







Stable Video Diffusion(SVD)是Stability AI于2023年11月21日发布的视频生成式大模型,是一种用于高分辨率、先进的文本到视频和图像到视频生成的潜在视频扩散模型。该模型不仅支持文本、图像生成视频,还支持多视角渲染和帧插入提升视频帧率,用户可以调整模型选择、视频尺寸、帧率及镜头移动距离等参数。
SVD模型对硬件要求较高,对缺乏硬件资源的普通用户有一定限制,且其支持的图片尺寸较小,限制了应用场景。尽管SVD与其他商用产品在帧率、分辨率、内容控制、风格选择和视频生成时长等方面存在差距,但其开源属性和对大规模数据的有效利用构成了独特优势。
Stable Video Diffusion开源了两种图生视频的模型,一种是能够生成 14 帧的SVD,另一种则是可以生成25帧的 SVD-XL。
模型权重
官方模型权重:
SVD模型权重地址:
https://huggingface.co/stabilityai/stable-video-diffusion-img2vid
SVD-XL模型权重地址:
https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt
SVD 1.1 模型权重地址:
https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt-1-1
fp16模型权重:
SVD-fp16模型权重地址:
https://huggingface.co/becausecurious/stable-video-diffusion-img2vid-fp16
硬件环境
内存:32G
显卡:24G
安装依赖
下载Git仓库
git clone https://github.com/Stability-AI/generative-models
cd generative-models基础环境配置
conda create --name svd python=3.10 #建议选择 python3.10及以上版本
conda activate svd
pip install -r requirements/pt2.txt
pip install .
# 安装ffmpeg
sudo apt install ffmpeg开始运行
cd generative-models
streamlit run scripts/demo/video_sampling.py --server.address 0.0.0.0 --server.port 8888在运行后,程序会自动去下载两个模型:
如果网络不好,可以手动下载下来后,分别放到路径如下:
/root/.cache/huggingface/hub/models–laion–CLIP-ViT-H-14-laion2B-s32B-b79K
/root/.cache/clip/ViT-L-14.pt运行成功后,在浏览器打开url
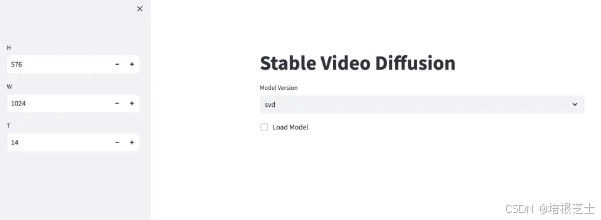
点击下拉箭头,选择不同模型版本,再勾选 load Model。
之后就可以输入图片生成视频。


















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









