







本文为作者看文献后所理解的知识
目录:
01 摘要(Abstract)
02 引言(Introduction)
03 相关工作(Related work)
04 方法(Method)
05 实验(Experiments)
06 结论(Conclusion)
一、摘要
现有的多视图聚类算法通常建立在这样一个先前假设的基础上,即来自不同来源的数据是完整的,没有缺失,然而在实际应用中并不总是满足这一假设。不完全多视图聚类(IMC)旨在发现潜在的簇结构,并将不完整的多视图数据划分为不同的组,这更为实际但也更具挑战性。此外,当前IMC研究的主要瓶颈在于如何在有限资源下经济高效地聚类大规模不完整多视图数据。在本文中,我们提出了一种新颖的可扩展不完全多视图聚类与自适应数据补全(SIMC_ADC)方法,旨在处理大规模IMC,并具有有望实现实例级别的恢复。具体而言,为了适应大规模IMC,我们的SIMC_ADC将代表性的锚点学习和相似性恢复统一到一个一站式学习方案中,具有线性计算和内存成本。此外,我们制定了自适应的实例补全方案,以发现和生成实例之间可靠的潜在连接,通过迭代推断和填充缺失的实例以及完整的相似性收益。重要的是,对数据完成误差的理论分析进一步保证了这种数据补全范式的可靠性。广泛的实验证实了我们的方法在处理大规模IMC问题时与最先进的算法相比的高效性和有效性。我们的SIMC_ADC的源代码可在https://github.com/DarrenZZhang/SIMC_ADC 上获得。(原文的代码)
1.黄色为背景
2.紫色为背景总结
3.蓝色是作者所做的工作
4.红色是实验结果
5.绿色为总结
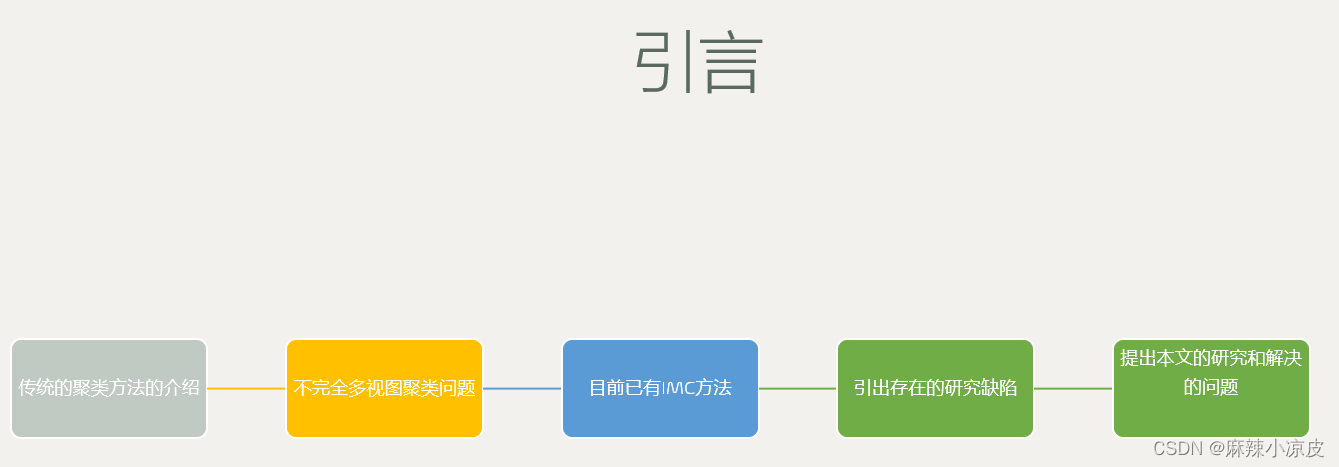
二、引言
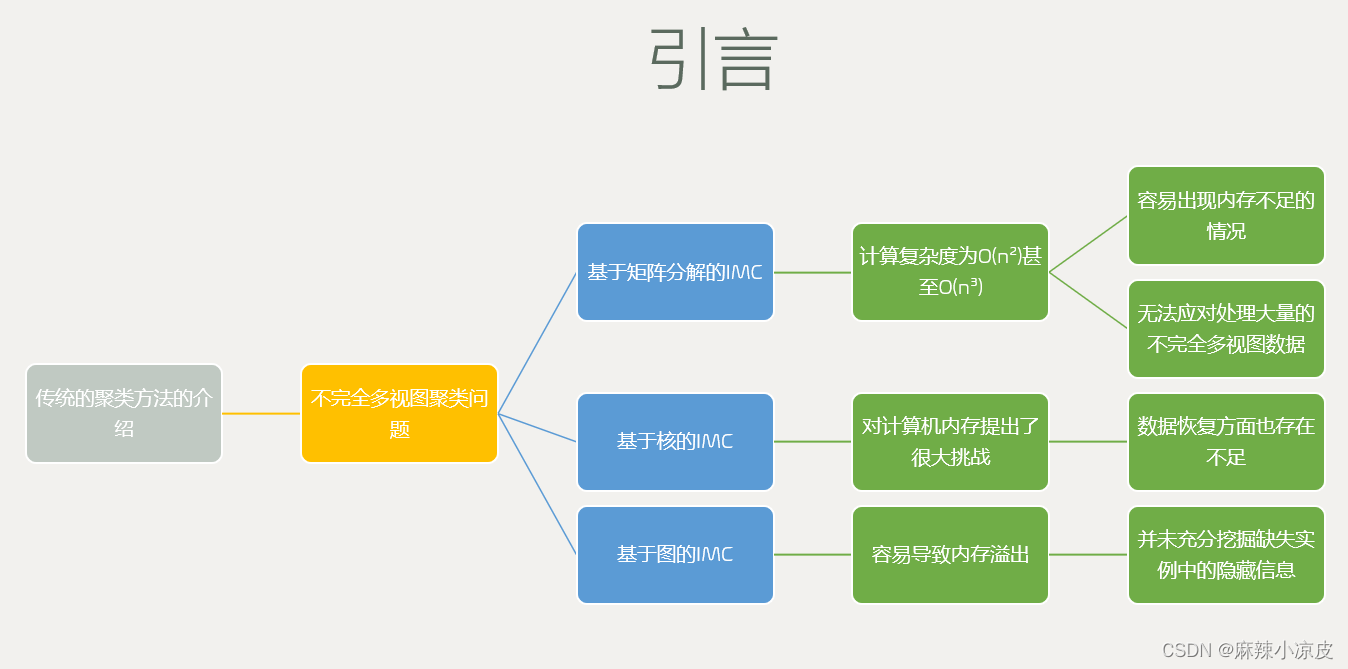
- 1.传统的聚类方法的介绍——大背景
-
传统的数据分析方法通常侧重于单视图任务,如图像识别、面部表情识别等,取得了令人鼓舞的成果。近年来,研究认识到多视图学习对于有效的数据分析至关重要。通常,多视图数据由于不同视角提供的互补信息而比单视图数据更具信息量。在众多多视图数据分析技术中,多视图聚类(MVC)因无需繁琐的数据标注而备受青睐。常见的研究的多视图聚类方法包括基于核的多视图聚类、基于子空间的多视图聚类、基于图的多视图聚类等。
-
2.由传统聚类方法的大背景到不完全多视图聚类的中间背景,并提出存在问题
-
值得注意的是,前述的多视图聚类方法都基于“完整数据假设”,即假设在每个视图中实例是完全被观察到的。然而在实际应用中,很难找到完全完整的多视图数据。例如,在使用多个摄像头捕捉实例时,某个摄像头可能无法正常工作,导致在相应视图中未观察到实例。在多媒体分析中,不同的信息载体(如文本、图像和视频)被视为不同的视图,一个实例可能无法由所有视图来表示。因此,出现了不完全多视图聚类(IMC)问题。总的来说,不可用的实例给多视图聚类带来了更大的挑战。首先,难以测量缺失实例与现有实例之间的相似性。其次,视图之间的互补信息变得难以探索。已经提出了许多方法来解决IMC问题,并可以大致分为三类主要群体,即基于矩阵分解的IMC、基于核的IMC 和基于图的IMC。
-
3.由传统不完全多视图聚类到基于矩阵分解的IMC这个小背景
-
其中一种普遍采用的方法是基于矩阵分解的不完全多视图聚类(IMC),它同时学习潜在子空间及其上的潜在表示。最早的IMC尝试之一[17]将部分观察到的实例投影到一个子空间中,其中视图之间共享的实例具有相同的表示。然而,其实现受限于它只能处理具有两个视图的IMC问题。为了克服这一问题,胡等人[18]为每个视图获取一个潜在子空间,其中所有视图共享一个公共特征矩阵,并且该模型基于视图特定的子空间学习最终的共识潜在子空间。然而,大多数基于矩阵分解的方法的计算复杂度为O(n²)甚至O(n³),当实例数量增加时,使得算法变得无法忍受的缓慢。
-
-
-
4.由传统不完全多视图聚类到基于核的IMC这个小背景
现有IMC方法的另一个主流是继承核方法的优点,将给定的数据映射到一个高维空间,从而可以进行线性划分。鉴于视图是部分观察到的,如何推断核的缺失部分是基于核的IMC的关键问题。特里韦迪等人[19]提出通过最小化推断核与完整核的拉普拉斯乘积的迹来填充不完整核。然而,它只能处理两个视图的情况,并且需要一个完整的视图。为了克服这样的约束,叶等人[20]提出在每个视图上进行核k均值,并利用每个视图的结果获得共识结果。然而,对于包含n个实例的数据集,所有基于核的IMC方法都构建n×n核矩阵来描述高维空间中实例之间的关系,这对计算机内存提出了很大挑战,也降低了运行速度。
5.由传统不完全多视图聚类到基于图的IMC这个小背景
图像的基于图的IMC方法也存在类似问题。具体来说,基于图的方法旨在学习图,其中每个节点代表一个实例,两个节点之间的边表示相应实例之间的相似性。李等人[21]提出根据它们的欧氏距离学习每个视图观察到的实例之间的相似性,并获得对应于聚类标签的离散指示器矩阵。为了探索实例之间的高阶关系,李等人[22]开发了一个通过自表达从所有视图学习亲和图并将其堆叠成一个三阶张量的聚类方案。显然,构建的图描述了实例之间的每一对关系,其大小为𝑛 × 𝑛,这很容易导致内存溢出。此外,这些方法涉及到诸如特征值分解等的程序,导致了计算复杂度为O(n²)甚至O(n³)。
6. 由已有的多视图聚类方法引出存在的研究缺陷
尽管在不完全多视图聚类方面取得了一些进展,但当前的方法仍然存在一些未解决的缺陷。一方面,当前的方法无法应对处理大量的不完全多视图数据,因为它们构建和处理了𝑛×𝑛的亲和性矩阵,导致了二次甚至是立方的时间复杂度,容易出现内存不足的情况。另一方面,当前的方法在数据恢复方面也存在不足,因为它们要么忽略了缺失的实例,要么简单地用一个固定值(通常是0或现有实例的平均值)来填充它们,并未充分挖掘缺失实例中的隐藏信息。
7. 提出本文的研究和解决的问题
为了解决上述不足,本文提出了一种新的可扩展的不完全多视图聚类方法,即具有自适应数据补全的SIMC_ADC框架,用于大规模的不完全多视图聚类。如图1所示,我们将传统图方法中的𝑛×𝑛亲和性矩阵替换为一个非对称的二分图,它描述了一小部分选定实例(即锚点)与所有实例之间的关系,大幅减少了计算负担和内存使用量。另外,未观测到的信息会被迭代地学习并添加到训练数据中,从而更好地探索和利用隐藏信息。值得注意的是,与传统框架将各个阶段分开的做法不同,我们的方法中恢复的数据、锚点集和二分图是相互更新的,以实现全局最优。我们在三个中等规模的数据集和四个大型数据集上评估了我们的SIMC_ADC方法,结果验证了我们的方法在高效处理大规模不完全多视图聚类问题方面的能力。
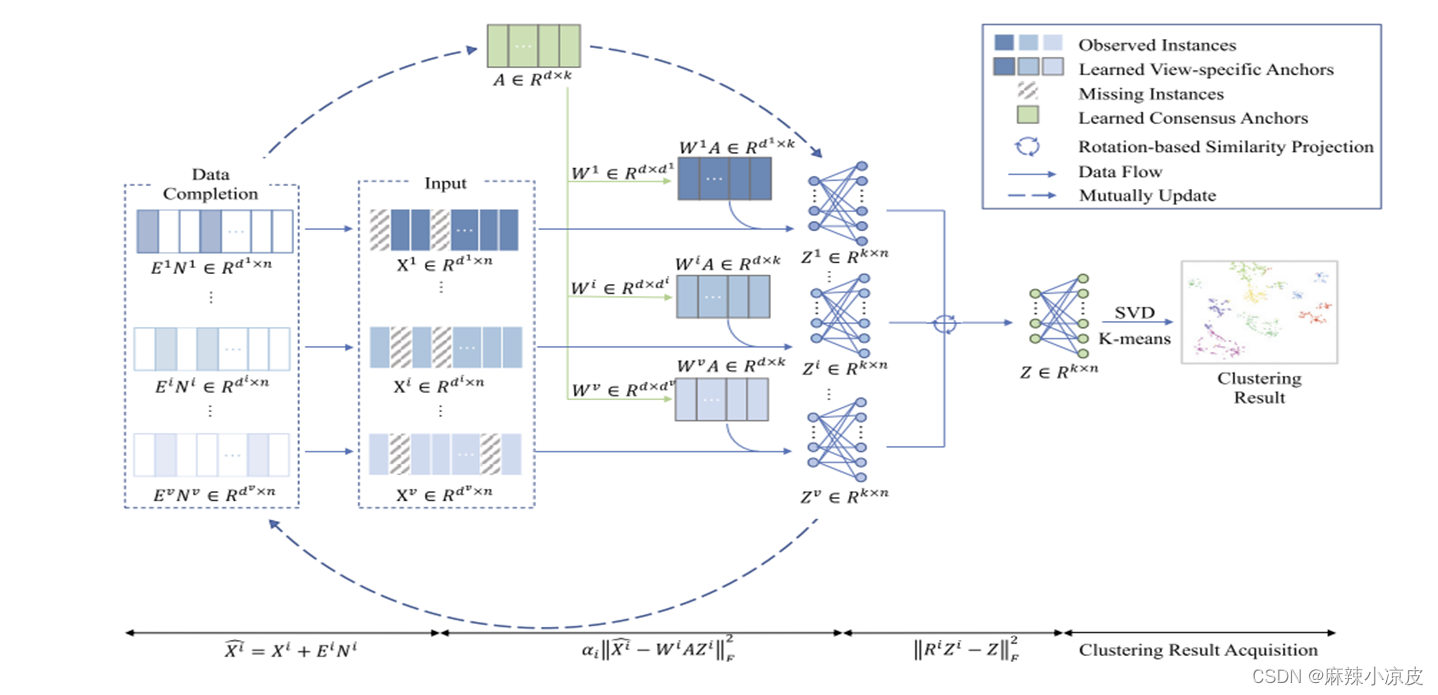 注释:
注释:
Data Completion:隐藏信息的获取
Input:隐藏数据添加到原始不完整数据集得到
:投影矩阵,使得每个视图都能够综合利用共识锚点的信息来填补缺失数据。
:将共识锚点集 𝑨 投影到每个视图中。
: 描述了从第 i 个视图中的数据点到预定义锚点的相似性关系。输出是一个二分图,描述了从第 i 个视图中的数据点(第一个顶点集合)到预定义锚点(第二个顶点集合)的相似性关系。也就是说,每个边表示了一个数据点和一个锚点之间的相似性或连接强度。
8.贡献总结
(1).提出了一种新颖的SIMC_ADC方法,以线性时间解决具有挑战性的大规模不完全多视图聚类问题。据我们所知,这是首次尝试通过联合考虑可学习的多视图相似性构建和自适应数据补全来探索大规模不完全多视图聚类问题之一。
(2).与现有的IMC方法相比,我们提出的方法同时利用可学习的投影式共识锚点来进一步保持在不同视图间的一致性,并引入了一个缺失关系恢复方案,以充分探索不同视图间的互补信息。
(3).对数据补全引入的潜在噪声以及其上界进行了严格分析,从理论上保证了我们提出的方法的可靠性。
(4).在中等规模和大规模数据集上进行了大量实验证明了所提方法在处理实际不完全多视图数据聚类时的高效性和有效性。
接下来的部分安排如下:第2节讨论了一些相关的IMC方法。第3节介绍了我们提出的模型以及其优化,并分析了其复杂性和完全误差。第4节在几个数据集上进行了大量实验。第5节简要总结了整篇论文。
三、相关工作
这部分工作主要是涉及符号的说明、公式的使用等,读者可自行前往原文查看。
四、方法
1.当前基于锚点的方法仍然存在一些共同的缺陷:
(1)大多数现有工作忽略了缺失信息的恢复,导致对隐藏信息的利用不足。
(2)所选的锚点是次优的,并对噪声敏感。
2.传统的IMC方法通常使用简单的一次填充策略来处理缺失实例,该策略将缺失实例填充为0或平均值,并在训练过程中从不更新它们。然而,这种措施会将所有缺失实例聚集在一起,因为它强制它们具有相同的值,从而在聚类结果中引入噪声。与上述填充策略相对立的是,我们提出了在每个视图中迭代恢复缺失实例的方法。
3.在公式(3)中,锚点集 𝑨𝑖 由k均值或随机选择预先定义,这是当前基于锚点的方法采用的普遍方法。换句话说,锚点选择和二部图构建分为两个阶段。然而,每个视图选择的锚点是独立的,这削弱了𝒁的可解释性,因为每个𝒁𝑣表示了与不同锚点的数据点的相似性。此外,预定义的锚点集通常对训练过程来说不够代表性,锚点选择引入的随机性难以消除。
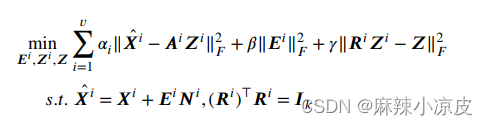
4.与固定的锚点策略相反,我们的方法在训练过程中更新锚点集。具体而言,SIMC_ADC学习了一个中央一致的锚点集以及一系列投影矩阵。通过将中央锚点投影到每个视图,视图特定的锚点与彼此紧密连接。通过这种方式,来自每个视图的锚点会随着相似性矩阵的更新而相互更新,从而得到最优结果。此外,由于我们对每个视图的重要性没有先验知识,手动设置锚点学习和视图特定的二部图学习的权重是不合理的。相反,我们引入了一个自适应加权参数来自动平衡每个视图的重要性。
五、实验
1.数据集:BDGP1包含了由伯克利果蝇基因组项目收集的果蝇家族的遗传数据。遵循现有的研究,将3个特征分别提取为3个视图,维度分别为1000、500和250,数据集总共包含2500个样本。
2.评价指标:为了全面评估测试方法的性能,我们选择准确率(ACC)、归一化互信息(NMI)、纯度(Purity)和F分数(Fscore)作为评价指标,这些指标是根据现有研究中的定义来衡量性能的。
3.所有提及的数据集都被假定为完整的,没有任何元素缺失。为了衡量测试方法处理不完整多视图数据的能力,我们首先构建了不完整数据。缺失实例的比例从10%到50%,间隔为10%,并且在每个视图中随机选择缺失实例。对于那些需要非负输入的方法,例如MIC和OMVC,我们将给定数据中的负值替换为零,以确保能够评估它们的性能。对于比较的方法,我们从相应的作者那里获取了代码,并在默认范围内调整了参数。对于每种方法,我们运行了20次k-means以减轻在目标矩阵上进行k-means时可能的随机性。所有实验都在装有Intel(R) Core(TM) i7-10700 CPU @ 2.90 GHz和64 GB RAM的个人电脑上在Matlab R2021a上进行。
4.聚类结果:由于数量比较多就不展示,需要可自行前往原文查看
六、结论
在本文中,我们提出了一种名为SIMC_ADC的新型基于锚点的不完全多视图聚类方法,该方法能够在合理的时间和内存使用情况下处理大规模的不完全多视图聚类问题。与传统方法相比,传统方法具有二次或三次时间复杂度,我们的方法通过使用一个非对称二分图来描述给定数据的全局结构,从而大幅降低了时间复杂度。此外,我们的方法以一种有前景的方式探索和恢复了实例之间未观察到的连接,并恢复了数据,从而可以充分利用隐藏的信息。在中等和大型数据集上进行了大量实验证明了我们提出的方法的效率和有效性。
原文链接:https://www.sciencedirect.com/science/article/abs/pii/S0020025523011477?via%3Dihub
















 656
656











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











