







聚类学习
一、基本概念
- 核心对象:若某个点的密度达到算法设定的阈值,则其为核心点,即r领域内点的数量不小于minPts。也就是说,当一个数据点为圆心点时,设定他的半径为
,以圆心点为圆心、
- 直接密度可达:如果点p在点q的r邻域内,并且q是一个核心点,则我们称p-q直接密度可达。
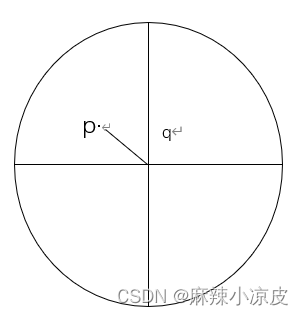
- 密度可达:如果有一个点的序列为
,对任意的
是直接密度可达的,则称
~
密度可达。实际上就是两两个数据点之间直接密度可达最终形成一条传播的链。
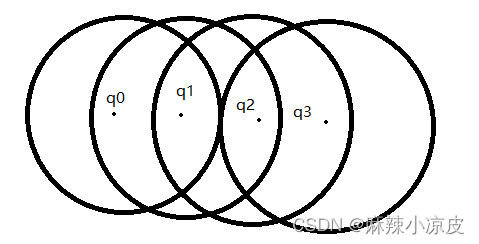
- 密度相连:如果从核心点
出发,点
都是和
都是和
- 边界点:属于某一个类的非核心点,不能再成为核心点。简单来说就是所画圆的圆边上的点,根据这个点为圆心画一个圆,园内所包含的数据点小于minPts。
- 噪声点:不属于任何一个类的点,以任何一个核心点画圆,都不能把这个点包含在园内,用密度可达的思想来解释就是从任何一个核心点到噪声点都是密度不可达的。
二、工作流程
- 参数D:就是我们所需要输入的数据集。
- 参数
- minPts:密度阈值,就是我们想让以核心点为圆心画的圆所包含的数据点的最小数量。
三、参数选择
- 半径
- k距离:就是随机选择的一个数据点点到其余所有数据点的距离,按照从小到大的顺序排列就得到k距离d(k)。
- minPts:k距离中k的值,一般取较小的值,多次尝试选择性能最好的值。
四、DBSCAN算法的优缺点:
优点:
- 不需要人为选择簇的个数。
- 可以很好的发现任意形状的簇,比如k-means不能解决的笑脸形状的数据。
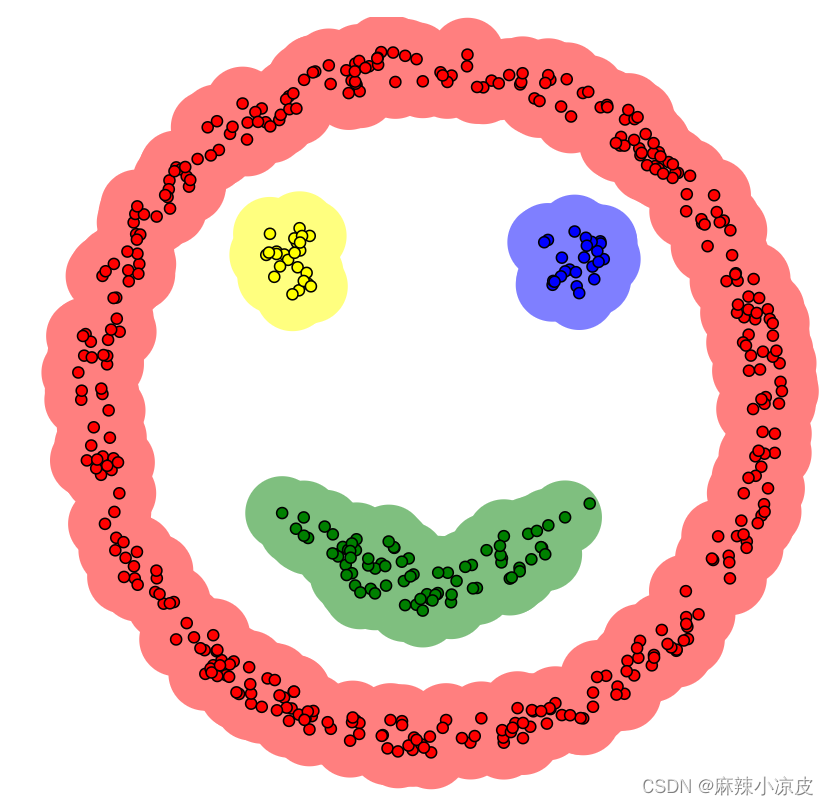
- 擅长找到离群点:DBSCAN会把所有的离群点也就是噪声点分到一个专门用于存放离群点的簇里面,便于检测离群点。
- 只需要半径
缺点:
- 对于高维数据聚类比较困难,速度低、效率慢,但是可以对数据做降维处理 。
- 参数难以选择,参数对聚类结果的影响非常大。
- 在Sklearn中效率很慢,可以对数据指标相似的数据进行消减。
五、MATLAB的DBSCAN算法代码实现:
% DBSCAN算法
function [clusters, clusterCount] = dbscan(data, epsilon, minPts)
dataSize = size(data, 1);
visited = false(dataSize, 1);
clusters = zeros(dataSize, 1);
clusterCount = 0;
for i = 1:dataSize
if ~visited(i)
visited(i) = true;
neighborPts = regionQuery(data, i, epsilon);
if numel(neighborPts) < minPts
clusters(i) = -1; % 标记为噪声点
else
clusterCount = clusterCount + 1;
expandCluster(data, i, neighborPts, clusterCount, epsilon, minPts, visited, clusters);
end
end
end
end
% 密度可达判断
function neighborPts = regionQuery(data, pointIdx, epsilon)
distances = pdist2(data(pointIdx, :), data, 'euclidean');
neighborPts = find(distances <= epsilon);
end
% 扩展聚类
function expandCluster(data, pointIdx, neighborPts, clusterCount, epsilon, minPts, visited, clusters)
clusters(pointIdx) = clusterCount;
i = 1;
while i <= numel(neighborPts)
currentPt = neighborPts(i);
if ~visited(currentPt)
visited(currentPt) = true;
newNeighborPts = regionQuery(data, currentPt, epsilon);
if numel(newNeighborPts) >= minPts
neighborPts = [neighborPts; newNeighborPts'];
end
end
if clusters(currentPt) == 0
clusters(currentPt) = clusterCount;
end
i = i + 1;
end
end
% 示例数据
data = [
1, 2;
1.5, 1.8;
5, 8;
8, 8;
1, 0.6;
9, 11
];
% 设置 DBSCAN 参数
epsilon = 2;
minPts = 2;
% 运行 DBSCAN
[clusters, clusterCount] = dbscan(data, epsilon, minPts);
% 打印聚类结果
disp('聚类结果:');
disp(clusters);
disp('聚类数目:');
disp(clusterCount);代码描述:
操作流程:
-
定义 DBSCAN 函数:包含三个函数:
dbscan(DBSCAN算法的主函数),regionQuery(用于找到邻域内的点),expandCluster(用于扩展聚类)。 -
DBSCAN 算法:主要分为几个步骤:
- 遍历数据集中的每个点。
- 对于每个点,检查是否已经被访问过。
- 对于未被访问的点,寻找其邻域内的点。
- 如果邻域内的点数大于等于指定的
minPts阈值,则扩展聚类。 - 标记噪声点和分配聚类编号。
-
数据预处理:准备数据并设置 DBSCAN 的参数(
epsilon和minPts)。 -
运行 DBSCAN 算法:使用提供的数据和参数运行 DBSCAN 函数,获得聚类结果和聚类数目。
-
输出结果:显示聚类结果和聚类的数量。
变量含义:
data:示例数据集,包含需要进行聚类的数据。epsilon:DBSCAN 中的领域半径,用于确定某个点的邻域范围。minPts:DBSCAN 中的最小点数,用于判定某个点为核心点的邻域内最少点数。clusters:存储数据点所属的聚类编号。clusterCount:最终确定的聚类数目。visited:标记数据点是否已经被访问过的逻辑数组。neighborPts:存储邻域内的数据点索引。distances:数据点之间的距离矩阵。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











