







 本文详细介绍了Pandas库中的Series和DataFrame两种基本对象,包括它们的特点、使用步骤、数据操作(如索引、切片、运算符应用、数据提取、合并和连接等),帮助读者理解和掌握这两种核心数据结构的使用。
本文详细介绍了Pandas库中的Series和DataFrame两种基本对象,包括它们的特点、使用步骤、数据操作(如索引、切片、运算符应用、数据提取、合并和连接等),帮助读者理解和掌握这两种核心数据结构的使用。
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
pandas有两种基本对象:Series、DataFrame
一、Series特点
- 一个带有名称和索引的一维数组
- Series中包含的数据类型可以是整数、浮点、字符串、列表、元组、ndarray等
- 语法:pd.Series(data=None,index=None,dtype=None,name=None)
二、Series使用步骤
1.Series定义
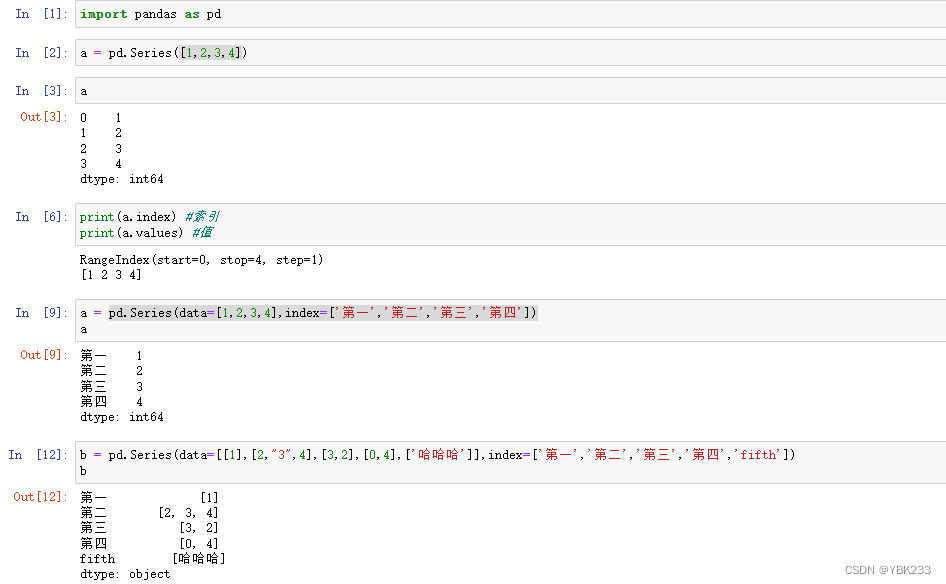
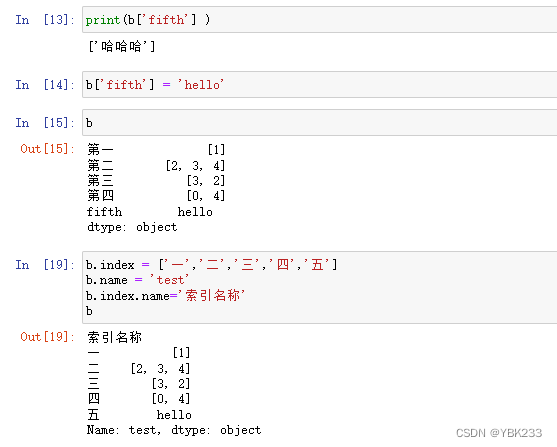
2.索引和切片

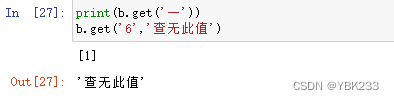
3.series的.get()
series和字典非常类似,我们可以将index看成key,对应值为value
如果在series中找不到要找的值,则返回预设的默认值
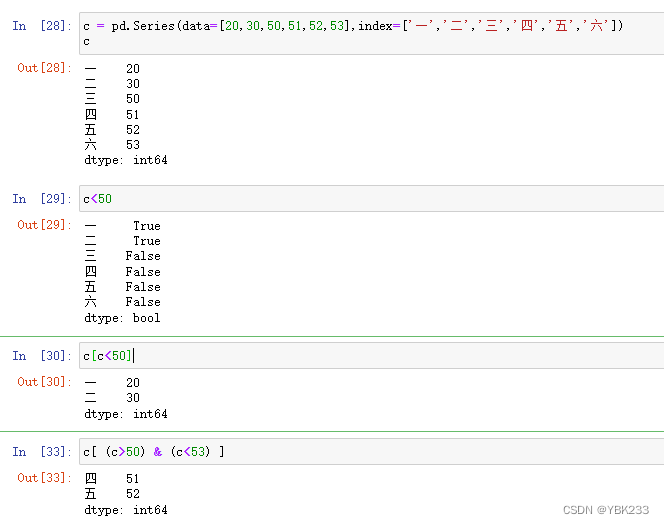
4.掩码提取
5.Series运算符和广播方法
Series支持ndarray的运算符、广播方法,包括numpy中的各种运算函数、聚合函数等
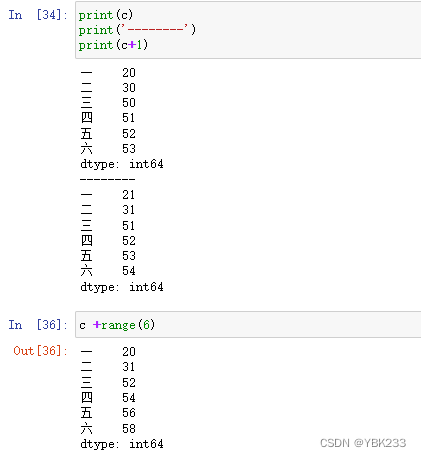
6.ufunc在Series对象中使用
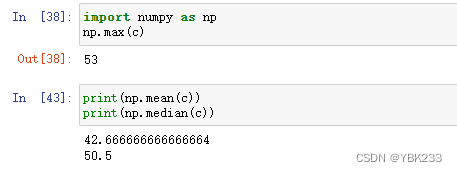
三、DataFrame
DataFrame是一个带有索引的二维数据结构,每个列都可以有自己的名字,且可以有不同的数据类型。与Excel中sheet页相似,也可理解为由多个Series拼接而成,共用一个索引。
1.DataFrame创建
语法:pd.DataFrame(data=None,index=None,columns=None,dtype=None)
1、通过数组转化
2、通过字典转化
3、通过嵌套列表转化
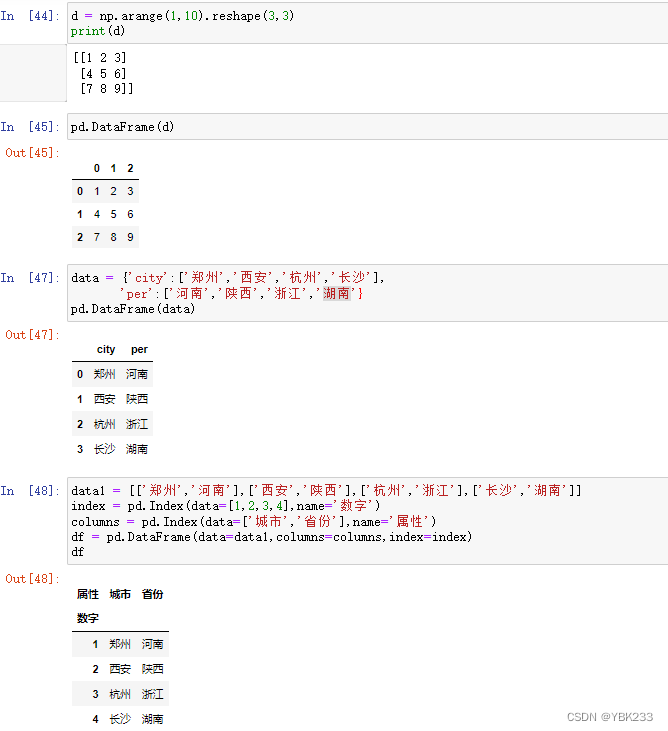
- df.index增加或修改行标签
- df.index.name增加或修改行标签名
- df.columns增加或修改列标签
- df.columns.name增加或修改列标签名
2.数据提取
- 根据标签名提取

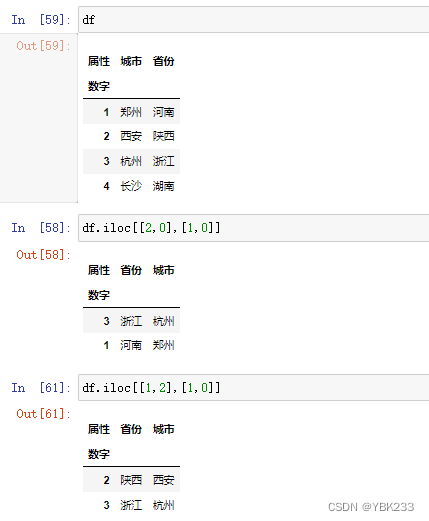
- df.loc[]
语法:df.loc[索引行,索引列]

- df.iloc[]
隐式索引
3.行列增删改
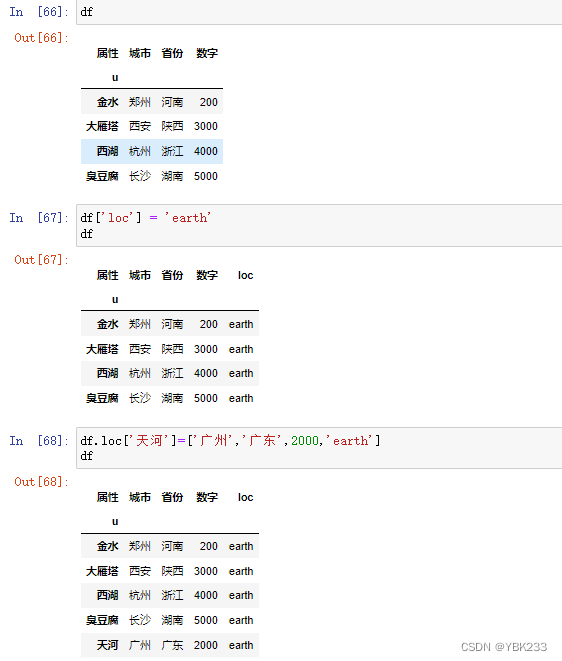
-
df.pop()只能删除列,直接在原数据上修改
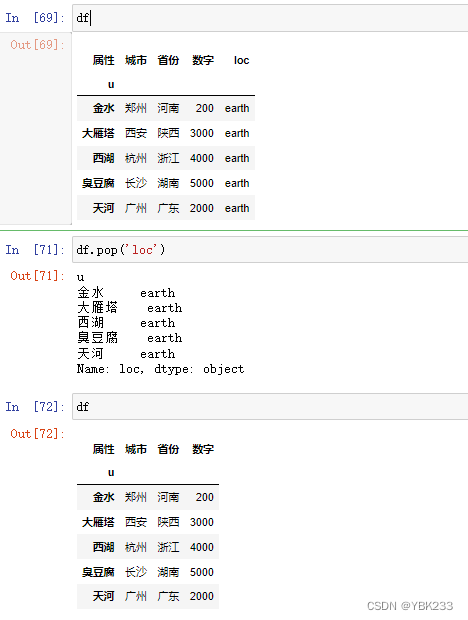
-
df.drop(),设置implace=False并没有删除原表记录,而是返回一个新的DataFrame对象,为true时,则之间在原数据上修改
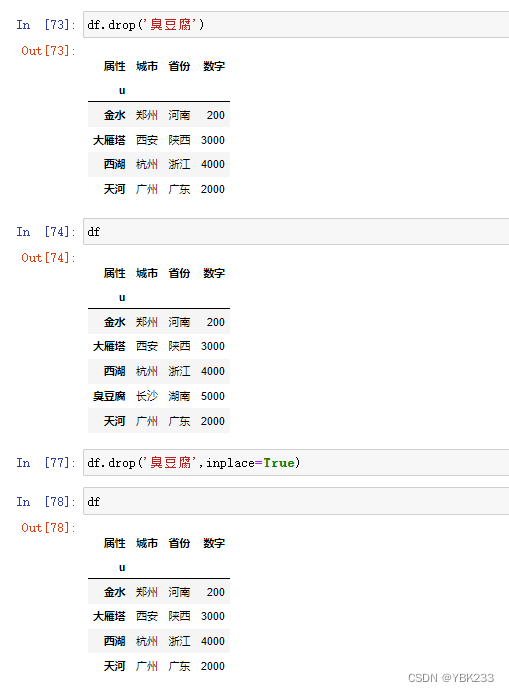
4.列顺序修改
修改后返回新的对象,原数据并不变

5.索引和列名修改
- 修改索引名用需要在df.rename()中设置index参数
- 修改列名只需要设置参数columns
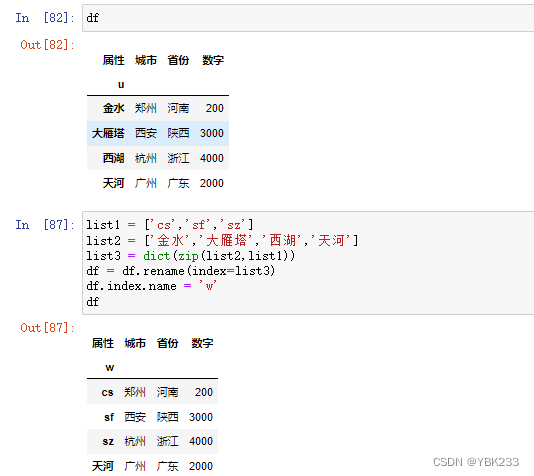
6.Series.astype()
不改变原数组,返回新的对象
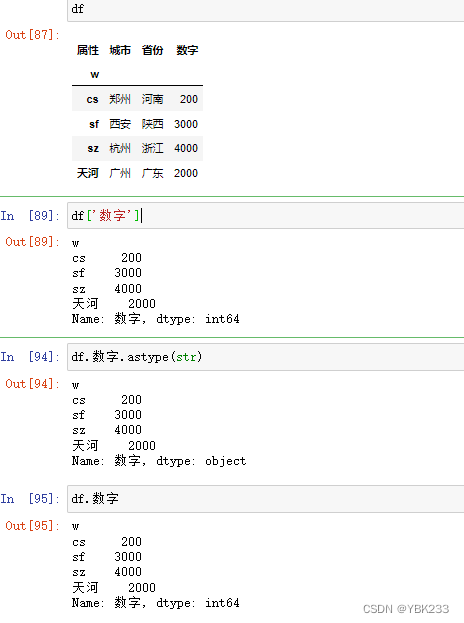
四、DataFrame表合并、连接
1.pd.concat(df1,df2)合并
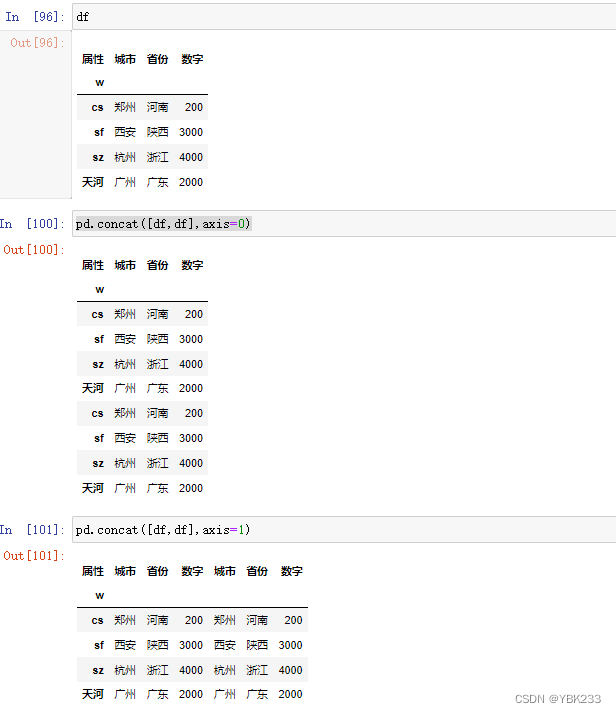
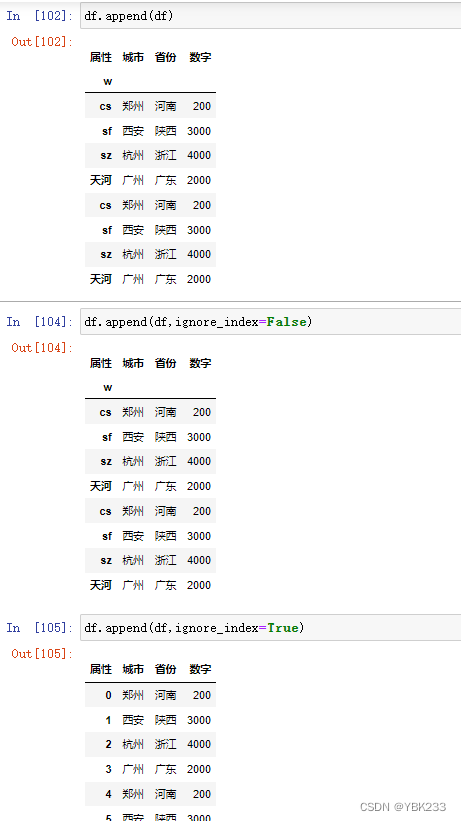
2.pd.append(df)拼接
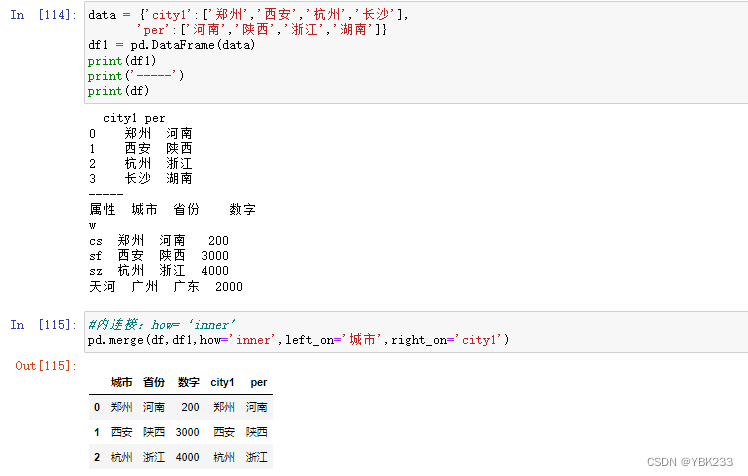
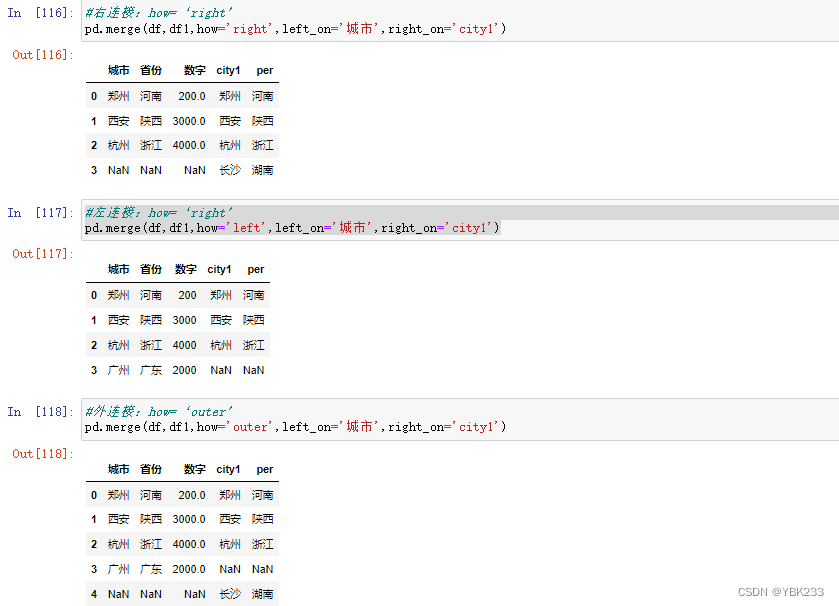
3.pd.merge()
pd.merge(‘left’,‘right’,how=‘inner’,on=None,left_on=None,right=None)
how:
- left:仅使用左框架中的键,类似于sql中左外连接,保留关键顺序
- right:仅使用右框架中的键,类似于sql中右外连接,保留关键顺序
- outer:使用来自两个帧的键的并集,类似于sql full outer,按字典顺序排序键
- inner:使用来自两个帧的键的交集,类似于sql内部加入,按左键排序

















 2789
2789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









