






目录
简介:
差分进化算法(Differential Evolution Algorithm,DE)是一种高效的全局优化算法,由Storn和Price于1995年提出。该算法基于群体智能,通过不断改进目标函数来优化群体中的个体。在差分进化算法中,每个个体代表一个解向量,整个群体则构成了解空间的一个子集。
1 算法原理
差分进化算法的基本流程包括初始化、变异、交叉和选择操作。首先,算法会随机生成足够多的初始个体,构成初始群体。然后,对于每个个体,根据固定的变异策略生成一个变异个体。接着,将原个体和变异个体进行交叉,得到一个新的个体。最后,将新个体与原个体进行比较,选择适应度更好的个体进入下一代。这个过程不断迭代,直到满足终止条件为止。具体流程如下。
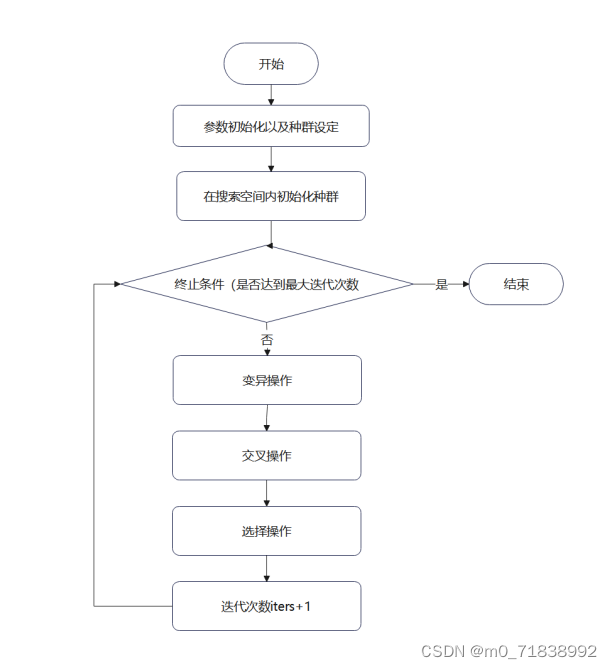
2 具体流程
2.1 具体问题
目标函数:
约束条件:
分别为第
个基因的上下限。
2.2 种群的初始化
是种群中第
个个体的第
个基因值,
是在上下限中随机生成一个值。
2.3 变异
差分进化算法与遗传算法对的最显著区别在于DE的个体变异是通过差分策略实现的如下式所示:
其中是第
次迭代时第
个变异后的个体,
是第
次迭代所产生的第
个个体,
是缩放因子。
2.4 交叉
让第次迭代产生的第
个个体
,和第
次迭代变异产生的第
个个体
进行交叉操作.
:
:
为交叉概率,
为第
次迭代时交叉所产生的第
个个体的第
个基因。
2.5 选择
用贪婪算法来选择下一代的种群>
:
:
3 总结
差分进化算法以其强大的全局搜索能力、简单易实现的特性、快速的收敛速度以及高鲁棒性在优化问题中表现出色。该算法通过变异、交叉和选择操作在整个搜索空间中寻找最优解,仅需设置少量参数如种群大小、交叉概率和变异因子,便于实际应用中的调整和优化。同时,差分进化算法能够充分利用种群信息,快速收敛至最优解,处理复杂问题时效率较高。此外,该算法对初始种群和参数设置不敏感,性能稳定,且具备较好的抗噪声能力,适用于各种优化场景。
4 Pyhton具体代码(DE)
import math
import random
import numpy as np
import matplotlib.pyplot as plt
class De:
def __init__(self,F,CR):
self.F=F
self.CR=CR
def fitness(self,X):
if self.pdhs(X)>=2:
y = math.cos(X[:, 1]) + math.sin(X[:, 0]) + X[:, 1] ** 2
else:
y=math.cos(X[1]) + math.sin(X[0]) + X[1] ** 2
return y
def mutate(self,X):
P=[]
n,m=np.shape(X)
X=np.array(X)
a,b,c = random.sample(range(0, n), 3)
#随机选择三个种群进行变异操作
for i in range(n):
t=X[a,:]+self.F*(X[b,:]-X[c,:])
P.append(t)
P=np.array(P)
# print(P)
return P
def cross(self,X,P):
NewP=[]
n, m = np.shape(X)
for i in range(n):
temp = []
for j in range(m):
# 随机生成一个0-1之间的小数
c = random.uniform(0, 1)
# 如果c<=cr,则选择H中个体染色体
if (c <= self.CR):
temp.append(X[i,j])
else:
temp.append(P[i,j])
# 将新产生的个个体加入新种群
NewP.append(temp)
return NewP
def selection(self,X,NewP):
Newpopulation = []
NewP=np.array(NewP)
n, m = np.shape(X)
for i in range (n):
if self.fitness(X[i,:])>self.fitness(NewP[i,:]):
t=NewP[i,:].copy()
else:
t=X[i,:].copy()
# print(t)
Newpopulation.append(t)
Newpopulation=np.array(Newpopulation)
return Newpopulation
def bestp(self,Newpopulation):
n, m = np.shape(Newpopulation)
bestpopulation=[]
bestfitness=10000
for i in range(n):
if self.fitness(Newpopulation[i, :]) < bestfitness:
bestpopulation=Newpopulation[i,:].copy()
return bestpopulation,self.fitness(bestpopulation)
def pdhs(self, X):
m = np.shape(X)
# 数组维度至少为2D时返回行数,否则返回错误信息
if X.ndim >= 2:
return m[0]
else:
return 1 # "输入不是二维数组,没有行的概念。"
#种群数量
N=1000
#特征数
M=2
De=De(F=0.8,CR=0.4)
#种群的生成
population = []
for i in range(N):
chromosome = [] # 每个个体的染色体
for j in range(M):
chromosome.append(random.uniform(-2, 2)) # 自变量的范围是[-4,4]
population.append(chromosome)
#迭代次数
population=np.array(population)
iters=100
#记录每次迭代的最优种群
besthistory=[]
iterss=[]
#种群更新全过程
for i in range(iters):
#变异
P=De.mutate(population)
#交叉
NewP=De.cross(population,P)
#选择产生的下一代种群
population=De.selection(population,NewP)
bestpopulation,bestfitness=De.bestp(population)
besthistory.append(bestfitness)
iterss.append(i)
print("第{}次迭代,最优种群为:{},最优适应度:{}".format(i+1,bestpopulation,bestfitness))
#迭代图像绘制
plt.rcParams["font.sans-serif"] = "SimHei"#汉字乱码的解决方法
plt.plot(iterss,besthistory,color='g')
#坐标题目绘制
plt.xlabel("迭代次数")
plt.ylabel("每次迭代的最优适应度")
plt.show()
















 703
703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









