










Stable Diffusion 是一种基于深度学习的图像生成模型,它利用了潜扩散模型(Latent Diffusion Model)提出的机器学习模型结构为基础进行绘图。
LDM包括:Conditioning(条件输入)、Latent Space(潜空间)、Pixel Space(像素空间)。
其中,Conditioning常用语义图谱(Semantic Map)、文本(Text)、数据表示(Representations)、图像(Images)等类型。这些条件被编码成向量,用来引导生成过程。
Latent Space(潜空间)通过变分自编码器(VAE)或其他类似的编码解码架构构建。当条件输入到LDM时,它首先被编码成这个潜空间中的一个点(即一个向量),然后所有后续的操作(比如去噪过程)都在这个较低维度的潜空间中进行。
Pixel Space(像素空间)图像或视频中每个像素点所构成的空间,它是数字图像处理和计算机视觉中最基础且直观的数据表示形式。在这个空间里,每个像素都对应于图像中的一个特定位置,并携带有关该位置颜色和亮度的信息。
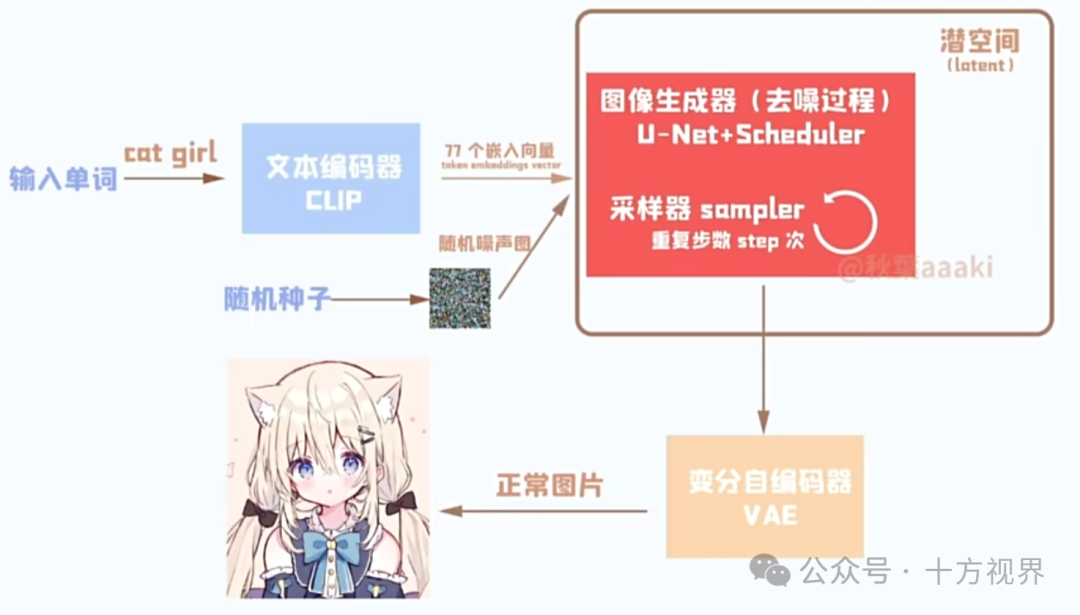
个人理解的SD生图过程为:潜空间(随机种子)随机生成噪声图为起点,条件输入被编码为低维向量表示;通过扩散模型向噪声中添加结构化信息(即从纯噪声逐渐演化到与目标分布相似的过程),U-Net神经网络(运算结构呈现U字形)在扩散过程中指导图像去噪;当扩散过程完成,使用变分自编码器(Variational AutoEncoder)的解码部分将低维表示映射回高维的像素空间,恢复出所有细节和颜色信息。
书接上文,搞明白基于LDM架构的SD绘图原理(注意不是算法),对于理解WebUI和ComfyUI绘图各环节模型输入及相应参数的设置具有重要作用,后续也会针对特定功能和模型进行仔细的梳理。
回到开始的疑惑,来系统梳理下SD常用的模型类别及基础规则。
一般来讲,SD常用模型主要包括Checkpoint、LoRA和LyCORIS、VAE、ControlNet、Embedding 、Clip等类型。
Checkpoint是SD画图的必备基础,俗称底模,决定后续画风的内容和基本输出风格。
LoRA(Low-Rank Adaptation,低秩适应或低秩微调)模型,是在原始模型的基础上,对选定层(通常是全连接层或卷积层)的权重矩阵应用低秩分解,只对这组“低秩矩阵”进行更新,保持其它参数不变。该类模型用来针对特定的艺术风格、对象类型等进行快速微调,而无需重新训练整个模型。需注意区分与ContolNet的不同。
与LoRA类似,LyCORIS(Low-rank Compression and Optimization for Rapid Incremental Synthesis,低秩压缩与优化以实现快速增量合成)模型,是一种用于加速和优化基于扩散模型的图像生成过程的技术。它借鉴了LoRA的思想,但又更进一步,不仅限于简单的权重矩阵分解,还结合了其他优化技术以提升效率。它允许用户以增量的方式添加新的知识到现有模型中,而不需要从头开始重新训练整个网络。
VAE(Variational Autoencoder,变分自编码器),旨在将输入数据压缩到一个较低维度的表示(编码),然后尽可能准确地重建原始输入(解码)。其中,编码器(Encoder)是将输入数据映射到一个低维的潜空间;解码器(Decoder)是从潜空间中取样并尝试重建原始输入。生图时,VAE的解码器类似在底模上加一层滤镜,微调输出的风格。有些Checkpoint模型已经合并了VAE模型。
ControINet模型,主要解决了画图输出不稳定问题,使生成模型不仅依赖于随机性和文本提示,还可以通过引入具体的视觉或结构化信息来实现更加精确和可控的图像生成。常见的视觉特征包括边缘检测、分割图、深度图等。
Embedding(嵌入)/HyperNetwork(超网络)/AestheticGradient(美学梯度)模型,均是在底模的基础上修改画面的风格,只是实现的算法和方式有所不同。
Embedding(嵌入式系统)是一种将离散的符号或类别信息映射到连续向量空间的技术,包含文本嵌入和图像条件嵌入。在图像生成任务中,将标签、文本描述或其他形式的条件信息转换为嵌入向量,用以指导生成过程。SD的文本提示通过 CLIP 模型转化为条件嵌入,从而影响生成图像的内容和风格。
Hypernetwork(超网络)是一个用于生成另一个神经网络(即目标网络)权重的网络。它可以根据输入条件动态调整目标网络的参数,使得目标网络能够在不同条件下表现出不同的行为。主要功能包括条件生成和参数高效微调。在生成模型中,Hypernetwork 可以用来生成 U-Net 或其他生成组件的条件依赖权重,从而增强模型的表达能力和灵活性。
Aesthetic Gradient(美学梯度)是指在优化过程中引入的一种损失项,旨在引导生成模型产生更符合人类审美标准的结果。它可以是基于预训练的美学评分模型,也可以是从大量高质量图像中学到的特征表示。主要功能是提升质量和保持风格一致性。
在实际应用中,这三个模型往往协同工作以实现更复杂和高效的生成任务。例如,在 Stable Diffusion 中,文本提示首先被转化为嵌入向量,然后通过 Hypernetwork 动态调整生成模型的权重,最后借助 AestheticGradient 来优化生成结果的质量和风格。这种组合方式不仅提升了生成内容的多样性和可控性,还保证了最终输出的视觉效果达到较高的美学标准。
Upscale(超分辨率模型)是一种专门用于提升图像分辨率的技术。它允许用户将低分辨率的图像转换为高分辨率版本,同时保持或增强图像的质量和细节,通常作为后处理步骤集成到生成流程中。现代 Upscale 模型通常使用卷积神经网络(CNN)、生成对抗网络(GAN)、或扩散模型等深度学习技术来实现超分辨率任务。
CLIP(Contrastive Language–Image Pretraining对比语言-图像预训练模型)多模态模型,旨在学习图像和文本之间的联合表示。CLIP 通过*对比学习**(contrastive learning)*的方法,将图像和文本映射到一个共同的嵌入空间中。包括基于Transformer架构的文本编码器,和基于ResNet、Vision Transformer (ViT) 等视觉模型的图像编码器。SD中,CLIP 提供了强大的条件转化能力,允许用户通过简单的文本提示来指导图像生成过程,确保生成的内容符合预期。
Motion(运动模型),是一种专门用于生成视频或动画序列的扩展模块,主要是AnimateDiff(动画差分)插件和对应的模型实现。目前大多数 Motion 模型擅长生成较短的视频片段。
Wildcard(通配符),是一种用于简化和增强文本提示(prompt)的辅助机制,实现在提示词中使用通配符来替代具体的词语或短语,从而实现更加灵活和多样化的图像生成。
了解了常用模型组件的基本概念和功能,接下来看下各自的特点和使用规则。
CheckPoint模型,是SD绘画基础大模型,常见的分为写实风、二次元和2.5D(3D),体量在GB级别。格式包括.ckpt和.safetensors两种,前者是用pickle序列化的,意味着可能会包含恶意代码;后者是用numpy保存的,只包含向量数据,没任何代码,加载更快且安全。
目前SD官方的常见大模型主要有普通模型(SD1.5/2.0/2.1等)、SDXL模型、CascadeStage模型。SD1.5前者基于512512分辨率训练,可适当调整为512768(2:3)的竖图或768512(3:2)的横图;SD2.1基于768768训练,生态不如SD1.5,效果也一般般。SD普通模型容量通常2-3GB。SDXL基于1024*1024分辨率训练,可适当调整至1100-1200,容量在6-8GB,需要更多的显存空间,比较耗费资源,生成耗时比SD1.5慢3-6倍,生态也没有1.5的好,但是出图不错。SDXL兼容性其实并没有普通模型的好,更常用的还是SD1.5。注意,当自定分辨率与底模训练分辨率差别较大时,容易被程序判定为拼接图像,容易出现多人头或多手多脚情况;可先设置目标比例的相近分辨率,再用Upscale进行放大。当需要生成带文字的图片时,推荐使用新出的CascadeStage模型,生态还没有很成熟。
LoRA微调模型,容量只有100-200MB,必须依附在大模型基础上使用。普通Lora和XL的Lora必须与相应的普通和XL大模型配套使用,不能交叉套用。当在Lora菜单找不到已安装的lora模型时,首先先确定下大模型是否匹配,不匹配时,不支持的就不会显示。
VAE模型,SD绘图时通常作为影响图像色彩空间的色调文件使用,当输出图像色彩异常时,注意看下是否未选择合适的VAE。对于SDXL模型,VAE一定要选择无,或者专门的SDXL_VAE,否则图片色彩便会异常。

Embedding模型,是一种用于生成图片的语言理解组件,可以接受文本提示并产生token embedding。作用在负面提示词框中,内含一系列姿态优化过的负面词,能够有效减少姿态错误。通常有Textual Inversion、Hypernetwork、Dreambooth 和LORA等训练方法。
ControlNet模型,也有普通款与SDXL之分。
Hypernetwork(超网络)模型,用来对SD的模型进行风格迁移(Style transfer),现在已经用的很少了。
其它的模型在具体使用时再单独汇总,此处暂略不表。
以上,对SD常见模型类别和基础规则进行了简要介绍。下节将针对WebUI和ComfyUI的目录结构,梳理各类模型的下载、安装、更新和调用方式进行梳理。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

1.stable diffusion安装包 (全套教程文末领取哈)
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍代码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入门stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 281
281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









