










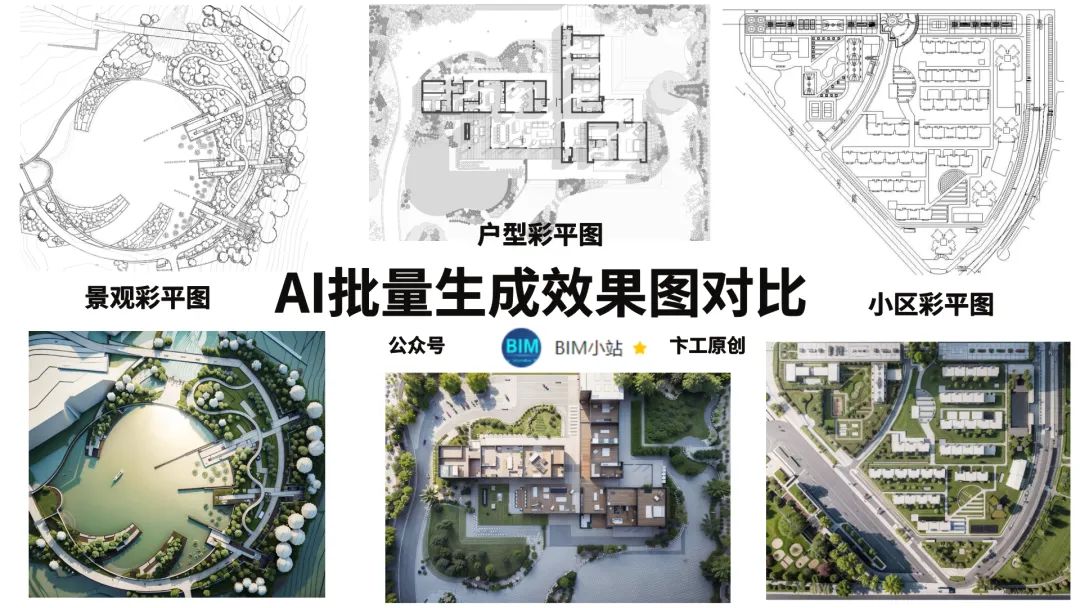
今年最火的关键词就是AI了,本期为AI批量生成彩色效果图的保姆级教程
即利用AI来生成彩色平面图,比如室内户型彩平图,建筑效果图,小区彩平图,景观彩平图,插画分析图等。
( **温馨提示:**全文4125字)包含SD的使用方式,批量生成彩平教学和SD参数原理和设置,AI出图的缺陷,最后是关于AI取代设计师的个人感想)
目前最常用的AI工具为Stable Diffusion和Midjourney。前者出图可以自定义效果,后者则相对随机,达不到具体的成像效果。本期教程主要围绕Stable Diffusion展开。

Stable Diffusion的定义
简而言之,Stable Diffusion(简称SD)是一种人工智能生成图像的软件。通过输入文字描述,SD能够生成对应的图片,无需像以往那样需要手工"绘制"或"拍摄"照片。
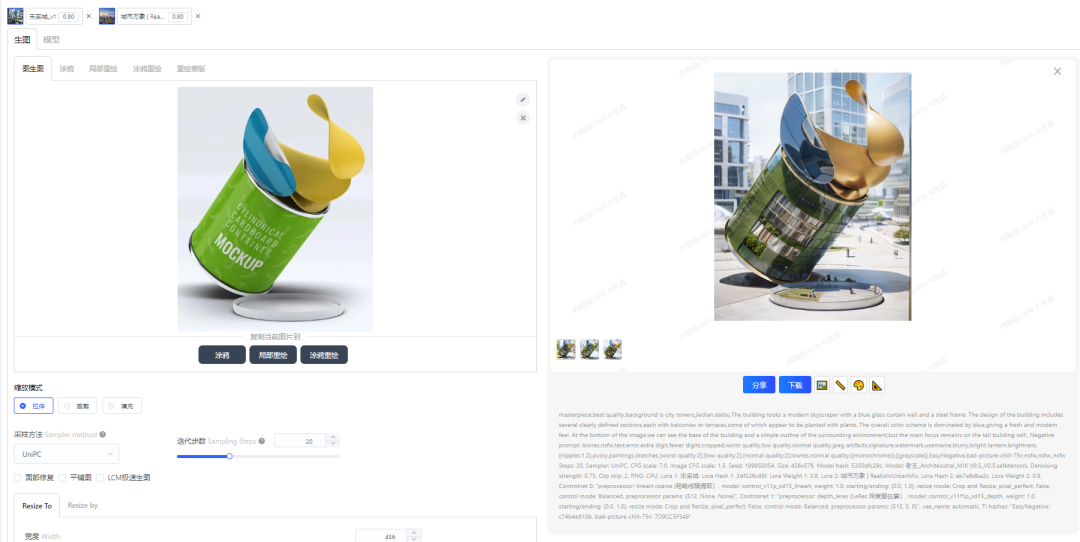
下图为利用SD将薯片盒生成的建筑效果图,上面的首页图也是SD生成的
Stable Diffusion的三种使用方式
1、本地部署软件(哔站搜秋叶有一键安装的整合包),对显卡有要求
2、云端部署(如揽睿星舟),需要购买服务器,成本高
3、SD的国产的****在线平台,主要的平台如下(推荐方式)
哩布哩布:*(特别推荐模型多)*
https://www.liblibai.com
esheep电子羊:*(含工作流模式)*
https://www.esheep.com
吐司:*(有微信小程序,手机可用)*
https://tusiart.com
触手AI:
https://douchu.ai
civitai:*(需要科学工具)*
https://www.civitai.com
全网最细致的喂饭级教程,快跟着卞工,一起来学习吧↓正式开始
出图的·1
)
)
登陆哩布哩布: https://www.liblibai.com(特别推荐模型多)
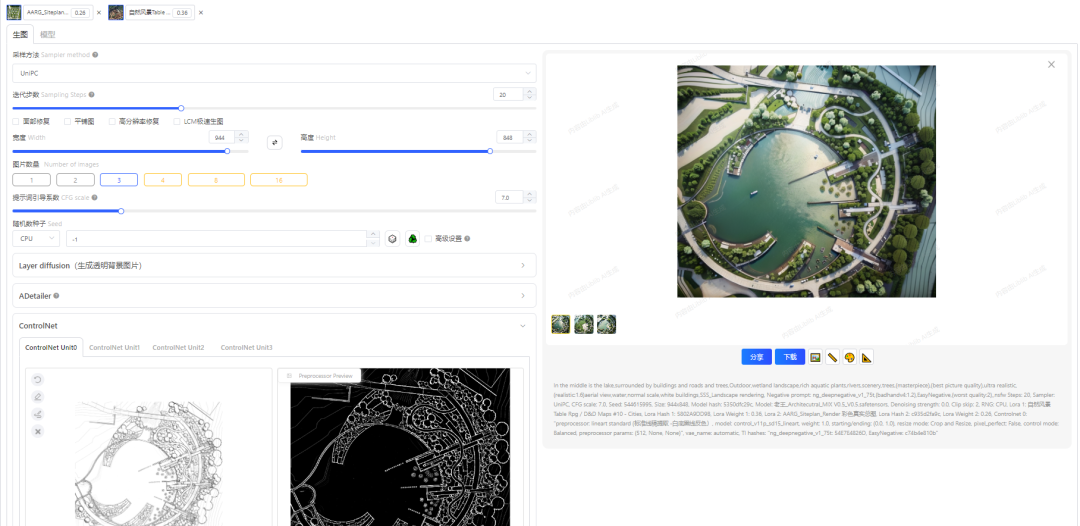
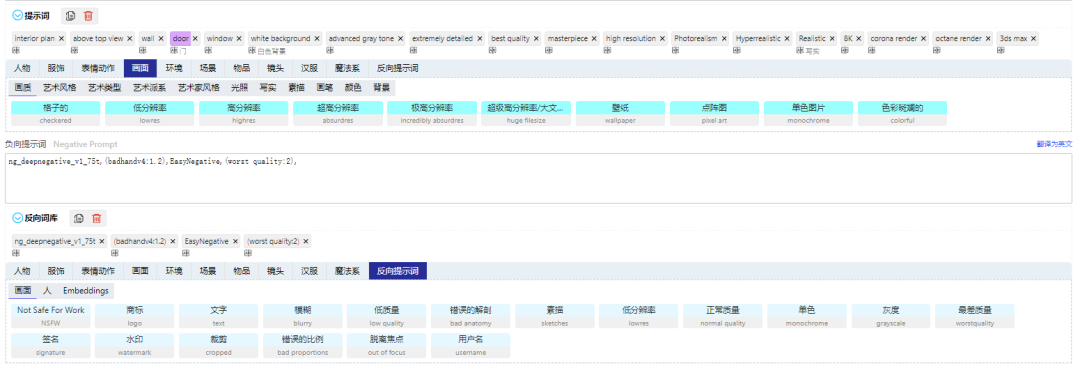
下图以户型图为例子
在网站上调整为下图的SD参数设置,大模型为老王的建筑模型,vae为84000,
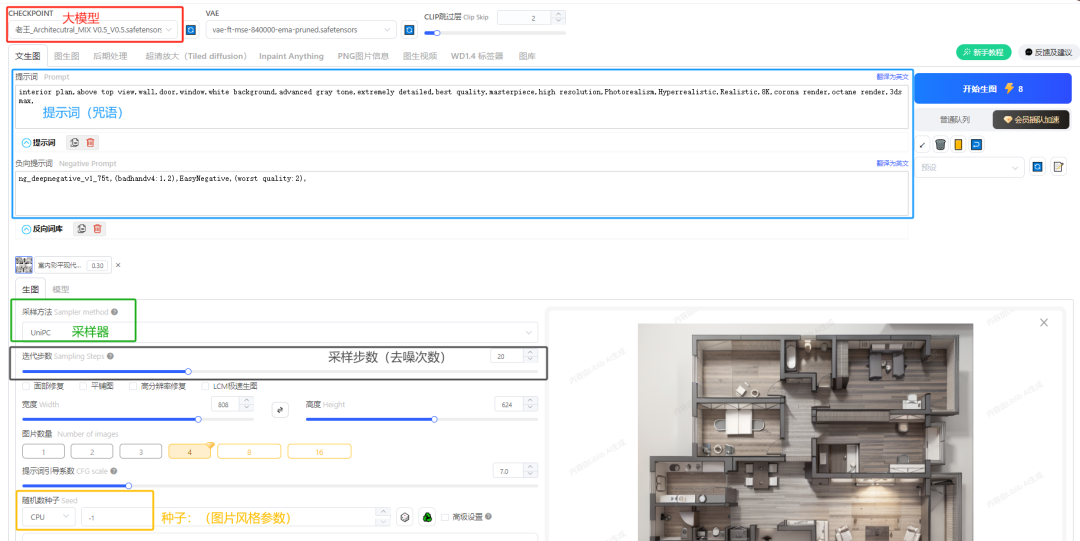 正面提示词:
正面提示词:
interior plan,above top view,wall,door,window,white background,advanced graytone,extremelydetailed,bestquality,masterpiece,high.resolution,Photorealism,Hyperrealistic,Realistic,8K,corona render,octane render,3ds max,
(室内平面图,俯视图,墙,门,窗,白色背景,高级灰色调,非常详细,质量最好,杰作,高分辨率,照片真实感,超现实主义,真实感,8K,电晕渲染,辛烷值渲染,3ds max,)
负面提示词:
ng_deepnegative_v1_75t,(badhandv4:1.2),EasyNegative,(worst quality:2),
**迭代步数:**20(15-35之间为常用区间)
**图片数量:**4(非会员用户可以选3,一次出多张,更好挑选)
随机种子:-1
ControlNet上传我们的建筑图纸,选择Lineart(线稿)或者Canny(硬边缘)可以采集白色建筑底图的墙体和家具等具体轮廓来,固定我们选择保留原图的特点来生成我们想要的效果。
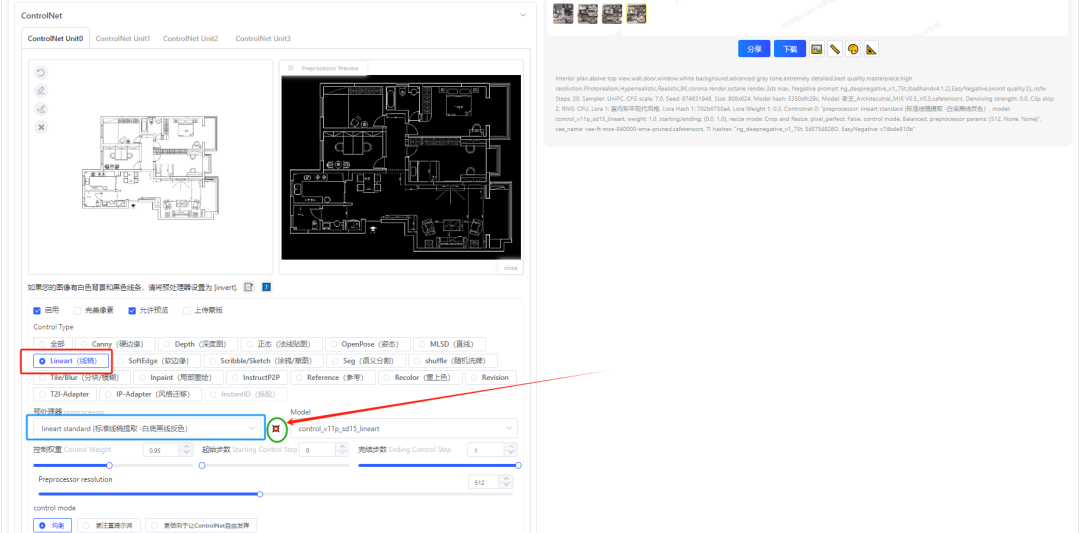
最后点击开始生图就可以了是不是很简单,下面就是如何SD生成以上效果图的原理,包括各项参数的含义和用法,和大家一起学习探讨。文末可以留言,本站免费提供学习资料和交流技术共同进步。
这里我口头化描述:各项参数的含义,大模型相当于相机,不同的相机成像差别很大,比如小型运动相机和影视摄影机。大模型有人像写实类和动漫游戏类,建筑空间类,扁平抽象类,手绘国画类,IP潮玩类等等
本期用的是建筑空间类老王的大模型。
人像写实类:
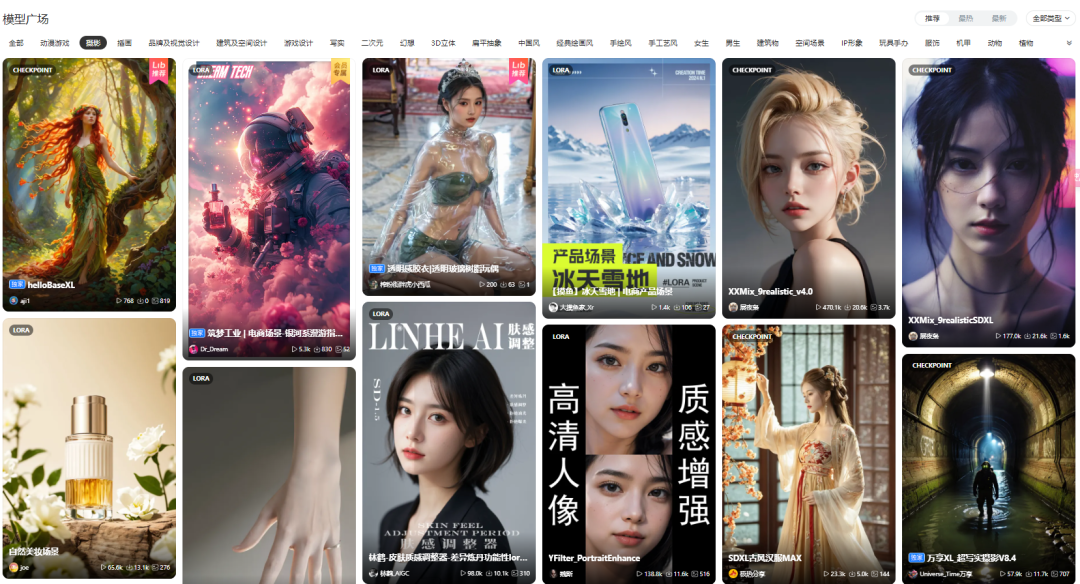
动漫游戏类:
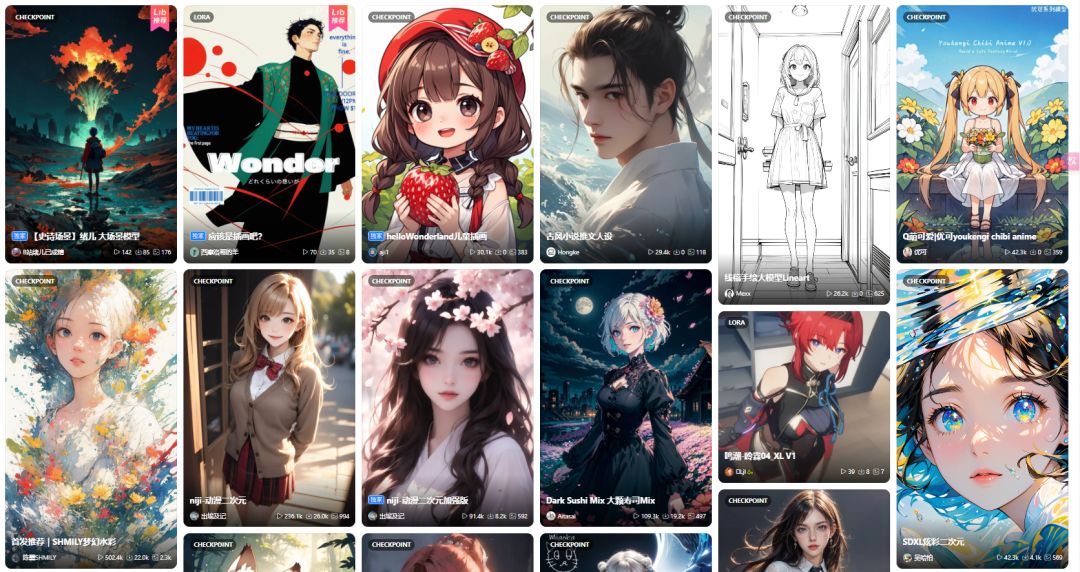
建筑空间类:
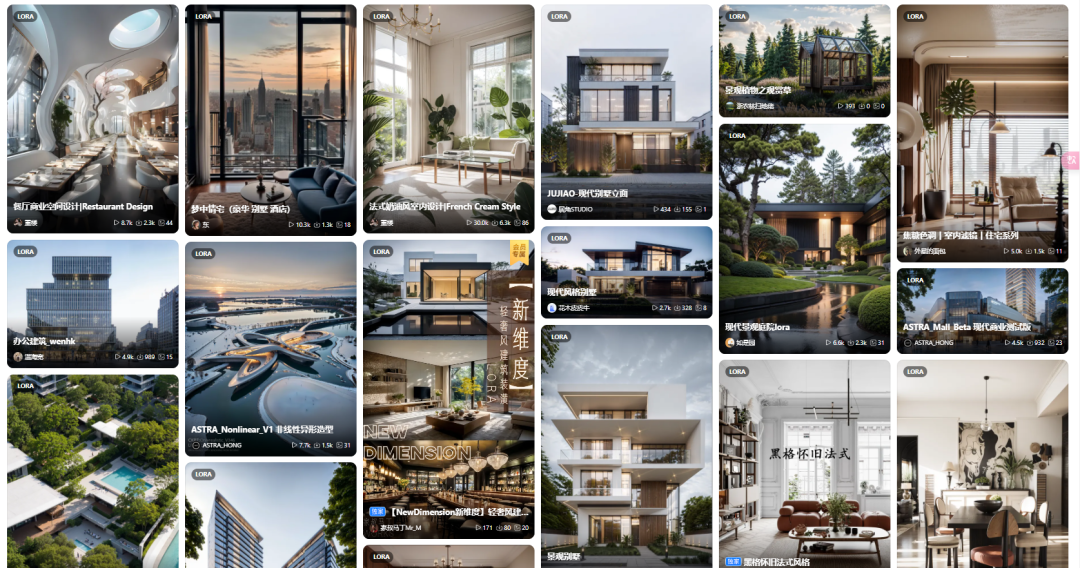
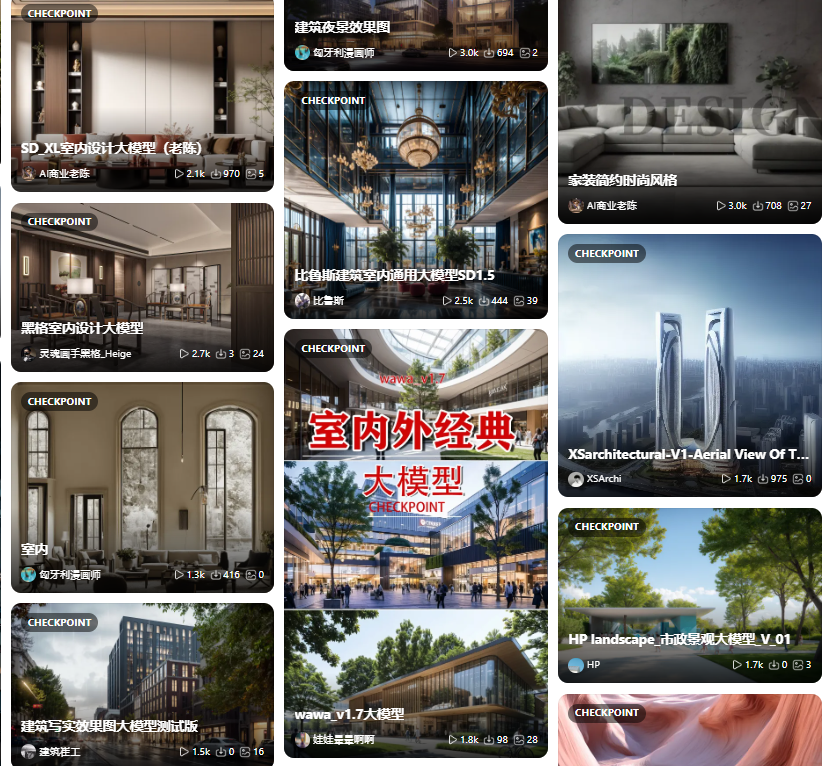
大模型:CHECKPOINT
SD能够绘图的基础模型,因此被称为大模型、底模型或者主模型,WebUI上就叫它Stable Diffusion模型。安装完SD软件后,必须搭配主模型才能使用。不同的主模型,其画风和擅长的领域会有侧重。checkpoint模型包含生成图像所需的一切,不需要额外的文件。
AI生成景观图
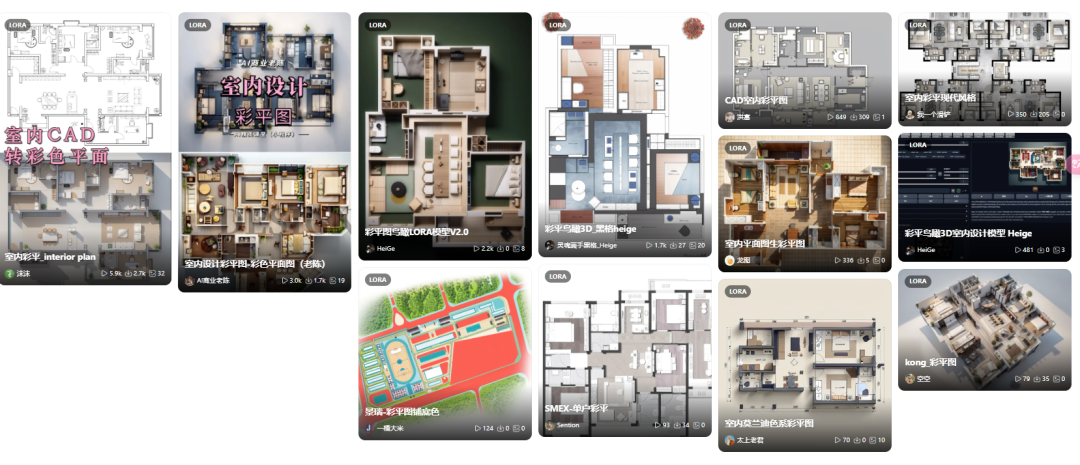
风格化滤镜:LORA
全称是Low-Rank Adaptation of Large Language Models 低秩的适应大语言模型,可以理解为SD模型的一种插件,和hyper-network,controlNet一样,都是在不修改SD模型的前提下,利用少量数据训练出一种画风/IP/人物,实现定制化需求,所需的训练资源比训练SD模要小很多,非常适合社区使用者和个人开发者。LoRA采用了一个办法,仅训练低秩矩阵(low rank matrics),使用时将LoRA模型的参数注入(inject)SD模型,从而改变SD模型的生成风格,或者为SD模型添加新的人物/IP。
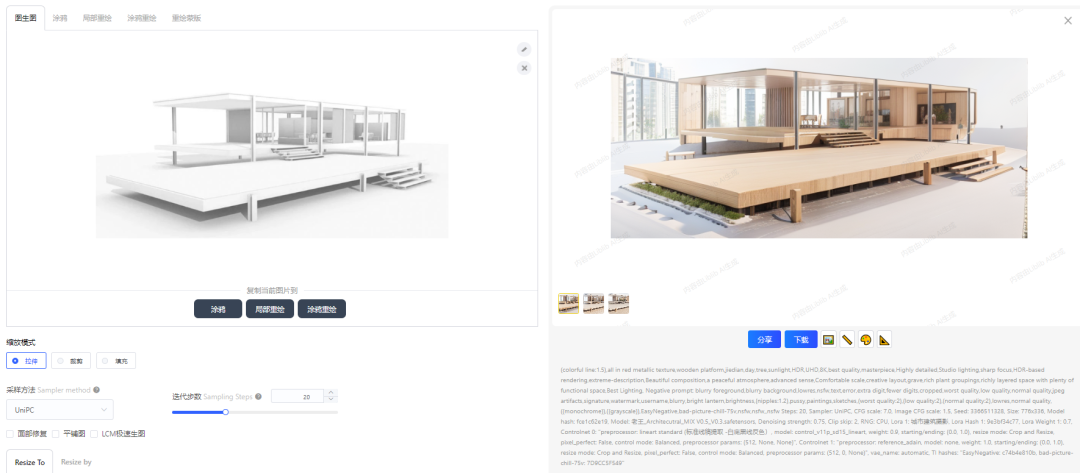
AI生成效果图
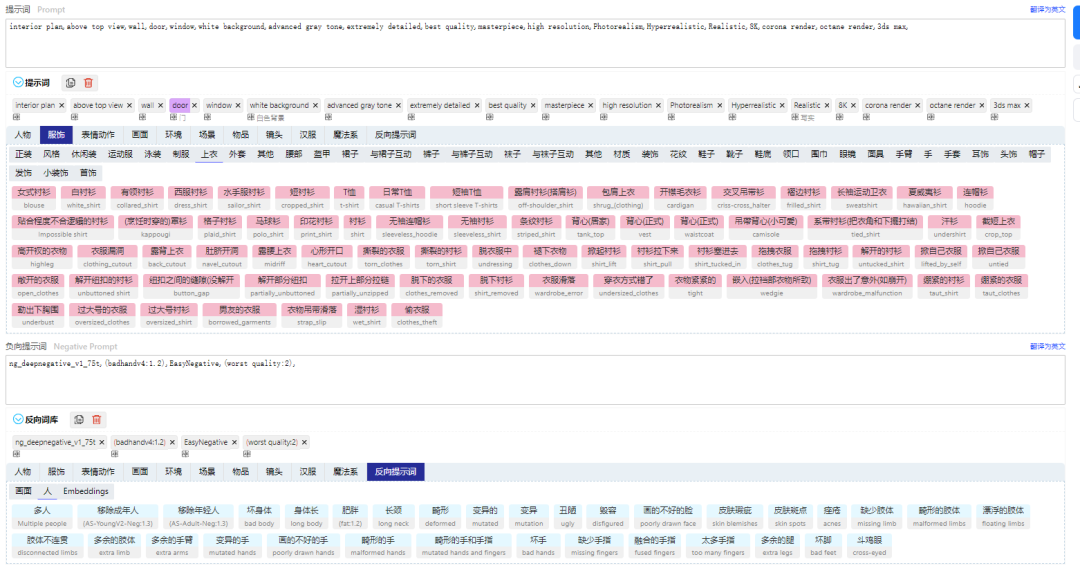
提示词(咒语):Prompt
通过提示词的描述来生成想要的图像效果,又细分为正面提示词和负面提示词,正面提示是想要出现的内容,负面则是不想出现的内容,提示词间用逗号来分隔
哩布哩布自带正反提示词库
AI生成插画风效果
采样器(采样方法)
所谓采样器,就是用于在生成图像的过程对图像进行去噪声的方法。
采样器的选择依赖于特定的需求,如生成速度、图像质量或特定风格的偏好。例如当需要快速出图看模型效果时,可选择 Euler 和 Heun 方法类型采样器,而当需要精细出图时,可选择 DPM++ 等采样器。
早期经典采样器
- **LMS:**ODM求解器,线性多步法。速度与Euler相近,但质量不如Euler。
- **LMS Karras:**ODM求解器
- **Heun:**ODM求解器,是Euler的改进算法,画质更好,但速度慢一倍。
- Euler:ODM求解器,简单直接,可收敛——能产生最终稳定图像。
- Euler a:ODM求解器,不收敛——最终图像具有一定幅度随机性。
- **DDIM:**SD刚问世时的内置算法。
- **PLMS:**SD刚问世时的内置算法。
Euler与Euler a的差别的“a”是祖先采样器,产生的画面不收敛。当Euler在合适的步骤下图像逐渐收敛产生一个稳定的图像结果。而Euler a在每一步骤下都添加随机噪声,因此产生的图像具有一定随机偏差。
DPM采样器DPM采样器名字中的名字释义
StableDiffusion中绝大部分都是DPM算法。二代算法相比于一代算法,质量有所提升但需要更多的时间和迭代步数,通过增加一代算法的迭代步数也能达到相同的质量效果。
-
**DPM2:**DPM二代算法。画质提升有限,渲染时长增加一倍。
-
**DPM2a**:****DPM二代算法。画质提升有限,渲染时长增加一倍。
-
DPM++2S a:DPM一代算法。
-
**DPM++2S a Karras:**DPM一代算法。优化算法,8步之后噪点更少。
-
DPM++2M:DPM一代算法。收敛速度快,质量好。
-
DPM++2M Karras**:**DPM一代算法。强烈推荐,优化算法。
-
DPM++SDE:DPM一代算法。
-
DPM++SDE Karras**:**DPM一代算法。高画质,速度慢,不收敛。
-
**DPM++2M SDE:**DPM一代算法。2M与SDE中和,速度较快,不收敛。
-
DPM++2M SDE Karras**:**DPM一代算法。优化算法,同上。
-
**DPM++2M SDE Heun:**DPM一代算法。
-
**DPM++2M SDE Heun Karras:**DPM一代算法。优化算法,同上。
-
DPM++3M SDE:DPM一代算法。
-
DPM++3M SDE Karras**:**DPM一代算法。30步以上低CFG值效果好。
-
**DPM++3M SDE Exponential:**DPM一代算法。同上。
-
DPM++2M SDE Exponential**:**DPM一代算法。画面柔和,不收敛。
-
**DPM2 Karras**:****DPM二代算法。画质提升有限,渲染时长增加一倍。
-
**DPM2 a Karras**:****DPM二代算法。画质提升有限,渲染时长增加一倍。
-
**DPM++2M SDE Heun Exponential:**DPM一代算法。
-
**DPM fast:**DPM一代算法。几乎不能生成想要的图像。
-
**DPM adaptive:**自适应渲染,无视采样步数。质量好但渲染时间过长。
DPM采样器名字中的名字释义
Karras是优化算法,它们在采样8步之后,比同名算法噪点更少。
2S代表单步算法。2M代表二阶多步算法。与2S相比增加了相邻层之间的信息传递。2M是2S的升级版本。3M是v1.6版本新增的算法,迭代步数到30+、CFG值减小后达到质量最佳。
SDE是随机微分方程,调用祖先采样,表现不收敛特性。没有多步算法加持生成图像较慢,可以生成逼真的写实风格画面。
Exponential是指数算法,细节少一些但是画面更柔和、干净。渲染时间与SDE和2M相接近。
新采样器
UniPC:统一预测校正器,收敛快,10步左右产生可用画面。
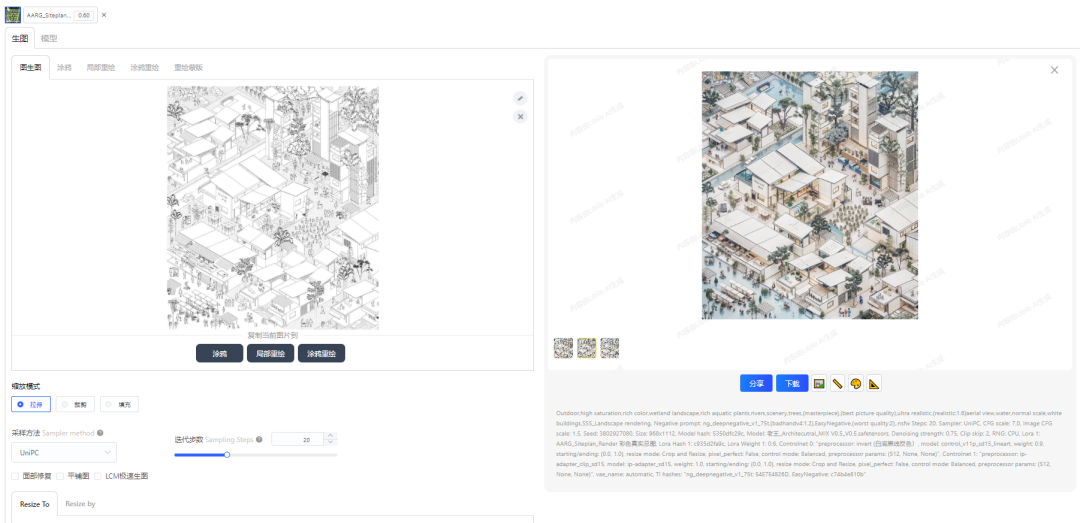
Restart:每步渲染时间长,比UniPC更少的采样步数就能生成不错的画面。AI生成总图彩平图效果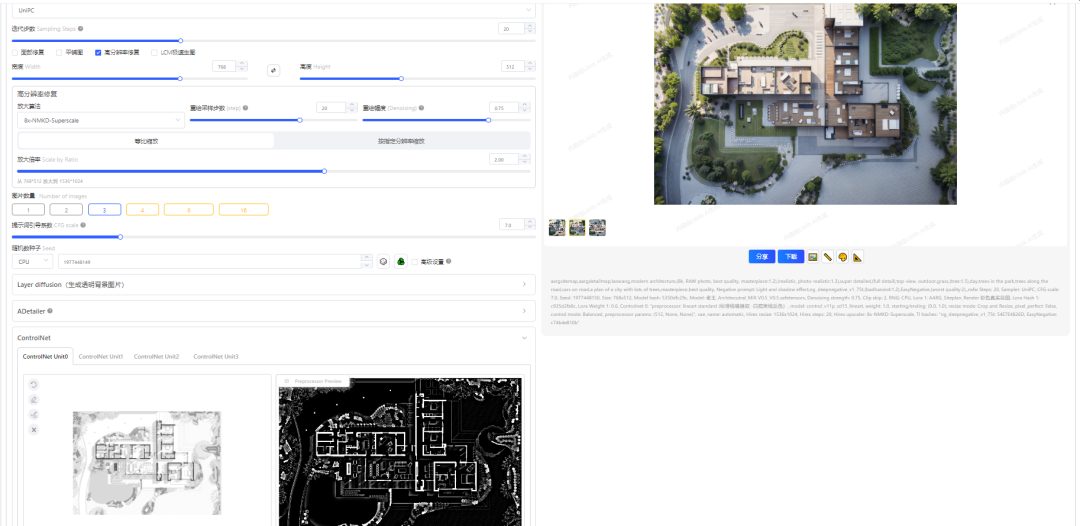
Controlnet插件
是针对 Stable Diffusion 模型开发的一种功能扩展插件,它允许用户在文本生成图像的过程中实现更为细致和精确的控制。该插件使得用户不仅能够通过文本提示(prompt)指导模型生成图像,还能添加额外的输入条件,比如控制图像的构图、颜色、纹理、物体位置、人物姿势、景深、线条草图、图像分割等多种图像特征。通过这种方式,ControlNet 提升了 AI 绘画系统的可控性和灵活性,使得艺术创作和图像编辑更加精细化。
Canny边缘检测算法能够检测出原始图片中各对象的边缘轮廓特征,提取生成线稿图,作为SD模型生成时的条件,该模型能够很好的识别出图像内各对象的边缘轮廓。
Depth算法通过提取原始图片中的深度信息,能够生成和原图一样深度结构的深度图。其中图片颜色越浅(白)的区域,代表距离镜头越近;越是偏深色(黑)的区域,则代表距离镜头越远。
OpenPose算法包含了实时的人体关键点检测模型,通过姿势识别,能够提取人体姿态,如人脸、手、腿和身体等位置关键点信息,从而达到精准控制人体动作。除了生成单人的姿势,它还可以生成多人的姿势,此外还有手部骨骼模型,解决手部绘图不精准问题。
Tile高阶放大算法和超分算法部分类似,能够增大图像的分辨率。但不同的是,在增加图像分辨率的同时,还能生成大量的细节特征而不是简单地进行插值。
Reference预处理器能够直接利用现有的图像作为参考(图像提示词)来控制SD模型的生成过程,类似于inpainting操作,从而可以生成与参考图像相似的图像。与此同时,在图像生成过程中仍会受到Prompt的约束与引导。
AI生成总图彩平图效果
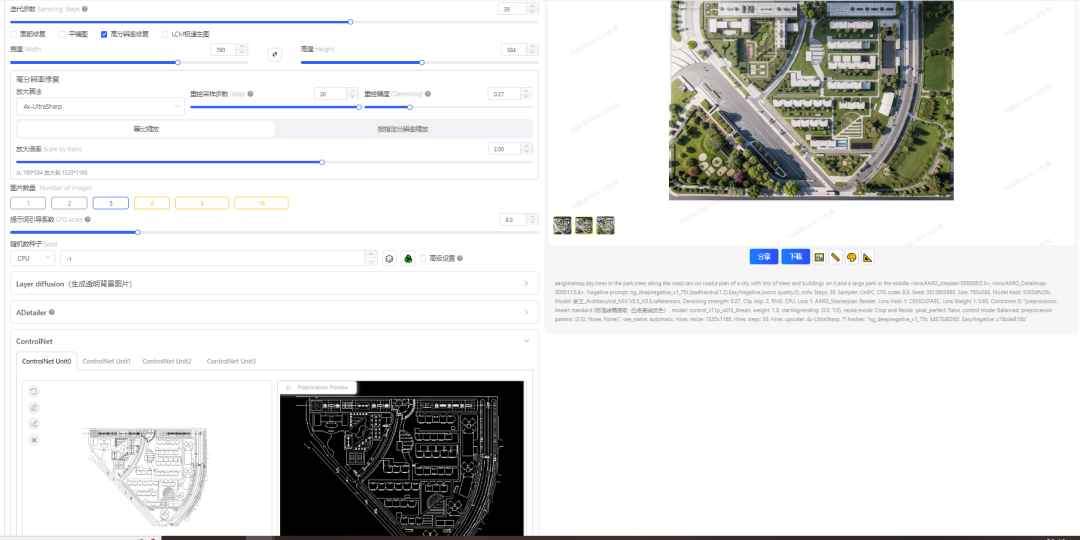
最后:说下总结吧,总体来说出的图,观感上看像那么一回事,但是外行看热闹,内行看门道,其实有很多细节都不尽人意,比如总平图含有不需要的光影信息,建筑效果图具体的建筑材质无法固定,户型图内每个房间的铺装材质无法确定,还有不需要的家具信息,插画图里面人都变成了树,小区彩平图的球场无法锁定材质等等。很多信息都是AI根据模型推理呈现的,很难都达到自己的需求,更别说甲方了。
但是相信未来,技术迭代后,模型对物理世界的理解越来越深刻,以上问题会逐步解决。AI的效果图后可以反哺自己对项目的理解认识,AI对建筑一些新材质的天马行空的运用,也可以提高设计师的灵感,原来用这个材料,最终项目交付后是这个效果。目前最大的好处就是效率,只要几十秒就可以生成好几张自己项目的彩平图,这个是以前绝对做不到的,这对设计师的生产力是极大的提高。
**
**
最后关于AI能否取代设计师,我来说一下自己的想法
1、AI能否达到人类设计理念的深度、人与建筑和自然的理解、视觉和构图的创意
2、AI能否三维建模的准确性,具体的建筑体块和甚至家具是否能准确体现
3、AI图的材质和纹理的质量,能否取代原始的3D或其他建模渲染软件的质量
4、**AI的技术依赖性和成本方面,**现有物质生产资料的水平能否满足AI对硬件的强制需求,高昂的显卡和算力成本,对AI的普及拓展也是钳制因素
5、AI数据对训练数据的依赖,AI在很大程度上依赖于训练数据的质量和多样性。如果训练数据有限或存在偏差,AI的输出可能会受到影响
等这些方面
以上就是本期文章的全部内容了,谢谢观看,欢迎大家在后台沟通交流。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 246
246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









