






Torch框架
数据集加载案例
通过一些数据集的加载案例,真正了解数据类及数据加载器。
示例
class MyCsvDataset(Dataset):
def __init__(self, filename):
df = pd.read_csv(filename)
# 删除文字列
df = df.drop(["学号", "姓名"], axis=1)
# 转换为tensor
data = torch.tensor(df.values)
# 最后一列以前的为data,最后一列为label
self.data = data[:, :-1]
self.label = data[:, -1]
self.len = len(self.data)
def __len__(self):
return self.len
def __getitem__(self, index):
idx = min(max(index, 0), self.len - 1)
return self.data[idx], self.label[idx]
def test001():
excel_path = r"./大数据答辩成绩表.csv"
dataset = MyCsvDataset(excel_path)
dataloader = DataLoader(dataset, batch_size=4, shuffle=True)
for i, (data, label) in enumerate(dataloader):
print(i, data, label)优化:使用ImageFolder加载图片集
ImageFolder 会根据文件夹的结构来加载图像数据。它假设每个子文件夹对应一个类别,文件夹名称即为类别名称。
ImageFolder构造函数如下:
torchvision.datasets.ImageFolder(root, transform=None, target_transform=None, is_valid_file=None)
参数解释
-
root:字符串,指定图像数据集的根目录。 -
transform:可选参数,用于对图像进行预处理。通常是一个torchvision.transforms的组合。 -
target_transform:可选参数,用于对目标(标签)进行转换。 -
is_valid_file:可选参数,用于过滤无效文件。如果提供,只有返回True的文件才会被加载。
加载官方数据集
在 PyTorch 中官方提供了一些经典的数据集,如 CIFAR-10、MNIST、ImageNet 等,可以直接使用这些数据集进行训练和测试。
数据集:Datasets — Torchvision 0.21 documentation
常见数据集:
-
MNIST: 手写数字数据集,包含 60,000 张训练图像和 10,000 张测试图像。
-
CIFAR10: 包含 10 个类别的 60,000 张 32x32 彩色图像,每个类别 6,000 张图像。(全连接神经网络)
-
CIFAR100: 包含 100 个类别的 60,000 张 32x32 彩色图像,每个类别 600 张图像。
-
COCO: 通用对象识别数据集,包含超过 330,000 张图像,涵盖 80 个对象类别。
torchvision.transforms 和 torchvision.datasets 是 PyTorch 中处理计算机视觉任务的两个核心模块,它们为图像数据的预处理和标准数据集的加载提供了强大支持。
transforms 模块提供了一系列用于图像预处理的工具,可以将多个变换组合成处理流水线。
datasets 模块提供了多种常用计算机视觉数据集的接口,可以方便地下载和加载。
以MNIST数据集为例:
def test():
transform = transforms.Compose(
[
transforms.ToTensor(),
]
)
# 训练数据集
data_train = datasets.MNIST(
root="./data",
train=True,
download=True,
transform=transform,
)
trainloader = DataLoader(data_train, batch_size=8, shuffle=True)
for x, y in trainloader:
print(x.shape)
print(y)
break
# 测试数据集
data_test = datasets.MNIST(
root="./data",
train=False,
download=True,
transform=transform,
)
testloader = DataLoader(data_test, batch_size=8, shuffle=True)
for x, y in testloader:
print(x.shape)
print(y)
break全连接神经网络
深入神经网络
神经网络是由大量人工神经元按层次结构连接而成的计算模型。每一层神经元的输出作为下一层的输入,最终得到网络的输出。
1 基本结构
神经网络有下面三个基础层(Layer)构建而成:
-
输入层(Input): 神经网络的第一层,负责接收外部数据,不进行计算。
-
隐藏层(Hidden): 位于输入层和输出层之间,进行特征提取和转换。隐藏层一般有多层,每一层有多个神经元。
-
输出层(Output): 网络的最后一层,产生最终的预测结果或分类结构。
网络构建
我们使用多个神经元来构建神经网络,相邻层之间的神经元相互连接,并给每一个连接分配一个权重,经典如下:
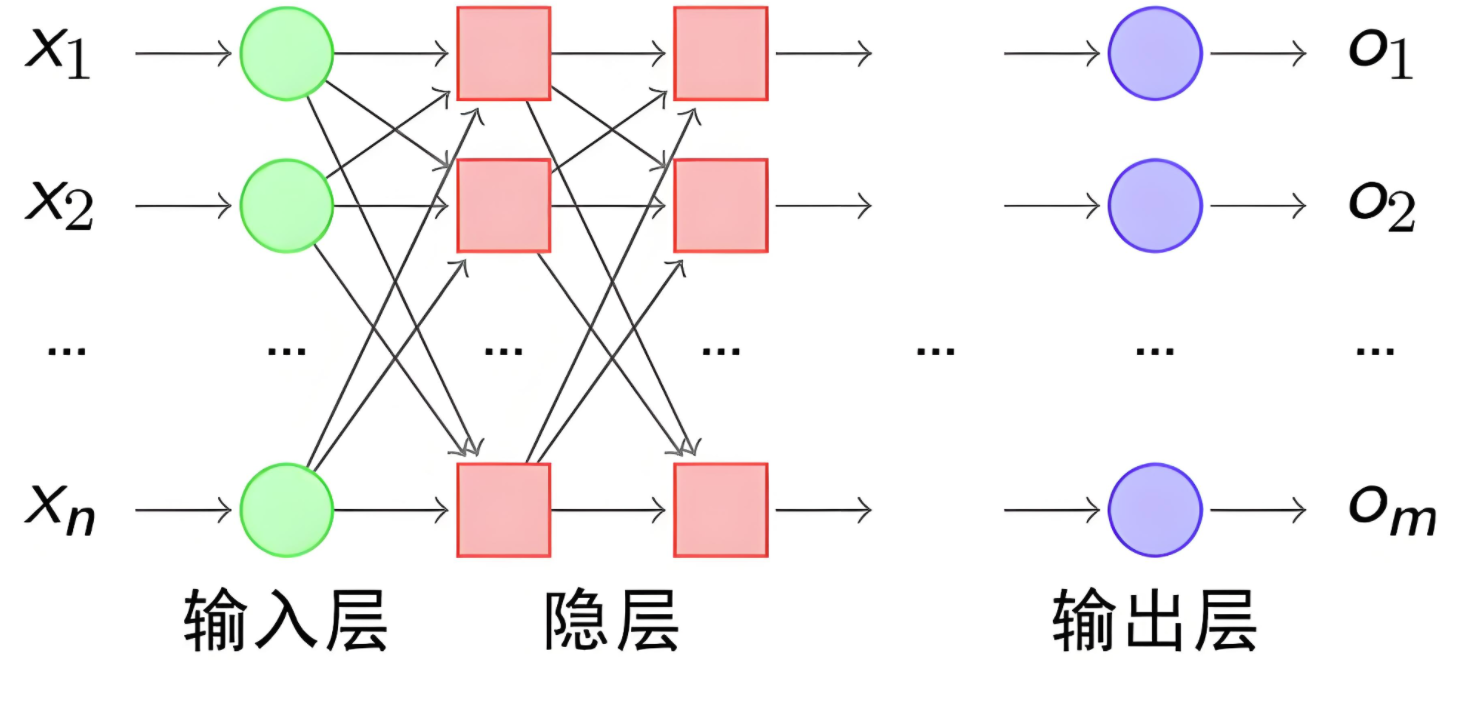
全连接神经网络
前馈神经网络(Feedforward Neural Network,FNN)是一种最基本的神经网络结构,其特点是信息从输入层经过隐藏层单向传递到输出层,没有反馈或循环连接。
全连接神经网络(Fully Connected Neural Network,FCNN)是前馈神经网络的一种,每一层的神经元与上一层的所有神经元全连接,常用于图像分类、文本分类等任务。
创建全连接神经网络
创建一个最基本的全连接神经网络(也称为多层感知机,MLP)通常需要以下步骤和方法:
-
定义网络结构
-
输入层:确定输入数据的维度。例如,对于一个简单的图像分类任务,输入层的维度可能是图像的像素数量。
-
隐藏层:定义一个或多个隐藏层,每个隐藏层包含一定数量的神经元。隐藏层的数量和每个隐藏层的神经元数量可以根据任务需求调整。
-
输出层:根据任务目标确定输出层的神经元数量。例如,对于一个二分类问题,输出层通常有一个神经元;对于多分类问题,输出层的神经元数量等于类别数。
-
选择激活函数
-
隐藏层激活函数:常用的激活函数有ReLU(Rectified Linear Unit)、Sigmoid、Tanh等。ReLU是最常用的激活函数,因为它可以有效缓解梯度消失问题。
-
输出层激活函数:根据任务类型选择合适的激活函数。例如,对于二分类任务,输出层通常使用Sigmoid函数;对于多分类任务,输出层使用Softmax函数。
-
初始化权重和偏置
-
权重初始化:权重的初始化方法对网络的训练效果有重要影响。常见的初始化方法包括随机初始化(如Xavier初始化或He初始化)和零初始化(通常不推荐,因为会导致梯度消失)。
-
偏置初始化:偏置通常初始化为0或小的常数。
-
定义损失函数
-
二分类任务:通常使用二元交叉熵损失函数(Binary Cross-Entropy Loss)。
-
多分类任务:通常使用多类交叉熵损失函数(Categorical Cross-Entropy Loss)。
-
回归任务:通常使用均方误差损失函数(Mean Squared Error, MSE)。
-
选择优化器
-
SGD(随机梯度下降):最简单的优化器,通过计算梯度来更新权重。
-
Adam:一种自适应学习率的优化器,结合了RMSprop和Momentum的优点,通常在训练深度神经网络时表现良好。
-
其他优化器:如RMSprop、Adagrad等。
-
前向传播
-
在前向传播过程中,输入数据通过每一层的线性变换(权重乘法和偏置加法)和非线性激活函数,最终得到输出结果。
-
计算损失
-
使用定义的损失函数计算模型的输出与真实标签之间的差异。
-
反向传播
-
通过计算损失函数对每个权重和偏置的梯度,利用链式法则反向传播这些梯度,更新网络的权重和偏置。
-
训练模型
-
迭代地执行前向传播、计算损失和反向传播,直到模型的性能不再提升或达到预定的训练轮数。
示例:创建一个全连接神经网络,主要步骤包括:
-
定义模型结构。
-
初始化模型、损失函数和优化器。
-
准备数据。
-
训练模型。
-
(可选)评估模型。
你可以根据实际任务调整网络结构、损失函数和优化器等。
激活函数
激活函数的作用是在隐藏层引入非线性,使得神经网络能够学习和表示复杂的函数关系,使网络具备非线性能力,增强其表达能力。
1. 基础概念
通过认识线性和非线性的基础概念,深刻理解激活函数存在的价值。
1.1 线性理解
如果在隐藏层不使用激活函数,那么整个神经网络会表现为一个线性模型。我们可以通过数学推导来展示这一点。
假设:
-
神经网络有L 层,每层的输出为 \mathbf{a}^{(l)}。
-
每层的权重矩阵为 \mathbf{W}^{(l)} ,偏置向量为\mathbf{b}^{(l)}。
-
输入数据为\mathbf{x},输出为\mathbf{a}^{(L)}。
一层网络的情况
对于单层网络(输入层到输出层),如果没有激活函数,输出\mathbf{a}^{(1)} 可以表示为: \mathbf{a}^{(1)} = \mathbf{W}^{(1)} \mathbf{x} + \mathbf{b}^{(1)}
两层网络的情况
假设我们有两层网络,且每层都没有激活函数,则:
-
第一层的输出:\mathbf{a}^{(1)} = \mathbf{W}^{(1)} \mathbf{x} + \mathbf{b}^{(1)}
-
第二层的输出:\mathbf{a}^{(2)} = \mathbf{W}^{(2)} \mathbf{a}^{(1)} + \mathbf{b}^{(2)}
将\mathbf{a}^{(1)}代入到\mathbf{a}^{(2)}中,可以得到:
\mathbf{a}^{(2)} = \mathbf{W}^{(2)} (\mathbf{W}^{(1)} \mathbf{x} + \mathbf{b}^{(1)}) + \mathbf{b}^{(2)}
\mathbf{a}^{(2)} = \mathbf{W}^{(2)} \mathbf{W}^{(1)} \mathbf{x} + \mathbf{W}^{(2)} \mathbf{b}^{(1)} + \mathbf{b}^{(2)}
我们可以看到,输出\mathbf{a}^{(2)}是输入\mathbf{x}的线性变换,因为:\mathbf{a}^{(2)} = \mathbf{W}' \mathbf{x} + \mathbf{b}' 其中\mathbf{W}' = \mathbf{W}^{(2)} \mathbf{W}^{(1)},\mathbf{b}' = \mathbf{W}^{(2)} \mathbf{b}^{(1)} + \mathbf{b}^{(2)}。
多层网络的情况
如果有L层,每层都没有激活函数,则第l层的输出为:\mathbf{a}^{(l)} = \mathbf{W}^{(l)} \mathbf{a}^{(l-1)} + \mathbf{b}^{(l)}
通过递归代入,可以得到:
$$
\mathbf{a}^{(L)} = \mathbf{W}^{(L)} \mathbf{W}^{(L-1)} \cdots \mathbf{W}^{(1)} \mathbf{x} + \mathbf{W}^{(L)} \mathbf{W}^{(L-1)} \cdots \mathbf{W}^{(2)} \mathbf{b}^{(1)} + \mathbf{W}^{(L)} \mathbf{W}^{(L-1)} \cdots \mathbf{W}^{(3)} \mathbf{b}^{(2)} + \cdots + \mathbf{b}^{(L)}
$$
表达式可简化为:
$$
\mathbf{a}^{(L)} = \mathbf{W}'' \mathbf{x} + \mathbf{b}''
$$
其中,\mathbf{W}'' 是所有权重矩阵的乘积,\mathbf{b}''是所有偏置项的线性组合。
如此可以看得出来,无论网络多少层,意味着:
整个网络就是线性模型,无法捕捉数据中的非线性关系。
激活函数是引入非线性特性、使神经网络能够处理复杂问题的关键。
常见激活函数
激活函数通过引入非线性来增强神经网络的表达能力,对于解决线性模型的局限性至关重要。由于反向传播算法(BP)用于更新网络参数,因此激活函数必须是可微的,也就是说能够求导的。
2.1 sigmoid
Sigmoid激活函数是一种常见的非线性激活函数,特别是在早期神经网络中应用广泛。它将输入映射到0到1之间的值,因此非常适合处理概率问题。
2.1.2 特征
-
将任意实数输入映射到 (0, 1)之间,因此非常适合处理概率场景。
-
sigmoid函数一般只用于二分类的输出层。
-
微分性质: 导数计算比较方便,可以用自身表达式来表示:
![]()
2.1.3 缺点
-
梯度消失:
-
在输入非常大或非常小时,Sigmoid函数的梯度会变得非常小,接近于0。这导致在反向传播过程中,梯度逐渐衰减。
-
最终使得早期层的权重更新非常缓慢,进而导致训练速度变慢甚至停滞。
-
-
信息丢失:输入100和输入10000经过sigmoid的激活值几乎都是等于 1 的,但是输入的数据却相差 100 倍。
-
计算成本高: 由于涉及指数运算,Sigmoid的计算比ReLU等函数更复杂,尽管差异并不显著。

















 1569
1569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









