






前言:爬虫是一种按照一定规则,从互联网上自动获取信息的脚本。本篇文章会介绍,如何利用网络爬虫,获取哔哩哔哩网站上的视频。
开发环境:
python:3.8
第三方包:
requests:2.28.2
moviepy:1.0.3
浏览器:Edge 132.0.2957.140 (正式版本) (64 位)
第三方包安装:打开cmd,输入如下命令
pip install requests
pip install moviepy一、获取视频地址
本文以“哔哩哔哩弹幕网”发布的跨年视频为例,在浏览器打开视频页面
按下F12,调出开发者人员工具,
并按下F5刷新,刷新后可捕捉到数据
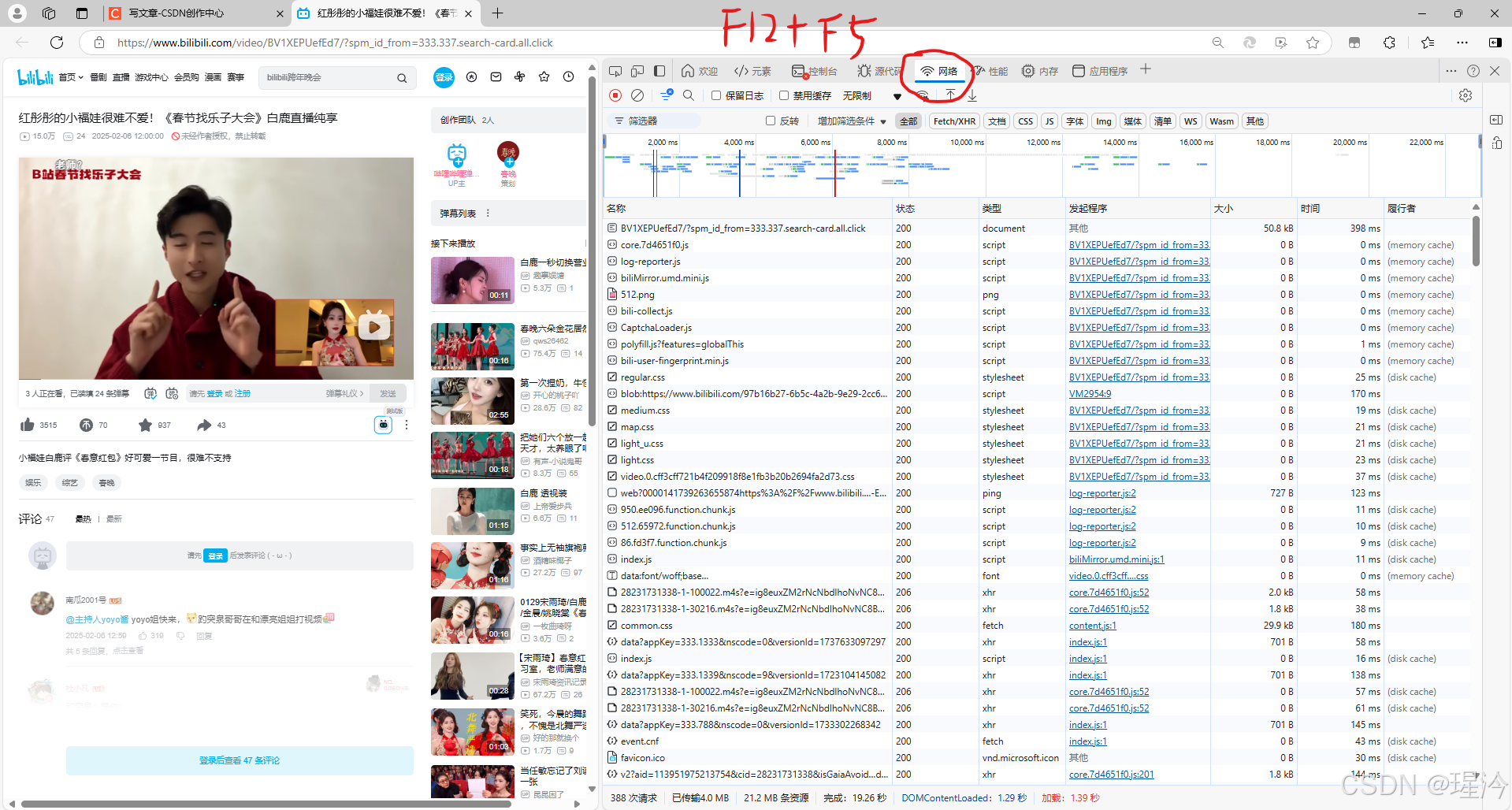
在开发者人员工具中的网络一栏中,可以看到捕捉到的网站数据
在其中可以找到后缀为.m4s的文件,这一般为视频文件。
打开它,并在标头一栏复制请求URL
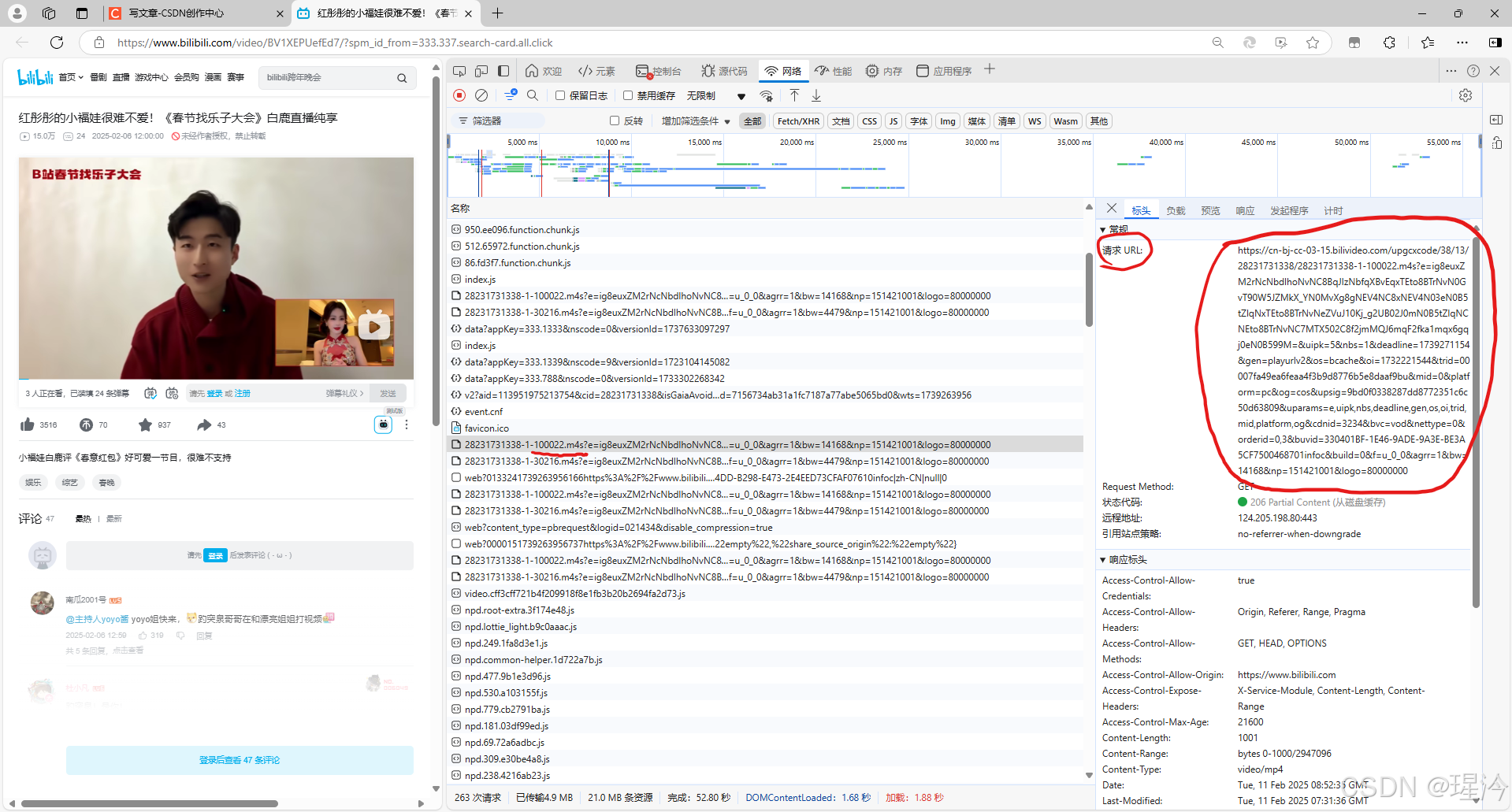
二、请求资源
打开Pycharm,导入requests库
import requests请求视频资源,url变量为刚复制的网址
url=“https://cn-bj-cc-03-15.bilivideo.com/upgcxcode/38/13/28231731338/28231731338-1-100022.m4s?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfqXBvEqxTEto8BTrNvN0GvT90W5JZMkX_YN0MvXg8gNEV4NC8xNEV4N03eN0B5tZlqNxTEto8BTrNvNeZVuJ10Kj_g2UB02J0mN0B5tZlqNCNEto8BTrNvNC7MTX502C8f2jmMQJ6mqF2fka1mqx6gqj0eN0B599M=&uipk=5&nbs=1&deadline=1739271154&gen=playurlv2&os=bcache&oi=1732221544&trid=00007fa49ea6feaa4f3b9d8776b5e8daaf9bu&mid=0&platform=pc&og=cos&upsig=9bd0f0338287dd8772351c6c50d63809&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,mid,platform,og&cdnid=3234&bvc=vod&nettype=0&orderid=0,3&buvid=330401BF-1E46-9ADE-9A3E-BE3A5CF7500468701infoc&build=0&f=u_0_0&agrr=1&bw=14168&np=151421001&logo=80000000”
# 这里的url便是刚才复制下来的请求url
res = requests.get(url) # 请求视频资源
print(res.status_code) # 打印状态码这里的状态码显示若为403,说明请求被服务器拒绝了。这是因为服务器具有反爬机制,所以我们需要让我们的程序看起来更像是一个真实的用户。
回到浏览器,将标头一栏向下滑动,我们会看到在请求标头中,有许多的用户信息。
我们复制user-agent和referer这两项即可。
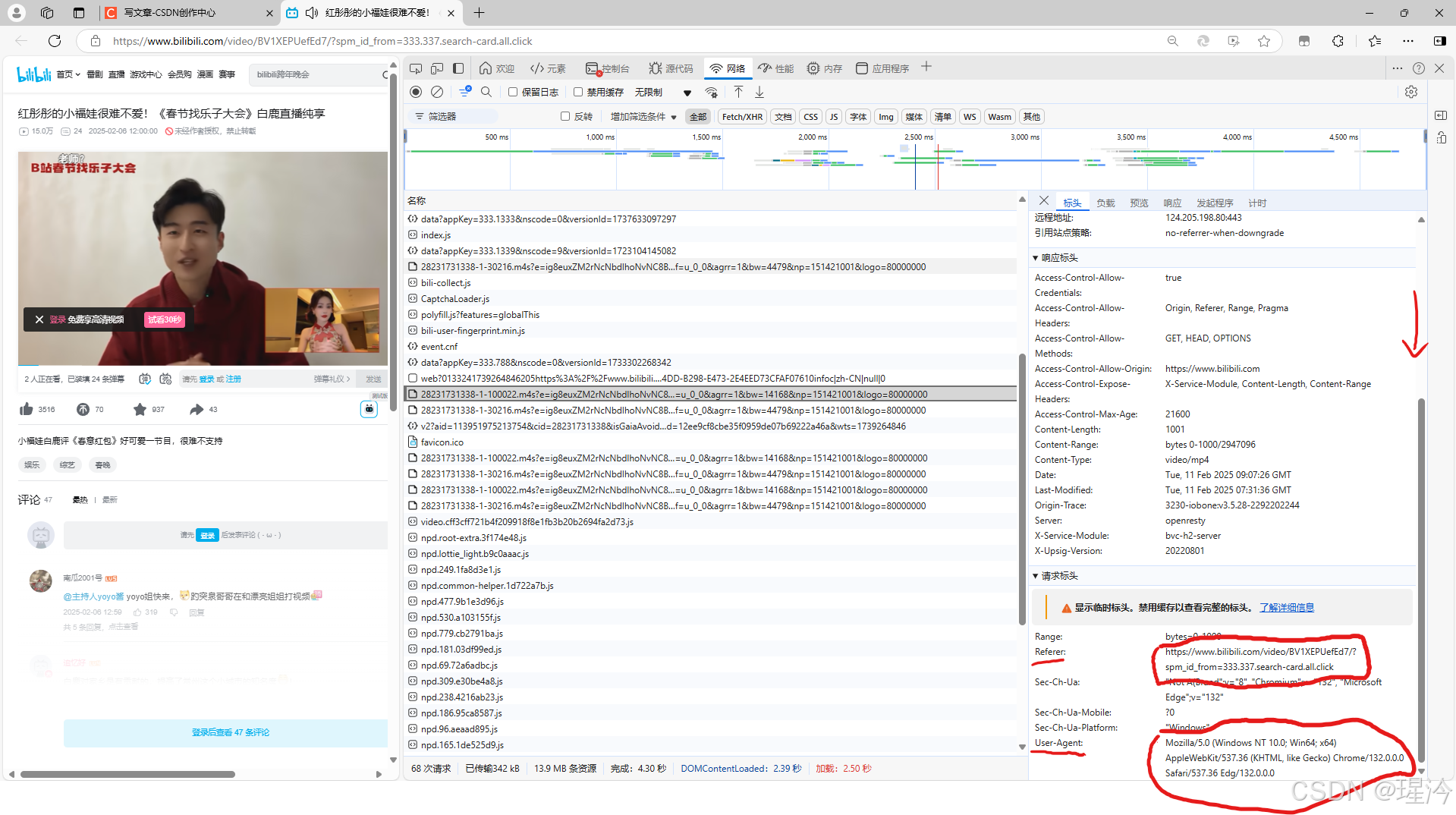
回到Pycharm,创建一个名为headers的字典。将复制的“user-agent”和“referer”以键值对的形式存入字典。
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36 Edg/132.0.0.0",
"referer":"https://www.bilibili.com/video/BV1XEPUefEd7/?spm_id_from=333.337.search-card.all.click"
}在request的请求中,加入请求头headers
url=“https://cn-bj-cc-03-15.bilivideo.com/upgcxcode/38/13/28231731338/28231731338-1-100022.m4s?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfqXBvEqxTEto8BTrNvN0GvT90W5JZMkX_YN0MvXg8gNEV4NC8xNEV4N03eN0B5tZlqNxTEto8BTrNvNeZVuJ10Kj_g2UB02J0mN0B5tZlqNCNEto8BTrNvNC7MTX502C8f2jmMQJ6mqF2fka1mqx6gqj0eN0B599M=&uipk=5&nbs=1&deadline=1739271154&gen=playurlv2&os=bcache&oi=1732221544&trid=00007fa49ea6feaa4f3b9d8776b5e8daaf9bu&mid=0&platform=pc&og=cos&upsig=9bd0f0338287dd8772351c6c50d63809&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,mid,platform,og&cdnid=3234&bvc=vod&nettype=0&orderid=0,3&buvid=330401BF-1E46-9ADE-9A3E-BE3A5CF7500468701infoc&build=0&f=u_0_0&agrr=1&bw=14168&np=151421001&logo=80000000”
# 这里的url便是刚才复制下来的请求url
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36 Edg/132.0.0.0",
"referer":"https://www.bilibili.com/video/BV1XEPUefEd7/?spm_id_from=333.337.search-card.all.click"
} # 请求头
res = requests.get(url,headers=headers) # 请求视频资源
print(res.status_code) # 打印状态码这时再运行程序,就能看到状态码为200,表示允许访问。
三、视频保存
接着我们需要把获取到的数据保存为视频格式。
with open("1.mp4","wb") as f:
f.wirte(res.content)"1.mp4"为视频的名字,“wb”是以二进制的形式写入文件。
不过这时打开视频发现没有声音,这是因为哔哩哔哩中视频文件和音频文件是分开存放的。
让我们回到浏览器,在刚才我们找到的视频文件下方有一个名为30216.m4s的文件,这大概率就是音频文件,复制它的请求URL
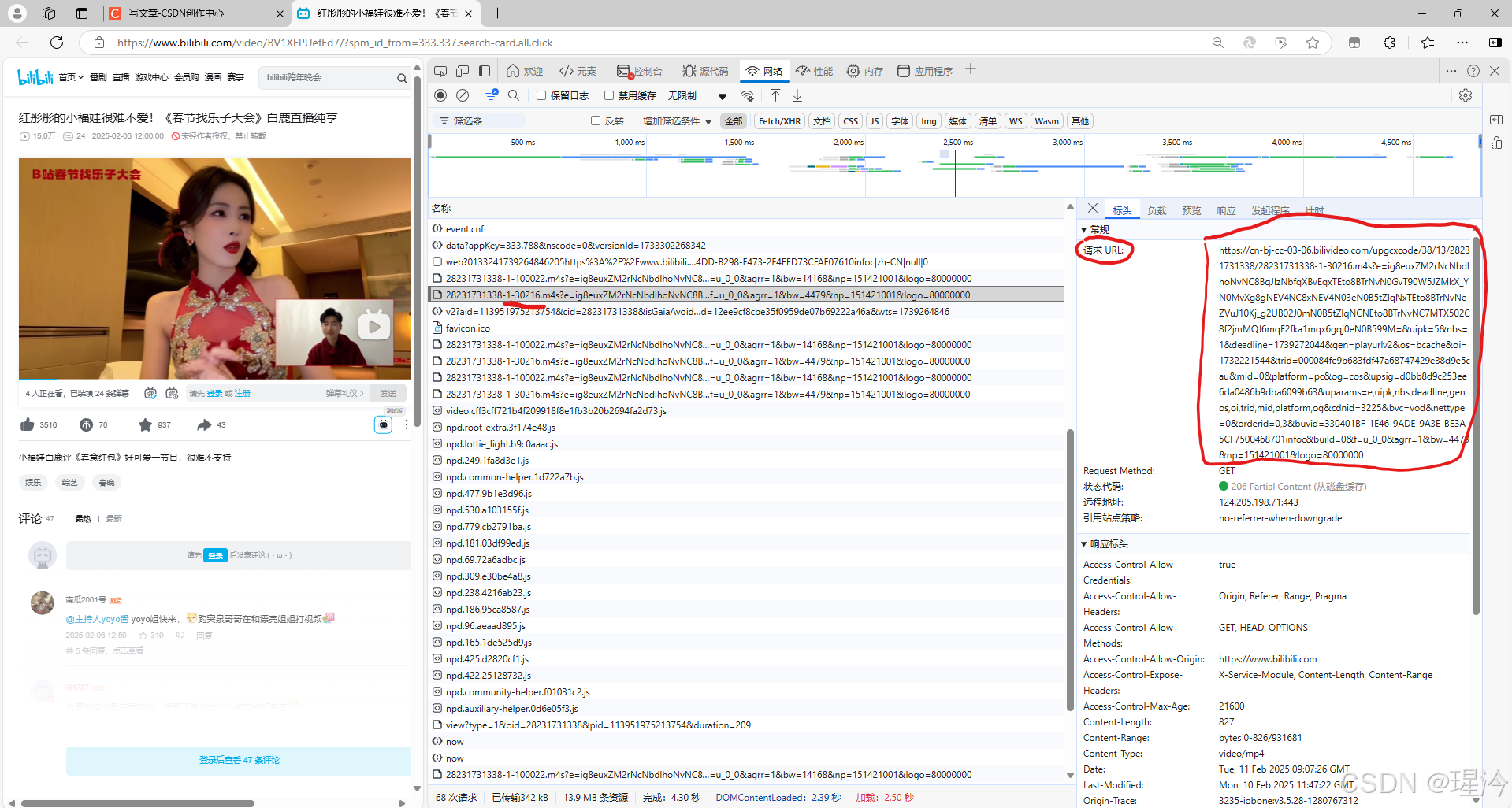
回到Pycharm,与视频请求相同,不过要把最后保存的文件改为mp3格式
import requests
url = "https://cn-bj-cc-03-06.bilivideo.com/upgcxcode/38/13/28231731338/28231731338-1-30216.m4s?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfqXBvEqxTEto8BTrNvN0GvT90W5JZMkX_YN0MvXg8gNEV4NC8xNEV4N03eN0B5tZlqNxTEto8BTrNvNeZVuJ10Kj_g2UB02J0mN0B5tZlqNCNEto8BTrNvNC7MTX502C8f2jmMQJ6mqF2fka1mqx6gqj0eN0B599M=&uipk=5&nbs=1&deadline=1739272044&gen=playurlv2&os=bcache&oi=1732221544&trid=000084fe9b683fdf47a68747429e38d9e5cau&mid=0&platform=pc&og=cos&upsig=d0bb8d9c253ee6da0486b9dba6099b63&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,mid,platform,og&cdnid=3225&bvc=vod&nettype=0&orderid=0,3&buvid=330401BF-1E46-9ADE-9A3E-BE3A5CF7500468701infoc&build=0&f=u_0_0&agrr=1&bw=4479&np=151421001&logo=80000000"
headers = {
"user-agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36 Edg/132.0.0.0",
"referer":
"https://www.bilibili.com/video/BV1XEPUefEd7/?spm_id_from=333.337.search-card.all.click"
} # 音频网址
res = requests.get(url, headers=headers) # 请求音频
print(res.status_code) # 打印状态码
with open("2.mp3","wb") as f:
f.write(res.content) # 保存文件四、插入音频
最后我们需要用到moviepy库,将视频和音频结合起来
导入moviepy
from moviepy.editor import *加载视频文件与音频文件
videoclip = VideoFileClip("1.mp4")
audioclip = AudioFileClip("2.mp3")将音频文件加入视频中
vc = videoclip.set_audio(audioclip)导出最终视频
vc.write_videofile("3.mp4",codec="libx264",audio_codec="aac")在文件夹中打开“3.mp4”,发现视频有声音有画面,这样视频就下载到电脑中了。

五、完整代码
以下是完整代码:
import requests
from moviepy.editor import *
# 视频地址
url_4 = "https://cn-bj-cc-03-15.bilivideo.com/upgcxcode/38/13/28231731338/28231731338-1-100022.m4s?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfqXBvEqxTEto8BTrNvN0GvT90W5JZMkX_YN0MvXg8gNEV4NC8xNEV4N03eN0B5tZlqNxTEto8BTrNvNeZVuJ10Kj_g2UB02J0mN0B5tZlqNCNEto8BTrNvNC7MTX502C8f2jmMQJ6mqF2fka1mqx6gqj0eN0B599M=&uipk=5&nbs=1&deadline=1739272044&gen=playurlv2&os=bcache&oi=1732221544&trid=000084fe9b683fdf47a68747429e38d9e5cau&mid=0&platform=pc&og=cos&upsig=13ad871e2968d42e9273bc1136c99e44&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,mid,platform,og&cdnid=3234&bvc=vod&nettype=0&orderid=0,3&buvid=330401BF-1E46-9ADE-9A3E-BE3A5CF7500468701infoc&build=0&f=u_0_0&agrr=1&bw=14168&np=151421001&logo=80000000"
# 音频网址
url_3 = "https://cn-bj-cc-03-06.bilivideo.com/upgcxcode/38/13/28231731338/28231731338-1-30216.m4s?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfqXBvEqxTEto8BTrNvN0GvT90W5JZMkX_YN0MvXg8gNEV4NC8xNEV4N03eN0B5tZlqNxTEto8BTrNvNeZVuJ10Kj_g2UB02J0mN0B5tZlqNCNEto8BTrNvNC7MTX502C8f2jmMQJ6mqF2fka1mqx6gqj0eN0B599M=&uipk=5&nbs=1&deadline=1739267031&gen=playurlv2&os=bcache&oi=1732221544&trid=00008aeb681ea5a649769a0081dfd0a50de2u&mid=0&platform=pc&og=cos&upsig=3e0231b32aa17c2eddf74b53c071c8c6&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,mid,platform,og&cdnid=3225&bvc=vod&nettype=0&orderid=0,3&buvid=330401BF-1E46-9ADE-9A3E-BE3A5CF7500468701infoc&build=0&f=u_0_0&agrr=1&bw=4479&np=151421001&logo=80000000"
# 请求头
headers = {
"user-agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36 Edg/132.0.0.0",
"referer":
"https://www.bilibili.com/video/BV1XEPUefEd7/?spm_id_from=333.337.search-card.all.click"
}
def get_resource(url, format):
"""
用于爬取资源
:param url: 资源的网址
:param format: 保存的文件名称
:return: None
"""
res = requests.get(url, headers=headers)
print(res.status_code)
with open(format, "wb") as f:
f.write(res.content)
def set_audio(f1, f2,f3):
"""
用于音视频合成
:param f1: 无声视频名称
:param f2: 音频名称
:param f3: 合成后(输出)的视频名称
:return: None
"""
videoclip = VideoFileClip(f1)
audioclip = AudioFileClip(f2)
vc = videoclip.set_audio(audioclip)
vc.write_videofile(f3, codec="libx264", audio_codec="aac")
if __name__ == "__main__":
get_resource(url_4, "1.mp4")
get_resource(url_3, "2.mp3")
set_audio("1.mp4","2.mp3","3.mp4")
















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









