






- 机器学习是人工智能的核心,目前的机器学习主要分为两大类:第一类是传统机器学习的研究,该类研究主要是研究学习机制,注重探索模拟人的学习机制;第二类是大数据环境下机器学习的研究,该类研究主要是研究如何有效利用信息,注重从巨量数据中获取隐藏的、有效的、可理解的知识。 [2]
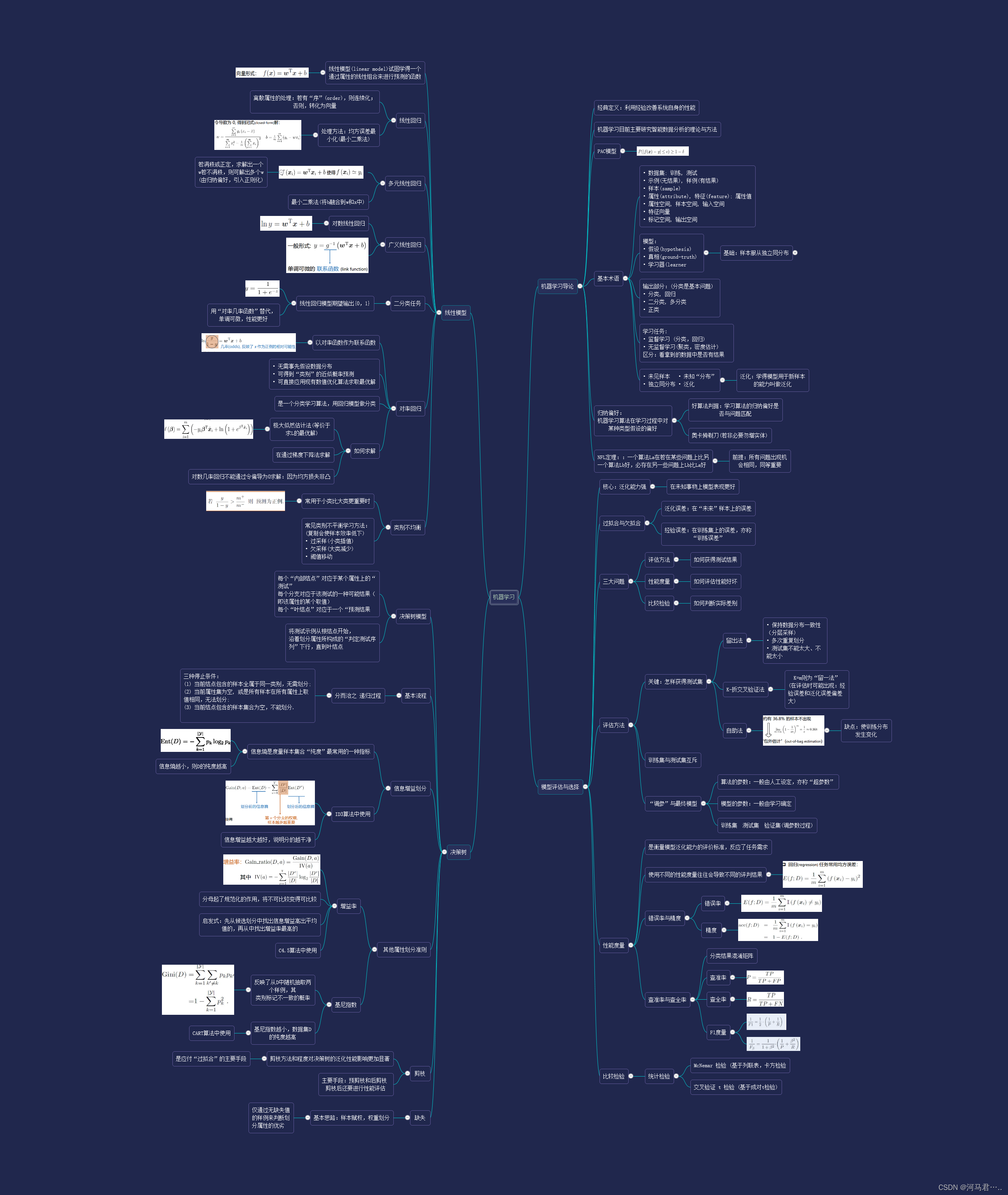
- 决策树:一个预测模型;监督学习:它是一种监督学习,所谓监督学习就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,那么通过学习得到一个分类器,这个分类器能够对新出现的对象给出正确的分类。这样的机器学习就被称之为监督学习。 剪枝是决策树停止分支的方法之一,剪枝有分预先剪枝和后剪枝两种。应付过拟合。
测试属性的标准:信息增益(越大分的越干净),增益率(先找增益高的,再找增益率高的),基尼指数(越小纯度越高)
3. 随机森林
随机森林指的是利用多棵树对样本进行训练并预测的一种分类器。
输出的类别是由个别树输出的类别的众数而定
待选特征的选取:三个臭皮匠顶一个诸葛亮
决策树的的待选特征是选择其中最优的一个待选特征,随机森林是从待选特征中随机选取几个,每颗树都不同,最终由投票规则确定结果
4. 人工神经网络
神经网络是一种运算模型,由大量的节点(或称神经元)之间相互联接构成。每个节点代表一种特定的输出函数,称为激励函数(activation function)。每两个节点间的连接都代表一个对于通过该连接信号的加权值,称之为权重,这相当于人工神经网络的记忆。
简单单元神经网络M-P模型
多层前馈神经网络模型
在监督学习中,将训练样本的数据加到网络输入端,同时将相应的期望输出与网络输出相比较,得到误差信号,以此控制权值连接强度的调整(B-P算法),经多次训练后收敛到一个确定的权值。当样本情况发生变化时,经学习可以修改权值以适应新的环境。
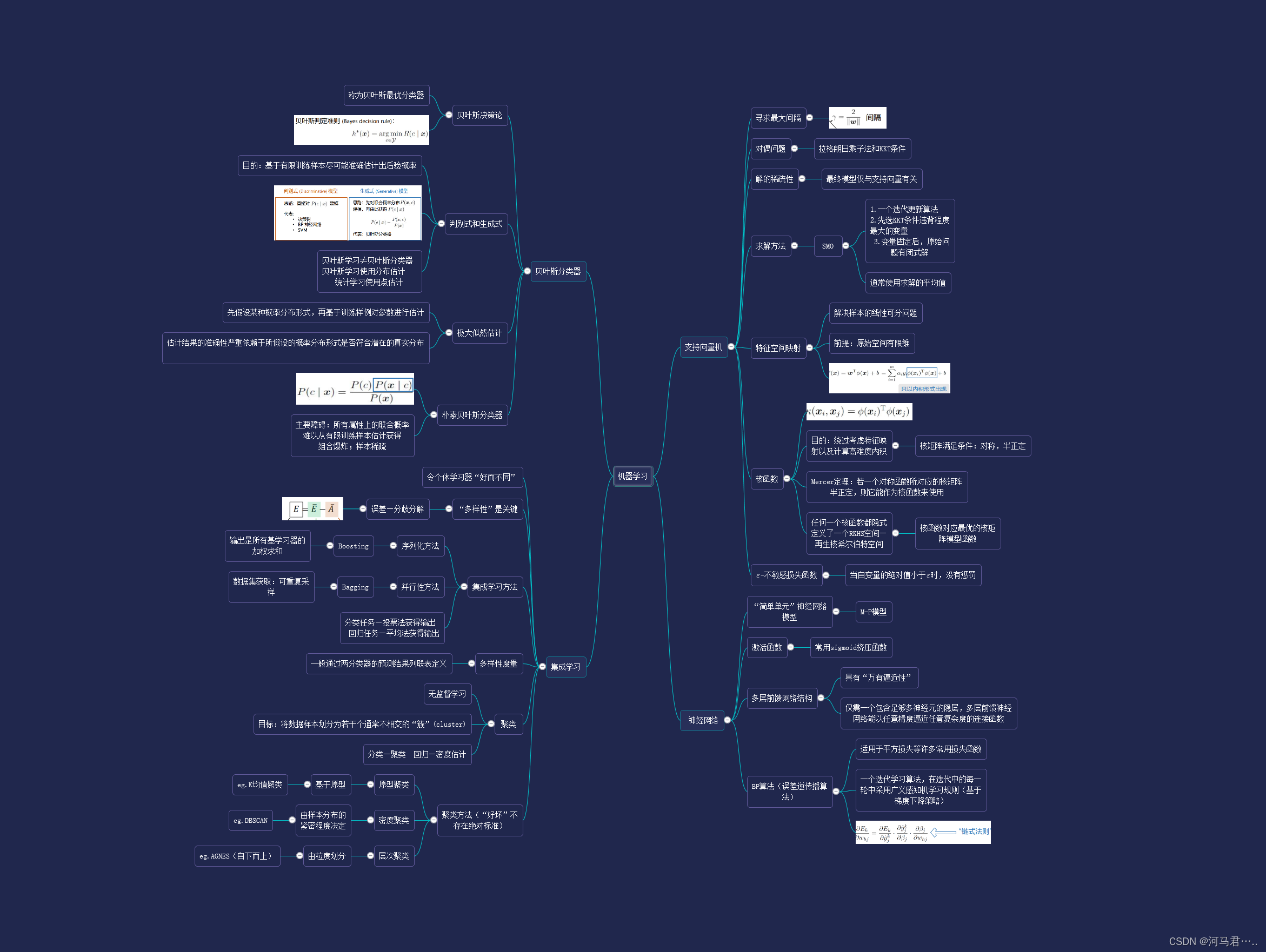
5. 贝叶斯分类器(为了将对象分类)
贝叶斯学习是利用参数的先验分布,由样本信息求来的后验分布,直接求出总体分布。贝叶斯学习理论使用概率去表示所有形式的不确定性,通过概率规则来实现学习和推理过程。

了解先验概率与后验概率是什么
贝叶斯分类器是各种分类器中分类错误概率最小或者在预先给定代价的情况下平均风险最小的分类器。它的设计方法是一种最基本的统计分类方法。其分类原理是通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类.
6.集成学习
分类器集成,其实就是集成学习,通过构建并结合多个学习器来完成学习任务。一般结构是:先产生一组“个体学习器”,再用某种策略将它们结合起来。
结合策略主要有平均法、投票法和学习法等
产生一组“个体学习器”,再用某种策略将它们结合起来。个体学习器通常由一个现有的学习算法从训练数据中产生,例如C4.5决策算法、BP神经网络算法等,此时集成中只包含同种类型的个体学习器,例如“决策树集成”中全是决策树,“神经网络集成”中全是神经网络,这样的集成是“同质”的。同质集成中的个体学习器亦称为“基学习器”。相应的学习算法称为“基学习算法”。集成也可包含不同类型的个体学习器,例如,同时包含决策树和神经网络,这样的集成称为“异质”的。异质集成中的个体学习器由不同的学习算法生成,这时就不再有基学习算法,常称为“组件学习器”或直接称为个体学习器。
集成学习通过将多个学习器进行结合,常可获得比单一学习器更加显著的泛化性能 [1]
要想获得好的集成,个体学习器应“好而不同”,即个体学习器要有一定的“准确性”,即学习器不能太坏,并且要有“多样性”,即学习器间具有差异。
在现实任务中,个体学习器是为解决同一个问题训练出来的,它们显然不可能独立。事实上,个体学习器的“准确性”和“多样性”本身就存在着冲突。一般的,准确性很高之后,要增加多样性就必须牺牲准确性。
集成学习方法可分为两大类:
序列(串行)方法boosting;
并行方法bagging,随机森林
7.支持向量机SVM
目的:寻找到一个超平面将样本分为两类,在样本中距离支持向量机越远的越不容易被分错,越近的越容易出错;
因此我们在寻找时要寻找 间隔最大的超平面进行区分
SVM可以通过核方法(kernel method)进行非线性分类,是常见的核学习(kernel learning)方法之一 [4] 。寻找一个合适的核函数将低维向高维转变
非线性可分的空间可以由核函数转化到希尔伯特空间,在高纬度线性可分
由于映射函数具有复杂的形式,难以计算其内积,可使用核方法(kernel method),即定义映射函数的内积为核函数,
Mercer定理: 函数是核函数具有一定的条件:对于输入空间的任何向量,其核矩阵都是对称且半正定的















 2107
2107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









