






-分页数据爬取操作
-爬取肯德基餐厅位置数据 url = http://www.kfc.com.cn/kfccda/storelist/index.aspx
-分析:
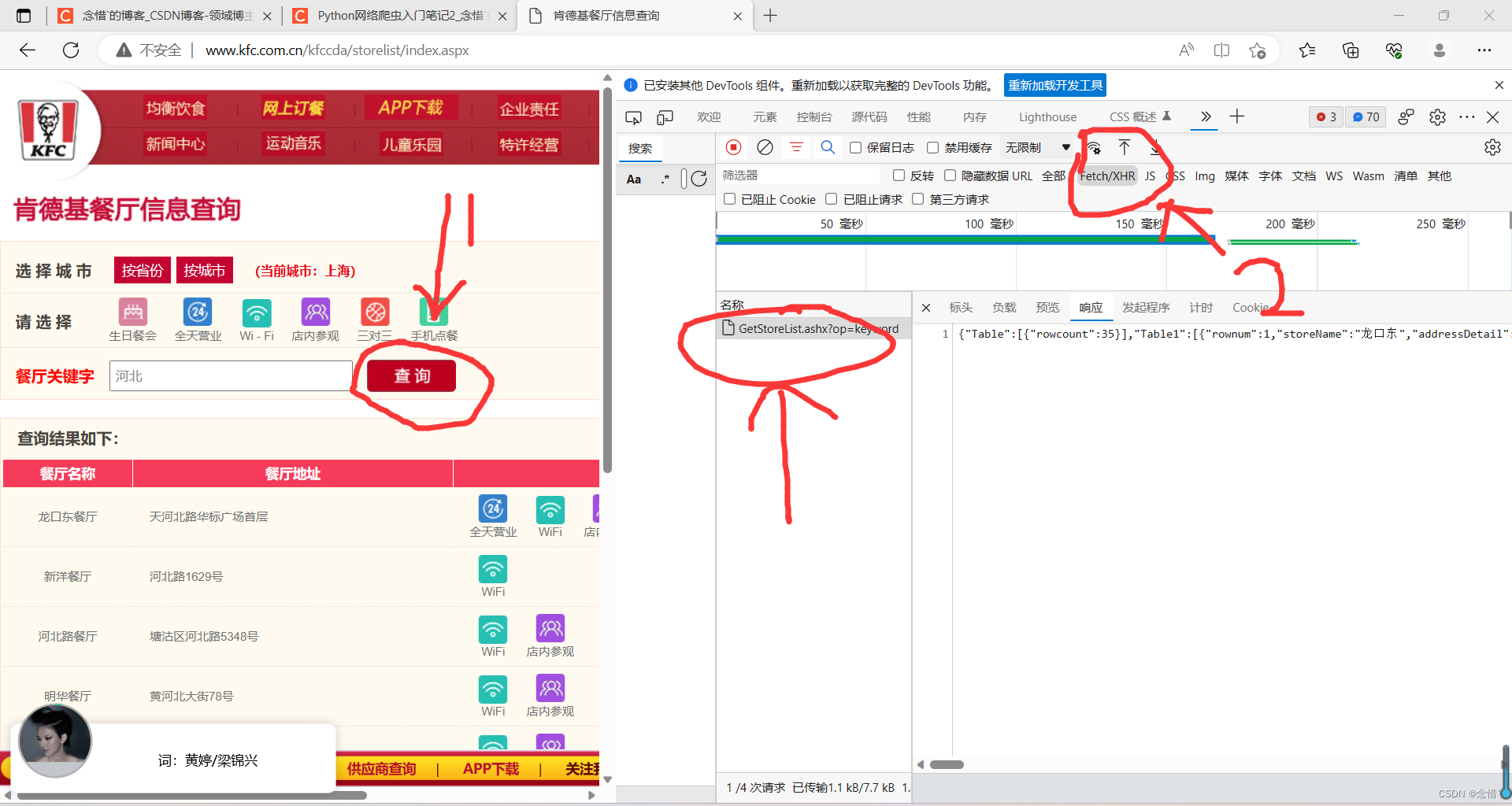
1.在录入关键字的文本框录入关键字按下搜索按钮,发起的是一个ajax请求
-当前页面刷新出的位置信息是通过ajax请求到的数据
2.基于抓包工具定位到该ajax请求的数据包,从该数据包捕获到:
-请求的url
-请求的方式
-请求携带的参数
-看到响应数据
3.All:所有数据包 XHR:基于ajax请求的数据包
import requests
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.57'
}
data = {
'cname':'',
'pid':'',
'keyword':'河北', #省份或市
'pageIndex':'1', #页码
'pageSize':'10' #每页爬取几个
}
# data参数是post处理参数动态化的参数
response = requests.post(url = url,data = data,headers = headers)
page_text = response.json()
for dic in page_text['Table1']:
title = dic['storeName']
addr = dic['addressDetail']
print(title,addr)结果

数据解析
-正则
-bs4
-xpath
-pyquery
正则(练习网站https://regex101.com/,中间下面那个框放字符串,上面那一行写正则表达式) 假设word,a,b,c为字符,多个字符则加上括号
-1.word? word可有可无
-2.ab*c ac中间只能有0个或多个b
-3.ab+c ac中间只能有1个或者多个b
-4.ab{5}c ac中间只能有5个b
-5.ab{2,6}c ac中间只能有2到6个b(包括2和6)
-6.a (cat|dog) 或运算 a cat 或者 a dog 均符合
-7.[a-z]+ 字符类,所有的小写字母
-8.[a-zA-Z]+ 所有的大写英文字母
-9.[a-zA-Z0-9]+ 不能留间隙,留了代表把空格也算在里面了
-10.方括号里字符前面加个^即代表非
-11.元字符 \开头 :\d 数字字符
\w 单词字符(英文字符数字及下划线 )
\s 空白符(包括tab和换行符)
\D 非数字字符
\W 非单词字符
\S 非空白符
\b 表示字符边界
-12. ^a a在行首
a$ a在行尾
-13. <.*> 贪婪匹配,会把整个字符串全部匹配,会将<>包裹的都匹配了
<.*?> 惰性匹配,最近的进行匹配。?会将贪婪匹配转换为惰性匹配
-14. .代表任何字符 普通的.要用\.表示
-使用正则进行图片数据的批量解析爬取
-方式1:基于requests
-方式2:基于urllib
-urllib模块和requests模块一样,都是基于网络请求的模块,只不过requests问世后替代了urllib模块
-上述两种方法不同之处:使用urllib爬取无法进行UA伪装
# 方式1
import requests
img_url = 'https://pic3.zhimg.com/v2-7896f875e8a7224d6b320e0a06ebe1c5_r.jpg?source=1940ef5c'#要爬取图片地址
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.57'
}
response = requests.get(url = img_url,headers = headers )
img_data = response.content #返回二进制响应数据
with open('touxiang.jpg','wb') as fp:
fp.write(img_data)结果
#方式2
import urllib
img_url = 'https://pic3.zhimg.com/v2-7896f875e8a7224d6b320e0a06ebe1c5_r.jpg?source=1940ef5c'#要爬取图片地址
# 可以直接对url发起请求并进行持久化存储
urllib.request.urlretrieve(img_url,'touxiang2.jpg')结果

实战,爬取堆糖甜妹图片
-需求: 爬取堆糖图片数据
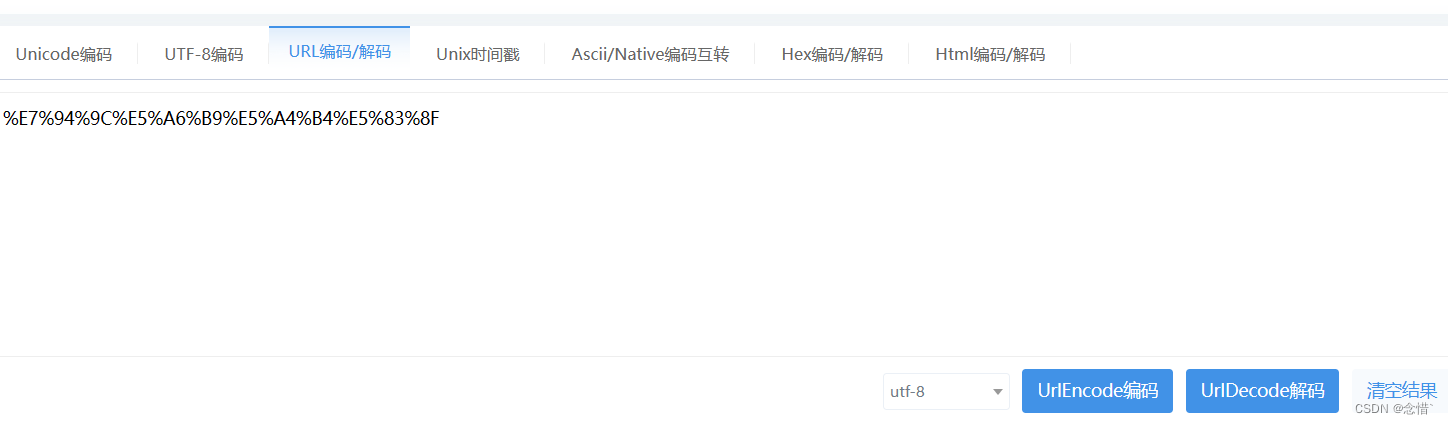
url: https://www.duitang.com/search/?kw=%E7%94%9C%E5%A6%B9%E5%A4%B4%E5%83%8F&type=feed&from=tuijian
-操作: 将每一张图片地址解析出来,然后对图片地址发起请求
-分析浏览器开发者工具中网络和元素这两个选项卡对应的页面数据有何不同之处
元素(Elements)中包含的显示的页面源码数据为当前页面所有的数据加载完毕后对应的完整页面源码数据(包含了动态加载数据)
网络(Network)中显示的页面源码数据仅仅为某一个单独请求对应的响应数据(不包含动态加载数据
结论:在进行数据解析时一定需要对页面布局进行分析,如果当前网站没有动态加载的数据直接使用Element元素对页面布局进行分析,否则只可使用network对 页面数据进行分析import urllib import re import os #新建文件夹 dirName = 'girls' if not os.path.exists(dirName): os.mkdir(dirName) #1.捕获当前页面源码数据 url = 'https://www.duitang.com/search/?kw=%E7%94%9C%E5%A6%B9%E5%A4%B4%E5%83%8F&type=feed&from=tuijian' headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.57' } page_text = requests.get(url = url,headers = headers).text #2.从当前获取图片源码数据中解析到地址,实在不会正则,gpt问的,呜呜 ex = r'https?://[^"]+\.(?:jpg|jpeg|png|gif)' # 验证URL是否是有效的图片URL img_src_list = re.findall(ex,page_text,re.S)#必加re.S处理换行 for src in img_src_list: img_path = dirName + '/' + src.split('/')[-1] urllib.request.urlretrieve(src,img_path) print(f'{img_path}下载成功')


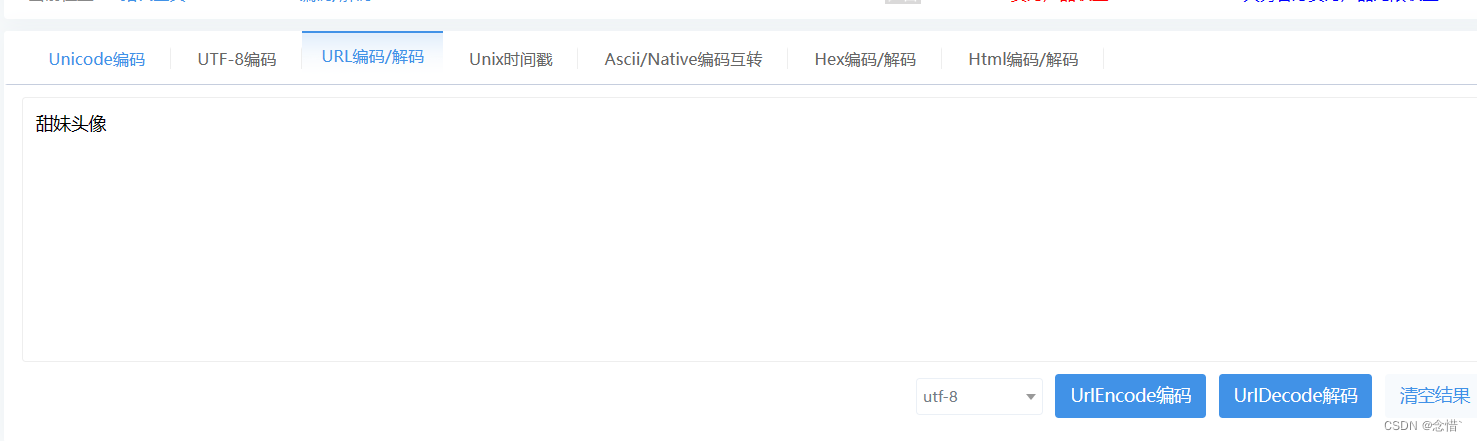
可以使用url编码器将中文转换为代码中url kw对应内容
同理,也可以爬取小狗狗表情包

















 1276
1276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











