







一. Pytest数据参数化(DDT)
语法结构:@pytest.mark.parametrize(argnames,argvalues)
常用参数:
- argnames:参数名
- argvalues:参数对应值,为列表,[元组,字典]
运行方式:参数值为N个,测试方法就会运行N次
二. Pytest+Excel接口自动化框架
Common/FileDataDriver.py中FileReader类
class FileReader:
"""
专门用来读取文件的,Yaml、Excel
"""
@staticmethod
def read_excel(file_path=CASEDATAURL, sheet_name=SHEETNAME):
"""
读取Excel文件,只支持 .xlsx文件
:param file_path: 文件路径
:return: excel文件数据,元组的格式
"""
# 打开现有的Excel文件或创建新的文件
try:
workbook = openpyxl.load_workbook(file_path)
except FileNotFoundError:
workbook = openpyxl.Workbook()
# 选择或创建指定的工作表
if sheet_name in workbook.sheetnames:
worksheet = workbook[sheet_name]
else:
worksheet = workbook.create_sheet(sheet_name)
data = []
for row in worksheet.values:
# 判断是整型则加到对应的数据列表中
if isinstance(row[0], int):
data.append(row)
workbook.close()
return data
@staticmethod
def readExcelToDict(file_path=CASEDATAURL, sheet_name=SHEETNAME):
# 打开现有的Excel文件或创建新的文件
try:
workbook = openpyxl.load_workbook(file_path)
except FileNotFoundError:
workbook = openpyxl.Workbook()
# 选择或创建指定的工作表
if sheet_name in workbook.sheetnames:
worksheet = workbook[sheet_name]
else:
worksheet = workbook.create_sheet(sheet_name)
# 获取列名
headers = [cell.value for cell in worksheet[2]]
# 将数据存储为字典
data = []
# 把小的数据从第三行开始
for row in worksheet.iter_rows(min_row=3, values_only=True):
data.append(dict(zip(headers, row)))
workbook.close()
return data
@staticmethod
def writeDataToExcel(file_path=CASEDATAURL, sheet_name=SHEETNAME, row=None, column=None, value=None):
# 打开现有的Excel文件或创建新的文件
try:
workbook = openpyxl.load_workbook(file_path)
except FileNotFoundError:
workbook = openpyxl.Workbook()
# 选择或创建指定的工作表
if sheet_name in workbook.sheetnames:
worksheet = workbook[sheet_name]
else:
worksheet = workbook.create_sheet(sheet_name)
# 写入数据到指定行和列
worksheet.cell(row=row, column=column).value = value
# 保存修改后的文件
workbook.save(file_path)三. 完整形态自动化框架组装
Allure报告日志及动态标题
def __dynamic_title(self, CaseData):
# # 动态生成标题
# allure.dynamic.title(data[11])
# 如果存在自定义标题
if CaseData["caseName"] is not None:
# 动态生成标题
allure.dynamic.title(CaseData["caseName"])
if CaseData["storyName"] is not None:
# 动态获取story模块名
allure.dynamic.story(CaseData["storyName"])
if CaseData["featureName"] is not None:
# 动态获取feature模块名
allure.dynamic.feature(CaseData["featureName"])
if CaseData["remark"] is not None:
# 动态获取备注信息
allure.dynamic.description(CaseData["remark"])
if CaseData["rank"] is not None:
# 动态获取级别信息(blocker、critical、normal、minor、trivial)
allure.dynamic.severity(CaseData["rank"])jsonpath实现接口关联
all_val={ },用来存储关联变量
提取方式:

读取方式:
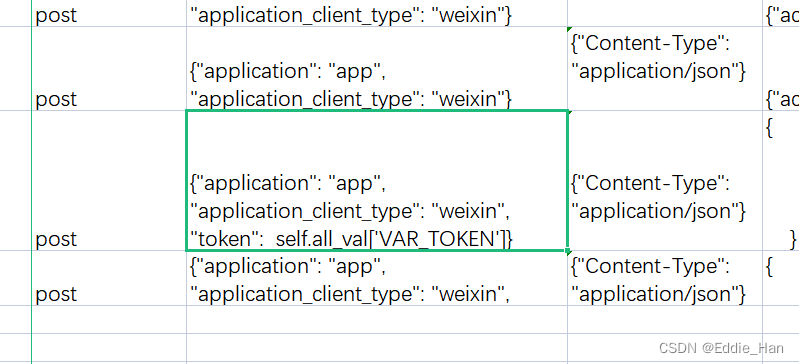
def __json_extraction(self, CaseData, res):
# JSON提取器,两个字段不能为空
try:
if CaseData["jsonKey"] and CaseData["jsonValue"]:
# 获取对应:JSON提取_引用名称;把存储列表(excel)中是字符串,进行类型转换
varStrList = eval(CaseData["jsonKey"])
jsonList = eval(CaseData["jsonValue"])
# 获取列表长度,进行遍历
length = len(varStrList)
# 循环输出列表值
for i in range(length):
# 1. 获取对应的key 和 valure
key = varStrList[i]
jsonExp = jsonList[i]
print(f"key:{key},jsonExp:{jsonExp}")
# 2.通过响应数据进行字典值获取
valueJson = self.ak.get_text(res, jsonExp)
# 3. 持续添加参数,只要参数名不重复,重复的后面就会覆盖前面的参数
self.all_val[key] = valueJson
print("res:", self.all_val)
except:
print("未提取到数据,请检查需要提取的数据正确性。")















 945
945











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









