像(所有图像都是用 z_c 生成的)。总体来说,各测试者的重建质量是稳定和准确的。

图 5 是定量评估的结果:

编码模型
图 6 显示了编码模型对与 LDM 相关的三种潜像的预测精度:z,原始图像的潜像;c,图像文本注释的潜像;以及 z_c,经过与 c 交叉注意力反向扩散过程后的 z 的加噪潜像表征。

图 7 显示,当加入少量的噪声时,z 对整个皮层的体素活动的预测比 z_c 更好。有趣的是,当增加噪声水平时,z_c 对高位视觉皮层内体素活动的预测优于 z,表明图像的语义内容逐渐被强调。

在迭代去噪过程中,添加噪声的潜在表征如何变化?图 8 显示,在去噪过程的早期阶段,z 信号主导了 fMRI 信号的预测。在去噪过程的中间阶段,z_c 对高位视觉皮层内活动的预测比 z 好得多,表明大部分语义内容在这个阶段出现了。结果显示了 LDM 如何从噪声中提炼和生成图像。
*你也想了解自己的梦境吗?那这100款Stable Diffusion超实用插件,涵盖目前几乎所有的,主流插件你一定要收好
全文超过4000字。
我把它们整理成更适合大家下载安装的【压缩包】,无需梯子,并根据具体的内容,拆解成一二级目录,以方便大家查阅使用。
单单排版就差不多花费1个小时。
希望能让大家在使用Stable Diffusion工具时,可以更好、更快的获得自己想要的答案,以上。
如果感觉有用,帮忙点个支持,谢谢了。
想要原版100款插件整合包的小伙伴,可以来点击下方插件直接免费获取
100款Stable Diffusion插件:
面部&手部修复插件:After Detailer
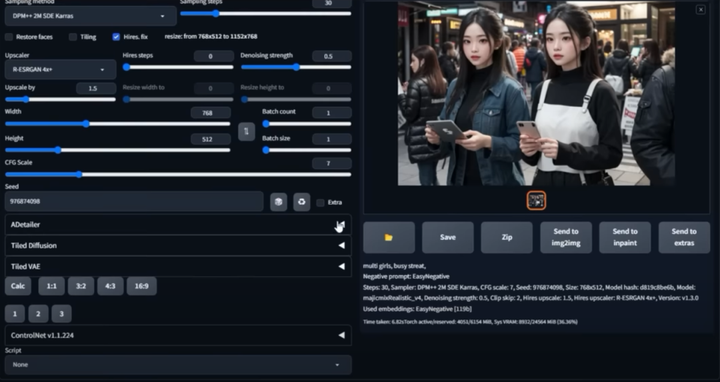
在我们出图的时候,最头疼的就是出的图哪有满意,就是手部经常崩坏。只要放到 ControlNet 里面再修复。
现在我们只需要在出图的时候启动 Adetailer 就可以很大程度上修复脸部和手部的崩坏问题
AI换脸插件:sd-webui-roop
换脸插件,只需要提供一张照片,就可以将一张脸替换到另一个人物上,这在娱乐和创作中非常受欢迎。

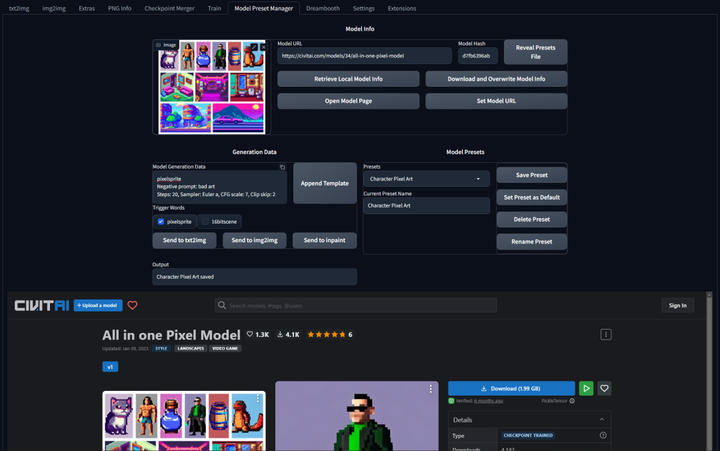
模型预设管理器:Model Preset Manager
这个插件可以轻松的创建、组织和共享模型预设。有了这个功能,就不再需要记住每个模型的最佳 cfg_scale、实现卡通或现实风格的特定触发词,或者为特定图像类型产生令人印象深刻的结果的设置!
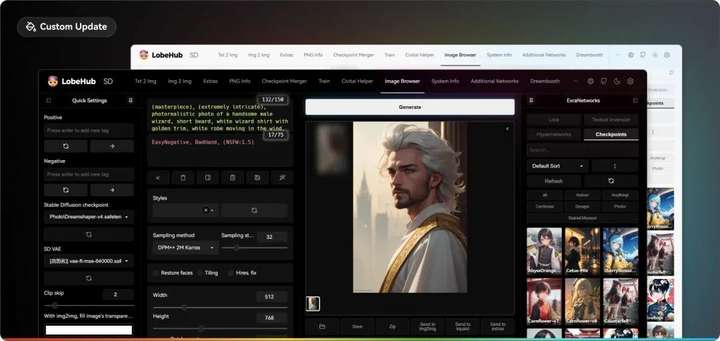
现代主题:Lobe Theme
已经被赞爆的现代化 Web UI 主题。相比传统的 Web UI 体验性大大加强。
提示词自动补齐插件:Tag Complete
使用这个插件可以直接输入中文,调取对应的英文提示词。并且能够根据未写完的英文提示词提供补全选项,在键盘上按↓箭头选择,按 enter 键选中

提示词翻译插件:sd-webui-bilingual-localization
这个插件提供双语翻译功能,使得界面可以支持两种语言,对于双语用户来说是一个很有用的功能。
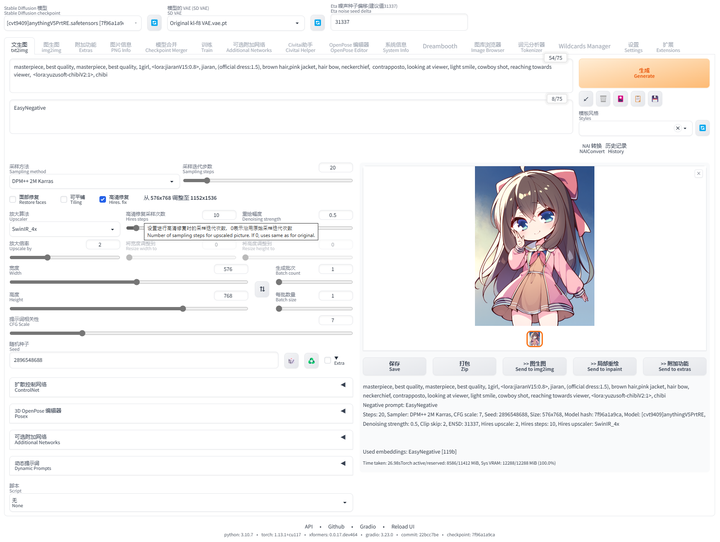
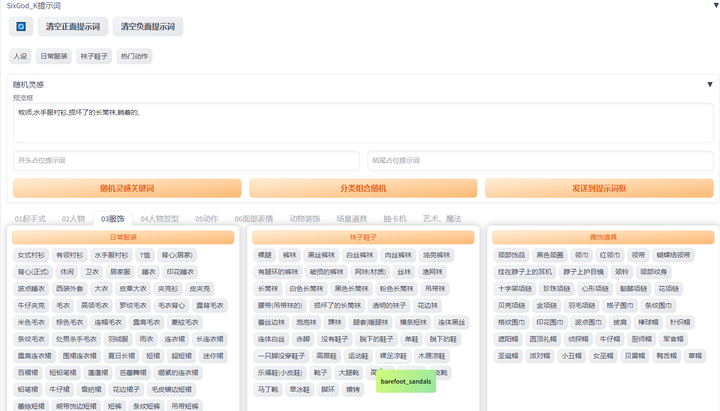
提示词库:sd-webui-oldsix-prompt
提供提示词功能,可能帮助用户更好地指导图像生成的方向。
上千个提示词,无需英文基础快速输入提示词,该词库还在不断更新。
以后再也不担心英文写出不卡住思路了!
由于篇幅原因,有需要完整版Stable Diffusion插件库的小伙伴,点击下方插件即可免费领取
















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









