







目录
3.2 读数据 并且绘制任意两个特征之间的散点图观察回归关系
一、前言
本文将会介绍单隐藏层全连接神经网络数据分类的用法,以及全连接神经网络对波士顿房价数据的应用。当然写这篇文章是为了作者学习深度学习,对于nn(神经网络)这方面有一些理解。
一、全连接神经网络是什么?
为啥叫神经网络呢,其实大家可能会联想到人体内的神经元,其实神经网络中的每个节点就是神经元,与我们体内的神经系统其实是如出一辙的。
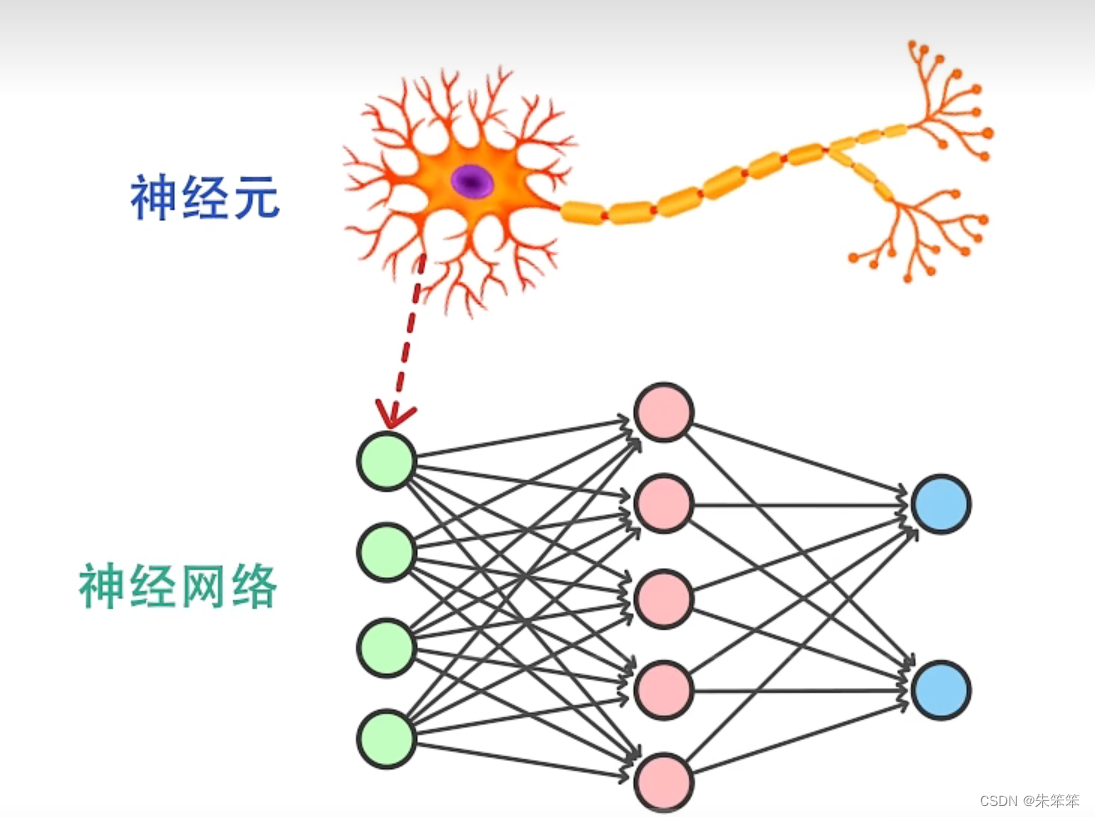
全连接神经网络是一种常见的人工神经网络,也被称为多层感知机(Multilayer Perceptron, MLP)。全连接神经网络包含多个层,每层都由多个神经元组成。每个神经元都与上一层的每个神经元都有一个连接,因此被称为“全连接”。
全连接神经网络通常由输入层、隐藏层和输出层组成。输入层接收原始数据,并将其传递给隐藏层。隐藏层对输入进行加权和处理,然后将结果传递给下一层。输出层最终生成预测结果。在训练过程中,神经网络会根据预测结果与真实结果之间的误差不断调整权重。这个过程被称为反向传播。
全连接神经网络的优点是可以处理非线性关系,并且可以对输入数据进行复杂的特征提取。它们在图像识别、自然语言处理、语音识别等应用中取得了很好的效果。

二、单连接神经网络模型对乳腺癌数据集分类
2.1导入库
暂时需要的库,后面的全连接神经网络基本也写里面了,不够的话会在下面的代码中补充的。
#读取癌症数据集,做全连接神经网络分类
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']#显示中文标签
plt.rcParams['axes.unicode_minus']=False#显示负号
import seaborn as sns
from sklearn.datasets import load_breast_cancer #乳腺癌数据集
from sklearn.model_selection import train_test_split #划分数据集
from sklearn.preprocessing import StandardScaler#标准化数据
from sklearn.neural_network import MLPClassifier#多层感知机分类
from sklearn.neural_network import MLPRegressor#多层感知机回归
from sklearn.model_selection import GridSearchCV#调参数用2.2调用全连接神经网络
#切分数据集
cancer = load_breast_cancer()
print(cancer.data.shape)
X_train,X_test,y_train,y_test=train_test_split(cancer.data,cancer.target,random_state=0,test_size=0.2)
print(X_train.shape)
#数据标准化
scaler=StandardScaler()
X_train_scaled=scaler.fit_transform(X_train)
X_test_scaled=scaler.transform(X_test)
MLP1 = MLPClassifier(hidden_layer_sizes=[1,100], #第i个元素表示第i个隐藏层中神经元的数量。[1,100]表示第一个隐藏层中有100个神经元
activation = "relu", ## 隐藏层激活函数
alpha = 0.001, ## 正则化L2惩罚的参数
solver = "adam", ## 求解方法
learning_rate = "adaptive",## 学习权重更新的速率
max_iter = 100, ## 最大迭代次数
random_state = 10,verbose = True)#verbose:是否将过程打印出来
## 训练模型
MLP1.fit(X_train_scaled,y_train)
## 输出预测结果的 mean accuracy 准确率达到0.86,迭代结果为20次
print("训练集准确率:{:.3f}".format(MLP1.score(X_test_scaled,y_test)))这里我们迭代 100次,并且列出了每次迭代后的损失函数,我们发现在一定范围内,迭代的次数增加时,我们模型的准确率在提高。这其实也说明了,全连接神经网络其实要有足够的深度,才能起到比较好的作用。当然,这建立在一定范围的情况下(过拟合就完了)。
 2.3MLP模型搜索最佳参数
2.3MLP模型搜索最佳参数
正规做法:用 GridSearchCV库
#gridsearchcv调参
param_grid = {"hidden_layer_sizes":[[1,100]],
"max_iter":[50,100,200,500,1000],
"activation":["logistic","relu"],
"alpha":[0.0001,0.001],
"solver":["lbfgs","adam"],
"learning_rate":["constant","invscaling","adaptive"]}
grid = GridSearchCV(MLPClassifier(random_state=0),param_grid,cv=5)
grid.fit(X_train_scaled,y_train)
print("最佳参数:{}".format(grid.best_params_))
print("最佳交叉验证分数:{:.3f}".format(grid.best_score_))
print("测试集分数:{:.3f}".format(grid.score(X_test_scaled,y_test))) 当然作者在用这个库之前也写了一个比较笨的的方法。现在看来有点蠢
当然作者在用这个库之前也写了一个比较笨的的方法。现在看来有点蠢
我用了5个for循环遍历,代码如下。大家乱别学这个哈。
iters = [1,5,10,20,50,100,200,500,1000]#迭代次数
activations = ["identity","logistic","tanh","relu"]#激活函数
alphas = [0.0001,0.001,0.01,0.1,1,10]#正则化参数
solvers = ["lbfgs","sgd","adam"]#求解方法
learning_rates = ["constant","invscaling","adaptive"]#学习权重更新的速率
best_score = 0
best_params = {}
for iter in iters:
for activation in activations:
for alpha in alphas:
for solver in solvers:
for learning_rate in learning_rates:
MLP2 = MLPClassifier(hidden_layer_sizes=[1,100], #第i个元素表示第i个隐藏层中神经元的数量。[1,100]表示第一个隐藏层中有100个神经元
activation = activation, ## 隐藏层激活函数
alpha = alpha, ## 正则化L2惩罚的参数
solver = solver, ## 求解方法
learning_rate = learning_rate,## 学习权重更新的速率
max_iter = iter, ## 最大迭代次数
random_state = 10,verbose = False)#verbose:是否将过程打印出来
MLP2.fit(X_train_scaled,y_train)
score = MLP2.score(X_test_scaled,y_test)
if score > best_score:
best_score = score
best_params = {"iter":iter,"activation":activation,"alpha":alpha,"solver":solver,"learning_rate":learning_rate}
print("最佳参数:{}".format(best_params))2.4绘制损失函数随迭代次数的变化图
MLP1 = MLPClassifier(hidden_layer_sizes=[10,100], #第i个元素表示第i个隐藏层中神经元的数量
activation = "relu", ## 隐藏层激活函数
alpha = 0.001, ## 正则化L2惩罚的参数
solver = "adam", ## 求解方法
learning_rate = "adaptive",## 学习权重更新的速率
max_iter = 500, ## 最大迭代次数
tol = 0.0001, ## 迭代停止的误差
random_state = 10,verbose = False)#verbose:是否将过程打印出来
MLP1.fit(X_train_scaled,y_train)
plt.figure(figsize=(10,5))
print(MLP1.loss_curve_)#是一个列表,记录了每次迭代的损失函数值
plt.plot(MLP1.loss_curve_,linewidth=3)#损失函数值随迭代次数的变化
plt.xlabel("迭代次数",fontsize=15)
plt.ylabel("损失函数值",fontsize=15)
plt.title("损失函数值随迭代次数的变化",fontsize=20)
plt.show()
从图中总体来看对于这个数据集,其实迭代到50次效果已经比较好了。损失函数一半都是先迅速下降,然后收敛的(比较理想的结果)。
2.5看每个神经元的权重
为了让大家更好的理解神经网络,我们可以查看每个神经元的权重大小。权重大小一般在【-1,1】。正数则代表输入特征影响是正面的,负值则相反。
## 输入层到隐藏层的权重
mat = MLP1.coefs_[0]
print(mat.shape[1])
## 绘制图像
plt.figure(figsize = (10,10))
sns.heatmap(mat ,annot=True,fmt = "0.3f",annot_kws={"size":12},
cmap="YlGnBu")
## 设置X轴标签
xticks = ["neuron "+str(i+1) for i in range(mat.shape[1])]
plt.xticks(np.arange(mat.shape[1])+0.5,xticks,rotation=45)
## 设置Y轴标签
yticks = ["Feature "+str(i+1) for i in range(mat.shape[0])]
plt.yticks(np.arange(mat.shape[0])+0.5,yticks,rotation=0)
plt.title("MLP输入层到隐藏层的权重")
plt.show()
三、全连接神经网络对波士顿房价数据集做回归
3.1 介绍数据集
波士顿房价数据集是一个经典的机器学习数据集,用于预测波士顿郊区房价的中位数。该数据集包含506个样本,每个样本包含13个房屋特征和一个目标变量(房价中位数)。这些特征包括房屋的犯罪率、住宅用地比例、商业用地比例、是否靠近河流、平均房间数等。
该数据集最初由美国马萨诸塞州波士顿市的几个社区采集,用于研究房价与社区环境的关系。该数据集广泛用于机器学习教学和研究中,是回归问题的经典数据集之一,许多模型都在该数据集上进行了测试和评估。

3.2 读数据 并且绘制任意两个特征之间的散点图观察回归关系
boston = pd.read_csv("boston.csv")
print(boston.head())
X_train,X_test,y_train,y_test=train_test_split(boston.iloc[:,:-1],boston.iloc[:,-1],random_state=0,test_size=0.3)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
其实我们发现有一些特征之间的会馆关系还是挺强的,呈现比较明显的线性关系。这里大家可能有点看不清楚。
3.3查看模型均方误差评估准确度
#数据标准化
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
scaler=StandardScaler()
X_train_scaled=scaler.fit_transform(X_train)
X_test_scaled=scaler.transform(X_test)
MLP_reg2 = MLPRegressor(hidden_layer_sizes=(100,100), #第i个元素表示第i个隐藏层中神经元的数量
activation = "relu", ## 隐藏层激活函数
alpha = 0.001, ## 正则化L2惩罚的参数
solver = "adam", ## 求解方法
learning_rate = "adaptive",## 学习权重更新的速率
max_iter = 2000, ## 最大迭代次数
tol = 0.0001, ## 迭代停止的误差
random_state = 10,verbose = False)#verbose:是否将过程打印出来
MLP_reg2.fit(X_train_scaled,y_train)
print("训练集上的均方误差",mean_squared_error(y_train,MLP_reg2.predict(X_train_scaled)))
print("测试集上的均方误差",mean_squared_error(y_test,MLP_reg2.predict(X_test_scaled)))
总体来说训练集的军方误差比较小,然后测试集在15左右,勉强接受,当然这个值越小越好
3.4绘制损失函数值随迭代次数变化图
plt.figure(figsize=(10,5))
plt.plot(MLP1.loss_curve_,linewidth=3)#损失函数值随迭代次数的变化
plt.xlabel("迭代次数",fontsize=15)
plt.ylabel("损失函数值",fontsize=15)
plt.title("损失函数值随迭代次数的变化",fontsize=20)
plt.show()

这个数据集也是在50次迭代之后趋于收敛。
3.5绘制拟合图
plt.figure(figsize=(10,5))
index = np.arange(len(y_test))
plt.plot(index,y_test,label="真实值",linewidth=3)
plt.plot(index,MLP_reg2.predict(X_test_scaled),label="预测值",linewidth=3)
plt.legend(fontsize=15)
plt.xlabel("样本序号",fontsize=15)
plt.ylabel("房价",fontsize=15)
plt.title("神经网络预测房价",fontsize=20)
plt.show()
总体来说拟合还是较好的。

总结
本文简单介绍了全连接神经网络模型,并且使用乳腺癌数据集和波士顿房价数据集来做了全连接神经网络的分类与回归人物。总的来说这个神经网络的思想还是值得大家去学习的,因为它很像人脑的一个思考过程,通过输入特征到给权重和偏执参数,然后一直迭代下去。作者知识粗略学了一下这方面的知识,如果有哪里写的不好的地方欢迎大家指正。
不知不觉也写了八篇关于机器学习入门的文章了,接下来的国庆作者准备去搭一个卷积神经网络处理图像修复问题,到时候可能可以教大家一下这方面的知识。
谢谢大家的支持,也希望看文章的人能和作者一起进步。
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











