






Pandas是一个开源的Python库,用于数据分析和数据处理。它提供了数据结构和函数,使得处理结构化数据变得更加简单和高效。Pandas最常用的数据结构是DataFrame,类似于表格或电子表格,可以将数据组织成行和列。Pandas还提供了许多用于数据操作、数据清洗、数据转换和数据分析的功能,使得用户可以更轻松地处理和分析大量的数据。Pandas还可以和其他Python库如NumPy和Matplotlib等一起使用,方便进行数据分析和可视化。
一、常用的数据结构
1.Series
1.1List列表创建
import pandas as pd
data1 = pd.Series([1, -5, 6, -4,8,-7,-4,5])
print(data1)
x = ["I", "O", "V", "E"]
z = [1, 0, 2, 4]
data2 = pd.Series(x, index = z, name = "col")
print(data2)
# 0 1
# 1 -5
# 2 6
# 3 -4
# 4 8
# 5 -7
# 6 -4
# 7 5
# dtype: int64
# 1 I
# 0 O
# 2 V
# 4 E
# Name: col, dtype: object1.2dic字典创建
data3 = {'OI': 99000, 'OH': 75000, 'HA': 1500, 'WOW': 5560}
data4 = pd.Series(data3)
print(data4)
# OI 99000
# OH 75000
# HA 1500
# WOW 5560
# dtype: int641.3引用数据自动找到对应值
data3 = {'OI': 99000, 'OH': 75000, 'HA': 1500, 'WOW': 5560}
data4 = pd.Series(data3)
names = ['OI', 'OH', 'WOW', 'HA']
data5 = pd.Series(data3, index = names)
print(data4+data5)
# HA 3000
# OH 150000
# OI 198000
# WOW 11120
# dtype: int642.DataFrame
2.1创建索引
data = {
'name':['张三', '李四', '王五', '小黄'],
'sex':['male', 'female', 'female', 'male'],
'year':[2221, 2201, 2024, 2025],
'city':['北京', '杭州', '广州', '北京']
}
df1= pd.DataFrame(data, columns = ['name', 'year', 'sex', 'city'])
display(df1)

二、索引
1.索引对象
1.1显示dataframe的索引和列
display(df1)
print(df1.index)
print(df1.columns)
1.2重构索引
import pandas as pd
obj = pd.Series([7.2,-3.3,3.5,3.6],index = ['b', 'a', 'd', 'c'])
obj = obj.reindex(['a','b','c','d','e'])
#a -3.3
#b 7.2
#c 3.6
#d 3.5
#e NaN
#dtype: float641.3重构索引时填充缺失值
obj.reindex(['a', 'b', 'c', 'd', 'e'], fill_value = 0)1.4缺失值的前向填充
import numpy as np
obj1 = pd.Series(['school','studnet','teacher'],index = [0,3,4])
obj1.reindex(np.arange(6),method = 'ffill')
# 0 school
# 1 school
# 2 school
# 3 studnet
# 4 teacher
# 5 teacher
# dtype: object1.5dataframe
data1 = pd.DataFrame(np.arange(9).reshape(3,3),
index = ['a','b','d'],columns = ['one','two','four'])
display(data1)
data1.reindex(index = ['a','b','c','d'],columns = ['one','two','three','four'])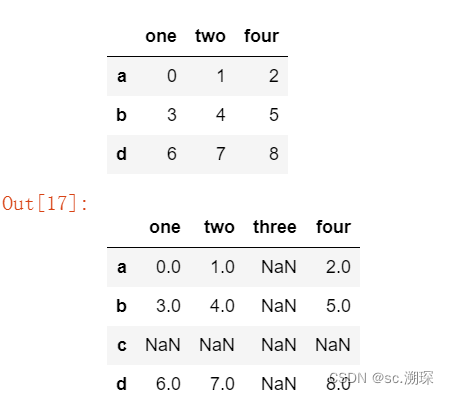
1.6填充值(fill_value = n)
data1.reindex(index = ['a','b','c','d'],columns = ['one','two','three','four'], fill_value = 100)1.7dataframe属性
print('信息表的所有值为:\n',df3.values)
print('信息表的所有列为:\n',df3.columns)
print('信息表的元素个数为:',df3.size)
print('信息表的维度是:',df3.ndim)
print('信息表的形状为:',df3.shape)
三、数据选取
1.行数据选取
display(df3)
print('显示前2行:\n',df3[:2])
print('显示1-3三行:\n',df3[0:3])
2.列选取
w1 = df3['name']
print('选取1列数据:\n',w1)
w2 = df3[['name','year']]
print('选取2列数据:\n',w2)3.使用loc和iloc选取行和列
display(df3.loc[:,['name','year']] )
#显示name和year两列
display(df3.iloc[[1,3]])
display(df3.iloc[[1,3],[1,2]])4.布尔选择
df3[df3['year']==2025]四、数据增删补
1.pd.concat()与df.append()
df = df.append(df2)
df_new = pd.concat([df, df2])
2.删除一行
df.drop(index_name)
3.删除多行
df.drop([index1, index2, ...])
4.删除一列
df.drop(column_name, axis=1)
5.删除多列
df.drop([column1, column2, ...], axis=1)
6.将水果价格表中的“元”去掉
data = {'fruit':['apple','grape','banana'],'price':['3元','3元','8元']}
df1 = pd.DataFrame(data)
print(df1)
def f(x):
return x.split('元')[0]
df1['price'] = df1['price'].map(f)
print('修改后的数据表:\n',df1)
# fruit price
# 0 apple 3元
# 1 grape 3元
# 2 banana 8元
# 修改后的数据表:
# fruit price
# 0 apple 3
# 1 grape 3
# 2 banana 87.apply方法
DataFrame.apply(func, axis=0, raw=False, result_type=None, args=(), **kwds)
参数说明:
- `func`:需要应用的函数,可以是自定义函数或lambda函数。
- `axis`:指定应用函数的轴。默认为0,表示按列应用函数;1表示按行应用函数。
- `raw`:布尔值,指示传递给函数的数据是否为原始索引。默认为False。
- `result_type`:指定返回结果的类型,可选值为`None`、`raise`、`reduce`。默认为`None`,返回一个Series。
- `args`、`**kwds`:传递给函数的其他参数。
import pandas as pd
# 定义一个自定义函数
def square(x):
return x ** 2
# 创建一个DataFrame
data = {'A': [1, 2, 3], 'B': [4, 5, 6]}
df = pd.DataFrame(data)
# 按列应用自定义函数
df.apply(square)
# 输出:
# A B
# 0 1 16
# 1 4 25
# 2 9 36
# 按行应用自定义函数
df.apply(square, axis=1)
# 输出:
# 0 1
# 0 1 16
# 1 4 25
# 2 9 36
8.applymap函数的用法
DataFrame.applymap(func)
import pandas as pd
# 创建一个DataFrame
data = {'A': [1, 2, 3, 4], 'B': [5, 6, 7, 8]}
df = pd.DataFrame(data)
# 定义一个函数,将每个元素加上10
def add_ten(x):
return x + 10
# 使用applymap函数将add_ten函数应用于每个元素
new_df = df.applymap(add_ten)
print(new_df)
A B
0 11 15
1 12 16
2 13 17
3 14 18
9.DataFrame排序。
import pandas as pd
# 创建一个DataFrame
data = {'Name': ['John', 'Emma', 'Oliver'],
'Age': [25, 28, 30],
'Country': ['USA', 'Canada', 'UK']}
df = pd.DataFrame(data)
# 按照年龄列进行升序排序
df_sorted = df.sort_values('Age')
print(df_sorted)
Name Age Country
0 John 25 USA
1 Emma 28 Canada
2 Oliver 30 UK
如果要按照多个列进行排序,可以将列的名称以列表的形式传递给sort_values()函数
df_sorted = df.sort_values(['Country', 'Age'])
print(df_sorted)
Name Age Country
1 Emma 28 Canada
0 John 25 USA
2 Oliver 30 UK
注意,sort_values()函数默认按照升序排序。如果要按照降序排序,可以将ascending参数设置为False:
df_sorted = df.sort_values('Age', ascending=False)
10.数据的频数统计。
obj = pd.Series(['a','b','c','a','d','c'])
print(obj.unique())
print(obj.value_counts())
#['a' 'b' 'c' 'd']
#a 2
#c 2
#b 1
#d 1
#dtype: int6411.groupby基本用法
groupby函数是pandas库中的一个函数,用于根据指定的列或多个列对数据进行分组。下面是几个示例:
- 对DataFrame按照某一列分组,并计算分组后每组的平均值:
import pandas as pd
data = {'Name': ['John', 'Anna', 'Peter', 'Linda', 'John'],
'Age': [23, 36, 28, 45, 30],
'Gender': ['M', 'F', 'M', 'F', 'M']}
df = pd.DataFrame(data)
grouped = df.groupby('Name')
mean_age = grouped['Age'].mean() # 分组后计算每组的平均年龄
print(mean_age)
输出结果:
Name
Anna 36.0
John 26.5
Linda 45.0
Peter 28.0
Name: Age, dtype: float64
- 对DataFrame按照多个列分组,并计算每组的数量:
import pandas as pd
data = {'Name': ['John', 'Anna', 'Peter', 'Linda', 'John'],
'Age': [23, 36, 28, 45, 30],
'Gender': ['M', 'F', 'M', 'F', 'M']}
df = pd.DataFrame(data)
grouped = df.groupby(['Name', 'Gender'])
count = grouped.size() # 分组后计算每组的数量
print(count)
输出结果:
Name Gender
Anna F 1
John M 2
Linda F 1
Peter M 1
dtype: int64
- 对DataFrame按照某一列分组,并同时计算多个统计量:
import pandas as pd
data = {'Name': ['John', 'Anna', 'Peter', 'Linda', 'John'],
'Age': [23, 36, 28, 45, 30],
'Gender': ['M', 'F', 'M', 'F', 'M']}
df = pd.DataFrame(data)
grouped = df.groupby('Name')
stats = grouped['Age'].agg(['mean', 'min', 'max']) # 分组后计算每组的平均年龄、最小年龄和最大年龄
print(stats)
输出结果:
mean min max
Name
Anna 36.0 36 36
John 26.5 23 30
Linda 45.0 45 45
Peter 28.0 28 28















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









