






 本文详细介绍了如何在SPSS中对数据进行加权处理,以解决因样本数量不均衡导致的分析偏误问题。步骤包括设置加权变量,如选择“人数”作为权重,以及使用“个案加权”功能。此外,还推荐了针对不同学习阶段的SPSS相关书籍,包括从基础操作到高级应用和实证研究的教程。
本文详细介绍了如何在SPSS中对数据进行加权处理,以解决因样本数量不均衡导致的分析偏误问题。步骤包括设置加权变量,如选择“人数”作为权重,以及使用“个案加权”功能。此外,还推荐了针对不同学习阶段的SPSS相关书籍,包括从基础操作到高级应用和实证研究的教程。
对数据进行加权处理是我们使用SPSS提供某些分析方法的重要前提。对数据进行加权后,当前的权重将被保存在数据中。当进行相应的分析时,用户无须再次进行加权操作。本节以对广告的效果观测为例,讲解数据的加权操作。本例给出了消费者购买行为与是否看过广告之间的联系,按“是否看过广告”和“是否购买商品”两个标准,消费者被分为4类,研究者对这4类消费者分别进行了调查。由于各种情况下调查的人数不同,如果将4种情况等同进行分析,势必由于各种情况的观测数目不同导致分析的偏误,因此我们需要对观测量进行加权。加权前的数据文件如图4.92所示。
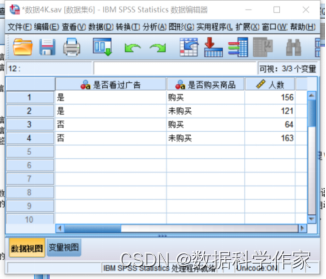
加权操作的具体步骤如下。
在菜单栏中选择“数据”→“个案加权”命令,打开如图4.93所示的“个案加权”对话框。
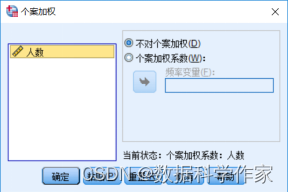
不对个案加权:表示对当前数据集不进行加权,该项一般用于对已经加权的数据集取消加权。
个案加权系数:表示对当前数据集进行加权,同时激活“频率变量”列表框。
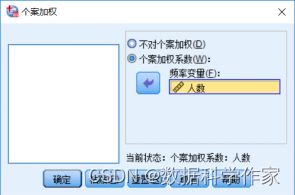
选择加权变量。加权变量用于定制权重,从变量列表框中选择作为加权变量的变量,单击按钮将其选入“频率变量”列表框,如图4.94所示,本例选择“人数”变量作为加权频率变量。
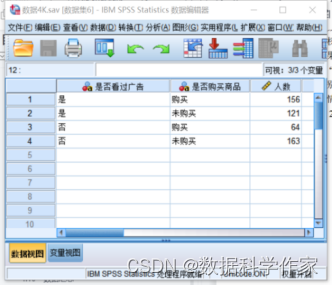
单击“确定”按钮,即可进行加权操作。加权后数据编辑器窗口右下角的状态栏右侧会显示“权重开户”信息,表示数据已经加权,如图4.95所示。
这儿我谈谈SPSS学习的分析。针对没有统计学基础的新手和小白,SPSS入门方面,建议一定边看书边操作,通过边学知识边上手操作的方式学习,会事半功倍,也有解决问题的成就感。推荐三本避雷避坑、亲测可行的网红图书,也是杨维忠、张甜老师撰写的SPSS三部曲:
1、《SPSS统计分析入门与应用精解(视频教学版)》杨维忠 张甜 清华大学出版社 2022年。侧重SPSS统计分析操作,体现在对于窗口选项设置和运行结果解读都非常全面、细致、到位;
2、《SPSS统计学基础与实证研究应用精解》张甜 杨维忠 清华大学出版社 2023年。为使用SPSS写作实证研究类论文所精心设计,实现零基础入门学会用SPSS写论文的目的。
3、《SPSS统计分析商用建模与综合案例精解》杨维忠 张甜 清华大学出版社 2021年。侧重使用SPSS开展数据挖掘、机器学习以及统计分析的综合应用。
《SPSS统计分析入门与应用精解(视频教学版)》杨维忠 张甜 编著 清华大学出版社。这是一本精解SPSS统计分析基础入门与应用的教材,山东大学陈强教授作序推荐,通过“精解统计分析原理、精解SPSS窗口选项设置、精解SPSS输出结果”三要素,帮助读者真正掌握常用统计分析软件SPSS的应用。适用于经济金融、管理、市场营销、教育学、心理学、医学等各类专业。
全书共14章。第1章为SPSS基础与应用操作概述;第2~7章介绍SPSS的基本统计分析方法,包括描述统计分析方法、比较平均值分析方法、非参数检验方法、相关分析方法、一般线性模型、各类常用回归分析方法等;第8~13章介绍SPSS的常用高级统计分析方法,包括时间序列预测方法、聚类分析方法、决策树分析与判别分析方法、生存分析方法、降维分析方法等;第14章为如何使用SPSS进行高质量综合性研究。每章有教学重点提示,章后有“知识点总结与练习题”,帮助读者增强学习效果,形成了“从基础原理到操作精解,从数据分析到案例应用”的完整教学闭环。与本书配套的还有教学PPT和作者新讲解的全套视频资料以辅助教学,力求实现最佳教学效果。
本书可作为经济学、管理学、统计学、金融学、社会学、医学、电子商务等相关专业的在校本、专科大学生及研究生学习、应用SPSS的主要教材,还可作为职场人士掌握SPSS应用、提升数据分析能力,进而提升工作效率、改善绩效水平的工具书。

如果是写论文使用SPSS,则推荐《SPSS统计学基础与实证研究应用精解》张甜 杨维忠著 清华大学出版社

《SPSS统计学基础与实证研究应用精解》张甜 杨维忠著 清华大学出版社
本书手把手教会使用SPSS撰写实证研究类论文或开展数据分析
常用统计学原理、实证研究的套路、调查问卷设计、信度分析、效度分析、T检验、ANOVA分析、相关性分析、回归分析、中介效应、调节效应、因子分析、聚类分析……一应俱全。

如果是使用SPSS开展数据挖掘、机器学习以及统计分析的综合应用,推荐《SPSS统计分析商用建模与综合案例精解》杨维忠 张甜编著 清华大学出版社 2021年 。国内众多高校作为核心专业课程教材。在51CTO举办的“2021年度最受读者喜爱的IT图书作者评选”中,《SPSS统计分析商用建模与综合案例精解》荣获“数据科学领域最受读者喜爱的图书TOP5”。



京东、当当、淘宝各大平台均在热销中,搜索书名即可。
创作不易,恳请大家多多点赞支持!也欢迎大家关注我,让我们一起学习Stata、SPSS、Python知识。多谢!


















 1198
1198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











