






随着AI技术的不断进步,视频生成模型在各类应用中正发挥越来越重要的作用。Stable Video Diffusion (SVD) 是当下开源视频生成模型中的佼佼者,也是从著名的图像生成模型Stable Diffusion微调而成的。在这篇文章中,我们将深入探讨Stable Video Diffusion的配置推荐,介绍其技术背景和生成流程,探究高效运行该模型所必须的硬件和软件配置,并分析影响模型运行效能的关键要素。
背景与模型架构
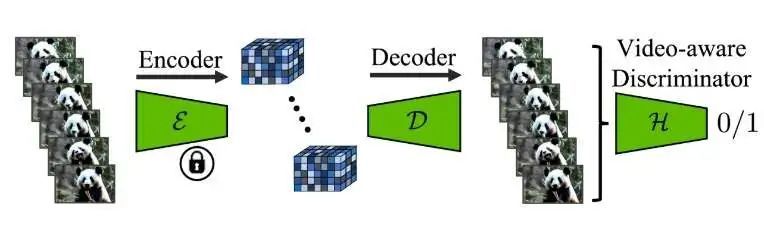
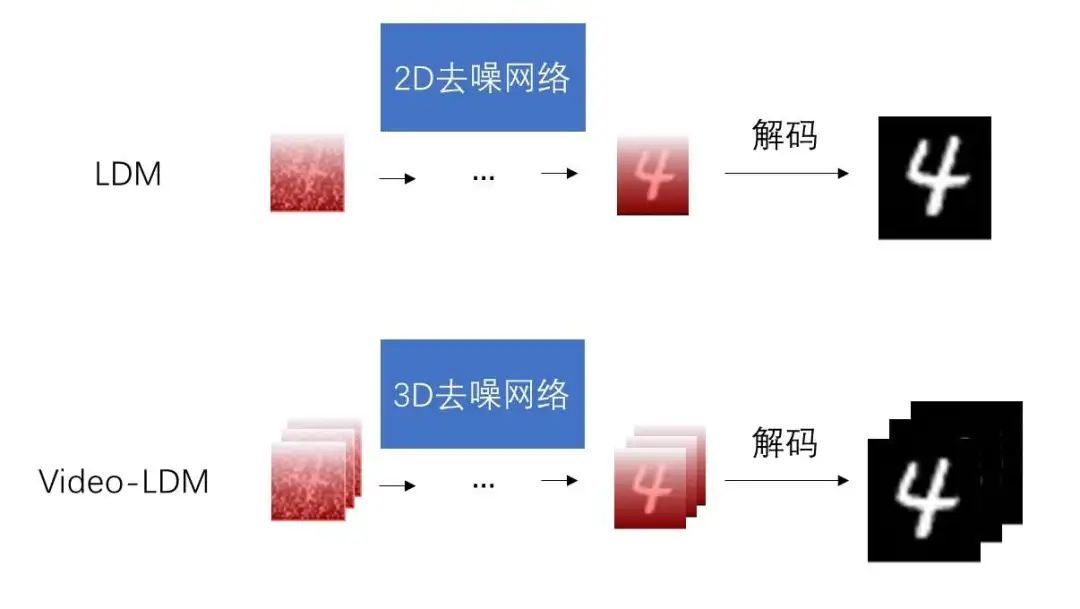
Stable Video Diffusion是由Stability公司在2023年11月21日发布开源的,用扩散模型实现的视频生成模型。SVD继承了Stable Diffusion的核心技术,在其基础上添加了视频时序相关的模块,并通过大量的视频数据集进行微调。原始的Stable Diffusion模型已经凭借其出色的图像生成能力在业界广泛应用,SVD的出现则进一步拓展了这一能力到视频生成领域。
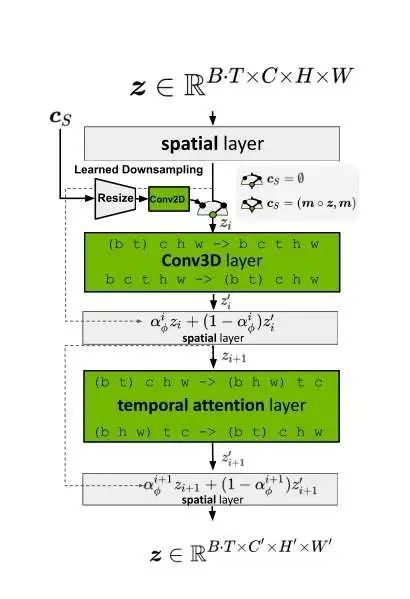
模型架构方面,SVD在Stable Diffusion(SD)的基础上做了两项主要改动:
\1. 在扩散模型的去噪模型U-Net中加入时序层。
\2. 在图像压缩和解压的VAE的解码器中加入时序层。
这些修改使得原本处理静态图片的模型能够兼容视频数据的时序特性,从而实现视频生成。
为了达到最佳的生成效果,SVD采用了多阶段训练策略,包括文生图预训练、视频预训练和高质量视频微调。每个阶段都有其独特的训练目标和技术细节,为最终高质量视频生成打下坚实基础。
硬件配置推荐
CPU与内存
视频生成模型由于涉及大量计算和数据处理,对CPU的要求较高。推荐使用多核心、高频率的CPU,例如英特尔的i9-13900K或AMD的Ryzen 9 7950X。这类高性能CPU能够有效处理模型推理过程中大量的计算任务,保证稳定运行。
内存方面,考虑到Stable Video Diffusion涉及大规模数据集处理和训练,建议至少配备64GB以上的内存。如果可能,128GB内存也会显著提升数据处理的效率。此外,高速内存(例如DDR4-3600MHz或更高规格)也有助于加快数据读取和处理速度。
GPU
生成高质量视频需要大量图像处理,因此GPU在稳定运行Stable Video Diffusion中起着核心作用。推荐使用NVIDIA的适合深度学习的显卡,如A100、V100或RTX 3090。这些显卡不仅具有强大的计算能力和海量显存,还支持CUDA和TensorRT等高效计算框架,从而显著提升模型推理速度。
尤其是A100 GPU,得益于其80GB的高带宽HBM2显存和专为深度学习优化的架构,能够在处理大规模视频数据时表现出色。多GPU配置也推荐使用NVLink桥接,以提高数据传输效率,进一步提升整体性能。
存储
Stable Video Diffusion需要处理和存储大量视频数据,因此高速且大容量的存储设备必不可少。推荐使用NVMe SSD,最低配备1TB容量,以确保数据的快速读写和高效存储。对于存储需求较高的场景,可以考虑Raid 0配置的多块NVMe SSD,进一步提高IO性能。
此外,应配备大容量的机械硬盘(如4TB以上HDD)以存储原始数据和中间结果。在执行频繁的数据备份和恢复操作时,RAID 5或RAID 6配置能提供额外的可靠性和数据恢复能力。
软件配置推荐
操作系统
推荐使用64位的Linux操作系统,例如Ubuntu 20.04 LTS。Linux操作系统在资源管理和底层驱动支持方面更加高效,适合处理深度学习任务。稳定的LTS版本能够提供更长时间的支持和安全更新,确保系统的稳定运行。
深度学习框架
Stable Video Diffusion依赖于主流的深度学习框架,如PyTorch或TensorFlow。推荐使用PyTorch 1.10或以上版本,因为其灵活性和社区支持更适合研究和开发人员。同时,PyTorch在集成CUDA加速、支持NVIDIA显卡优化方面表现优异,可以充分发挥硬件性能。

库和依赖
确保安装所有必要的库和依赖,如CUDA Toolkit、cuDNN、NCCL等。此外,稳定且兼容的Python虚拟环境(如Anaconda)有助于管理项目依赖和避免兼容性问题。以下是一些关键依赖库的安装建议:
bash
sudo apt-get update
sudo apt-get install -y cuda-toolkit-11-3
sudo apt-get install -y libcudnn8 libcudnn8-dev
conda create -n svd python=3.8
conda activate svd
conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch
pip install -r requirements.txt
数据处理与管理工具
Stable Video Diffusion需要处理大量视频数据,推荐使用DVC(Data Version Control)管理数据版本。DVC能够有效跟踪和管理数据集的变化,确保实验的可重复性和数据的可靠性。此外,还可以结合Git进行代码和数据的统一管理。
数据标注工具也必不可少,如Labelbox或CVAT,用于人工智慧的数据标注和预处理。这些工具能够帮助构建高质量的数据集,为模型训练提供坚实的数据支持。
性能优化与调优策略
扩散模型调度器优化
Stable Video Diffusion采用了改进的EDM(Elucidating the Design Space of Diffusion-Based Generative Models)调度器,显著提升了模型采样效率。在模型训练和推理过程中,合理选择和调优EDM参数尤为重要。
具体来看,EDM调度器最重要的改进在于其统一噪声强度的概念,将离散噪声改进为连续噪声。通过调整噪声强度参数,可以更灵活地控制模型采样步数和增强生成效果。EDM默认的
配置已经能够提供良好的采样效果,但针对特定应用场景,可以通过实验进一步调优参数。
数据集精制与预处理
高质量视频生成依赖于高质量的数据集。SVD论文中提出了一套系统性的数据精制流程,包括数据的标注与过滤。合理地精制数据集,确保训练集的多样性和标注的准确性,能够显著提升模型的生成效果。
首先,使用多种自动化工具对原始视频进行剪辑,剔除无用片段,将视频切割成连续的场景。然后,采用多个标注模型对视频添加文字描述,并利用大语言模型润色描述,确保标注的准确性和一致性。最后,通过数据过滤方法,生成一个高质量的过滤数据集(LVD-F),用于模型训练。
多GPU并行训练
Stable Video Diffusion在处理大规模视频生成任务时,可以通过多GPU并行训练提高训练效率。推荐使用PyTorch中的DistributedDataParallel模块,将数据分配到多个GPU上并行计算。此外,NVLink桥接可以显著提升GPU之间的通信效率,减少训练时间。
通过多GPU训练,不仅可以缩短训练时间,还能扩展模型的容量和复杂度,进一步提升生成效果。在部署多个GPU时,应确保系统散热良好,并合理配置电源,以防止因过热或供电不足导致的系统不稳定。
应用场景与效果展示
高分辨率文本生成视频

Stable Video Diffusion最直接的应用是高分辨率的文生视频生成。通过多阶段训练和细致的数据精制,SVD能够在576x1024分辨率下生成高质量的视频内容。生成的视频不仅具有逼真的视觉效果,还能通过文本描述实现精确的内容控制。
图像生成视频与视频插帧

除了文本生成视频,SVD还可以通过微调生成图生视频模型。通过调整U-Net的交叉注意力层,实现从图像到视频的转换。这一功能特别适用于创意动画和视频制作,能够将静态图像转换为具有连续运动的视频片段。
视频插帧也是SVD的重要应用之一。通过对视频片段的首末帧进行约束,生成中间帧,从而实现视频补帧。这一技术在视频修复、帧率提升等领域具有广阔的应用前景。
多视角生成
多视角生成是指从3D物体的某一视角图像生成其他视角的图像,从而还原物体的三维形态。SVD通过在3D数据集上微调基础模型,能够生成环绕物体旋转的视频,从多个视角展示物体。这一技术在虚拟现实、三维建模等领域具有重要应用。
Stable Video Diffusion作为当前最为先进的视频生成模型之一,其广泛的应用前景和优异的生成效果备受关注。为了流畅运行SVD,合理的硬件与软件配置至关重要。高性能的CPU、多核GPU、充足的内存和快速存储是基础;合适的操作系统、深度学习框架和必要的库依赖则是保障。
通过优化模型调度器、精制数据集和采用多GPU并行训练,可以进一步提升模型的生成效率和效果。Stable Video Diffusion不仅在视频生成、视频插帧、图像生成视频等方面展现出强大的能力,还在多视角生成等创新性应用中展现出广阔前景。
我们期待未来有更多科研人员和开发者能够充分利用Stable Video Diffusion,探索其更多潜在应用,为视频生成领域带来更多创新和突破。无论是科研实验还是实际应用,SVD都将成为推动视频生成技术发展的重要工具和平台。
通过本文的介绍,希望能够为广大研究者和开发者在部署和运行Stable Video Diffusion时提供有价值的参考和建议。如果你对具体的实现细节感兴趣,建议进一步阅读相关文献和技术报告,深入理解SVD的工作原理和技术细节。结合实际应用需求,进行合理配置和调优,才能充分发挥该模型的潜力,推动视频生成技术的前沿发展。
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。


















 1667
1667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









