






在UMAP作图过程中,有些时候,不同类别的分群并没有显著性被区分开,这个时候,我们想通过一些参数的调整来使得 不同群点区分度更好。
UMAP的调参:
可调的参数如下:
1.随机数:seed.use:默认为42
2.计算距离的方法 metric
3.相邻点数量 n.neighbors
4.嵌入的空间的尺寸 n.components
调参的经验:【降维算法UMAP】调参获得更适合的低维图_runumap参数-CSDN博客
UMAP的内置算法
UMAP首先使用Nearest-Neighbor-Descent算法来找到每个数据点的最近邻。也就是NN-Descent构建K近邻图,文章发表于2011年
K近邻图的构建流程:
我们可以从V(数据集)中每一个点的现有的近似K近邻出发,通过探索该点邻居的邻居(在当前近似K近邻中)而不断完善该点的K近邻。换句话说,可从粗略的K近邻图出发通过改进而不断完善它。
NN-Descent构建K近邻图——论文超详细注解 | whenever (whenever5225.github.io)
补充定义:
哈希表:是一种数据结构
定义:
散列表(Hash table,也叫哈希表),是根据键(Key)而直接访问在内存存储位置的数据结构。也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做哈希函数,存放记录的数组称做哈希表
目的:
是为了快速查找。它提供了快速的插入操作和查找操作,无论哈希表总中有多少条数据,插入和查找的时间复杂度都是为O(1)。
实际应用:
因为哈希表的查找速度非常快,所以在很多程序中都有使用哈希表,例如拼音检查器。
参考:
数据结构 5分钟带你搞定哈希表(建议收藏)!!!_哈希表怎么画-CSDN博客
图文并茂详解数据结构之哈希表 - 知乎 (zhihu.com)
树:是一种数据结构
树是一种数据结构,它是由n(n≥0)个有限节点组成一个具有层次关系的集合。把它叫做“树”是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点:
每个节点有零个或多个子节点;没有父节点的节点称为根节点;每一个非根节点有且只有一个父节点;除了根节点外,每个子节点可以分为多个不相交的子树。
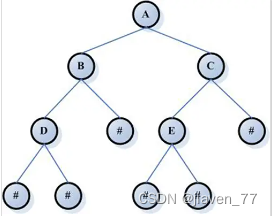
参考
代码:https://github.com/aaalgo/kgraph
【降维算法UMAP】调参获得更适合的低维图_runumap参数-CSDN博客
NN-Descent构建K近邻图——论文超详细注解-CSDN博客
NN-Descent构建K近邻图——论文超详细注解 | whenever (whenever5225.github.io)
调整参数的代码
scRNA<-RUnUMAP(SCRNA,dims=1:20)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









