










在电商设计中,实际运用于工作的开始其实就是炼丹,也就是lora模型的训练。
我们需要根据自己的类目和产品训练适合自己的模型和场景,那今天我就跟大家讲一讲模型炼丹的那些事。
---------------------------------------------------------------------------
1-
首先:
选择合适的炼丹炉,这里我经常使用的是秋葉的开源训练工具lora-scripts
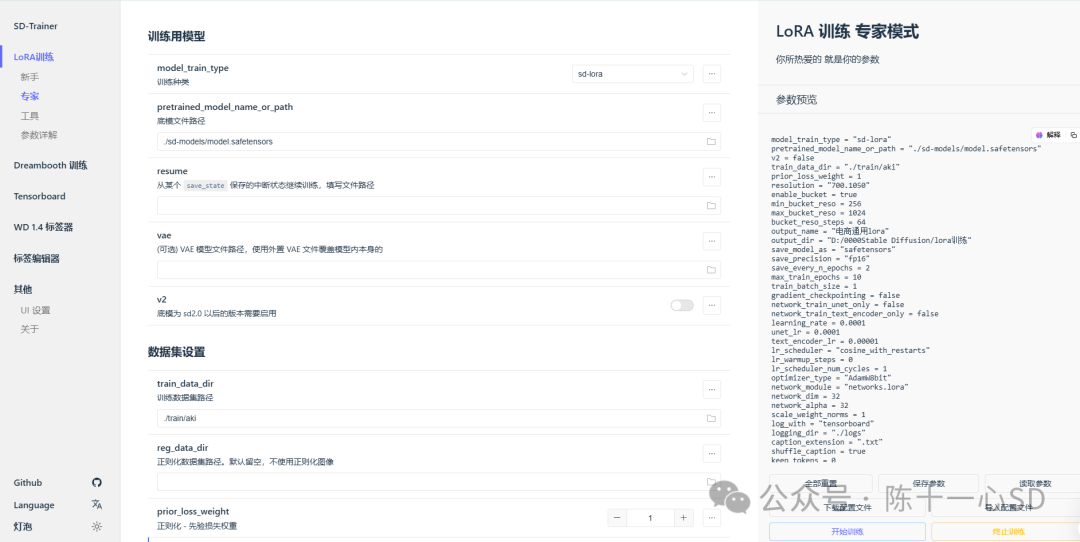
之所以使用这样的模型训练器是因为它可以自主的设置更多的数据、步数,图片尺寸,已经训练精度,能够完全把控,而市面上也有一些网站的训练器,目前我并没有觉得有哪个比这个好用。
2-
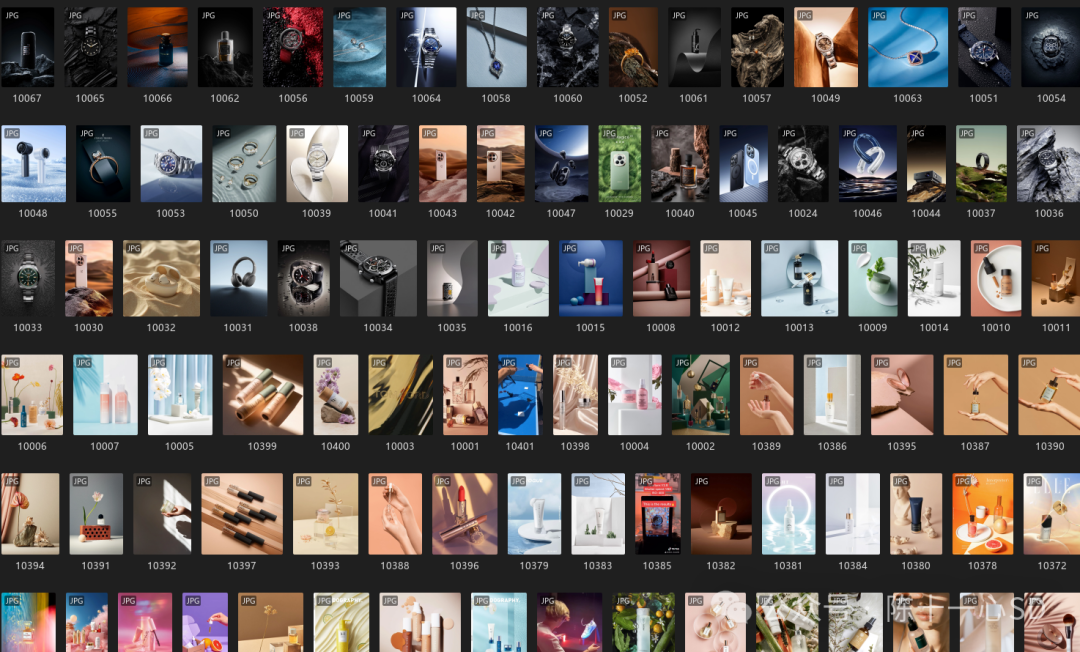
选好了炼丹炉,接下来就是需要收集足够多的图片素材,这里我推荐收集200张左右就够了,也有用十几张或者几千张的,但数量太少,训练的最终模型出图效果不会太好,图片数量太多,炼丹对电脑的要求又太高,甚至动辄两三天训练不成一个模型,这样也不利于我们测试模型效果。
另外需要注意的是,在收集图片的时候尽量保持它们的长宽形态一致,竖图海报就全是竖图,横屏就全是横屏,不要混合在一起,最小尺寸控制住,比如所有图都是高于500的宽度的,这样最终的模型出图效果才能保持水准一致。
3-
接下来就可以给图片打标
打标是最关键的一步,意思就是我们需要提取每张图片的关键词信息,
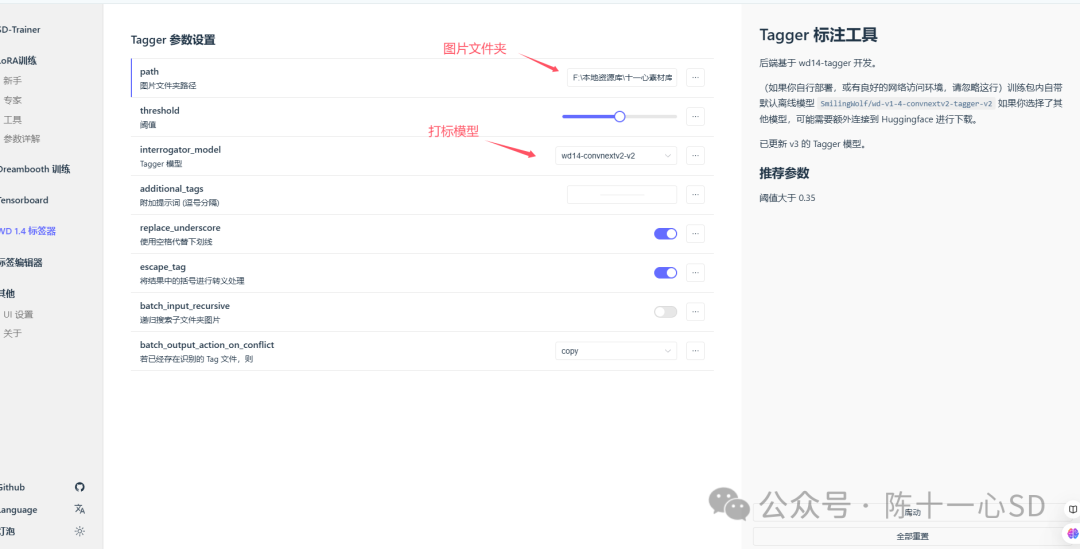
这里我们使用WD1.4标签器,将图片的文件夹目录和打标模型选上就可以了,右下角启动,标签器会自动进行打标,
这里有一个小问题:阈值推荐大于0.35,实际上是数值越小,所得到的打标词越多,虽然会稍微有些不精准,但我一般还是会设置0.2-0.35之间这样的数值。

最后图片文件夹中就会得到每张图的关键词文件:
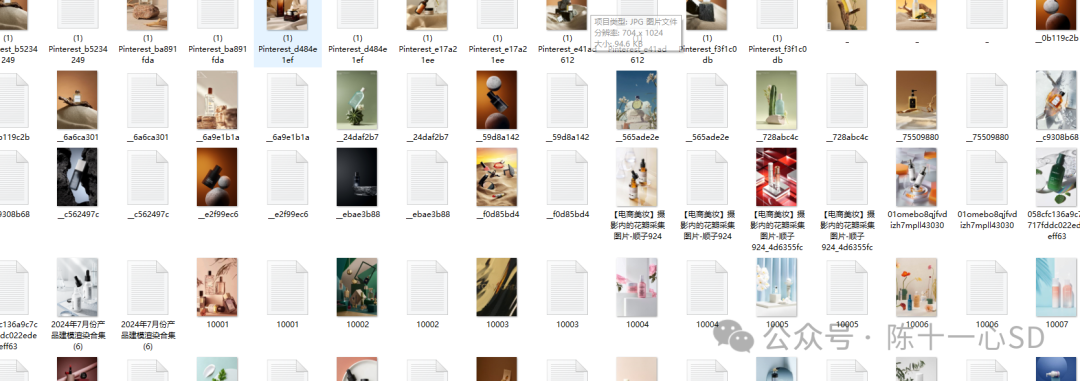
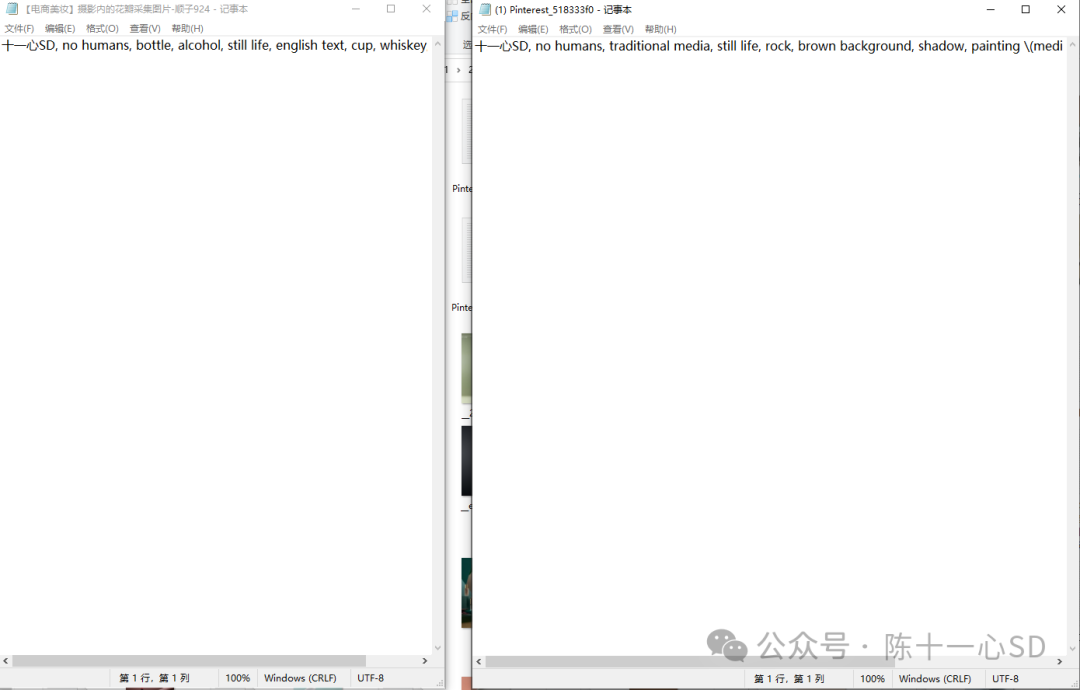
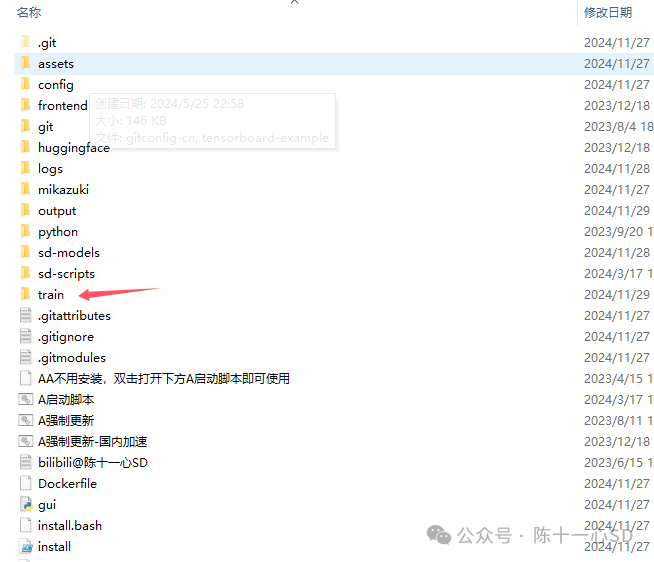
我们需要把这个文件夹复制到训练器的后台文件夹中,找到一个叫train的文件夹,放进去之后给文件夹随便命个名,我这里用001代替,
然后我们需要在这个文件夹中再新建一个空文件夹,命格式为 10_001,把图片和关键词文件全部都放到这个文件夹中,这一步的含义其实就是指:我每张图要训练的步数是10,总调用的文件夹是001. 保证这两个文件夹就可以了,tips:下划线别打错哦。
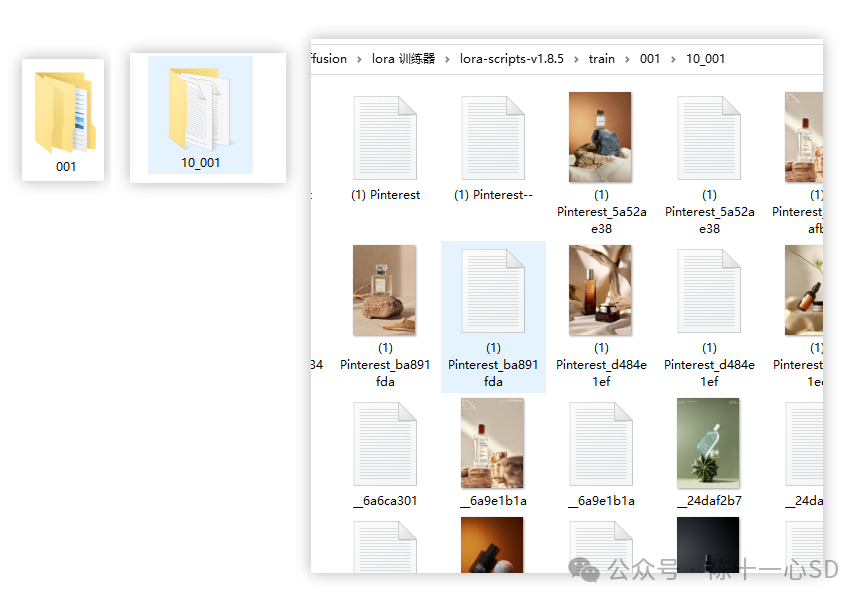
4-
到这一步,我们就可以正视开始训练模型了,选择训练器新手模式(新手足够了),如图填写各个目录和数值,开始训练。

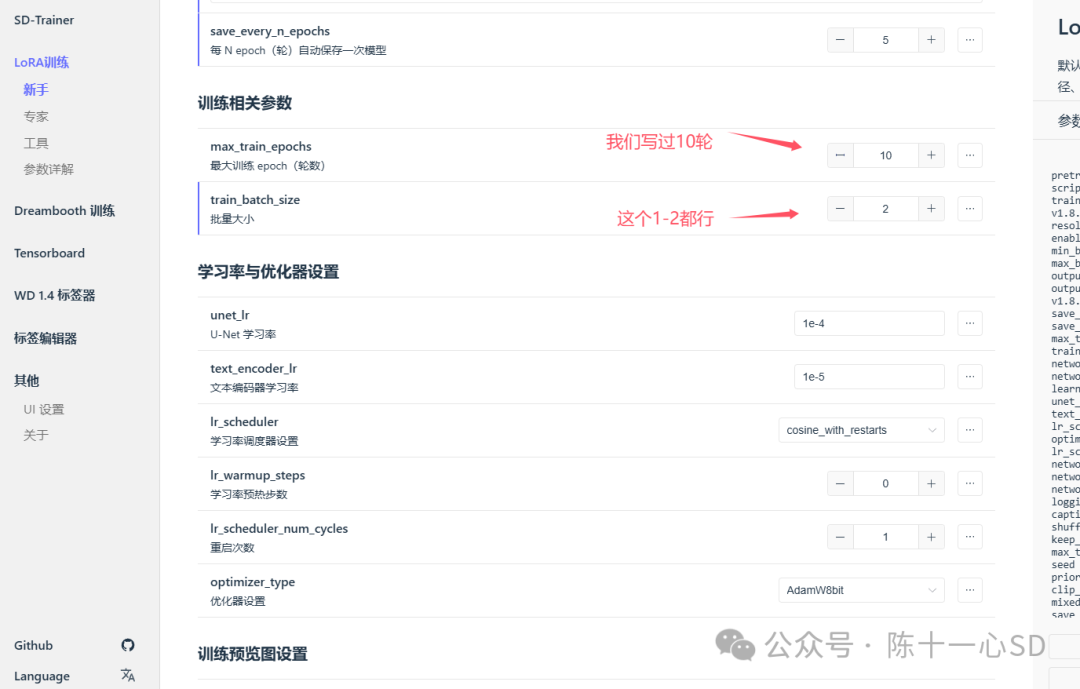
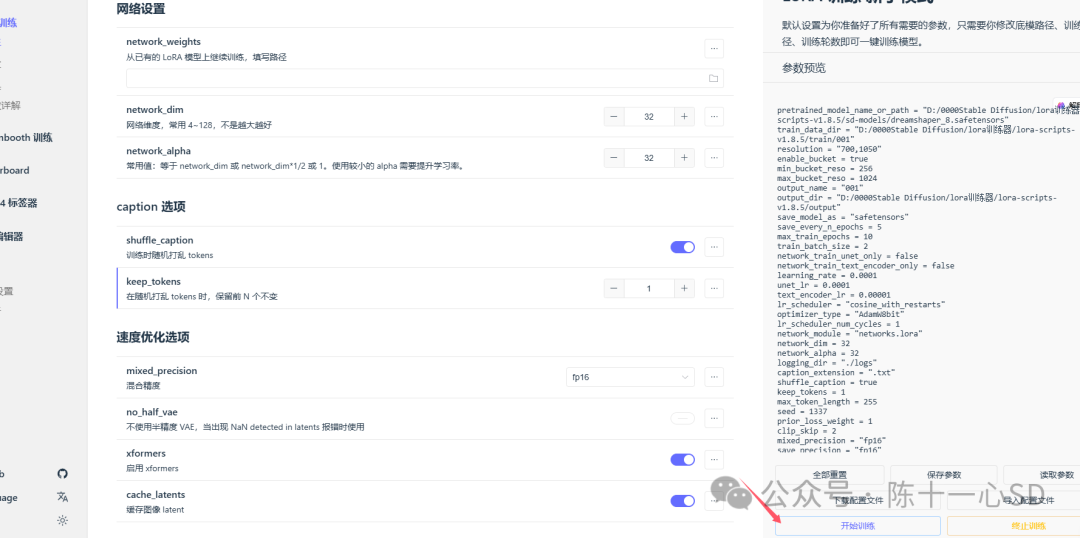
训练的速度取决于图片大小和多少以及电脑配置,因人而异,耐心等待即可,训练过程中后台一定不要随意关掉。
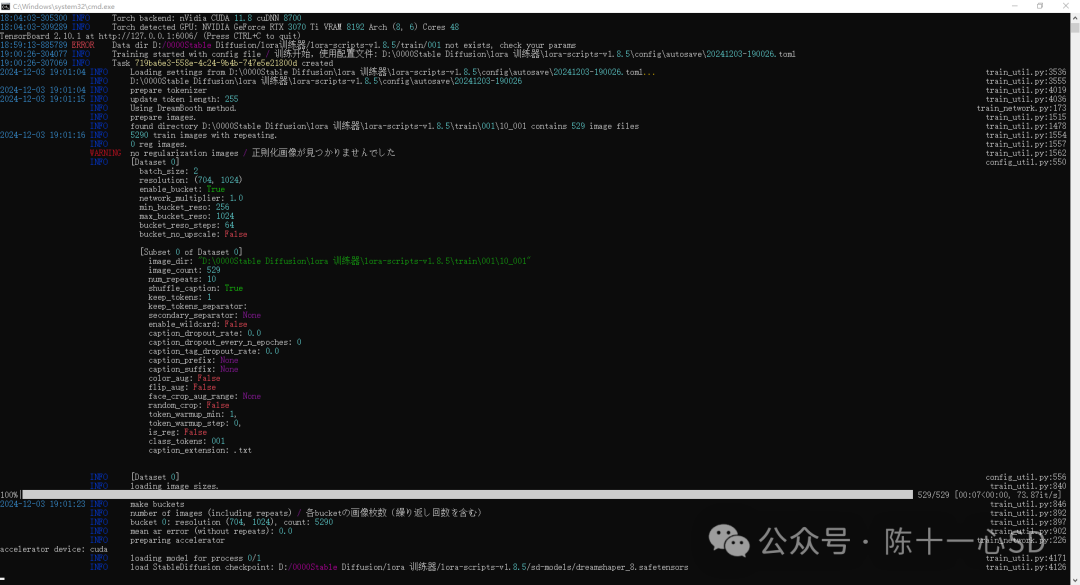
--------------------------------------------------------------------------
好了,这就是本次炼丹流程的分享,喜欢的话就给我点个赞吧,下期再见。
现在AI绘画还是发展初期,大家都在摸索前进。
但新事物就意味着新机会,我们普通人要做的就是抢先进场,先学会技能,这样当真正的机会来了,你才能抓得住。
如果你对AI绘画感兴趣,我可以分享我在学习过程中收集的各种教程和资料。
学完后,可以毫无问题地应对市场上绝大部分的需求。
这份AI绘画资料包整理了Stable Diffusion入门学习思维导图、Stable Diffusion安装包、120000+提示词库,800+骨骼姿势图,Stable Diffusion学习书籍手册、AI绘画视频教程、AIGC实战等等。
完整版资料我已经打包好,点击下方卡片即可免费领取!
【Stable Diffusion学习路线思维导图】
【Stable Diffusion安装包(含常用插件、模型)】
【AI绘画12000+提示词库】
【AI绘画800+骨骼姿势图】

【AI绘画视频合集】
这份完整版的stable diffusion资料我已经打包好,点击下方卡片即可免费领取!


















 1459
1459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









