







本文为作者看文献后所理解的知识
目录:
01 摘要
02 引言
03 相关工作
04 方法
05 实验
06 模型分析
07 结论和未来工作
一、摘要
背景:不完全的多视图聚类(IMVC)分析通常涉及多视图数据的某些视图具有缺失数据,已引起越来越多的关注。背景总结:然而,现有的IMVC方法仍然存在两个问题:(1)它们非常关注填补或恢复缺失数据,而没有考虑到由于未知标签信息可能导致的填补值可能不准确的事实;(2)多视图的共同特征通常是从完整数据中学习的,而忽略了完整数据和不完整数据之间特征分布差异。本文工作:为解决这些问题,我们提出了一种无填补的深度IMVC方法,并考虑特征学习中的分布对齐。具体而言,所提出的方法通过自动编码器学习每个视图的特征,并利用自适应特征投影来避免对缺失数据进行填补。所有可用数据都被投影到一个共同的特征空间中,在这个空间中通过最大化互信息来探索共同的聚类信息,并通过最小化均值差异来实现分布对齐。实验结果:此外,我们设计了一种新的均值差异损失函数用于不完整多视图学习,并使其适用于小批量优化。总结:大量实验证明,我们的方法与最先进的方法相比具有相当或更优越的性能。
解读:首先介绍了目前不完全多视图聚类的必要性,然后总结了目前已有的不完全多视图聚类方法仍未解决的两个问题,同时也是本文已经解决的两个问题,即针对不完全多视图聚类大多数都是采用对数据进行补全的操作,然后再进行聚类,但是确实数据的标签信息会导致我们根据这个标签信息来补全数据,可能会出现补全的值不是很准确从而导致聚类效果降低的情况。以及对于多个视图的数据,它们的共同特征都是从完整的数据集里面学习得到的,这就忽视了不完整数据和完整数据之间的特征分布是有差异的,并不是完全一致的。其次,论文的作者又介绍了为了解决这两个问题所做的工作,作者提出来一种不需要填补的深度学习的不完全多视图聚类的方法,并且考虑了完整数据和不完整数据的特征对齐的方法。具体来说,作者设计了一个自动编码器来学习多个视图中每一个视图的特征,然后对这些特征寻找最合适的角度或视角,以便更清晰地看到数据的本质,也就是将数据原始的特征空间投影到另一个空间来观察,以便更好地表达数据的特点或提取更有用的信息(自适应特征投影)。这个方法就避免了我们需要对缺失数据进行填补,来得出一个补全数据的特征操作。将所有可用数据都投影到一个共同的特征空间里面然后通过最大化互信息(就是衡量两个随机变量之间的相互关系或相关性,通过选择合适的变换或映射,使得在新的特征空间中的特征对之间的互信息最大化。最大化互信息可以帮助算法更好地捕捉数据中不同类别之间的相关性,有助于提高模型性能和准确性。)来探索不完整数据之间共同的聚类信息,然后通过最小化均值差异(是衡量两个不同分布之间差异的统计量。在域自适应或多视图学习中,均值差异通常用来衡量不同数据域(或视图)之间特征分布的差异。我们需要使得这个差异越小越好,使得每个视图的特征分布都越相似越相近。)来实现分布对齐。然后作者设计了一种新的均值差异损失函数用来对这种不完全多视图的数据进行学习,并且能够实现小批量的优化。最后经过作者的实验证明,作者所提出的方法与最先进的方法相比具有更优越的性能。
二、引言
- 大背景:先谈了谈多视图聚类的相关情况。多视图数据广泛存在于现实世界的应用中,每个样本由不同传感器或不同预处理方法提取的多个视图/模态组成。作为一种重要的无监督学习方法,多视图聚类分析旨在探索多视图数据中的共同聚类模式,在机器学习和图像处理领域得到了广泛研究。
- 过渡背景:提出来目前很多多视图数据都是缺失的,引出不完全多视图聚类。然而,在实际场景中,多视图数据的收集往往存在不完整,即某些视图的数据部分缺失。例如,视频数据可以同时包含图像、字幕和声音等多个视图,但某些视频可能缺少字幕或声音。不幸的是,现有的多视图聚类方法不适用于不完整的多视图数据,因此引起了当前备受关注的不完整多视图聚类(IMVC)问题。
- 过渡背景总结:简单总结了目前针对不完全多视图聚类的解决方法,并指出存在的缺点。IMVC的目标是发现隐藏在不完整多视图数据中的共同聚类模式,先前的IMVC方法大致可分为两组,即传统方法和深度方法。传统的IMVC方法可以进一步分为四类:基于核的IMVC方法,基于非负矩阵分解的IMVC方法,基于张量的IMVC方法,以及基于图的IMVC方法。它们通常倾向于对不完整多视图数据集的缺失数据进行填补/恢复/推断,然后探索聚类信息。然而,传统的IMVC方法具有学习特征表示的能力有限,同时其中一些方法消耗计算成本较高(例如,在矩阵的逆运算中)。
- 小背景:提出今年来有部分人通过深度学习来进行不完全多视图聚类的方法,得到了很大的性能提升。近年来,深度IMVC方法通过将深度模型的表示学习与聚类相结合取得了令人瞩目的进展,例如深度自动编码器。一般来说,深度方法利用深度模型的泛化能力来实现对缺失数据的填补。例如,在对比学习框架中利用附加的预测网络重构缺失数据。一些研究将鉴别器网络与自动编码器相结合,并采用对抗训练来生成缺失数据的可能值。
- 对现有IMVC方法进行总结并提出作者的模型:即摘要里面提到的现有IMVC方法存在本文解决的问题。(1) 大多数现有的IMVC方法,包括传统方法和深度方法,在完成不完整的多视图数据时都会加入缺失数据的填补过程。(2) 许多IMVC方法在处理不完整的多视图数据时采用两阶段的过程,即首先从完整数据部分探索多个视图之间的一致性,然后将学习到的一致性扩展到不完整数据部分。
为解决上述问题,作者提出了APADC:用于深度不完整多视图聚类的自适应特征投影与分布对齐。所提出的方法是一个无需填补的框架,如下图(a)所示,包括多个深度自动编码器(用于学习各个视图的特定特征)和自适应特征投影(用于获得所有视图共享的公共特征)。
具体而言,为了避免对缺失数据进行填补,我们提出了如下图(b)所示的自适应特征投影,通过将所有视图可用数据的特征投影到一个共同的特征空间中来生成共同特征。特别地,自适应特征投影中嵌入了指示矩阵和权重矩阵,使其能够适应不同数量的缺失数据,并根据其特征质量为各个视图提供不同的权重。其中(c)图为通过最大化互信息(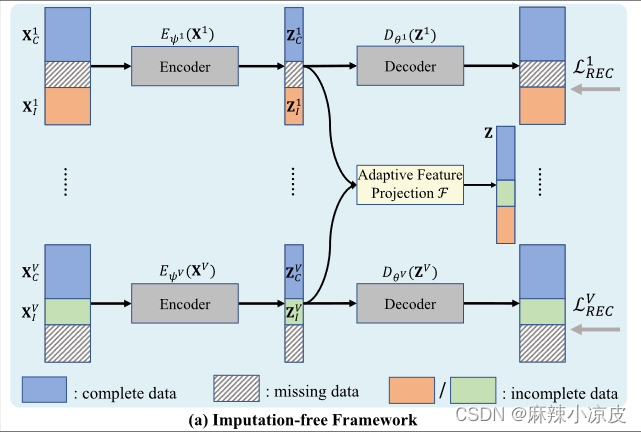
)来探索共同的聚类信息,并通过最小化均值(
)差异来实现分布对齐。
图像解读:首先,输入完整数据
和不完整数据
,通过编码器Encoder,得到输出完整数据的自适应特征投影
和不完整数据的自适应特征投影
,然后通过解码器,我们就能得到输出特征学习好的特征投影
。其中,我们最大化共同特征与完整多视图数据的视图特定特征之间的互信息,对完整数据的自适应特征投影
、
和
,同时对不完整数据的自适应特征投影
。
三、相关工作
这部分工作主要就是介绍了深度多视图聚类和不完全多视图聚类的相关内容,读者可自行前往原文查看。需要原文请私信。
四、方法(具体细节请看原文)
- 符号介绍
文献使用的符号带翻译
and代表&
Notations Descriptions translate the index notations 索引符号 the sample number of multi-view data set 多视图数据集样本编号 the sample number of data set in the -th view
第v视图中数据集的样本编号 the view number of the multi-view data set 多视图数据的视图编号设置 the data matrix in the 第v视图的数据矩阵 the complete part of data matrix in the 第v视图中数据矩阵的完整部分 the incomplete part of data matrix in the 第v视图中数据矩阵的不完整部分 the missing part of data matrix in the 第v视图中缺少的数据矩阵部分 the learned view-specific features of 第v视图中数据矩阵的完整部分所学习到的特定视图的特征 the learned view-specific features of 第v视图中数据矩阵的不完整部分所学习到的特定视图的特征 the imputed view-specific features of 第v视图中缺少的数据矩阵部分所填补的特定视图的特征 the learned view-specific features of 与
所学习到的特定视图的特征
the common features projected from 从 和
中第一个视图所投影出的共同特征
the common features projected from 从 the common features projected from 从 the features extended from 从 the indicator matrix of the multi-view data set, 多视图数据集的指示矩阵 the weight matrix of the multi-view data set, 多视图数据集的权重矩阵
the dimensionality of 的维度
the dimensionality of 的维度
the trade-off parameters in loss function 损失函数中的权衡参数 the batch size in mini-batch optimization 小批量优化中的批量大小 the encoder and decoder parameters of the 第v视图的编码器和解码器参数 -
动机与框架
在本文中,我们通过避免对缺失数据进行填补,并考虑特征学习的分布对齐来解决上述问题。如图(a)(b)(c)所示,我们提出了一个无需填补的框架,通过自适应特征投影将所有可用数据的视图特定特征投影到共同特征上。然后,我们优化共同特征与所有视图的视图特定特征之间的互信息损失,以挖掘它们的共同聚类信息,同时优化完整数据和不完整数据特征之间的均值差异损失,以在特征学习中对齐它们的分布。
-
自适应特征投影
在不失一般性的前提下,缺失数据的数量是不确定的,但至少每个样本存在一个视图的数据。此外,当所有视图的特征投影到一个共享的公共特征空间时,一个样本可以由多个视图中的任何特征来表示。基于以上观察,我们提出了自适应特征投影F,以获得每个样本的共同特征,从而避免了对缺失数据的填补过程和引入噪音信息。 -
特征学习与分布对齐
(1) 对进行特征学习,以探索跨所有视图的共同聚类信息,以提高聚类性能。
(2) 对齐 -
小批量优化和聚类
其中 λ1 和 λ2 是权衡参数。是自动编码器的重构损失,自适应特征投影在此基础上将学习到的可用数据的视图特定特征映射到共同特征上。
执行k-means [59],以获取所有
个样本的最终聚类结果。
-
复杂度分析
提出的APADC总结如算法1所示。其中,表示小批量大小,我们使用小批量优化算法来优化APADC。对于每个批次,
损失、
损失和重构损失的计算复杂度分别为
、
。当我们计算公式(3、4和8)以及通过最小化总损失,优化自动编码器网络的参数(即
)时,复杂度与
,与数据大小
五、实验
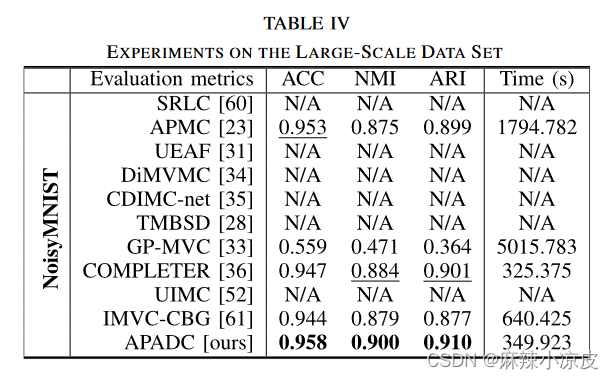
实验部分就是对数据集的操作得出聚类结果,并对结果进行各种分析,读者可自行前往原文查看。
六、模型分析(具体细节看原文)
在本节中,我们首先从两个方面进行消融研究,即损失函数和模型结构,然后在四个缺失率为0.3的数据集上进行参数敏感性分析和收敛性分析。
- 损失函数的有效性
方程(15)中的总损失函数包括互信息损失(在 MNIST-USPS 上的 ACC 较
提高了14%。因此,所提出的分布对齐对于发现聚类结构具有积极的作用。此外,
报告了通过优化基本
中的分析一致,并进一步验证了我们改进的
- 结构消融实验
我们进一步进行了不同结构的消融研究,并在表VI中报告了它们的结果。具体来说,不利用自适应特征投影来避免对缺失数据进行填补。在这种结构中,我们使用均值来填补缺失数据,并优化视图特定特征之间相同的损失,即
仅利用指示矩阵 A 进行自适应特征投影(在这种情况下,
)来获得共同特征 Z,在性能上优于
- 参数敏感分析公式
公式(15)包括两个权衡参数,即和
。图4显示了通过在
区间上变换
和
。
- 收敛分析
下图展示了训练过程中三种损失(即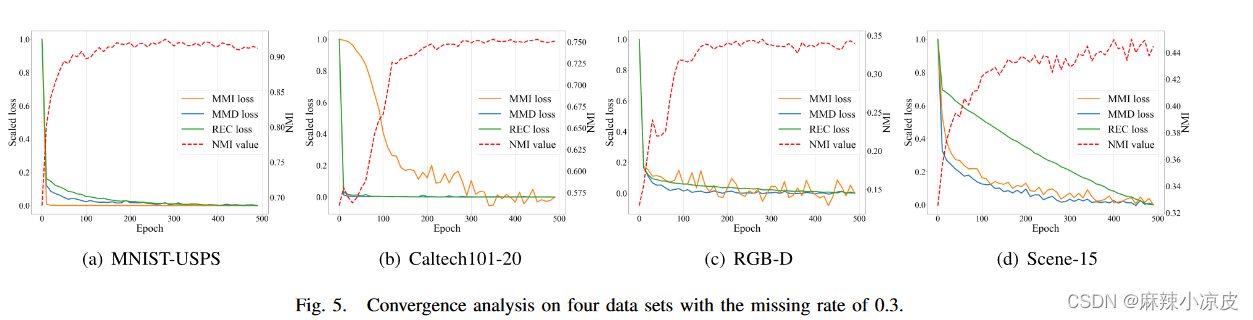
七、结论和未来工作
在本文中,我们提出了一种通过自适应特征投影实现无填充的深度多视图聚类方法。具体而言,自适应特征投影将学习到的视图特定特征映射到一个共同的特征空间,在此空间中,我们对不完整的多视图数据进行特征学习和分布对齐,以发现跨多视图的共同聚类模式。大量实验证明了我们方法的有效性。提出的特征学习框架也可以应用于其他领域。在未来,我们将把它扩展到不完整数据的跨模态匹配和检索中。此外,研究框架的损失平滑化和降低参数敏感性也是未来的工作方向。
简单总结:本人刚开始接触不完全多视图聚类的相关研究,旨在互相交流学习共同进步,有疑问和错误请及时私信,谢谢!原文链接:Adaptive Feature Projection With Distribution Alignment for Deep Incomplete Multi-View Clustering | IEEE Journals & Magazine | IEEE Xplore
需要原文pdf请私信,谢谢!
















 2709
2709











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











