









SD的大模型带来了丰富的艺术效果,不同的模型之间的艺术效果区别很大。所以现阶段利用SD的一大作用就是风格迁移,将相同的内容赋予不同的艺术效果,以此带来更多的创造灵感。本篇章将介绍几种风格迁移的方法。
一、图生图+ControlNet
1.1操作步骤概述
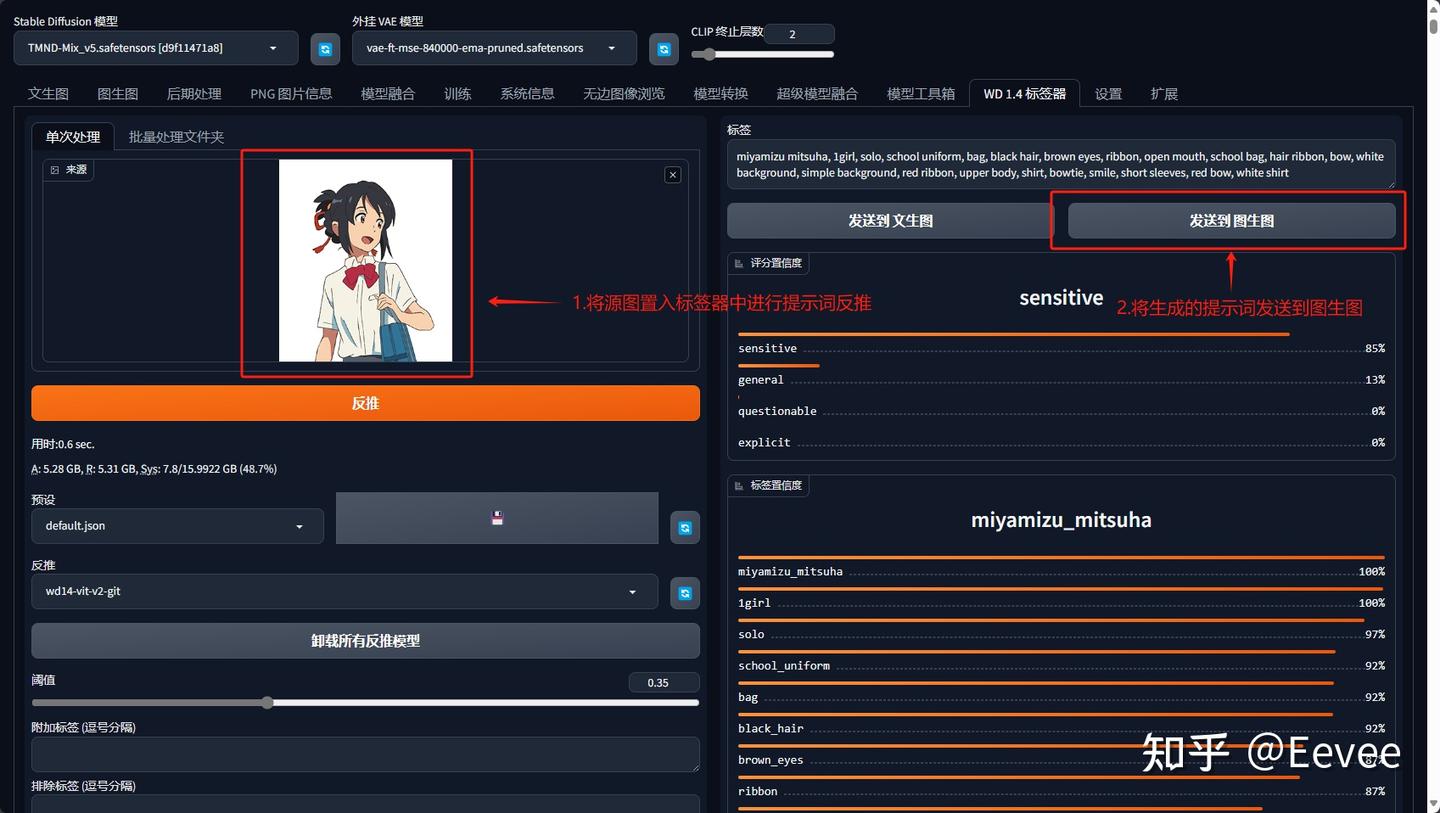
步骤1-2
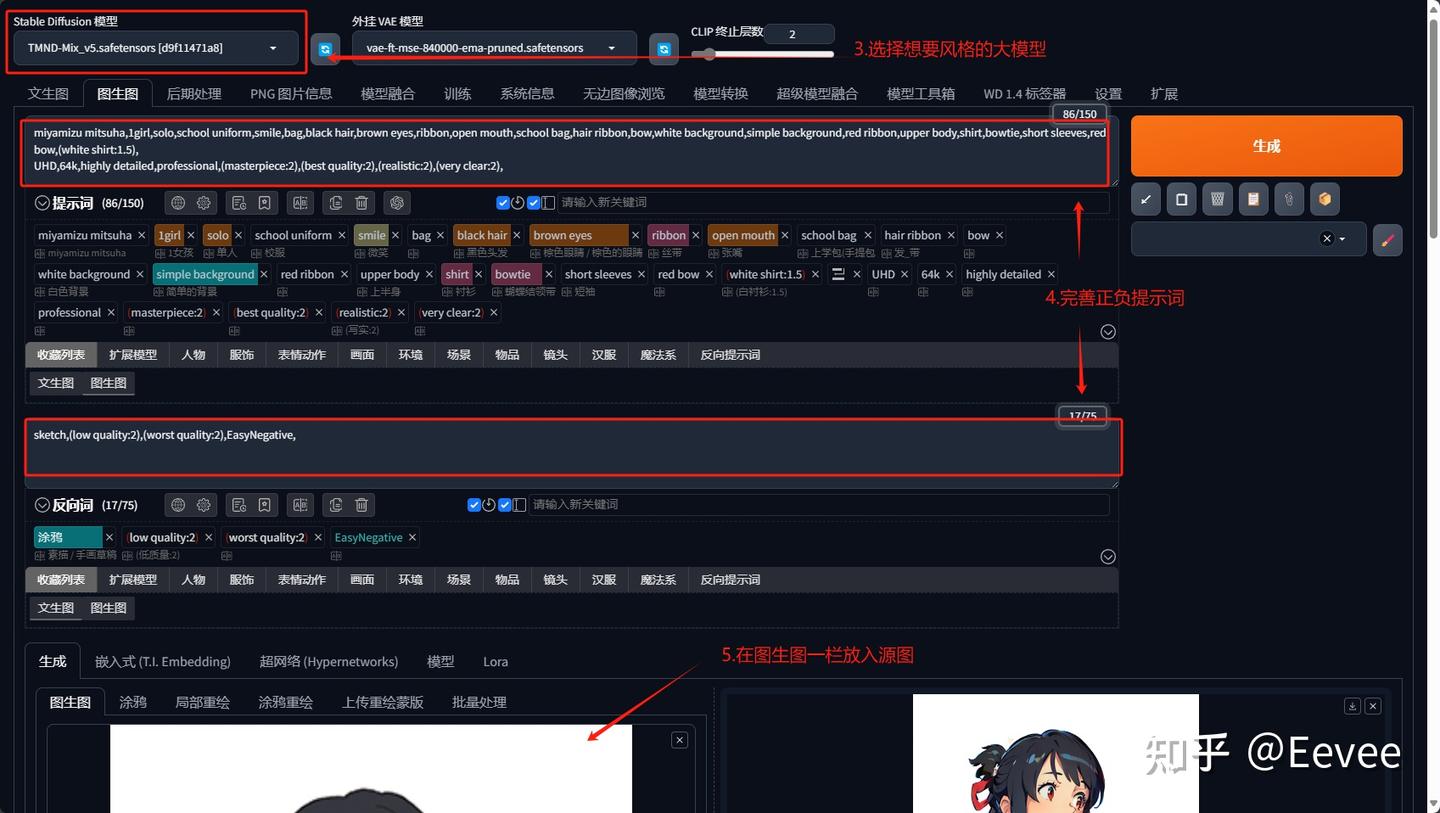
步骤3-5

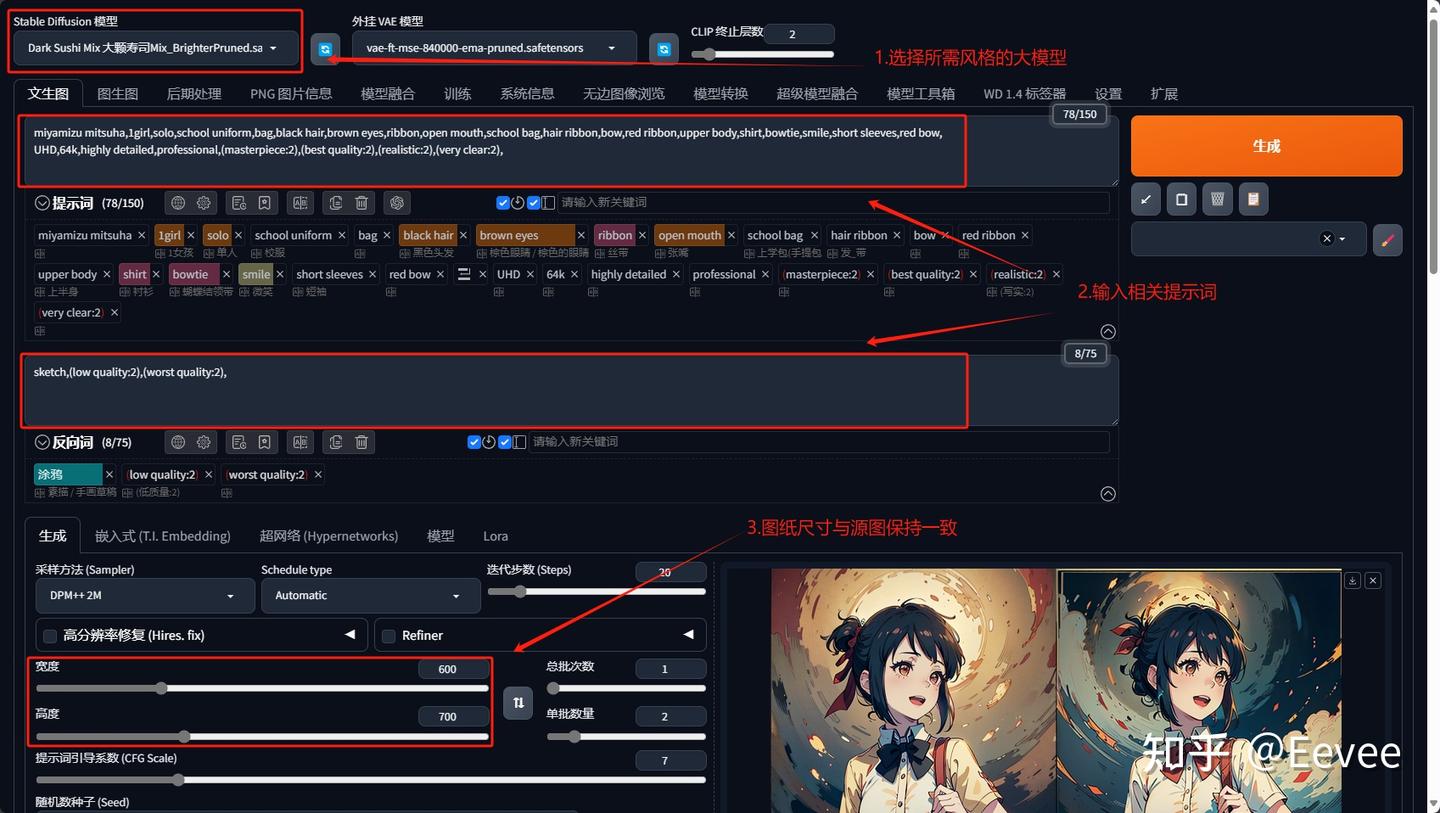
步骤6-7
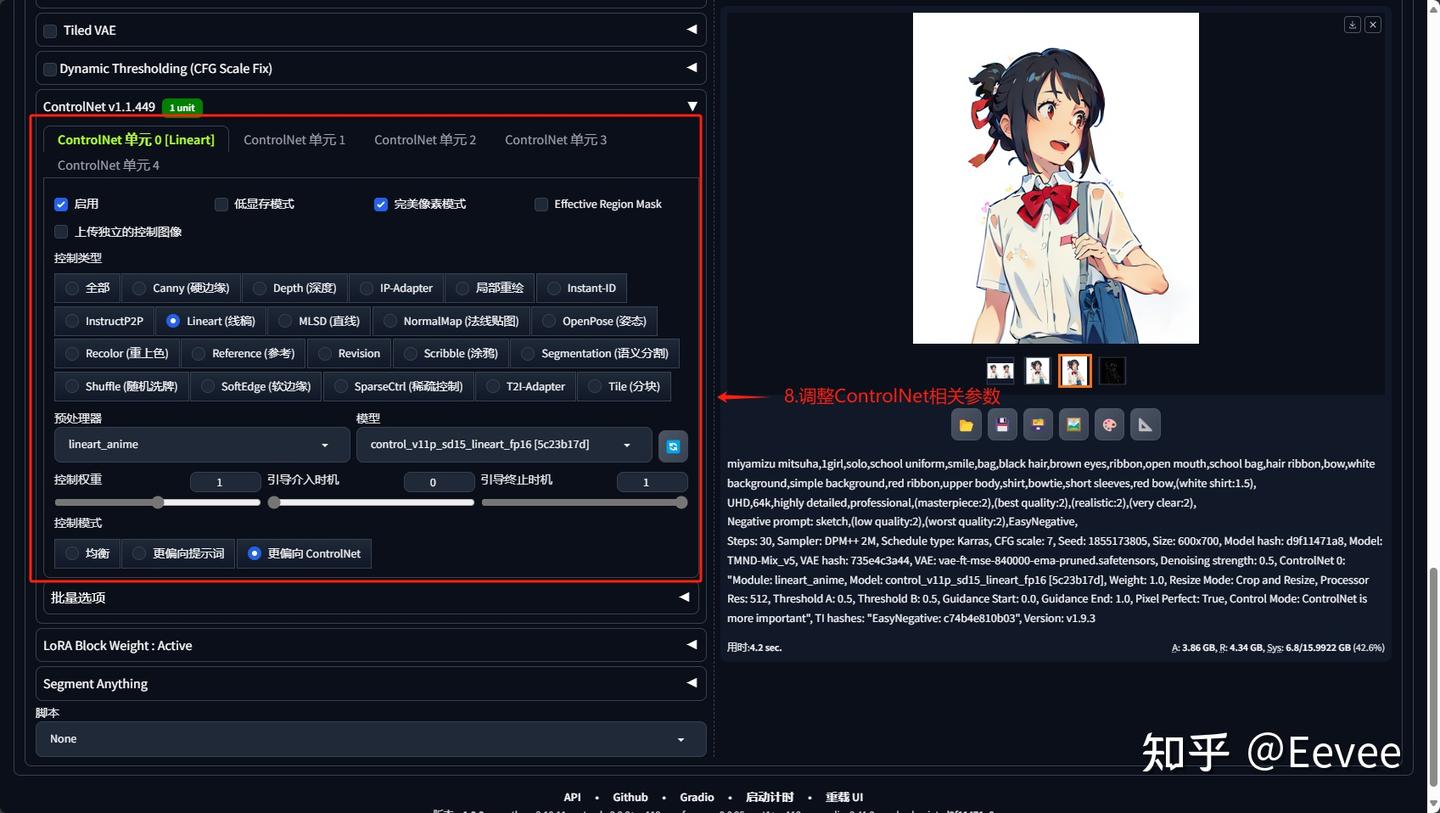
步骤8
1.2相关参数研究
该方法迅速快捷,能保持画面基本一致的情况下,快速实现风格的转变,用此方法进行风格迁移的重点在于:
①大模型的选择
大模型的选择直接决定了我们所迁移的风格。
②重绘幅度
一般来说重绘在0.4-0.6之间,能较好保留源图画面结构的情况下,将画风融入画面之中。如果是二次元转换三次元,那重绘幅度就需要适量提高。以下是利用新海诚电影《你的名字。》中的宫水三叶作为源图,进行的一些风格转换研究。

源图

TMND-Mix_v5

anything_v5

Drak Sushi

ghostmix
用此方法不仅可以实现风格迁移,还能实现二次元转三次元的真人风格,**但需要注意的是,由于动画作画风格,使得动画中的人物比例往往与真实世界中不同,所以在实现二次元的三次元转换时,需特别重视源图的人物比例是否符合现实世界的经验,避免出去过于诡异的画面。**本次想利用此图生成三次元真实风格人物,但实践后发现,人物比例与真实世界相差较大,显得画面较为诡异。
二、文生图+ip_adapter+ControlNet
通过第一种方式得到的风格迁移,相当于是照着源图用不同的风格重新画了一篇,但画面差异不会很大,就比如主人公的衣服,领结等特征还是大部分保留。如果我们想改变结果能更猛一点,可以考虑使用IP-Adapter。
IP-Adapter是由腾讯AI实验室开发的图片生成项目。通过笔者的实验,我认为它更接近风格的相融,把参考图的风格融入源图中。

案例示意
2.1操作步骤概述
步骤1-3
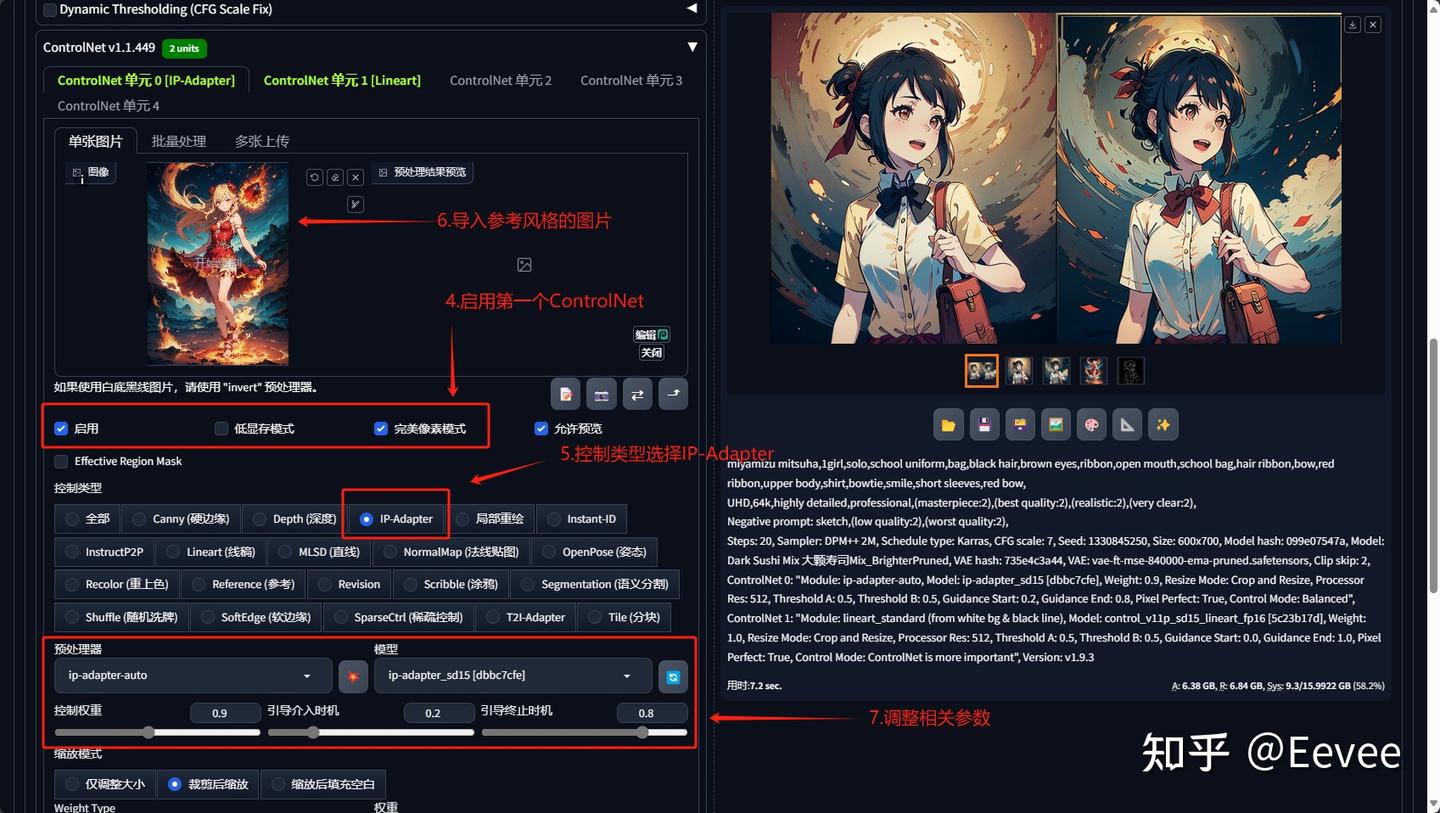
步骤4-7
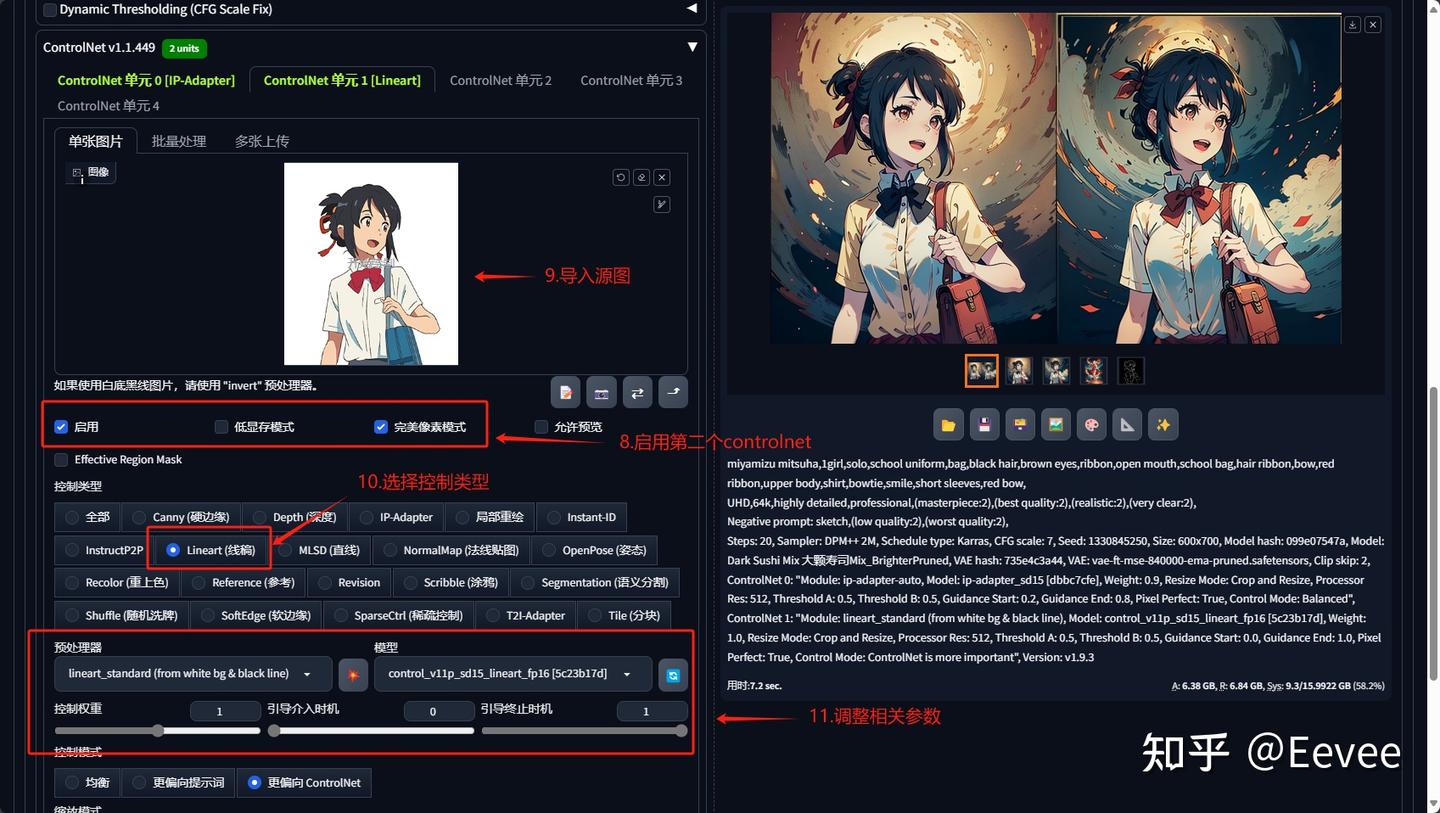
步骤8-11
2.2相关参数研究
用此方法生成风格改变的图
步骤一:大模型的风格尽量与参考图保持一致,这样能最大限度地实现风格相容;
步骤二:同理提示词也应尽量与参考图相关;
步骤七:预处理器的模型与控制权重可根据需要的效果调整。
以下是一些用第二种方法生成的图纸,通过比较我们也可以直观地发现与第一种方式的区别。






此方法形成风格相融的图片能最大限度保留参考图的色彩构成与艺术风格。同时它对参考图的包容性也很高,不管是什么样式的图纸都能较好地嵌入到生成的图当中。这就有点像一张图的Lora能对所有的源图做类似的风格相融。
因此还能用此方式生成一系列风格相融的新图,形成系列的更新。

图片对比合集
现在AI绘画还是发展初期,大家都在摸索前进。
但新事物就意味着新机会,我们普通人要做的就是抢先进场,先学会技能,这样当真正的机会来了,你才能抓得住。
如果你对AI绘画感兴趣,我可以分享我在学习过程中收集的各种教程和资料。
学完后,可以毫无问题地应对市场上绝大部分的需求。
这份AI绘画资料包整理了Stable Diffusion入门学习思维导图、Stable Diffusion安装包、120000+提示词库,800+骨骼姿势图,Stable Diffusion学习书籍手册、AI绘画视频教程、AIGC实战等等。
完整版资料我已经打包好,点击下方卡片即可免费领取!
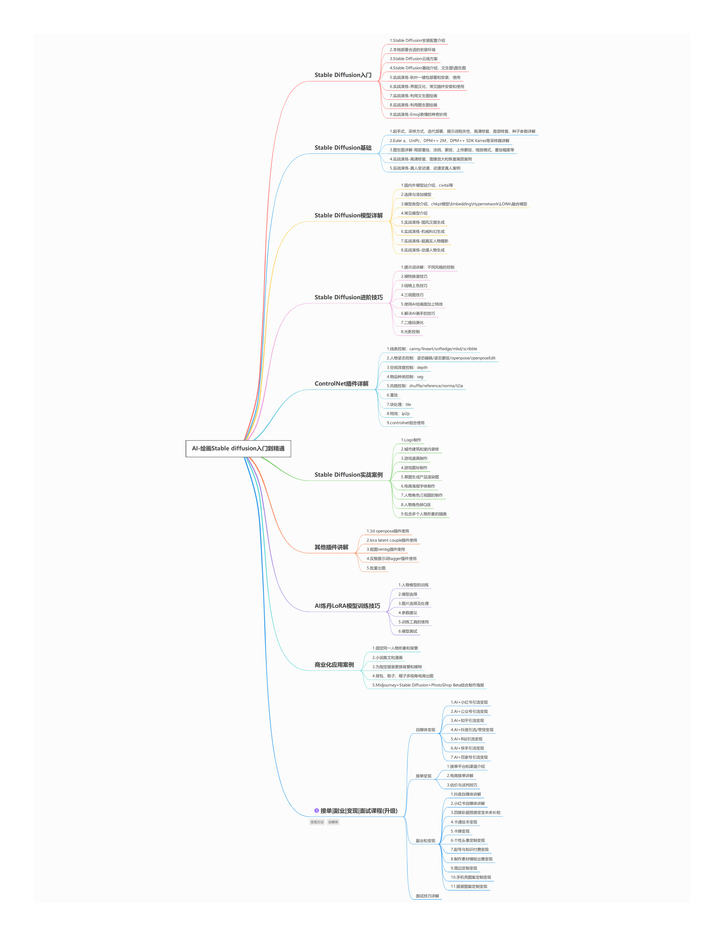
【Stable Diffusion学习路线思维导图】
【Stable Diffusion安装包(含常用插件、模型)】
【AI绘画12000+提示词库】
【AI绘画800+骨骼姿势图】

【AI绘画视频合集】
这份完整版的stable diffusion资料我已经打包好,点击下方卡片即可免费领取!


















 3941
3941

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









