









前言
嗨喽,大家好呀~这里是爱看美女的茜茜呐
又到了学Python时刻~

在我们学习的时候,通常会产生疑问:这个行业前景好不好呢?
今天我们就用python的数据分析这个就业方向来举例
看一下都有哪些因素影响了薪资的高低呢?
数据采集
模块使用:
requests 第三方模块
pyecharts 可视化模块
pandas 操作表格
开发环境:
版 本: python3.8
编辑器: pycharm
思路分析
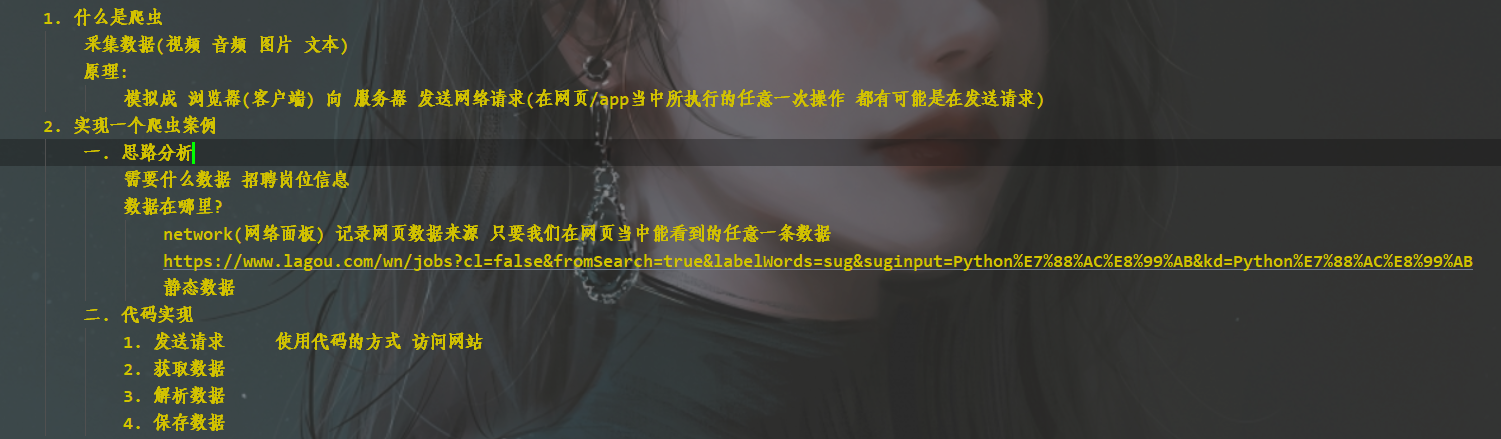
代码展示
导入模块
import requests # 第三方模块 发送请求
import re # 内置模块
import json # 内置模块
import csv
f = open('lagou.csv', mode='a', newline='', encoding='utf-8')
csv_writer = csv.writer(f)
csv_writer.writerow(['positionName', 'companyFullName', 'companySize', 'financeStage', 'city', 'district', 'salary', 'salaryMonth', 'workYear', 'jobNature', 'education'])
伪装 像正常的用户
( 因不可抗原因,不能出现网址,会发不出去,用图片代替了,大家照着敲一下
或者点击此处跳转跳转文末名片加入裙聊,找管理员小姐姐领取呀~ )

for page in range(1, 31):
print(f'###正在爬取第{page}页###')

- 发送请求
response = requests.get(url=url, headers=headers)
- 获取数据
html_data = response.text
- 解析数据 提取数据
# 结构化数据: json数据 ==> {}所包裹的数据 非常好提取
# 非结构化数据: 网页源代码 方式方法: css/xpath/re 模块/工具: bs4/lxml/parsel/re
# re: 搜索功能 高级用法
# .*?: 匹配任意字符
# <script id="__NEXT_DATA__" type="application/json">(.*?)</script>
json_str = re.findall('<script id="__NEXT_DATA__" type="application/json">(.*?)</script>', html_data)[0]
json_dict = json.loads(json_str)
result = json_dict['props']['pageProps']['initData']['content']['positionResult']['result']
# result: 15个岗位信息
for res in result:
positionName = res['positionName']
companyFullName = res['companyFullName']
companySize = res['companySize']
financeStage = res['financeStage']
city = res['city']
district = res['district']
salary = res['salary']
salaryMonth = res['salaryMonth']
workYear = res['workYear']
jobNature = res['jobNature']
education = res['education']
print(positionName, companyFullName, companySize, financeStage, city, district, salary, salaryMonth, workYear, jobNature, education)
- 保存数据
csv_writer.writerow([positionName, companyFullName, companySize, financeStage, city, district, salary, salaryMonth, workYear, jobNature, education])
PS:完整源码或数据集如有需要的小伙伴可以加下方的群去找管理员免费领取

数据分析
一、数据集
首先我们来上面采集的数据集:拉gou网的数据分析岗位数据


二、分析方向
1.数据分析岗位的薪资状况?
2.各城市对数据分析岗位的需求情况?
3.岗位的学历要求高吗?
4.公司都要求什么掌握什么技能?
三、代码展示
导包和数据
import pandas as pd
import numpy as np
import seaborn as sns
from pyecharts.charts import Pie
from pyecharts import options as opts
import matplotlib.pyplot as plt
%matplotlib inline
sns.set_style('white',{'font.sans-serif':['simhei','Arial']})
pd.set_option("display.max_column", None)
pd.set_option("display.max_row",None)
读取数据
df = pd.read_csv('lagouw.csv')
df.head()
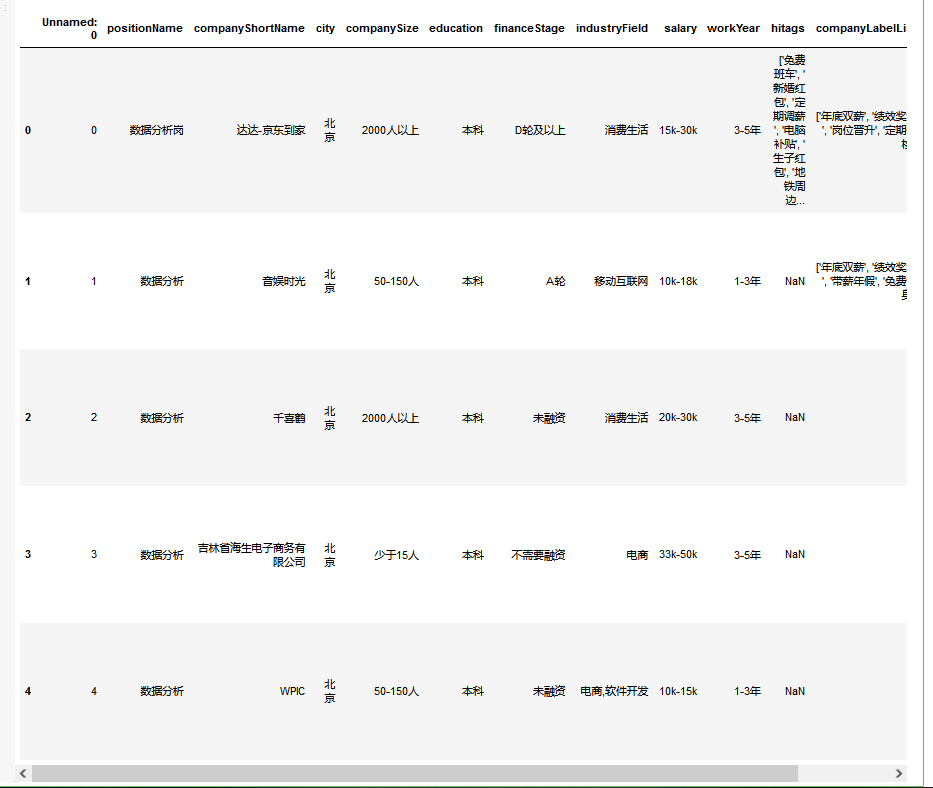

取出我们进行后续分析所需的字段
columns = ["positionName", "companyShortName", "city", "companySize", "education", "financeStage",
"industryField", "salary", "workYear", "hitags", "companyLabelList", "job_detail"]
df[columns].drop_duplicates() #去重
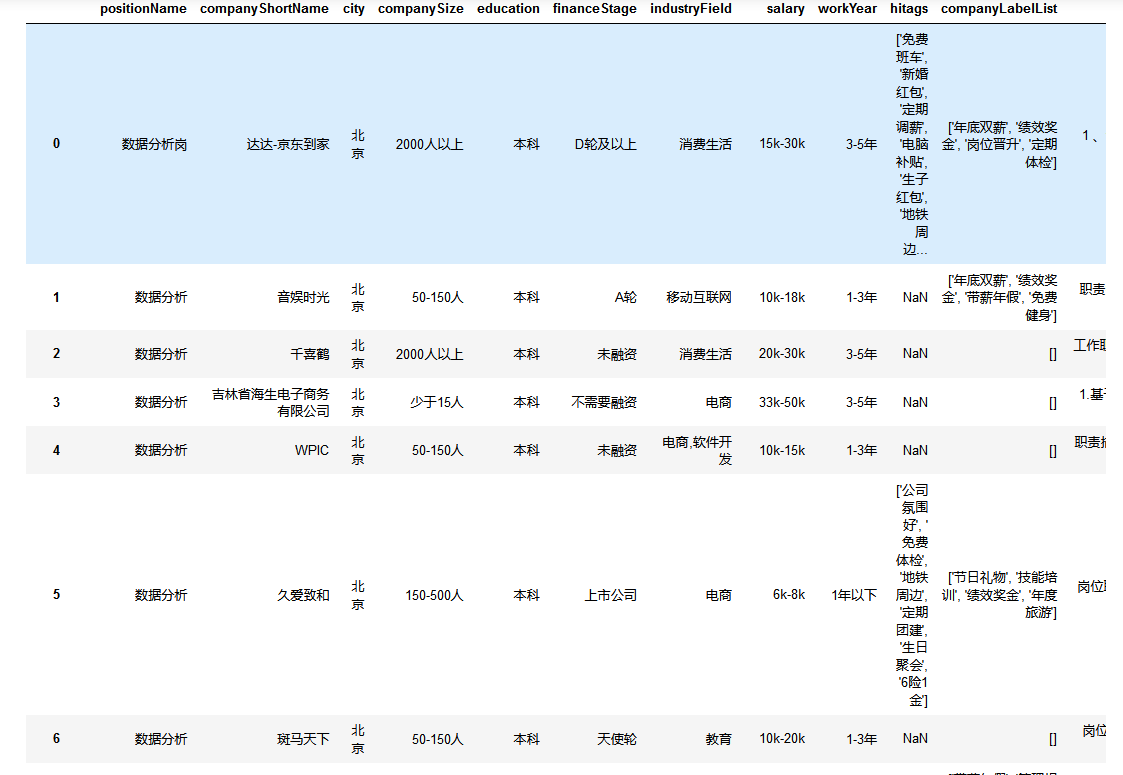
数据清洗
去掉非数据分析岗的数据

筛选出我们想要的字段,并剔除positionName
df = df[cond_1 & cond_2]
df.drop(["positionName"], axis=1, inplace=True)
df.reset_index(drop=True, inplace=True)
df.head()
将拉勾网的薪水转化为数值
拉勾网爬取下来的薪水是一个区间,这里用薪水区间的均值作为相应职位的薪水
处理过程
1、将salary中的字符串均小写化(因为存在8k-16k和8K-16K)
2、运用正则表达式提取出薪资区间
3、将提取出来的数字转化为int型
4、取区间的平均值
df["salary"] = df["salary"].str.lower()\
.str.extract(r'(\d+)[k]-(\d+)k')\
.applymap(lambda x:int(x))\
.mean(axis=1)
从job_detail中提取出技能要求
将技能分为以下几类:
-
Python/R
-
SQL
-
Tableau
-
Excel
处理方式: 如果job_detail中含有上述四类,则赋值为1,不含有则为0
df["job_detail"] = df["job_detail"].str.lower().fillna("") #将字符串小写化,并将缺失值赋值为空字符串
df["Python/R"] = df["job_detail"].map(lambda x:1 if ('python' in x) or ('r' in x) else 0)
df["SQL"] = df["job_detail"].map(lambda x:1 if ('sql' in x) or ('hive' in x) else 0)
df["Tableau"] = df["job_detail"].map(lambda x:1 if 'tableau' in x else 0)
df["Excel"] = df["job_detail"].map(lambda x:1 if 'excel' in x else 0)
df.head(1)
处理行业信息
def clean_industry(industry):
industry = industry.split(",")
if industry[0]=="移动互联网" and len(industry)>1:
return industry[1]
else:
return industry[0]
df["industryField"] = df.industryField.map(clean_industry)
数据可视化
各城市对数据分析岗位的需求量
fig, ax = plt.subplots(figsize=(12,8))
sns.countplot(y="city",order= df["city"].value_counts().index,data=df,color='#3c7f99')
plt.box(False)
fig.text(x=0.04, y=0.90, s=' 各城市数据分析岗位的需求量 ',
fontsize=32, weight='bold', color='white', backgroundcolor='#c5b783')
plt.tick_params(axis='both', which='major', labelsize=16)
ax.xaxis.grid(which='both', linewidth=0.5, color='#3c7f99')
plt.xlabel('')
plt.ylabel('')
plt.show()

不同细分领域对数据分析岗的需求量
industry_index = df["industryField"].value_counts()[:10].index
industry =df.loc[df["industryField"].isin(industry_index),"industryField"]
fig, ax = plt.subplots(figsize=(12,8))
sns.countplot(y=industry.values,order = industry_index,color='#3c7f99')
plt.box(False)
fig.text(x=0, y=0.90, s=' 细分领域数据分析岗位的需求量(取前十) ',
fontsize=32, weight='bold', color='white', backgroundcolor='#c5b783')
plt.tick_params(axis='both', which='major', labelsize=16)
ax.xaxis.grid(which='both', linewidth=0.5, color='#3c7f99')
plt.xlabel('')
plt.ylabel('')

各城市相应岗位的薪资状况
fig,ax = plt.subplots(figsize=(12,8))
city_order = df.groupby("city")["salary"].mean()\
.sort_values()\
.index.tolist()
sns.barplot(x="city", y="salary", order=city_order, data=df, ci=95,palette="RdBu_r")
fig.text(x=0.04, y=0.90, s=' 各城市的薪资水平对比 ',
fontsize=32, weight='bold', color='white', backgroundcolor='#3c7f99')
plt.tick_params(axis="both",labelsize=16,)
ax.yaxis.grid(which='both', linewidth=0.5, color='black')
ax.set_yticklabels([" ","5k","10k","15k","20k"])
plt.box(False)
plt.xlabel('')
plt.ylabel('')

fig,ax = plt.subplots(figsize=(12,8))
fig.text(x=0.04, y=0.90, s=' 一线城市的薪资分布对比 ',
fontsize=32, weight='bold', color='white', backgroundcolor='#c5b783')
sns.kdeplot(df[df["city"]=='北京']["salary"],shade=True,label="北京")
sns.kdeplot(df[df["city"]=='上海']["salary"],shade=True,label="上海")
sns.kdeplot(df[df["city"]=='广州']["salary"],shade=True,label="广州")
sns.kdeplot(df[df["city"]=='深圳']["salary"],shade=True,label="深圳")
plt.tick_params(axis='both', which='major', labelsize=16)
plt.box(False)
plt.xticks(np.arange(0,61,10), [str(i)+"k" for i in range(0,61,10)])
plt.yticks([])
plt.legend(fontsize = 'xx-large',fancybox=None)
plt.show()

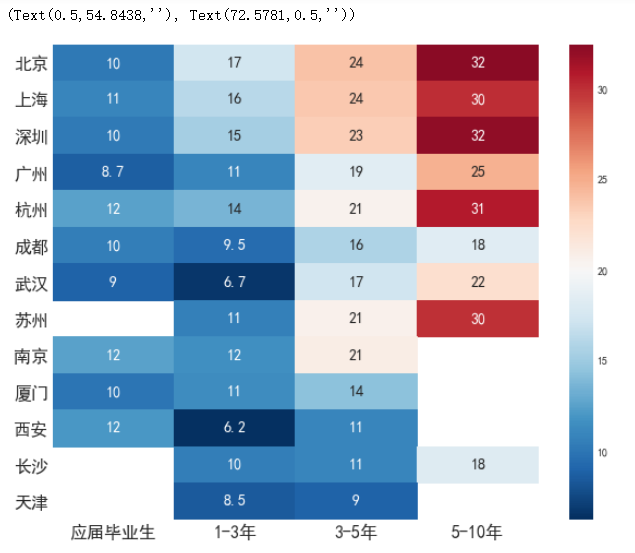
工作经验与薪水的关系
corr = df.pivot_table(index="city",columns="workYear",values="salary")
df.head()
corr = corr[["应届毕业生","1-3年","3-5年","5-10年"]]
corr.loc[city_order]

fig,ax = plt.subplots(figsize=(10,8))
sns.heatmap(corr.loc[df["city"].value_counts().index],cmap="RdBu_r",center=20,annot=True,annot_kws={'fontsize':14})
plt.tick_params(axis='x', which='major', labelsize=16)
plt.tick_params(axis='y', which='major', labelsize=16,labelrotation=0)
plt.xlabel(""),plt.ylabel("")
技能要求
py_rate = df["Python/R"].value_counts(normalize=True).loc[1]
sql_rate = df["SQL"].value_counts(normalize=True).loc[1]
tableau_rate = df["Tableau"].value_counts(normalize=True).loc[1]
excel_rate = df["Excel"].value_counts(normalize=True).loc[1]
print("职位技能需求:")
print("Python/R:",py_rate)
print("SQL:",sql_rate)
print("Excel:",excel_rate)
print("Tableau:",tableau_rate)
职位技能需求:
Python/R: 0.6078431372549019
SQL: 0.6070889894419306
Excel: 0.3310708898944193
Tableau: 0.09502262443438914
def get_level(x):
if x["Python/R"] == 1:
x["skill"] = "Python/R"
elif x["SQL"] == 1:
x["skill"] = "SQL"
elif x["Excel"] == 1:
x["skill"] = "Excel"
else:
x["skill"] = "其他"
return x
df = df.apply(get_level,axis=1)
fig,ax = plt.subplots(figsize=(12,8))
fig.text(x=0.02, y=0.90, s=' 不同技能的薪资水平对比 ',
fontsize=32, weight='bold', color='white', backgroundcolor='#c5b783')
sns.boxplot(y="skill",x="salary",data=df.loc[df.skill!="其他"],palette="husl",order=["Python/R","SQL","Excel"])
plt.tick_params(axis="both",labelsize=16)
ax.xaxis.grid(which='both', linewidth=0.75)
plt.xticks(np.arange(0,61,10), [str(i)+"k" for i in range(0,61,10)])
plt.box(False)
plt.xlabel('工资', fontsize=18)
plt.ylabel('技能', fontsize=18)

学历要求
education = df["education"].value_counts(normalize=True)
from pyecharts.commons.utils import JsCode
def new_label_opts():
return opts.LabelOpts(formatter=JsCode("educatio"))
pie = (
Pie()
.add(
"",
[list(z) for z in zip(education.index, np.round(education.values,4))],
center=["50%", "50%"],
radius=["50%","75%"],
label_opts=new_label_opts()
)
.set_global_opts(
title_opts=opts.TitleOpts(title=""),
legend_opts=opts.LegendOpts(
is_show=False
)
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%")))
pie.render_notebook()

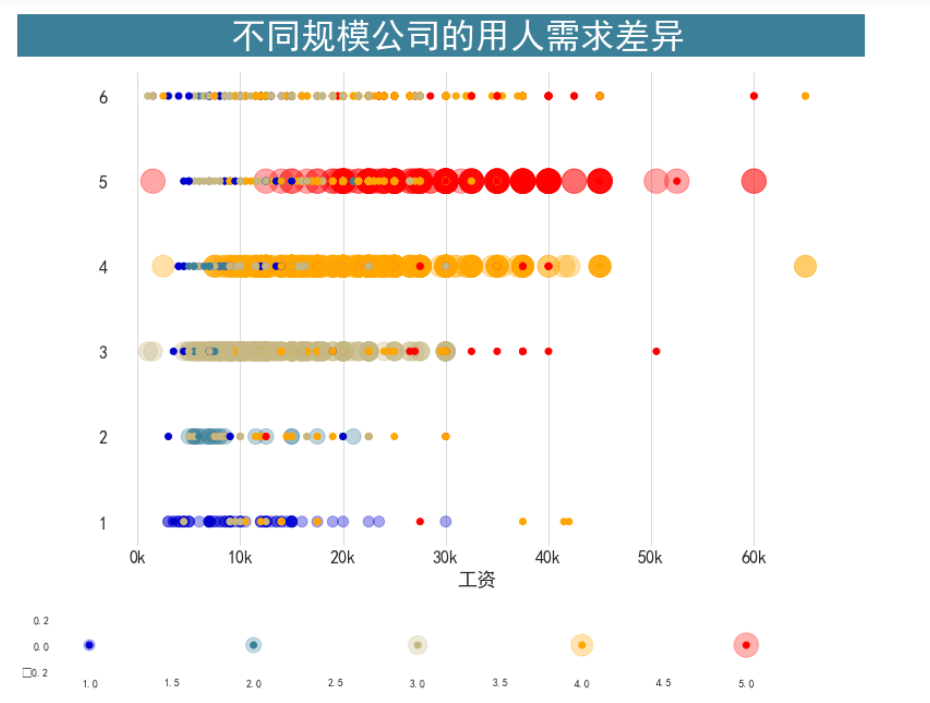
不同规模的公司在招人要求上的差异
company_size_map = {
"2000人以上": 6,
"500-2000人": 5,
"150-500人": 4,
"50-150人": 3,
"15-50人": 2,
"少于15人": 1
}
workYear_map = {
"5-10年": 5,
"3-5年": 4,
"1-3年": 3,
"1年以下": 2,
"应届毕业生": 1
}
df["companySize"] = df["companySize"].map(company_size_map)
df["workYear"] = df["workYear"].map(workYear_map)
df.head()
df = df.sort_values(by="companySize",ascending=True)
df_plot = df.loc[~df.workYear.isna()]
color_map = {
5:"#ff0000",
4:"#ffa500",
3:"#c5b783",
2:"#3c7f99",
1:"#0000cd"
}
df_plot["color"] = df_plot.workYear.map(color_map)
df_plot.reset_index(drop=True,inplace=True)
def seed_scale_plot():
seeds=np.arange(5)+1
y=np.zeros(len(seeds),dtype=int)
s=seeds*100
colors=['#ff0000', '#ffa500', '#c5b783', '#3c7f99', '#0000cd'][::-1]
fig,ax=plt.subplots(figsize=(12,1))
plt.scatter(seeds,y,s=s,c=colors,alpha=0.3)
plt.scatter(seeds,y,c=colors)
plt.box(False)
plt.grid(False)
plt.xticks(ticks=seeds,labels=list(workYear_map.keys())[::-1],fontsize=14)
plt.yticks(np.arange(1),labels=[' 经验:'],fontsize=16)
fig, ax = plt.subplots(figsize=(12, 8))
fig.text(x=0.03, y=0.92, s=' 不同规模公司的用人需求差异 ', fontsize=32,
weight='bold', color='white', backgroundcolor='#3c7f99')
plt.scatter(df_plot.salary, df_plot["workYear"], s=df_plot["workYear"]*100 ,alpha=0.35,c=df_plot["color"])
plt.scatter(df_plot.salary, df_plot["companySize"], c=df_plot["color"].values.tolist())
plt.tick_params(axis='both', which='both', length=0)
plt.tick_params(axis='both', which='major', labelsize=16)
ax.xaxis.grid(which='both', linewidth=0.75)
plt.xticks(np.arange(0,61,10), [str(i)+"k" for i in range(0,61,10)])
plt.xlabel('工资', fontsize=18)
plt.box(False)
seed_scale_plot()
尾语
感谢你观看我的文章呐~本次航班到这里就结束啦 🛬
希望本篇文章有对你带来帮助 🎉,有学习到一点知识~
躲起来的星星🍥也在努力发光,你也要努力加油(让我们一起努力叭)。
















 8737
8737











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









