







FramePack是一种下一帧(下一帧部分)预测神经网络结构,可逐步生成视频。
FramePack将输入上下文压缩为恒定长度,因此生成工作量与视频长度无关。
即使在笔记本电脑 GPU 上,FramePack 也能使用 13B 模型处理大量帧。
FramePack可以用更大的批次规模进行训练,类似于图像扩散训练的批次规模。
Video diffusion, but feels like image diffusion.
要求:
- 支持 fp16 和 bf16 的 RTX 30XX、40XX、50XX 系列 Nvidia GPU。不测试 GTX 10XX/20XX。
- Linux 或 Windows 操作系统。
- 至少 6GB GPU 内存。
安装
Windows一键安装包,作者正在TODO
Linux
conda create -n FramePack python=3.10 -y
conda activate FramePack
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
pip install -r requirements.txt
要启动图形用户界面,请运行
python demo_gradio.py # --server 0.0.0.0
软件支持 PyTorch attention、xformers、flash-attn 和 sage-attention。默认情况下,它只使用 PyTorch attention。如果你知道如何安装,也可以安装这些注意力内核。
例如,安装 sage-attention (linux):
pip install sageattention==1.0.6
不过,强烈建议您先在不使用sage-attention的情况下进行尝试,因为sage-attention会影响效果,尽管影响很小。
UI操作
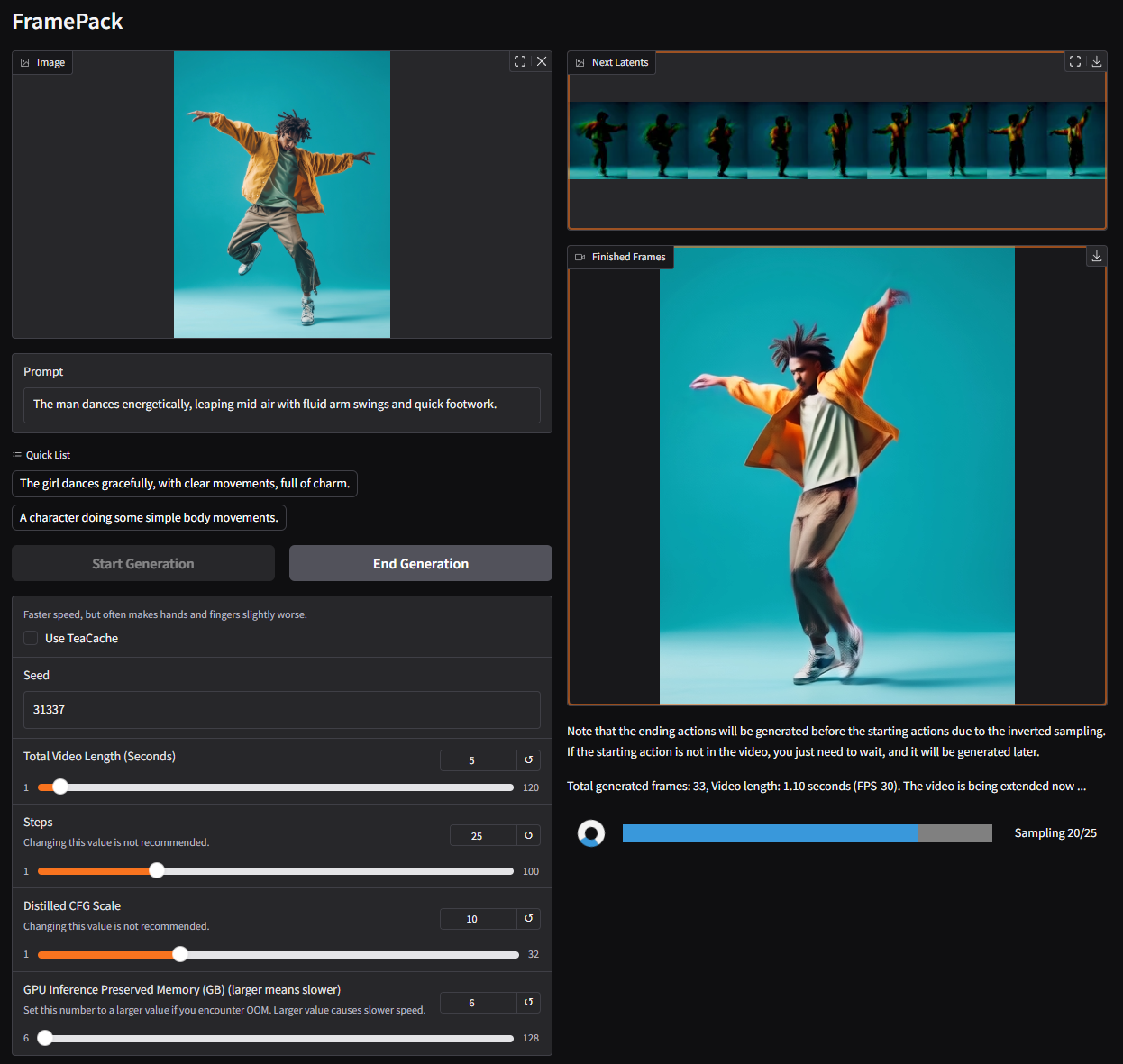
上传图片

prompt:
The man dances energetically, leaping mid-air with fluid arm swings and quick footwork.
代码
https://github.com/lllyasviel/FramePack
模型
from huggingface_hub import snapshot_download
snapshot_download(repo_id="hunyuanvideo-community/HunyuanVideo")
snapshot_download(repo_id="lllyasviel/flux_redux_bfl")
snapshot_download(repo_id="lllyasviel/FramePackI2V_HY")


















 1066
1066

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









